


一、SPSS 概 览
到目前为止,SPSS已成为适合于DOS,Windows,UNIX,Macintosh及OS/2等多种操作系统使用的产品,国内常用的是其适用于DOS和Windows的版本。SPSS for DOS通常称为SPSS/PC+,现已较少使用。1994至1998年间,SPSS公司陆续购并了Systat公司、BMDP软件公司、Quantum公司、ISL公司等,并将各公司的主打产品整合到SPSS旗下。通过这一系列的收购,引进的新技术包括数据挖掘技术、为IBM的eServer iSeries开发的商业智能套件、Web分析、复杂分析组件、Web界面的OLAP分析方法,以及文本挖掘。随着IBM的软件产品战略转变为“智慧地球”,IBM逐步整合完善了软件与服务产品线包括企业信息化咨询、商业数据库系统、商业智能系统等。在2009年7月28日,IBM公司以12亿美元收购SPSS公司,并且在同年10月2日宣布收购成功完成。
SPSS主要有3种运行方式。
1.批处理方式
2.完全窗口菜单运行方式
3.程序运行方式
1.SPSS主界面
SPSS安装完毕后,系统会自动在Windows菜单中创建快捷方式。
SPSS主界面主要有两个,一个是SPSS数据编辑窗口,另一个是SPSS输出窗口。数据编辑窗口由标题栏、菜单栏、工具栏、编辑栏、变量名栏、内容区、窗口切换标签页和状态栏组成。
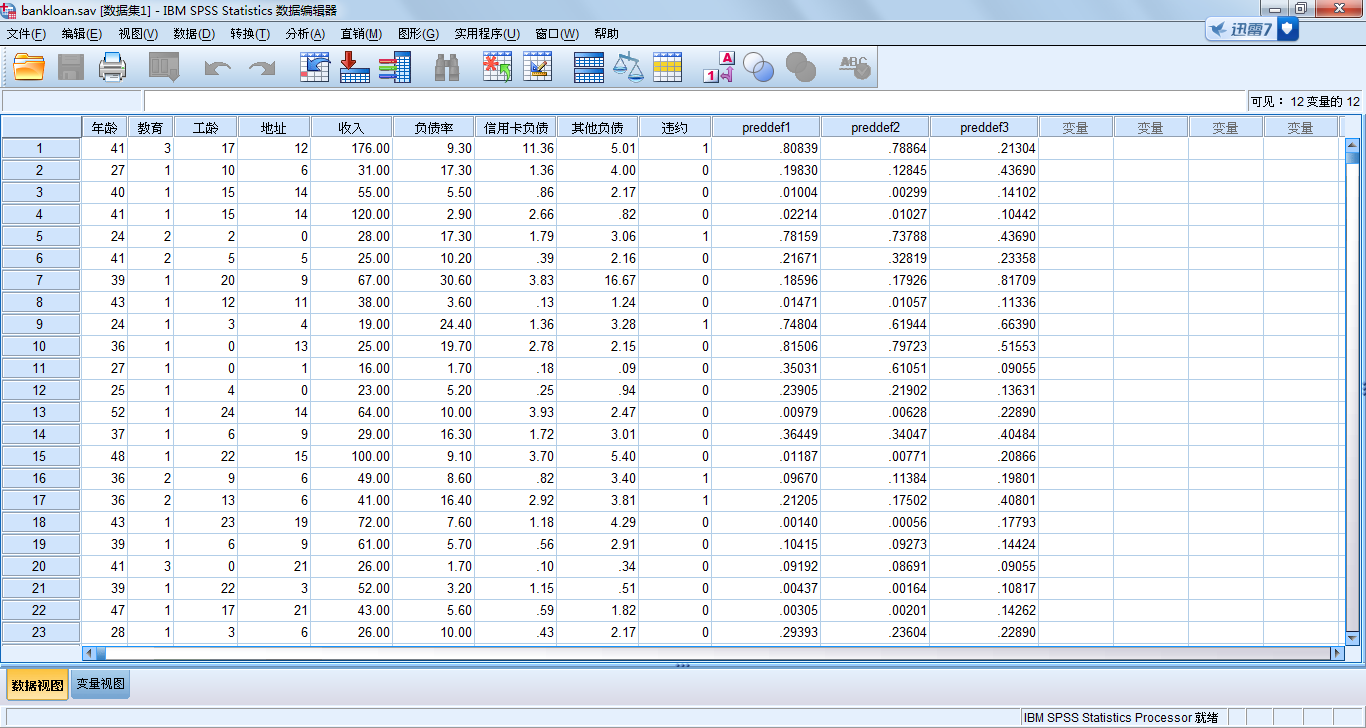
(1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征。例如问卷上的每一项就是一个变量。
(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case)。例如,问卷上的每一个人就是一个观测。
(3)单元包含值,即每个单元包括一个观测中的单个变量值。单元(Cell)是观测和变量的交叉。
(4)数据文件是一张长方形的二维表。数据文件的范围是由观测和变量的数目决定的。可以在任一单元中输入数据。如果在定义好的数据文件边界以外键入数据,SPSS将数据长方形延长到可包括那个单元和文件边界之间的任何行和列。
2.SPSS结果输出窗口
SPSS结果输出窗口名为Viewer,它是显示和管理SPSS统计分析结果、报表及图形的窗口。读者可以将此窗口中的内容以结果文件.spo的形式保存。
