


爬虫实践02 | xpath爬取某大学新闻网站
完整源代码:
#2022-03-01 xpath爬取某大学新闻网站 import requests from lxml import etree import time for i in range(95):#一共有95页 headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'} url='http://journal.whu.edu.cn/news/index/page/{}'.format(i) response=requests.get(url=url,headers=headers).text html=etree.HTML(response) lis=html.xpath('/html/body/div[3]/div/div/ul/li')#拿到所有的li for li in lis: title=li.xpath('./div[2]/h4/a/text()')[0]#获取标题 dt=li.xpath('./div[2]/div[2]/text()')[0]#获取日期 href=li.xpath('./div[2]/h4/a/@href')[0]#获取页面链接 href2='http://journal.whu.edu.cn/news'+href#拼接起来 print(title,dt,href2) time.sleep(2)#休息一下,避免频繁访问 with open(r"wunews.txt","a",encoding="utf-8") as f: #使用with open()新建对象f ,a 表示追加, f.write("{},{},{}".format(title,dt,href2)) #将列表中的数据循环写入到文本文件中 f.write("\n")#换行
分析:
1、访问网站信息
url=“http://journal.whu.edu.cn/news”
import requests headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'} url='http://journal.whu.edu.cn/news' response=requests.get(url=url,headers=headers) print(response.text)
2、解析数据,拿到所有li标签
import requests from lxml import etree headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'} url='http://journal.whu.edu.cn/news' response=requests.get(url=url,headers=headers).text html=etree.HTML(response) lis=html.xpath('/html/body/div[3]/div/div/ul/li')#拿到所有的li print(len(lis))
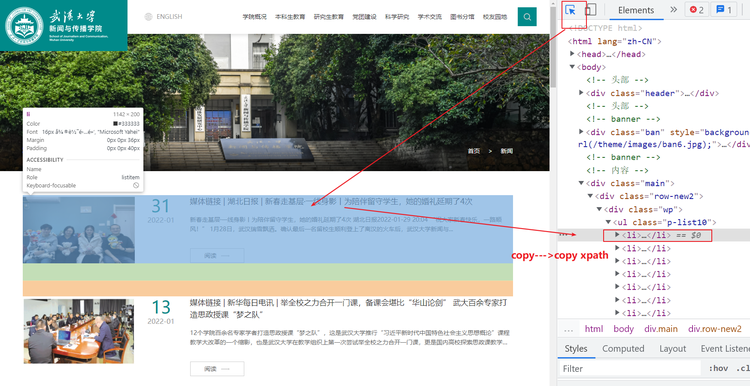
copy得到的xpath是:/html/body/div[3]/div/div/ul/li[1],需要的是所有的li,所以把[1]去掉
3、找到单个li,并查找所有需要的字段
import requests from lxml import etree import time headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'} url='http://journal.whu.edu.cn/news' response=requests.get(url=url,headers=headers).text html=etree.HTML(response) lis=html.xpath('/html/body/div[3]/div/div/ul/li')#拿到所有的li for li in lis: title=li.xpath('./div[2]/h4/a/text()')[0]#获取标题,获取的列表,列表里面只有一个元素,所以用[0] dt=li.xpath('./div[2]/div[2]/text()')[0]#获取日期 href=li.xpath('./div[2]/h4/a/@href')[0]#获取页面链接 href2='http://journal.whu.edu.cn/news'+href#拼接起来 print(title,dt,href2) time.sleep(2)
输出结果为:

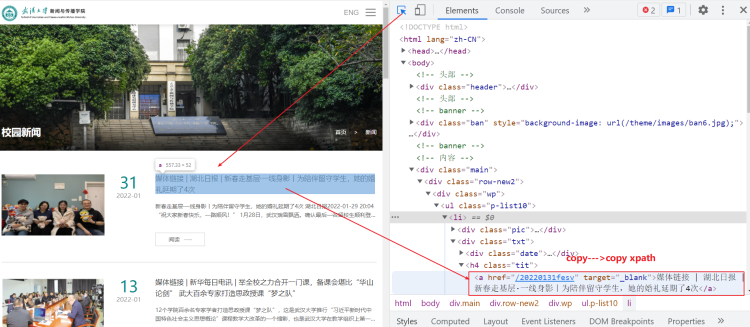
其他字段也是一样的方法:点击按钮,在网页中点击你想查找的部分,在Elements对应代码中点击右键,Copy->Copy Xpath
4、保存数据
import requests from lxml import etree import time for i in range(95):#一共有95页 headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'} url='http://journal.whu.edu.cn/news/index/page/{}'.format(i) response=requests.get(url=url,headers=headers).text html=etree.HTML(response) lis=html.xpath('/html/body/div[3]/div/div/ul/li')#拿到所有的li for li in lis: title=li.xpath('./div[2]/h4/a/text()')[0]#获取标题 dt=li.xpath('./div[2]/div[2]/text()')[0]#获取日期 href=li.xpath('./div[2]/h4/a/@href')[0]#获取页面链接 href2='http://journal.whu.edu.cn/news'+href#拼接起来 print(title,dt,href2) time.sleep(2)#休息一下,避免频繁访问 with open(r"wunews.txt","a",encoding="utf-8") as f: #使用with open()新建对象f ,a 表示追加, f.write("{},{},{}".format(title,dt,href2)) #将列表中的数据循环写入到文本文件中 f.write("\n")#换行
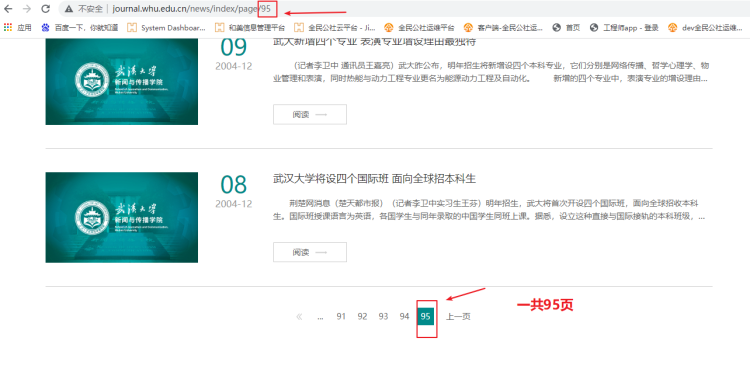
1、分析网站url可得到,每一页就是一个page,page1、2、3、、、95 一共有95页,所以用for循环来保存每一页数据:
2、用with open来打开一个对象文件
5、爬取完成
注意:
1、这种最简单的访问方式,很容易导致ip被封,请谨慎执行!
(执行3-5次,好像没啥问题,执行多了,就封了。。。)
2、可以尝试使用selenium方式来访问
