


GIL锁及多进程
GIL
python有一个非常重要的GIL(global interpreter lock,全局解释器锁)
python代码执行由python虚拟机(解释器主循环)来控制。对python虚拟机的访问由GIL控制,GIL保证同一时刻只有一个线程在执行。
多进程
由于Python设计的限制(我说的是咱们常用的CPython)。最多只能用满一个CPU核心。
multiprocessing, 你只需要定义一个函数,Python会替你完成其他所有事情。借助这个包,可以轻松完成从单进程到并发执行的转换。

from multiprocessing.dummy import Pool import time def get_page(str): print("正在下载:" + str) time.sleep(2) print("下载成功:" + str) return str name_list = ['1', '2', '3', '4', '5', '6', '7', '8', '9'] # 实例化一个线程池对象 pool = Pool(9) # 开辟一个进程池 # 将列表中每一个列表元素传递给get_page进行处理 returnData = pool.map(get_page, name_list) print(returnData)
总结
1. 对应上例中的所面临的可能同时出现的上千甚至上万次的客户端请求,“线程池”或“连接池”或许可以缓解部分压力,但是不能解决所有问题。
2. 总之,多线程模型可以方便高效的解决小规模的服务请求,但面对大规模的服务请求,多线程模型也会遇到瓶颈,可以用非阻塞接口来尝试解决这个问题。
异步及多任务异步
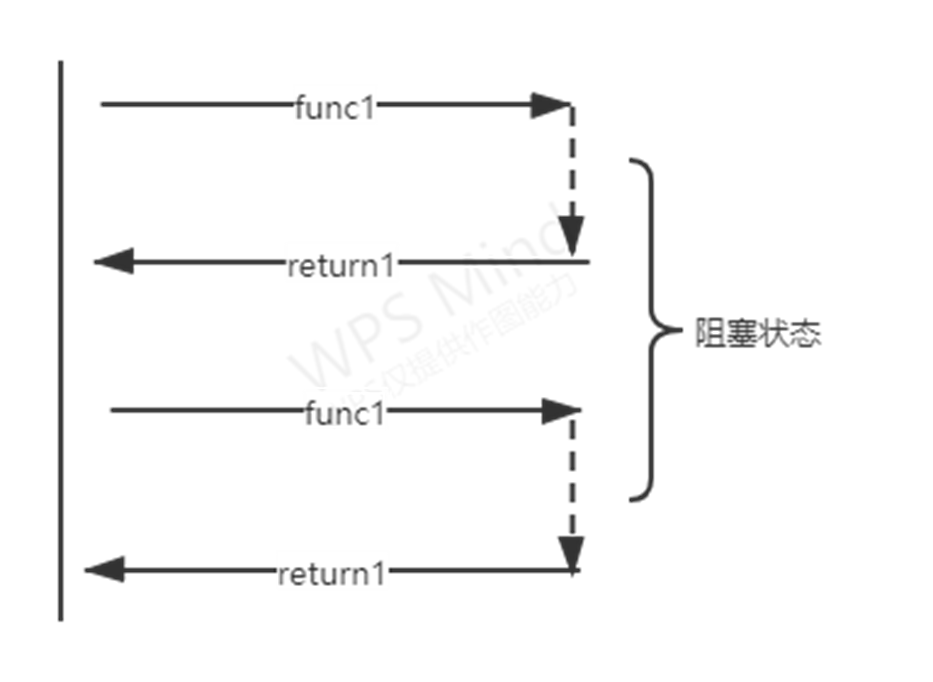
同步调用
即提交一个任务后就在原地等待任务结束,等到拿到任务的结果后在继续下一行代码,效率低下。
解决同步调用方案之多线程/多进程
好处: 在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。
弊端: 开启多进程或多线程的方式,我们是无法无限制开启多进程或多线程的,在遇到要同时响应成百上千的连接请求,则无论多线程还是多进程都会严重占据系统资源,降低系统对外界响应效率,而且线程与进程本身也更容易进入假死状态。
好处: 很多程序员可能会考虑使用“线程池”或“连接池”。“线程池”旨在减少创建和销毁线程的频率,其维持一定合理数量的线程,并让空闲的线程重新承担新的执行任务。可以很好的降低系统开销。
弊端: “线程池”和“连接池”技术也只是在一定程度上缓解了频繁调用IO接口带来的资源占用。而且,所谓“池”始终有其上限,当请求大大超过上限时,“池”构成的昔日对外界的响应并不比没有池的时候效果好多少。所以使用“池“必须考虑其面临的响应规模,并根据响应规模调整“池”的大小。
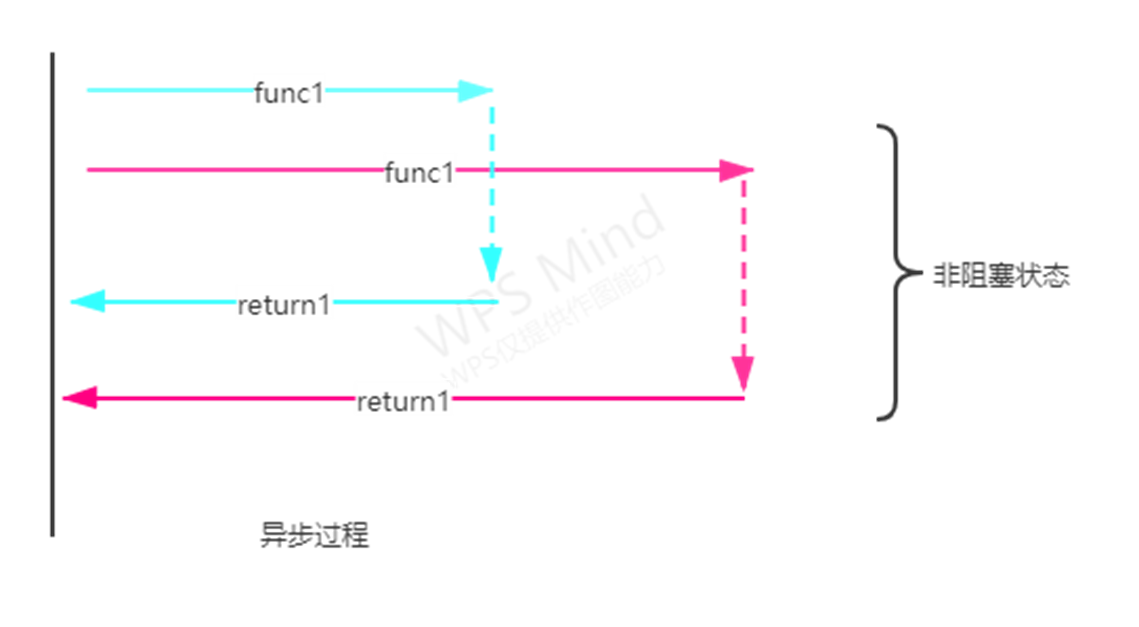
异步
cpu做完自己的事情后,可以先去干别的事情,让磁盘或者网络慢慢的去写入和加载,cpu只需要偶尔过来瞄一眼看看磁盘有没有做完,如果磁盘做完了事情,那么cpu就继续往下做事,如果磁盘还没做完,cpu就继续做别的事情,直到磁盘做完。
协程
1. 协程就相当于未来需要完成的任务,多个协程就是多个需要完成的任务,多个协程可以进一步封装到一个task对象中,task就是一个储存任务的盒子;
2. 此时,装在盒子里的任务并没有真正的运行,需要把它接入到一个监视器中使它运行,同时监视器还要持续不断的盯着盒子里的任务运行到了哪一步,这个持续不断的监视器就用一个循环对象loop来实现。
多任务异步协程
启用flask服务
from flask import Flask import time app = Flask(__name__) @app.route('/aaa') def index_aaa(): time.sleep(2) return 'aaa' @app.route('/bbb') def index_bbb(): time.sleep(2) return 'bbb' @app.route('/ccc') def index_ccc(): time.sleep(2) return 'ccc' if __name__ == "__main__": app.run(threaded=True) # 这表明Flask启动了多线程模式
多任务异步协程
async def get_page(url): print("正在下载:", url) response = await get(url) # aiohttp: 基于异步网络请求模块 print("下载完成:", response.text) tasks = [] for url in urls: c = get_page(url) task = asyncio.ensure_future(c) tasks.append(task) loop = asyncio.get_event_future(c) loop.run_until_complete(asyncio.wait(tasks))
import asyncio import time from requests_html import HTMLSession urls = [ 'http://127.0.0.1:5000/aaa', 'http://127.0.0.1:5000/bbb', 'http://127.0.0.1:5000/ccc' ] session = HTMLSession() async def get(url): return session.get(url)
使用aiohttp实现
async def get(url): session = aiohttp.ClientSession() response = await session.get(url) result = await response.text() await session.close() return result asunc def get_html(url): print("正在下载:", url) result = await get(url) print("下载成功!", result)
