


网络爬虫
1. Python基础语法学习(基础知识)
2. 对HTML页面的内容抓取(Crawl)
3. 对HTML页面的数据解析(Parse)
4. 动态HTML的处理/验证码的处理(针对反爬处理)
5. Scrapy框架以及scrapy-redis分布式策略(第三方框架)
6. 爬虫(Spider)、反爬虫(Anti-Spider)、反反爬虫(Anti-Anti-Spider)之间的斗争。
基本概念
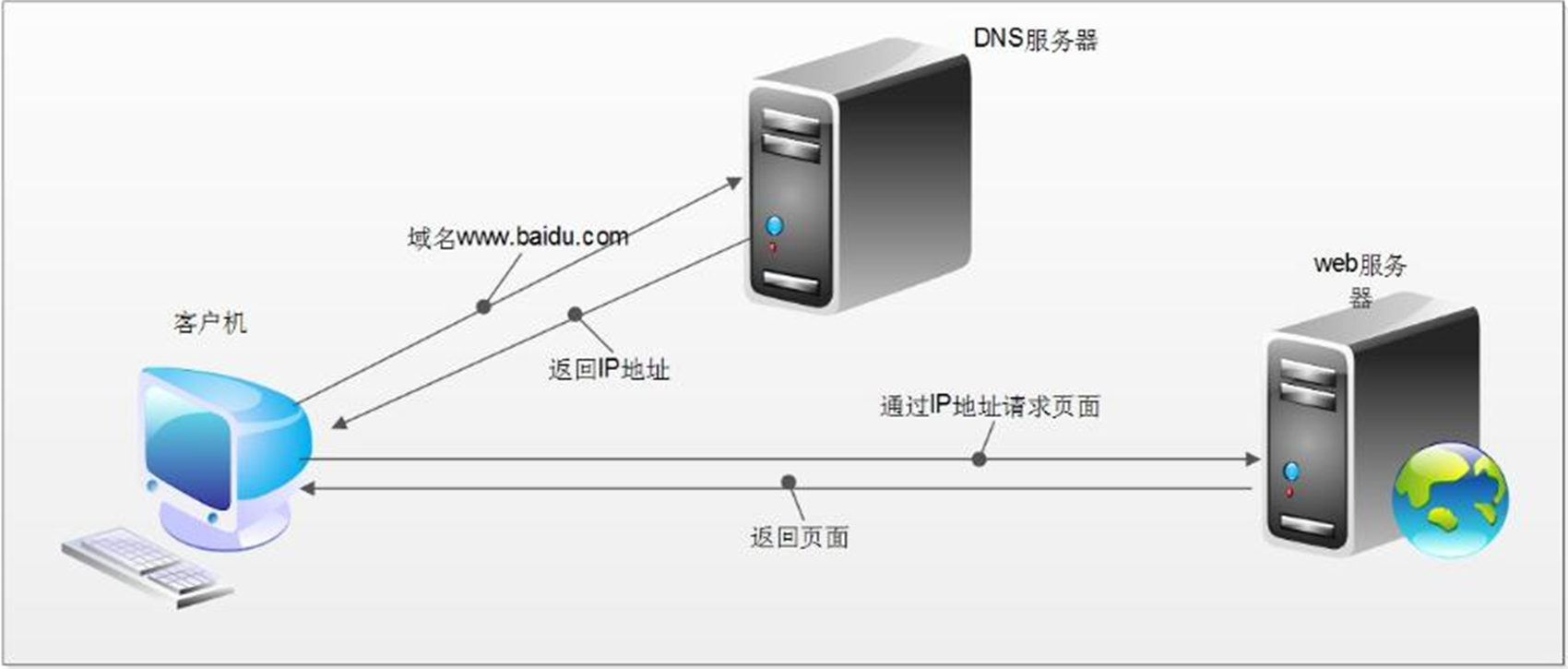
HTTP&HTTPS
客户端发起一个HTTP请求会携带请求的参数和报头,请求报文是严格规范的。HTTP请求主要分GET、POST两类。在经过三次握手四次挥手建立起稳定连接后,服务端返回完整的数据,包含状态行,响应正文等。状态码200-300 响应正常,常见200, 300-400 重定向,常见302, 400-500 被反爬 常见403/404, 500远程服务器本身的问题,常见503。
GET&POST
GET请求:GET是从服务器上获取制定页面信息,GET请求次数都显示在URL上。“Get”请求的参数是URL的一部分;
POST请求:POST是想服务器提交数据并获取页面信息。POST请求次数在请求体当中,信息长度没有限制而且以隐式的方式进行发送,“POST”请求的参数不在URL中,而在请求体中。
常用请求报文
Host:对应网址URL中的Web名称和端口号,用于制定被请求资源的Internet主机和端口号,通常属于URL的Host部分;
User-Agent:标识客户端身份的名称,通常页面会根据不同的User-Agent信息自动做出适配,甚至返回不同的响应内容;
Referer:表明产生请求的网页来自于哪个URL,用户是从该Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站来的等;
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现模拟登录。
常用响应报文
Content-Type:告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行heml解析。通常我们会看到有些网站是乱码的,往往就是服务端没有返回正确的编码。
Date:这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
Cache-Control:这个值告诉客户端,服务端不希望客户端缓存资源,在下次请求资源时,必须要重新请求服务器,不能从缓存副本中获取资源。
基本爬虫过程
1. 导入请求库(requests)以及对用的解析方式库(re、bs4、xpath);
2. 准备起始url(需要情况下,需要准备params/data:查询/登录参数,headers请求头信息等);
3. 起始的url发送请求(get、post);
4. 获取响应,返回HTML类型数据,并以文本形式处理;
5. 数据提取,即re、bs4、xpath规则等。
request请求
GET请求传参方式:
get_url = "http://httpbin.org/get?id=123" params = {"gender": "nan", "name": "dongli"} response = requests.get(get_url, params=params)
POST请求传参方式:
post_url = "http://httpbin.org/post" data = {"user": "dongli", "password": "123"} response = requests.post(post_url, data=data)