输出区是详解输出区的一个视图,以简洁的方式反映出详解输出区中各个内容项,便于用户查找操作结果。
可以对详解输出区中的表格进行编辑等操作。
3.SPSS的帮助系统
在运行SPSS的任何时候,单击“Help”菜单中的“topics”命令,会弹出帮助主题窗口,如图1-4所示。在其中选择相关的命令,即可得到所需的各种帮助。
二、变量处理
SPSS对数据的处理是以变量为前提的,因此本节首先介绍定义变量、输入数据,再介绍保存数据、操作数据文件,最后介绍SPSS运行环境和系统参数的设置。
启动SPSS后,出现如图所示数据编辑窗口。由于目前还没有输入数据,因此显示的是一个空文件。
1. 定义变量
输入数据前首先要定义变量。定义变量即要定义变量名、变量类型、变量长度(小数位数)、变量标签(或值标签)和变量的格式。
单击数据编辑窗口左下方的“变量视图(Variable View)”标签或双击列的题头(变量),进入如图所示的变量定义视图窗口,在此窗口中即可定义变量。
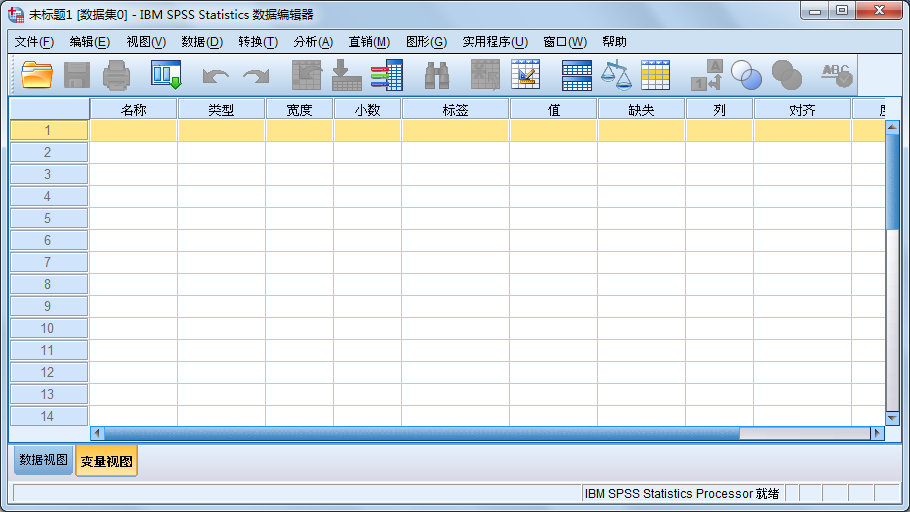
2. 变量定义和命名标准
在上图所示的窗口中每一行表示一个变量的定义信息,包括名称、类型、宽度、小数、标签、值、缺失、列、对齐、度量标准等。SPSS默认的变量为Var00001、Var00002等,用户也可以根据自己的需要来命名变量。SPSS变量的命名和一般的编程语言一样,有一定的命名规则,具体内容如下。
- 变量名必须以字母、汉字或字符@开头,其他字符可以是任何字母、数字或_、@、#、$等符号。
- 变量最后一个字符不能是句号。
- 变量名总长度不能超过8个字符(即4个汉字)。
- 不能使用空白字符或其他特殊字符(如“!”、“?”等)。
- 变量命名必须惟一,不能有两个相同的变量名。
- 在SPSS中不区分大小写。例如,HXH、hxh或Hxh对SPSS而言,均为同一变量名称。
- SPSS的保留字(Reserved Keywords)不能作为变量的名称,如ALL、AND、WITH、OR等。
3. 变量类型(Type)
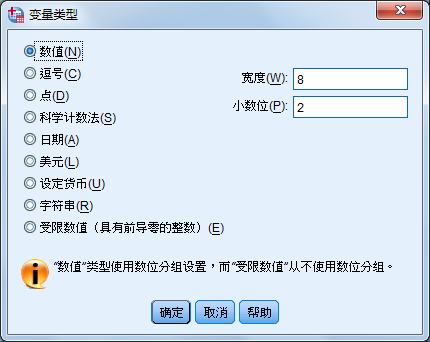
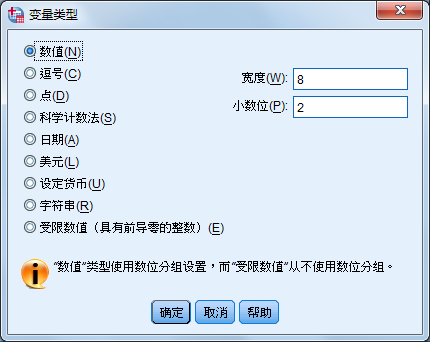
单击类型相应单元中的按钮,弹出如图所示的对话框,在对话框中选择合适的变量类型并单击“OK”按钮,即可定义变量类型。
SPSS的主要变量类型如下:
- Numeric
- Comma