import asyncio import time from requests_html import HTMLSession import aiohttp # 使用模块中的ClientSession对象 ''' pip install aiohttp ''' urls = [ 'http://127.0.0.1:5000/aaa', 'http://127.0.0.1:5000/bbb', 'http://127.0.0.1:5000/ccc' ] # session = HTMLSession start = time.time()
aiomultiprocess实现
async def get(url): print("正在下载:", url) session = aiohttp.ClientSession() response = await session.get(url) result = await response.text() await session.close() print("下载完成!", url) return reslut async def request(): url = 'http://127.0.0.1:5000/aaa' urls = [url for _ in range(10)] async with Pool() as pool: result = await pool.map(get, urls) return result
练习例子
1. 多进程实现模式
import csv import multiprocessing import requests import time import decimal from bs4 import BeautifulSoup from multiprocessing import Pool from multiprocessing import Process start_time = time.time() # 开始时间 # 创建csv文件 with open("haitou2.csv", "w+", encoding="utf-8", newline="") as fp: write = csv.writer(fp) # 定义表头 headers = ("company", "address", "publish_time", "clicks",) write.writerow(headers) lock = multiprocessing.RLock() # 下载函数 def download(url): document = requests.get(url).text bs = BeautifulSoup(document, "html.parser") # 获取所有的tr节点 tr_list = bs.select("#w0 table.table.cxxt-table tbody tr") for tr in tr_list: # print(tr) # 获取公司 company = tr.select_one("div.text-success.company.pull-left").text # 举办地址 address = tr.select_one("td.text-ellipsis span").text publish_time = tr.select_one("td.cxxt-time").text # 发布时间 clicks = tr.select_one("td.cxxt-clicks") # 点击量 lock.acquire() with open("haitou2.csv", "a", encoding="utf-8", newline="") as fp: write = csv.writer(fp) write.writerow((company, address, publish_time, clicks)) lock.release() if __name__ == "__main__": # 创建线程池 # pool = Pool(processes=4) urls = [f"https://xjh.haitou.cc/xa/after/page-{page}" for page in range(1, 11)] pool = Pool(processes=4) pool.map(download, urls) pool.close() pool.join() end_time = time.time() # 结束时间 exec_time = decimal.Decimal(str(end_time)) - decimal.Decimal(str(start_time)) print("运行时间:", exec_time)
2. 多线程实现模式
import csv import requests import time import decimal from bs4 import BeautifulSoup from concurrent.futures import ThreadPoolExecutor # 创建线程池 """ 线程数 = CPU 核心数 * (1 + IO 耗时/ CPU 耗时) """ pool = ThreadPoolExecutor(12) # 创建线程池 start_time = time.time() # 开始时间 # 创建csv文件 with open("haitou2.csv", "w+", encoding="utf-8", newline="") as fp: write = csv.writer(fp) # 定义表头 headers = ("company", "address", "publish_time", "clicks",) write.writerow(headers) # 