
基于BiLSTM 模型的漏洞检测
一.摘要
首先从源代码中提取方法体,形成方法集;为方法集中的每个方法构建抽象语法树,借助抽象语法树抽取方法中的语句,形成语句集;替换语句集中程序员自定义的变量名、方法名及字符串,并为每条语句分配一个独立的节点编号,形成节点集。其次,运用数据流和控制流分析提取节点间的数据依赖和控制依赖关系。然后,将从方法体中提取的节点集、节点间的数据依赖关系以及控制依赖关系组合成方法对应的特征表示,并运用one-hot编码进一步将其处理为特征矩阵。最后,为每个矩阵贴上是否含有漏洞的标签以生成训练样本,并利用神经网络训练出相应的漏洞分类模型。为了更好地学习序列的上下文信息,选取BiLSTM神经网络,并在其上增加了Attention层,以进一步提升模型性能。漏洞检测结果的精确率和召回率分别达到了95.3%和93.5%。
二.主要贡献
- 结合抽象语法树分析、数据流分析和控制流分析技术,提出了一种融合代码结构、数据依赖和控制依赖信息的源代码特征提取方法。
- 结合深度神经网络技术和程序静态分析技术,提出了一种基于BiLSTM 模型的漏洞检测方法。
三.方法介绍
-
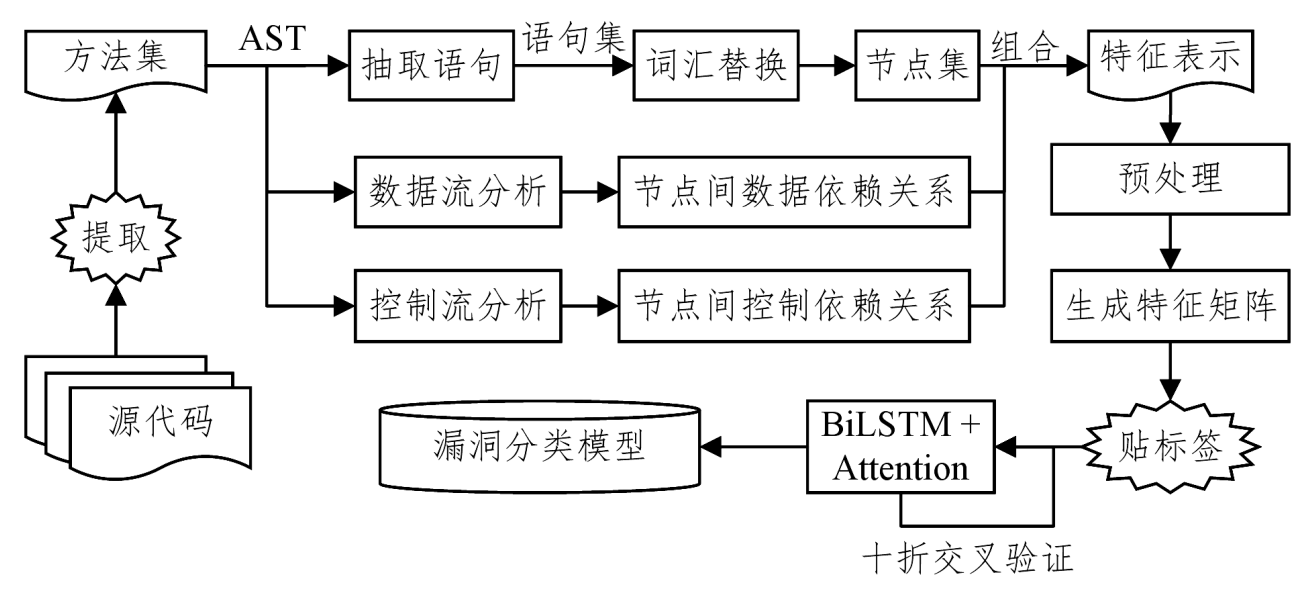
整体架构
从源代码中提取方法体,形成方法集;为方法集中的每个方法构建抽象语法树,借助抽象语法树抽取方法中的语句,形成语句集;替换语句集中程序员自定义的变量名、方法名及字符串,并为每条语句分配一个独立的节点编号,形成节点集。其次,运用数据流和控制流分析提取节点间的数据依赖和控制依赖关系。然后,将从方法体中提取的节点集、节点间数据依赖关系以及控制依赖关系组合成方法对应的特征表示,并运用one-hot编码进一步将其处理为特征矩阵。最后,为每个矩阵贴上是否含有漏洞的标签以生成训练样本,并增设Attention机制来辅助BiLSTM神经网络训练出更好的漏洞分类模型。
-
生成节点集
根据抽象语法树中的节点类型,筛选出用户自定义的变量名、方法名以及字符串,并对其做统一替换,以在将文本表示转换为向量时压缩词汇表的大小。例如,同样是bool类型的变量,程序员A命名为isTrue,程序员B命名为isRight,程序员C命名为exist等,上万个程序员可能产生数千个变量名,将这些自定义的变量名统一替换为某一标识符(如cid)之后,可以有效地减少词汇的数量,从而在将token展开为one-hot向量时降低向量的维度。同一方法体中的不同变量用cid_1和cid_2进行区分。最后,将每一个处理完的语句当作方法的一个节点,并为其分配一个独立的节点编号。
缓冲区漏洞示例源码:

生成语句集:

生成节点集:

-
生成特征矩阵
- 以分号为间隔,将节点集、节点间的数据依赖关系和节点间的控制依赖关系中所有语句组合而成的文本,即为方法体所对应的特征表示。
- 以空格为分隔符对文本做分词处理,即可将每个方法对应的特征表示转换为一个token序列。将token序列设置为固定长度400(长度超过400的约占总数量的1.77%,舍弃这极小部分样本对实验结果的影响可忽略不计)。
- 使用one-hot编码将代码token映射到向量空间,得到特征矩阵。
- 为防止特征矩阵向量维度过大(信息过于稀疏,不利于学习),引入embedding层对原始向量进行压缩。
四.实验结果
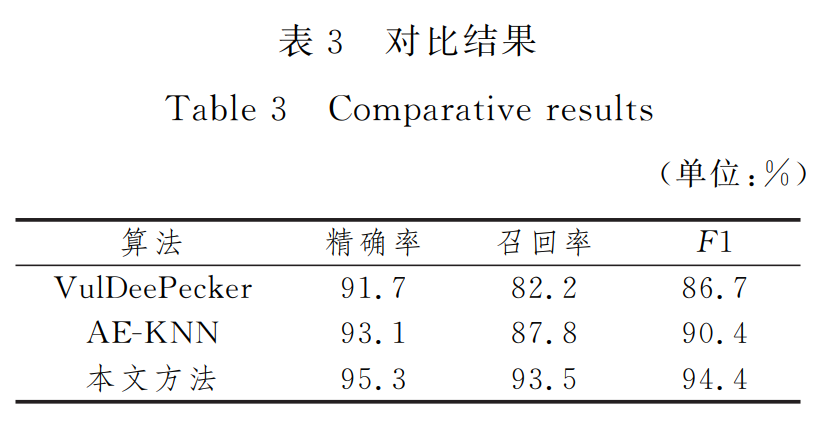
实验结果显示,本文方法的精确率和召回率最高达到了95.3%和93.5%,召回率与VulDeePecker相比更是高出了11个百分点。VulDeePecker在数据预处理时,主要提取源代码中的API和库方法调用,生成codegadgets。然而,该过程只针对API和库方法调用做提取,丢失了一些代码信息,导致其在召回率上的表现稍显逊色。
与 AEGKNN相比,本文方法在准确率和召回率上分别高出了约2和6个百分点。AEGKNN 提取方法的API序列并量化为特征向量,然后对特征向量进行聚类,提取每一类中异常值排序高的样本函数以匹配漏洞库。因此,该方法的表现很大程度上依赖于其制定的漏洞库,并没有彻底解放人力。相比之下,本文方法不需要领域专家的参与,能够自动化地从 漏洞样本中提取一些隐含的漏洞模式,省时省力,且具备良好的可扩展性。
五.总结
为检测软件中隐含的大量漏洞,本文将代码的语句以及语句间的数据流和控制流依赖抽象为一种特征表示,并采用基于Attention的BiLSTM神经网络学习且训练出相应的漏洞分类模型。实验在CWE-120,CWE-121和CWE-122这3种漏洞的小规模数据集上取得了95.3%的精确率和93.5%的召回率,优于现有的基于机器学习的漏洞检测方法。