- Dot
- Scientific notation
- Date
- Dollar
- Custom currency
- String
4. 变量长度、小数点位数、标签、值
设置变量的长度(Width) ,当变量为日期型时无效。设置变量的小数点位数(Decimal),当变量为日期型时无效。
变量标签(Label)是对变量名的进一步描述,变量只能由不超过8个字符组成,而8个字符经常不足以表示变量的含义。而变量标签可长达120个字符,变量标签可显示大小写,需要时可用变量标签对变量名的含义加以解释。
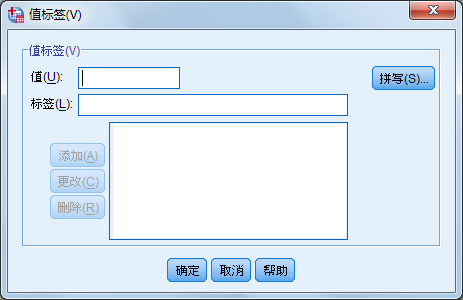
变量值标签(Values)是对变量的每一个可能取值的进一步描述。
5. 变量缺失值、列、对齐方式
SPSS有两类缺失值:系统缺失值和用户缺失值。单击Missing相应单元中的按钮,在弹出的如图所示的对话框中可改变缺失值的定义方式,在SPSS中有两种定义缺失值的方式。
- 可以定义3个单独的缺失值。
- 可以定义一个缺失值范围和一个单独的缺失值。
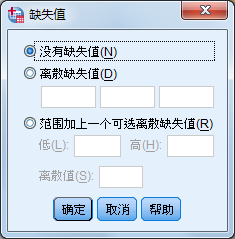
选择变量值显示时的对齐方式(Align):Left(左对齐)、Right(右对齐)、Center(居中对齐)。默认是右对齐。
6. 变量度量标准
变量按度量精度可以分为定性变量、定序变量、定距变量和定比变量几种。如果有多个变量的类型相同,可以先定义一个变量,然后把该变量的定义信息复制给新变量。
三、数据输入与保存
变量按度量精度可以分为定性变量、定序变量、定距变量和定比变量几种。
如果有多个变量的类型相同,可以先定义一个变量,然后把该变量的定义信息复制给新变量。
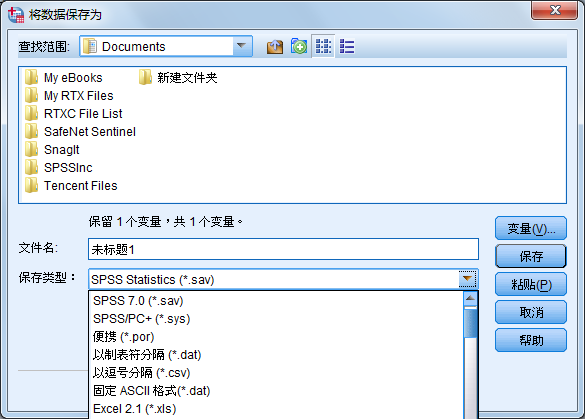
- SPSS(*.sav)
- SPSS/PC+(*.sys)
- SPSS Portable(*.por)
- Tab delimited(*.dat)
- Comma delimited(*.csv)
- Fixed ASCII(*.dat)
- Excel 2.1(*.xls)
- 1-2-3 Rel 3.0(*.wk3)
- SYLK(*.slk)
- dBASE 4(*.dbf)
- dBASE Ⅲ(*.dbf)
- dBASE Ⅱ(*.dbf)
- SAS v6 for Windows(*.sd2)
