
论文笔记-基于代码属性图和Bi-GRU的软件脆弱性检测方法
一.摘要
提出了一种基于代码属性图和Bi-GRU的软件脆弱性检测方法。该方法通过从函数的代码属性图中提取出抽象语法树序列、控制流图序列作为函数表征的表征方式,减少代码表征过程中的信息的损失,并通过选取Bi-GRU来构建特征提取模型,提高对脆弱性代码的特征提取能力。实验结果表明,与以抽象语法树为表征方式的方法相比,该方法最大可提高35%的精确率和22%的召回率,可改善面向多个软件源代码混合的真实数据集的脆弱性检测效果,有效降低误报率和漏报率。
二.本文贡献
- 提出了一种基于代码属性图的软件脆弱性智能检测方法(vulnerability detection based on code property graph,VDCPG),该方法基于代码属性图对源代码进行表征,并根据在
LibTIFF数据集上的实验结果选择基于Bi-GRU的特征提取模型对表征向量进行特征提取,降低了不同项目编码风格差异对脆弱性检测效果的影响。 - 提出了一种基于代码属性图的表征方式,利用从函 数的代码属性图中提取的抽象语法树序列和控制流图序列对函数进行表征,以减少代码表征过程中的语法和语义信息的损失,提高表征能力。
- 在特征提取阶段,基于
Bi-GRU和Bi-LSTM(bi-directional long short-term memory)构建多个提取模型。通过实验发现,与基于Bi-LSTM构建的特征提取模型相比,利用Bi-GRU构建的特征提取模型最大可提高10%的精确率和6%的召回率。
三.整体架构

本方法通过3个步骤对待测软件进行脆弱性检测:
- 代码表征阶段。利用
Joern根据从源代码中生成代码属性图,并提取代码属性图中的信息作为函数的表征。 - 特征提取阶段。利用基于
Bi-GRU的特征提取模型提取函数表征中的脆弱性特征,获得函数的特征向量。 - 脆弱性检测阶段。利用随机森林模型学习函数特征向量中的脆弱性特征,以此进行脆弱性检测。
四.代码表征