下载函数 def download(url): document = requests.get(url).text bs = BeautifulSoup(document, "html.parser") # 获取所有的tr节点 tr_list = bs.select("#w0 table.table.cxxt-table tbody tr") for tr in tr_list: # print(tr) # 获取公司 company = tr.select_one("div.text-success.company.pull-left").text # 举办地址 address = tr.select_one("td.text-ellipsis span").text publish_time = tr.select_one("td.cxxt-time").text # 发布时间 clicks = tr.select_one("td.cxxt-clicks") # 点击量 with open("haitou2.csv", "a", encoding="utf-8", newline="") as fp: write = csv.writer(fp) write.writerow((company, address, publish_time, clicks)) if __name__ == "__main__": # 创建线程池 # pool = Pool(processes=4) urls = [f"https://xjh.haitou.cc/xa/after/page-{page}" for page in range(1, 11)] for url in urls: pool.submit(download, url) pool.shutdown(True) # 执行完所有的任务之后才往下运行 end_time = time.time() # 结束时间 exec_time = decimal.Decimal(str(end_time)) - decimal.Decimal(str(start_time)) print("运行时间:", exec_time)
3. 异步实现模式
import aiohttp import asyncio import csv import requests import time import decimal from bs4 import BeautifulSoup start_time = time.time() # 开始时间 # 创建csv文件 with open("haitou2.csv", "w+", encoding="utf-8", newline="") as fp: write = csv.writer(fp) # 定义表头 headers = ("company", "address", "publish_time", "clicks",) write.writerow(headers) # 下载函数 async def download(url): # document = requests.get(url).text # 同步网络请求 # response = await aiohttp.ClientSession().get(url) # document = response.text() async with aiohttp.ClientSession() as session: # 异步网络请求 async with session.get(url) as response: document = await response.text() bs = BeautifulSoup(document, "html.parser") # 获取所有的tr节点 tr_list = bs.select("#w0 table.table.cxxt-table tbody tr") for tr in tr_list: # print(tr) # 获取公司 company = tr.select_one("div.text-success.company.pull-left").text # 举办地址 address = tr.select_one("td.text-ellipsis span").text publish_time = tr.select_one("td.cxxt-time").text # 发布时间 clicks = tr.select_one("td.cxxt-clicks") # 点击量 with open("haitou2.csv", "a", encoding="utf-8", newline="") as fp: write = csv.writer(fp) write.writerow((company, address, publish_time, clicks)) if __name__ == "__main__": # 创建线程池 # pool = Pool(processes=4) urls = [f"https://xjh.haitou.cc/xa/after/page-{page}" for page in range(1, 11)] tasks = [] for url in urls: tasks.append(asyncio.ensure_future(download(url))) # 创建一个事件池 loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks)) end_time = time.time() # 结束时间 exec_time = decimal.Decimal(str(end_time)) - decimal.Decimal(str(start_time)) print("运行时间:", exec_time)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理