1. 数据的编辑
由于各种原因,已经输入的数据有时会需要修改,这就需要进行编辑,可用方向键或鼠标将黑框移动到要修改的单元,键入新值。
2. 数据的排序和行列互换
在数据文件中,可根据一个或多个排序变量的值重排个案的顺序。
3. 选择个案子集
在数据统计中可从所有资料中选择部分数据进行统计分析。系统提供的方式如下:
- All cases
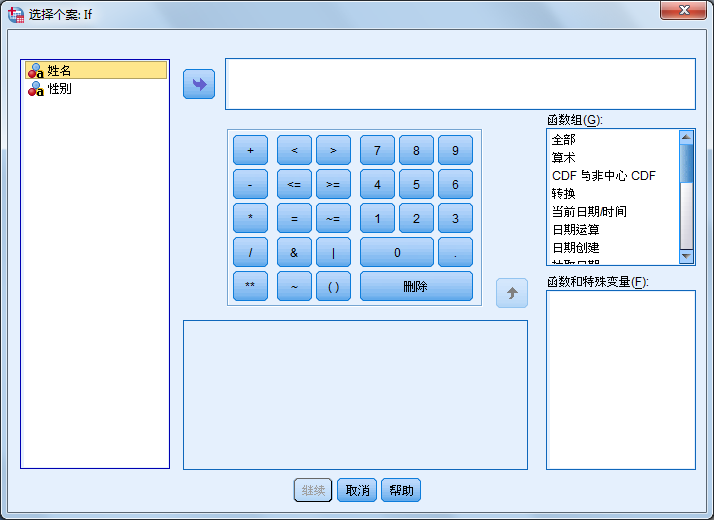
- If condition is satisfied
- Random sample of cases
- Based on time or case range
- Use filter variable
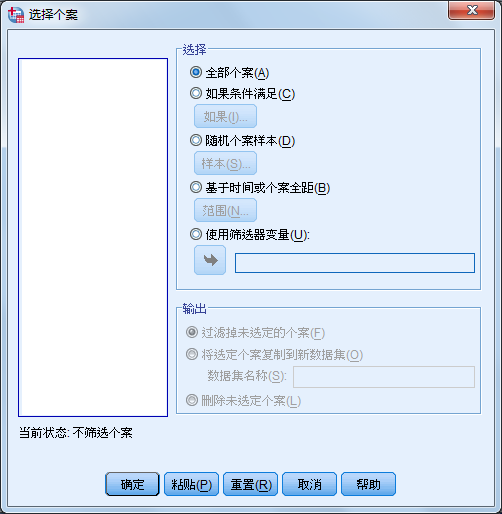
Output单选框有三个选项,分别提供如下的输出方式:
- Filter out unselected cases
- Copy selected cases to a new dataset
- Delete unselected cases
4. 数据分类汇总
用户还可对数据编辑器中的数据按指定变量的数值进行归类分组汇总。在SPSS中,实现数据文件的分类汇总需要3个步骤。首先,需要指定分类变量和汇总变量。然后,计算机根据分类变量的若干个不同取值将个案数据分成若干类,并对每类个案计算汇总变量的描述统计量。最后,将分类汇总计算结果保存到一个文件中。
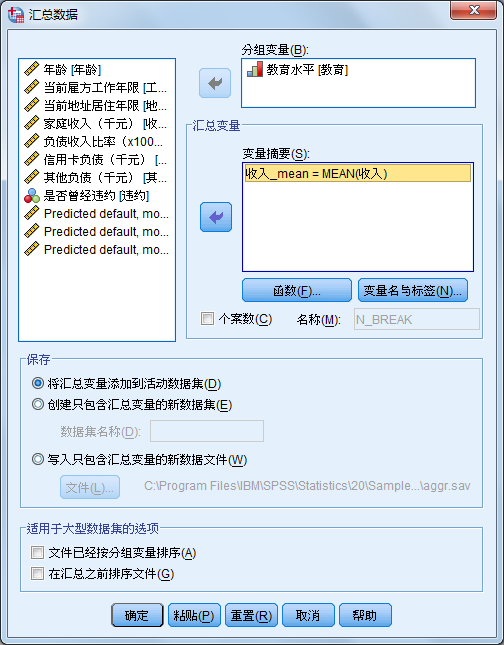
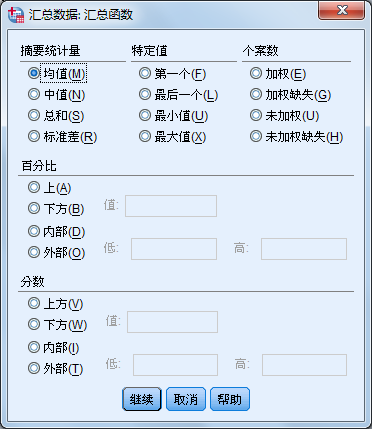
分组汇总提供的函数形式主要有以下几种。
- Mean
- Median
- Sum
- Standard deviation
- First
- Last
- Minimum
- Maximum
- Weighted
- Weighted Missing
- Unweighted
- Unweighted
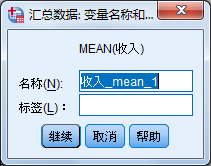
5. 缺失值的替代
对于缺失值,可采取多种手段进行科学替代。这里的缺失值必须是系统或用户指定的缺失值。 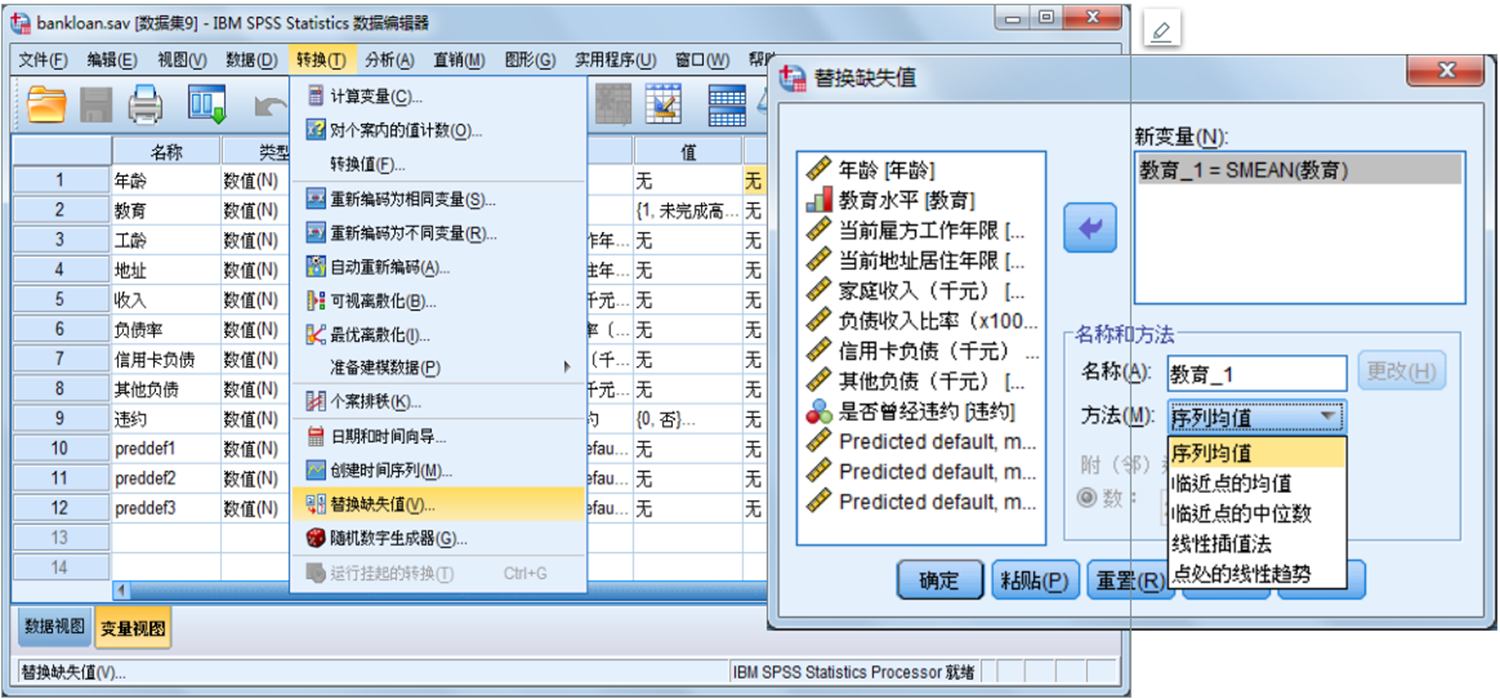
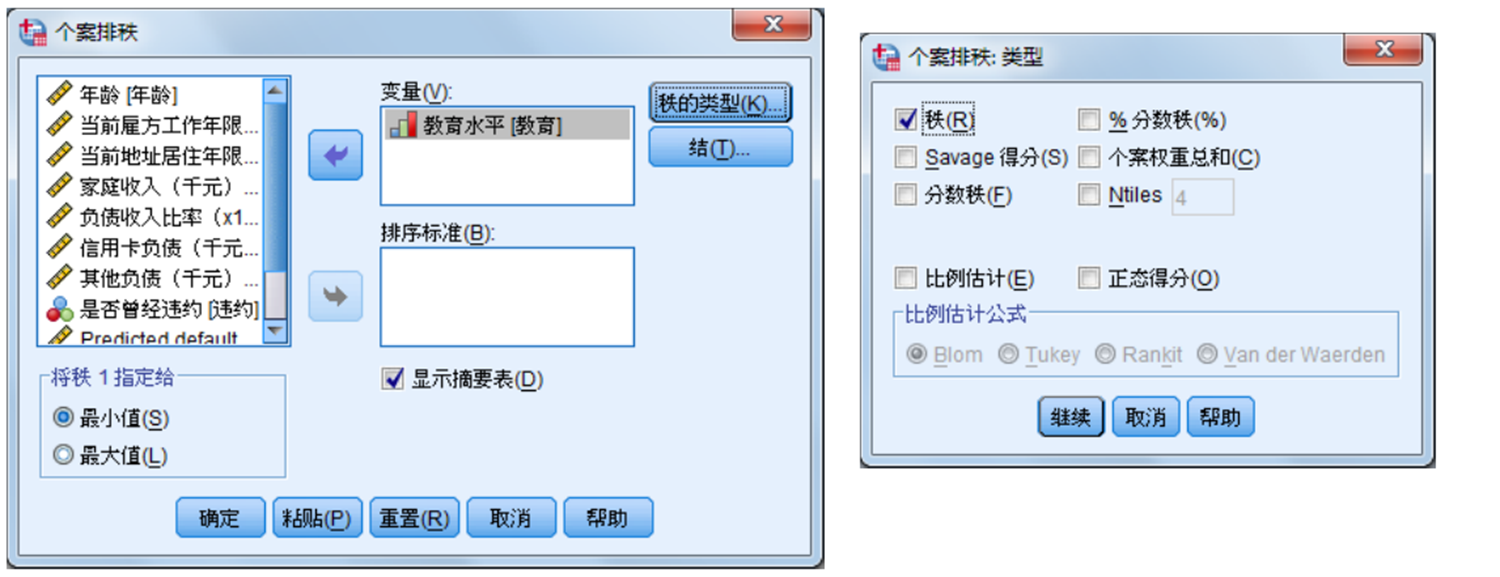