源码示例:
int fun1(int x)
{
int y = test2(x);
for(int i = 0, i < 5, i++)
{
if (i == 3)
{
printf(i);
return y;
}
}
return (x + y);
}
-
通过
Joern工具生成代码属性图,并存储为Json格式(fun1函数的代码属性图的Json表示)。
-
从代码属性图中提取抽象语法树
(AST)序列以及控制流图(CFG)序列,替换代码中的所有字符串为"str"。 -
将控制流序列和抽象语法树序列合并得到文本型向量(称为
ACS,abstract syntax tree and control flow graph sequence),可唯一标识fun1函数。#抽象语法树序列: [METHOD, fun1, PARAM, int, x, ...] #控制流图序列: [METHOD, fun1, test2, test2(x), <operator>.assignment, y, =, test2, (, x, ), ...] #文本型向量ACS ACS = [METHOD, fun1, PARAM, int, x, ...] + [METHOD, fun1, test2, test2(x), <operator>.assignment, y, =, test2, (, x, ), ...] -
通过
keras分词器Tokenizer将ACS(METHOD, fun1, PARAM, int, x, ...)转为数值型向量(1,2,25,...),并统一向量长度(长度大于L,向量末端进行截断;长度小于L,向量末端用0来填充)。 -
利用所有函数的文本型向量组成的语料库对
Word2vec模型进行训练,得到映射集。利用映射集将向量中的每个元素转换为N维词向量,当元素没有对应的词向量时,使用全零的N维向量作为当前元素的词向量。
五.特征提取和脆弱性检测
分别使用BIGRU和随机森林进行特征提取和脆弱性检测。
六.实验结果
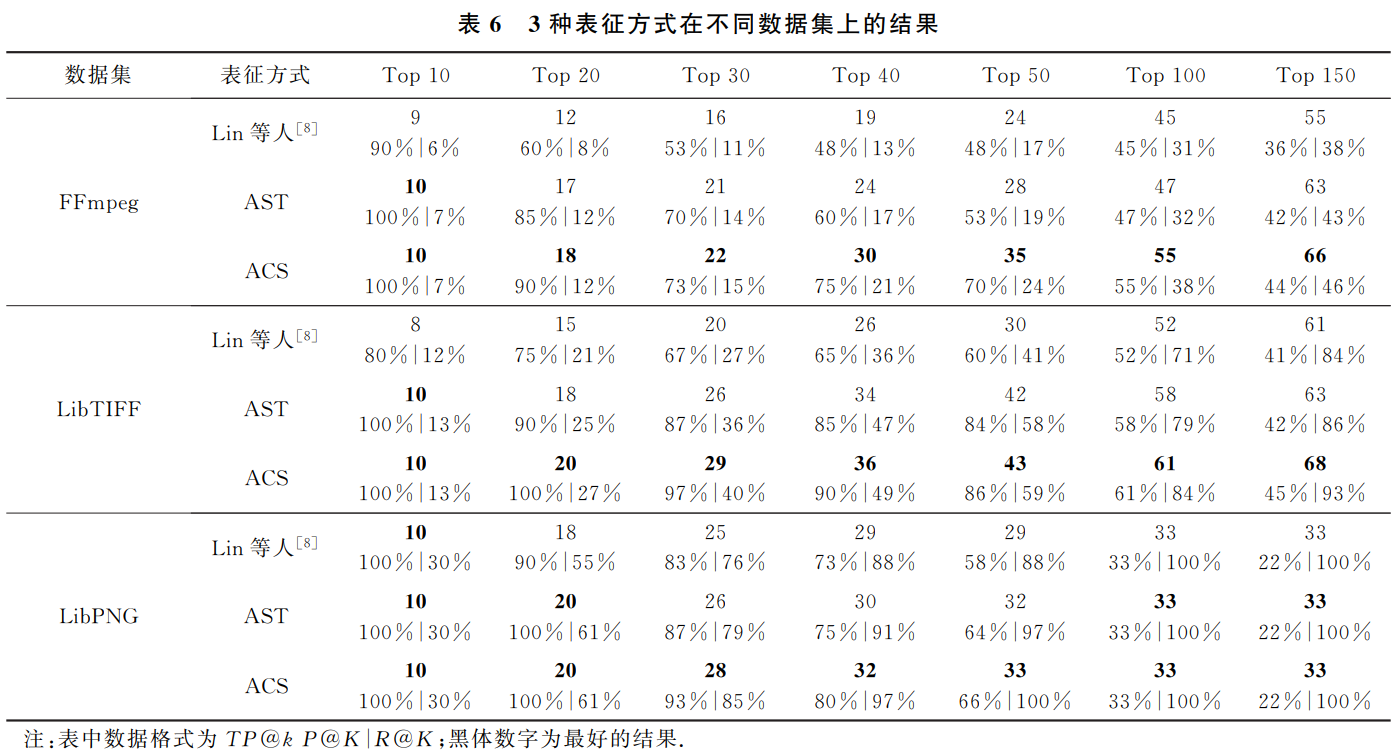
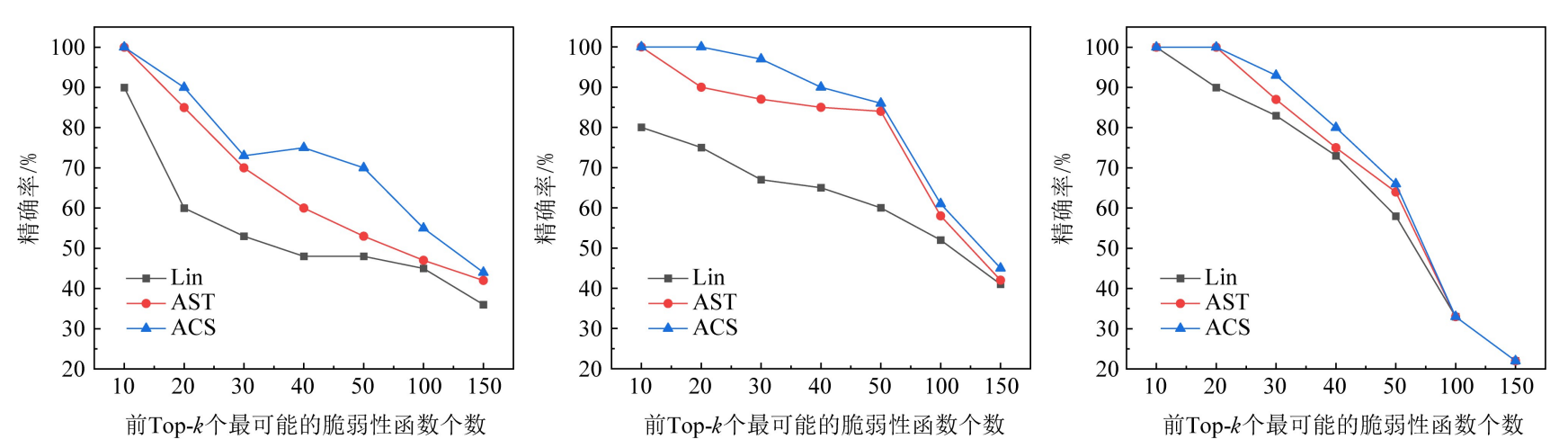
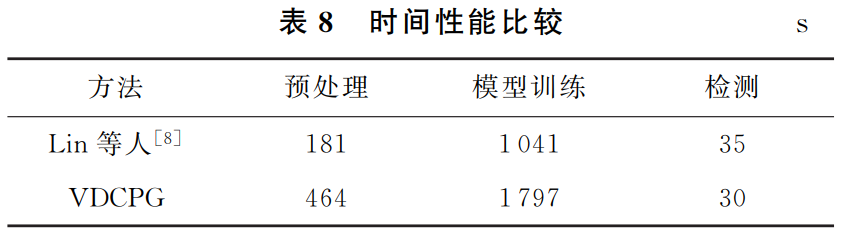


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?