requests响应
response.encoding = 'utf-8'
print(response.text) # 响应内容的字符串形式
print(type(response.text)) # str
print(response.content) # 响应内容的二进制形式
print(type(response.status_code)) # 状态码
print(response.request) # request对象,请求对象
print(response.request.headers) # 请求头
print(response.request.url) # 请求地址
print(response.url) # 响应地址 获取重定向之后的地址
cookies = response.cookies # 获取响应之后的cookies
print(requests.utils.dict_from_cookiejar(cookies)) # 获取字典形式的cookies对象
1. 统一资源定位符:https://www.baidu.com
2. 协议 + 域名 + 资源路径 + 搜索字符串
3. https://www.baidu.com/s?wd=%E6%89%8B%E6%9C%BA&rsv_spt=1&rsv_iqid=0x80f093b10019518d&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=8&rsv_sug1=2&rsv_sug7=101&rsv_sug2=0&rsv_btype=i&prefixsug=%25E6%2589%258B%25E6%259C%25BA&rsp=6&inputT=1336&rsv_sug4=2578
4. 资源路径:域名之后,?之前
5. 关键字 + “=” + 值 wd=手机
6. ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=8&rsv_sug1=2&rsv_sug7=101&rsv_sug2=0&rsv_btype=i&prefixsug=%25E6%2589%258B%25E6%259C%25BA&rsp=6&inputT=1336&rsv_sug4=2578
7. wd = 手机
8. 浏览器所呈现的页面不是由一个请求构造而成
9. 静动态请求分析
10. 静态请求:网址导航栏输入的网址+html文件里面各种链接
11. javascript 原生的通信架构 XMLHttpRequest | Fetch | jauery
12. 网站首页:https://www.baidu.com ------> 网站首页
13.
14. 请求行 + 报头 +请求报文
15. POST
16. 静态请求 get
17. 状态码200-300 响应正常 300-400 重定向 400-5-- 被反爬 500远程服务器本身的问题
18. ==========》请求报头 《==========
19. 1 user-agent 用户代理 写死的,不会变化的
20. 2 cookie 身份标识符 反爬的一种手段
21. 3 referer 同一个域名下哪一个页面跳转过来的
22. 4 content-type 请求报文的类型
23.
24. 反爬手段 报头--cookie referer 响应报文-js
25. cookie 10
26. 远程服务器到底有没有做反爬效验
27. fiddler模拟请求的原理:解析复制并发送浏览器发送请求包


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程