6. 数据个案排秩
选择“转换(Transform)”菜单中的“个案排秩(Rank Cases)”命令,弹出“个案排秩(Rank Cases)”对话框,如图所示,在该对话框中可以改变数据排序的次序。排序类型如下:
- Rank
- Fractional rank as percent
- Savage score
- Sum of case weights
- Fractional rank Ntiles
- Proportion estimates
- Normal scores
7. 变量操作
增加一个变量,即增加一个新的列。可以有多种操作方法,
(1)菜单操作法。 (2)选中某列法。 (3)Variable View标签页法。
8. 指定加权变量
在实际的统计中,经常需要计算数据的加权平均数。例如,希望了解某超市中某天售出商品的平均价格。如果仅以各种商品的单价平均数作为平均价格是不合理的,还应考虑到各商品的销售量对平均价格的影响。因此,以商品的销售量作为权重计算各种商品单价的加权平均数,才是我们需要求的数据。在SPSS处理中就需要将商品销售量作为加权变量。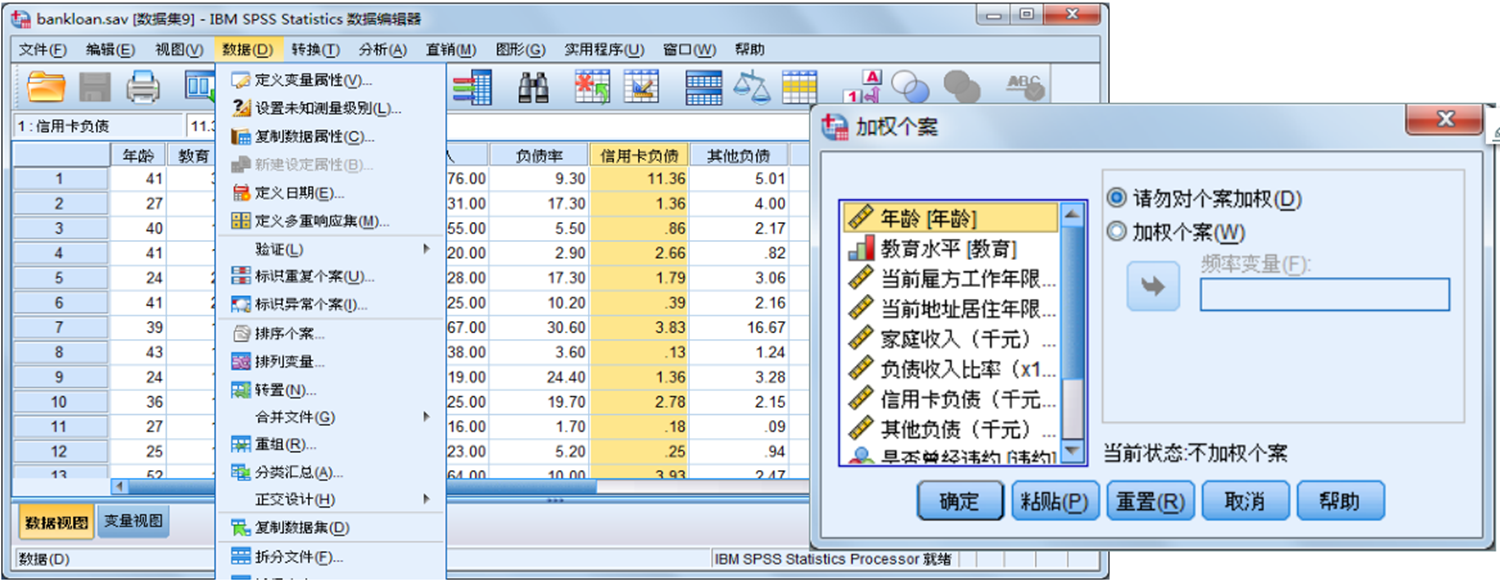
9. 生成新变量
在数据统计中,有时候经常需要通过数据转换来提示变量之间的真实关系。这时需要通过对已经存在的变量进行处理,从而生成新的变量。选择“转换Transform”菜单的“计算变量Compute Variable”项,弹出如图所示的“Compute Variable”(计算变量)对话框。在该对话框中的“Target Variable(目标变量)”框中输入符合变量命名规则的变量名,目标变量可以是现存变量或新变量。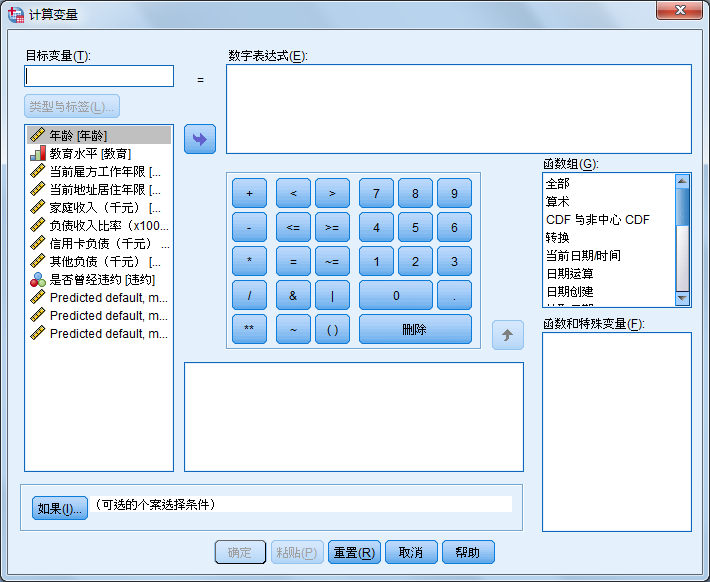
10. 产生计数变量
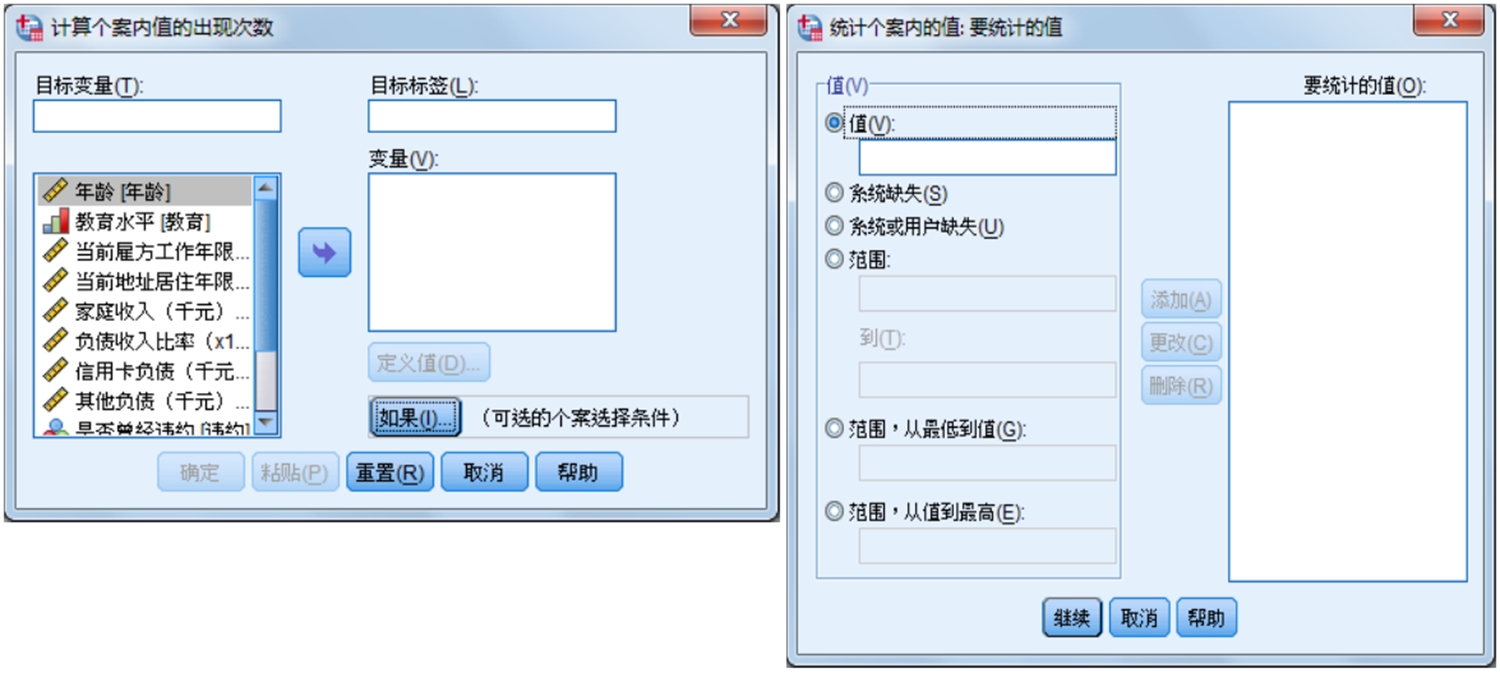
在统计过程中,往往需要进行一些计数工作。产生计数变量就是实现计数功能,它对所有个案或满足一定条件的个案,计算若干个变量中有几个变量的值落在指定的区间内,并将计数结果放入一个新变量中。
11. 变量重新赋值
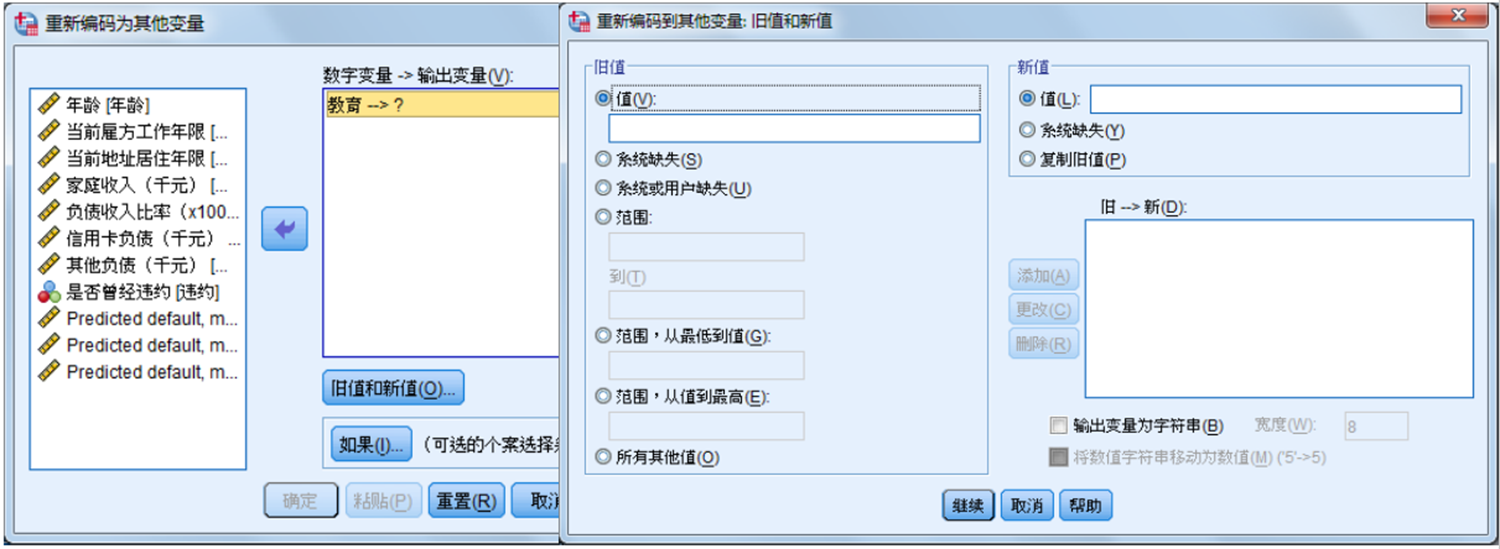
在数据编辑过程中,用户可对个案的某个变量的数值重新赋予新值。这种操作只适用于数值型变量。在“Transform”菜单中的有“重新编码为相同变量”和“重新编码为不同变量”两种赋值方法供选择。其中“重新编码为相同变量”是对变量自身重新赋值;“重新编码为不同变量”是赋值到其变量或新生成的变量。
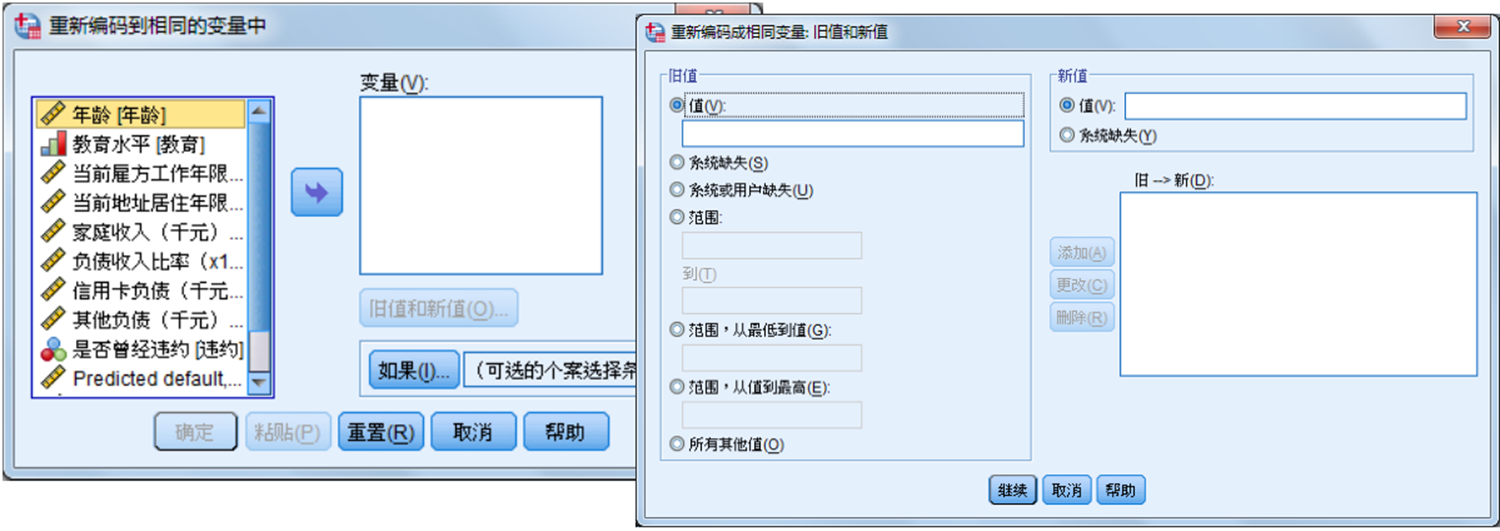
与前面根据已存在的变量建立新变量方法不同的是:变量的重新赋值Recode不能进行运算,只能根据指定变量值作数值转换,且这种转换是单一数值的转换。
12. 变量自动赋值
变量的自动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在一个新的变量中,其中字符型数据按照字母的顺序排序。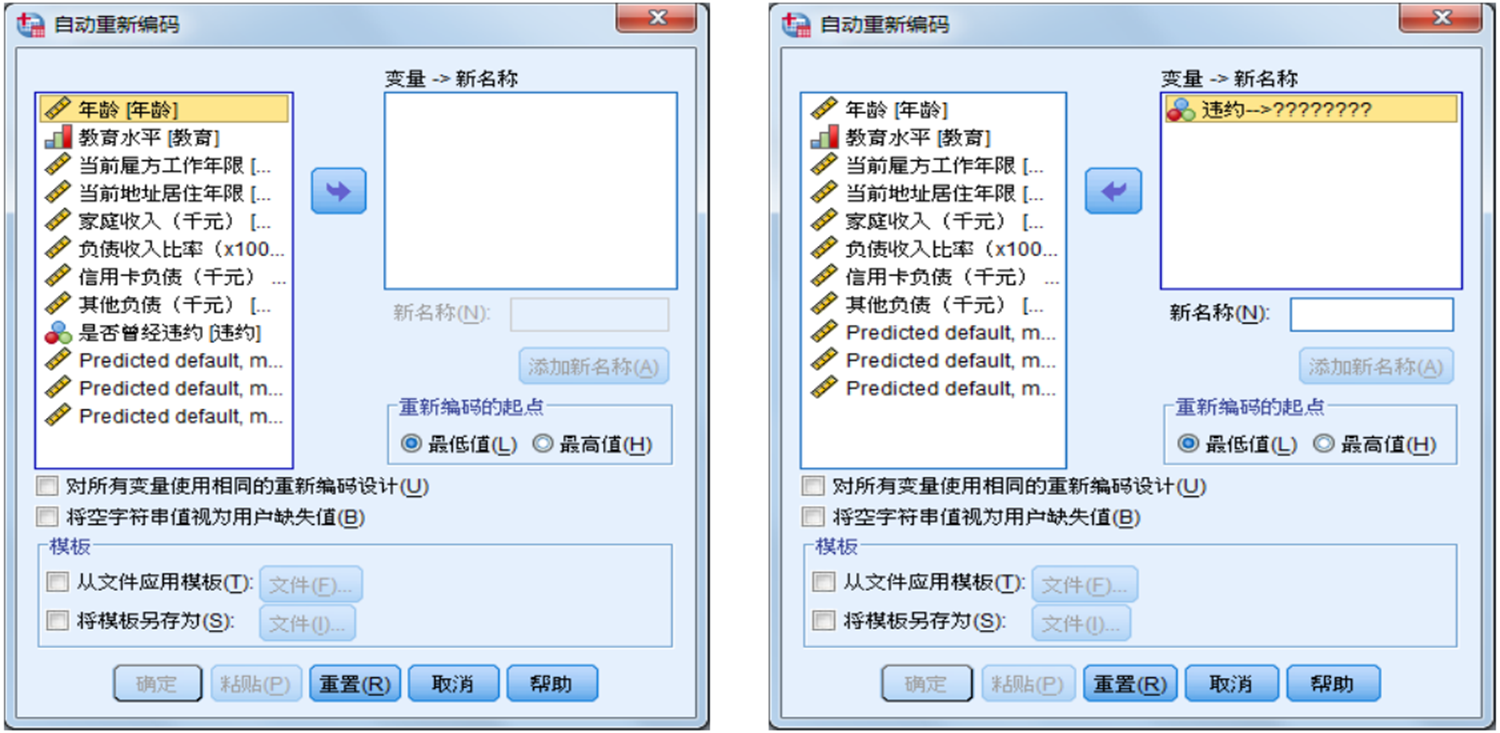

13. 变量集的定义和使用
在SPSS的统计过程中,有时候收集到的变量会有很多个。在进行各种数据处理和统计分析时,所有变量都会显示在各个处理对话框的变量列表框中供用户选择。在众多变量中选择几个变量进行处理以及分析是很麻烦的,尤其是对于某几个经常需要进行操作的变量。SPSS提供了变量集(Variable Set)的概念,可以很好地解决上面所提出的问题。所谓变量集是指一些变量的集合。比如我们收集了某班级同学众多科目的成绩,可以把这些科目分为理科、文科、自然科学等,这其实就是变量集的概念。SPSS变量集有两类:系统变量集和用户自定义变量集。
系统变量集是SPSS系统已经定义好的,它包括以下两个集合。
- ALL VARIABLES:存放数据编辑窗口中所有的变量。
- NEW VARIABLES:存放数据编辑窗口中所有尚未保存的新定义变量。
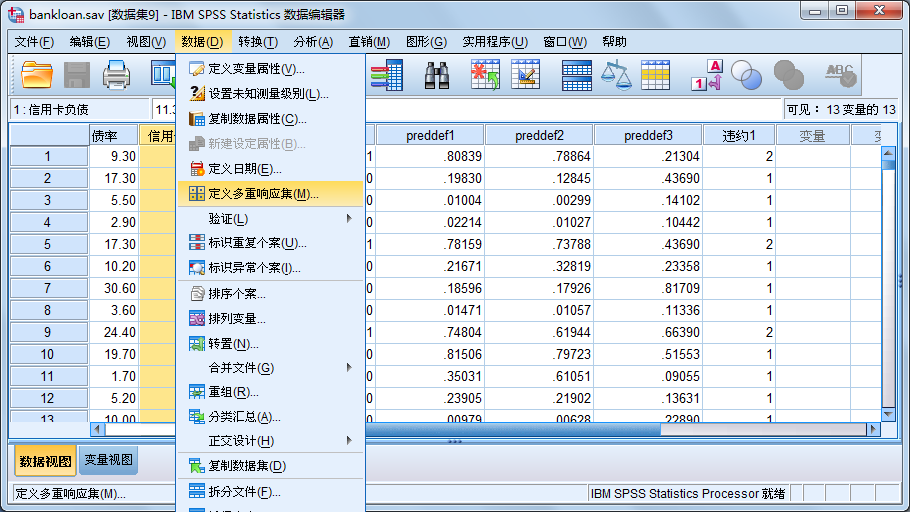
要将信用卡负债、其他负债归到一个用户定义变量集中,名称为理科,具体操作的过程如下
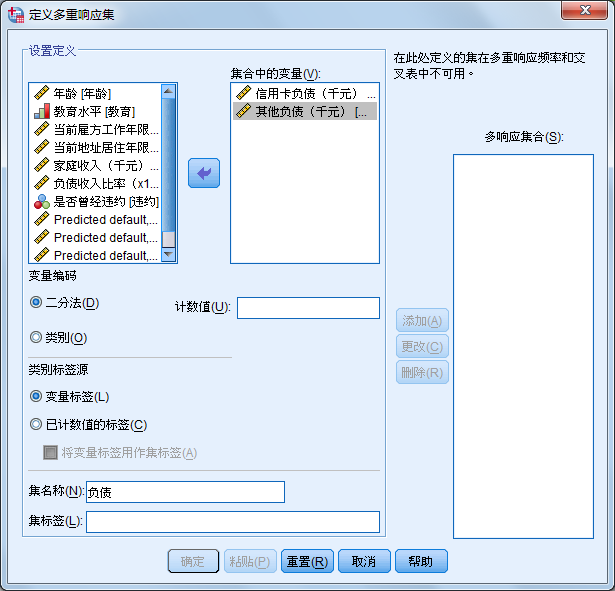
14. 数据文件的合并和分组
统计分析的首要任务是将数据输入到计算机中。在数据量较大时,经常需要将一份大的数据文件分成几个小部分,分别由几个人输入,然后将若干个小的数据文件合并成一个大的数据文件。数据文件的合并有两种方式:纵向合并和横向合并。纵向合并就是将一个SPSS数据文件的内容追加到数据编辑窗口当前数据的后面,然后将合并后的数据重新显示在数据编辑窗口中。通过该方法,可以将两个或更多个数据文件合并在一起。
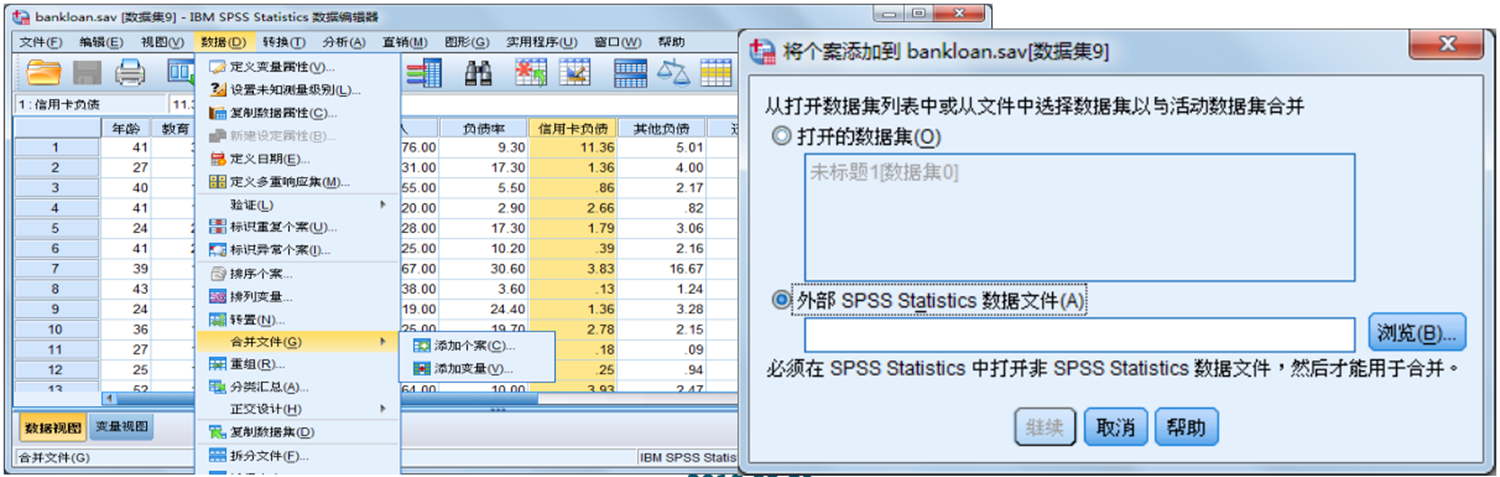
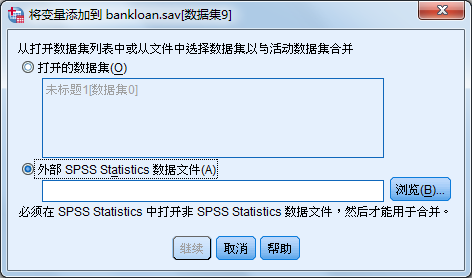
① 数据文件的横向合并
横向连接,也就是变量值的合并。利用横向合并可以将两个或两个以上的具有相同个案的数据文件连在一起。即将SPSS数据文件的内容连接到当前数据编辑窗口的右边,然后将合并后的数据文件显示在数据编辑窗口中。横向合并实质是将两个数据文件,按照个案对应进行左右对接。实现数据文件的横向连接,必须有一个相同的公共变量,这个变量是两个数据文件横向对应连接的依据。 在合并的两个数据文件中,数据含义不同的变量,变量名不应取相同的名称。
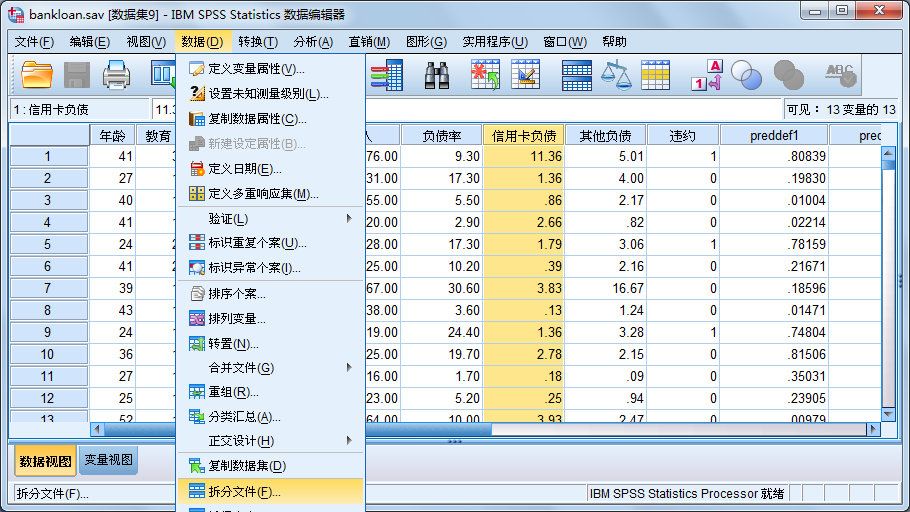
②数据文件的分组
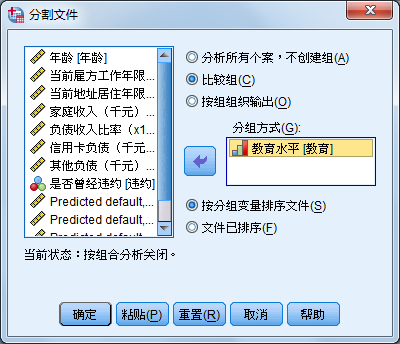
在统计中,经常需要先按某个变量进行分组,然后再求各个组的统计分析。例如,想分别了解男生和女生的成绩情况。这时就需要按照性别变量,进行数据文件的分组(这种分组是系统内定义的,在数据管理器中并不一定明确体现,故亦可称之为分割)。
用户一旦设置了分组,那么此后的所有分析都将按这种分组进行,除非取消数据分组的命令。
15. 读入其他格式数据文件
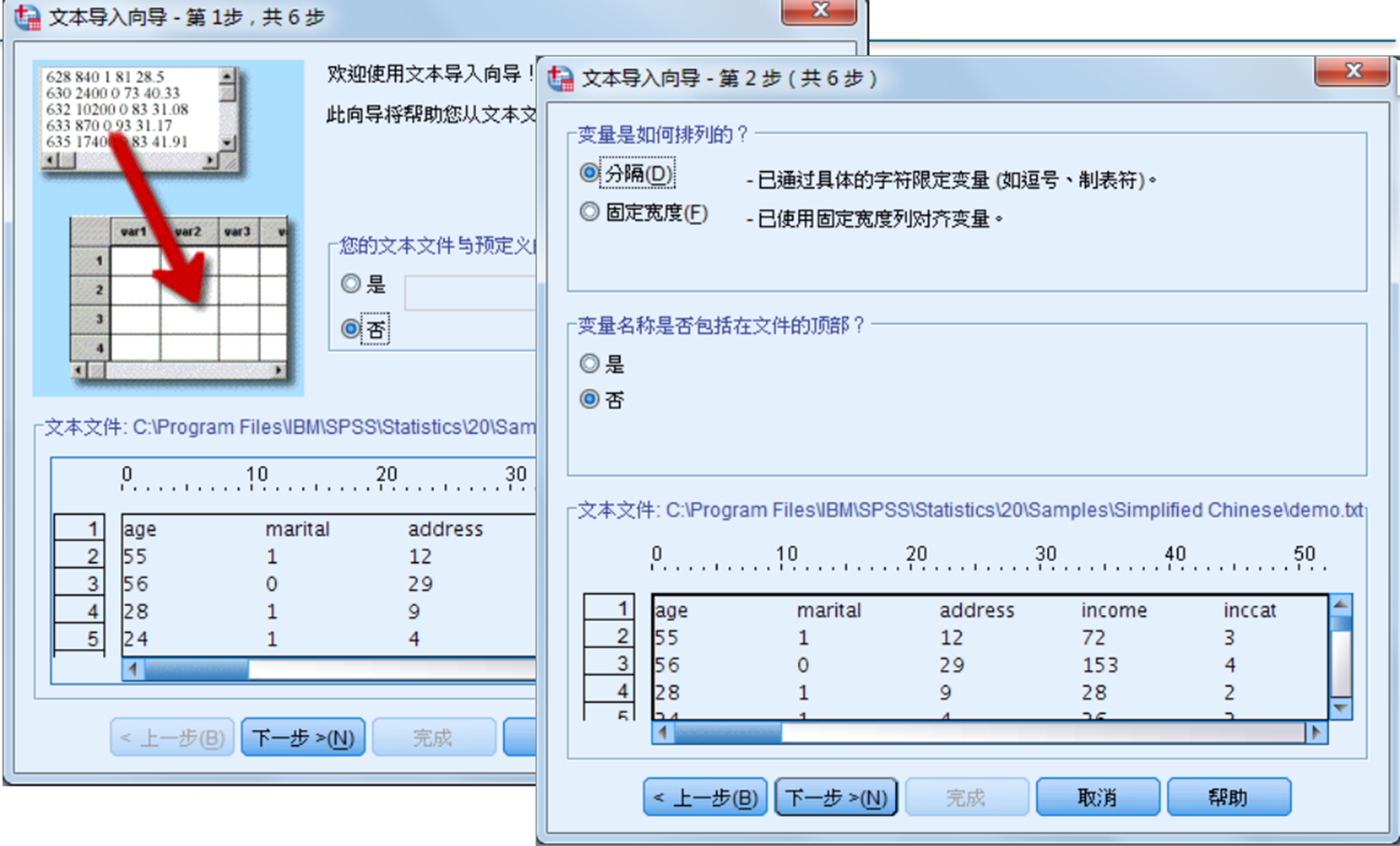
在前面的数据保存中,已经讲到SPSS数据文件可以保存成其他格式的文件,如文本文件、dbf文件等。反过来,SPSS是否可以直接读取其他格式数据文件呢?答案是肯定的。SPSS可以读取文本文件、数据库文件等内容。文本文件是计算机各种软件中最通用的一种格式文件。文本文件没有保存格式,因此,其文件很小,其中的数据均以ASCII码存储。各种软件,包括数据库软件、表格操作软件、字处理软件都可以将自己的格式数据转换成文本文件。因此,如果SPSS能够方便读取文本文件,那么就提高了读取其他软件数据的能力。根据文本文件中数据的排列方式,可将文本文件分成固定格式的文本文件和自由格式的文本文件两种。
固定格式(Fixed Columns)的文本文件,要求每个个案数据的变量数目、排列顺序、变量取值长度固定不变,一个个案数据可以占若干行,数据项之间可以有分隔符,也可以没有。分隔符一般为逗号、空格等。
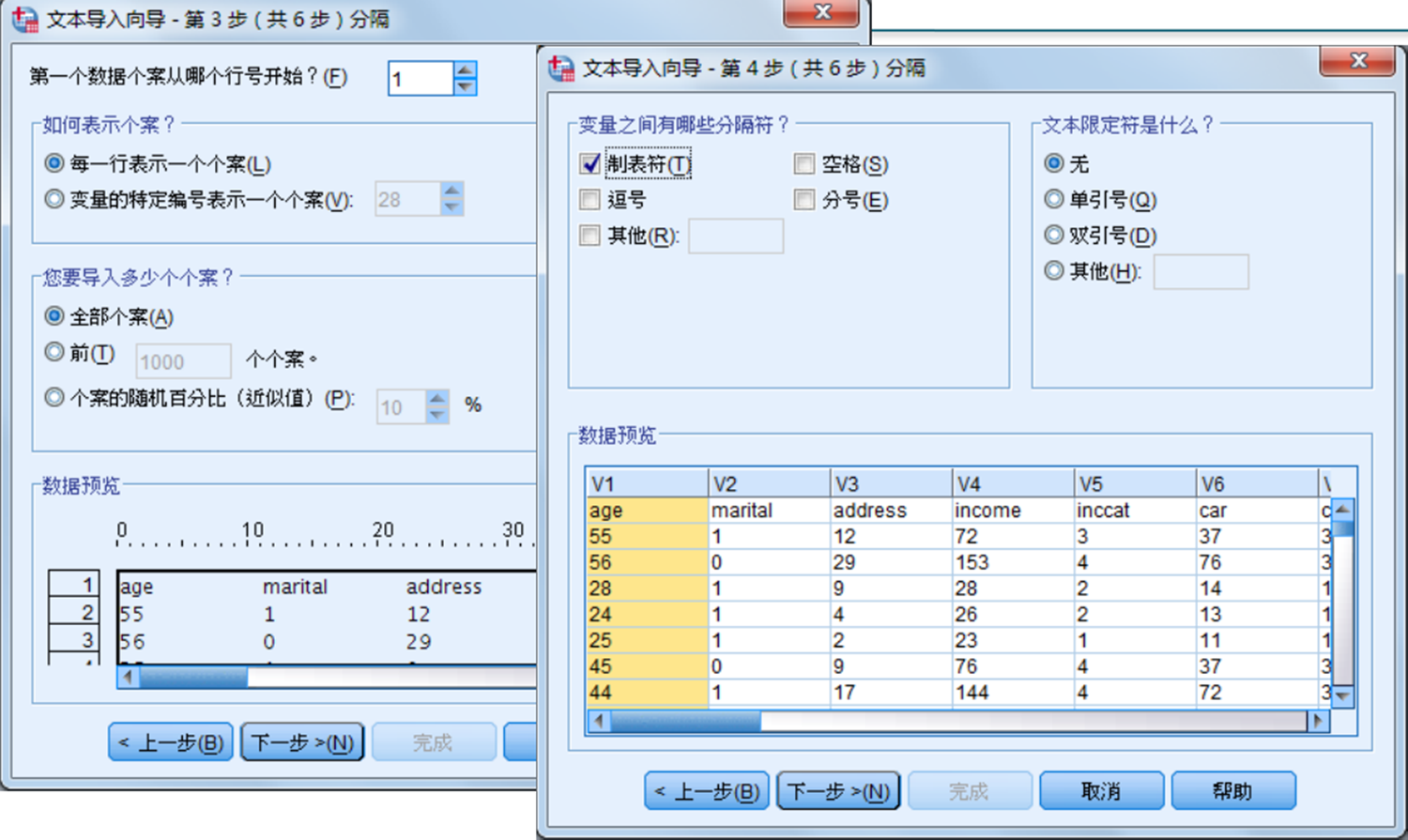
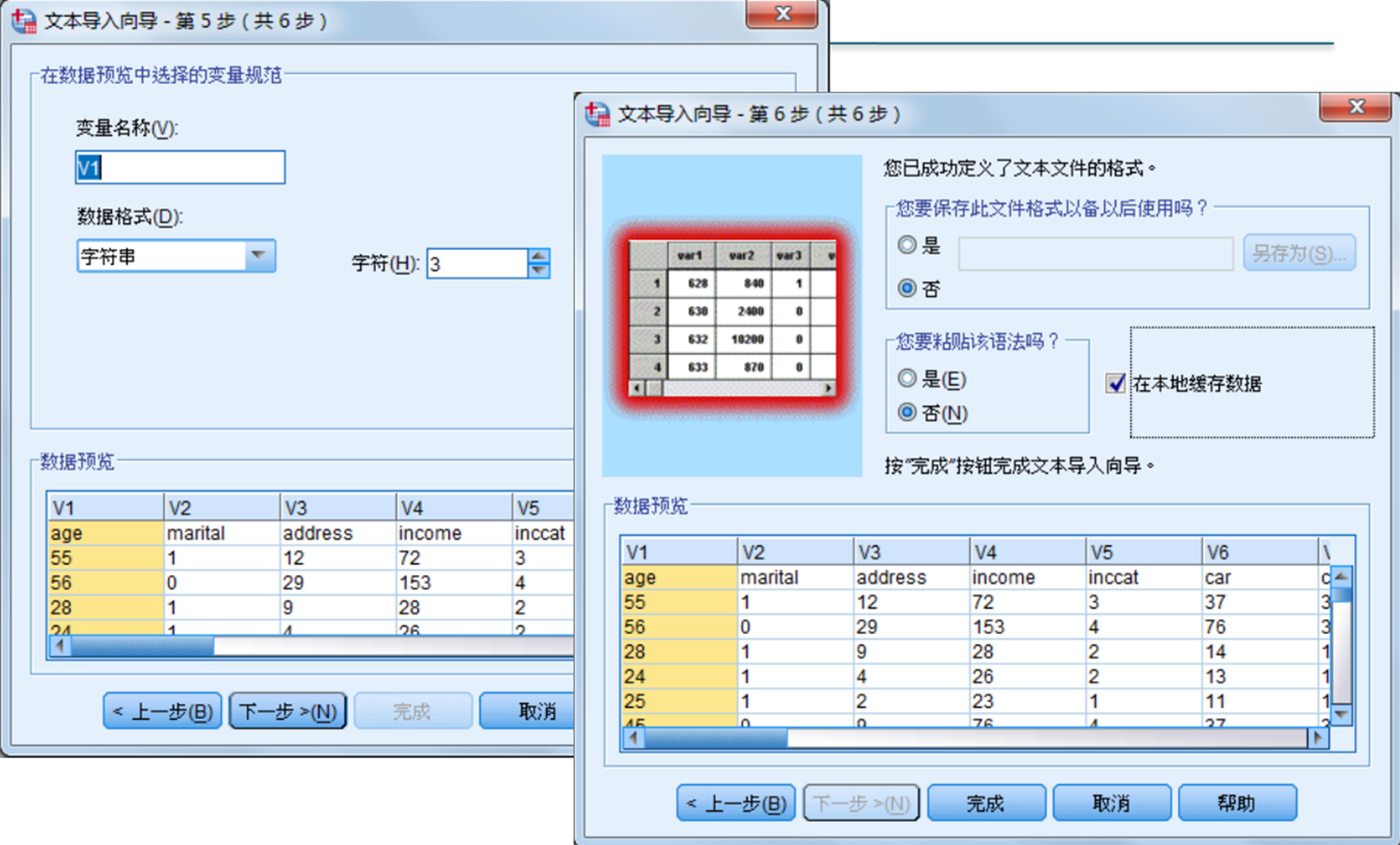
16. 读取自由格式文本文件
自由格式的文本文件(Free Field)每个个案的变量数目、排列顺序固定,一个个案数据可以占据若干行,和固定格式文本文件不同的是,自由格式文本文件的数据项之间必须有分隔符(分隔符可以是逗号、空格、Tab键等),但数据项的长度可以变化。17. 读取dBASE软件文件
dBASE数据库软件的文件以.dbf为扩展名保存。该文件除了保存纯数据信息外,还保存了一些数据结构、属性方面的信息。SPSS提供了与DBASE文件的接口,可以方便地将dBASE文件读入数据编辑窗口。具体的操作过程如下。

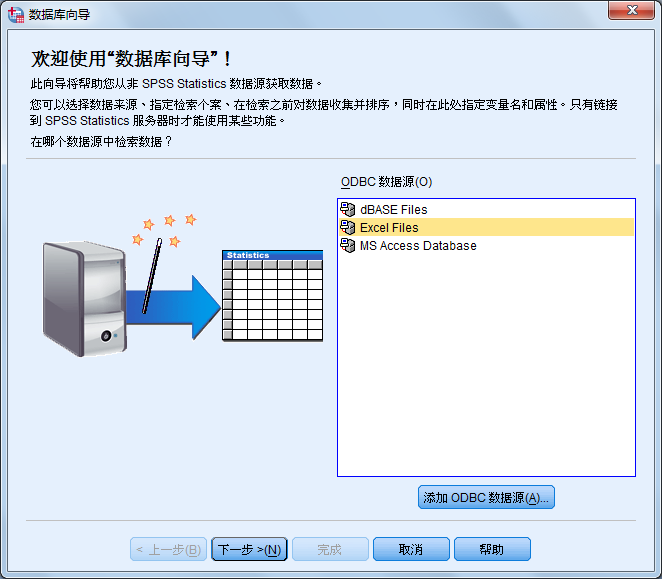
18. 读取Excel软件文件
Excel软件可能是Windows系列操作系统中使用最多的数据表格软件。Excel文件以.xls为扩展名保存。该文件除了保存纯数据信息外,还保存了另外一些数据信息。SPSS提供了与Excel文件的接口,可以方便地将Excel文件读入数据编辑窗口。具体的操作过程如下。
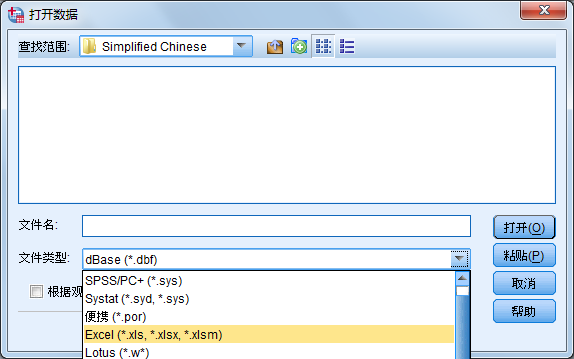
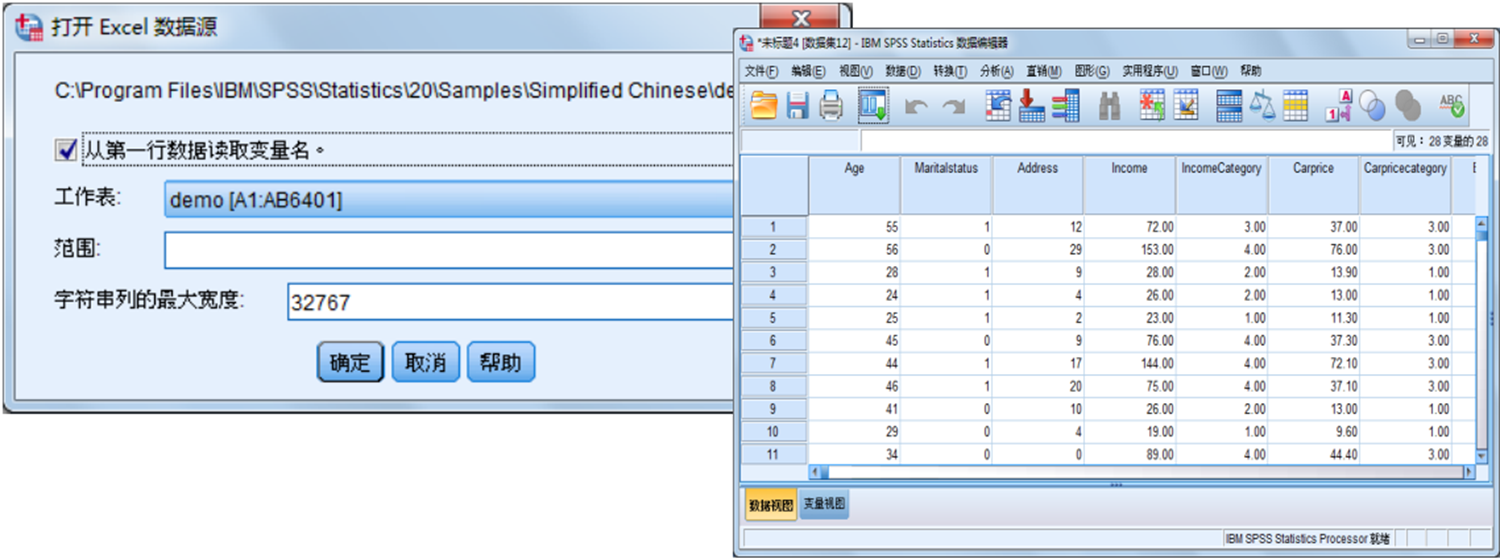
SPSS默认将某个sheet中所有数据都读入到数据编辑窗口中。在“Range”框中输入要读取数据的范围,也允许指定读取一部分区域的数据,如要读入前50行数据,则在该框中输入A1:F50,表示读取的区域是以A1单元为左上角,F50为右下角的矩形区域。Excel表格中每一行为SPSS的一个个案。单击“Continue”按钮,即可完成数据导入。
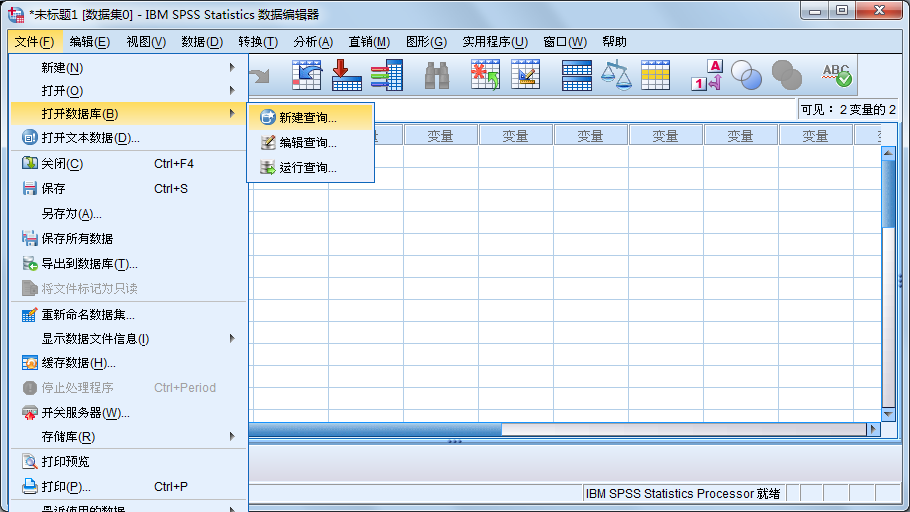
19. 读取数据库文件
SPSS还提供了读取Access及FoxPro等数据库文件的功能。
四、小结
利用SPSS进行统计分析,变量和数据是必不可少的。本次课主要介绍数据的输入、编辑以及针对变量的各种操作。将数据输入SPSS中有多种方法,用户可以逐行录入也可以读入其他格式文件数据。数据输入后通常需要对数据进行进一步的处理,如排序、分类汇总或缺失值的替代等。
SPSS中的分析都是针对某一特定变量进行的。熟练掌握变量的操作技巧十分有助于提升工作的效率。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)