Hadoop综合大作业
本次作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
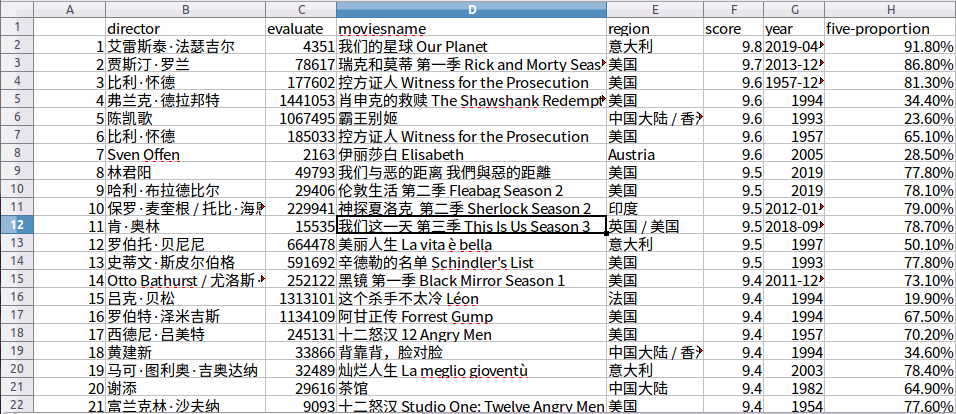
1.准备本次数据分析的数据(以下为爬虫大作业获取的CSV文件)
2.创建一个来运行案例的bigdatabase、dataset的文件夹

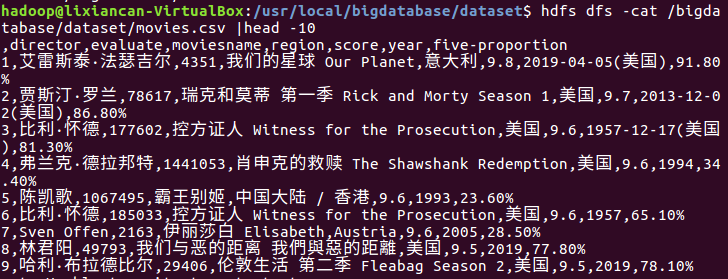
3.(1)将CSV文件上传到hdfs上

(2)查看文件中前10条信息,即可证明是否上传成功。
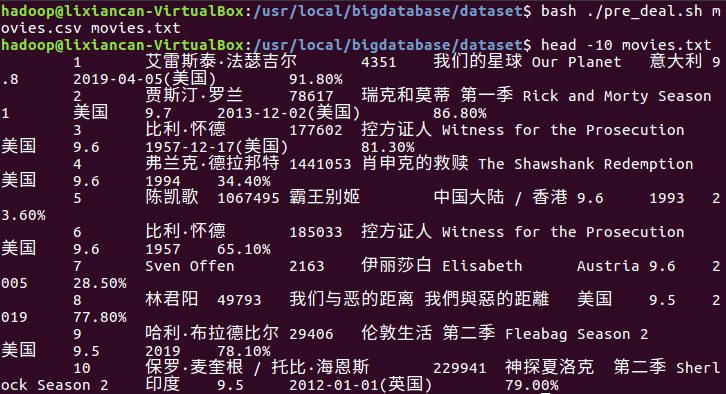
4.预处理文件,将CSV文件生成txt文件
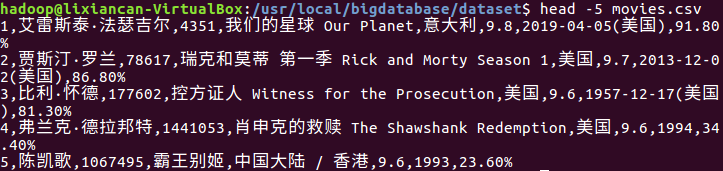
(1)先删除第一行字段:
(2)生成txt文件,并查看前十条数据验证是否成功
5.将movies.txt文件上传的hdfs上
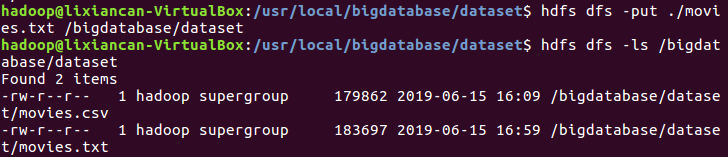
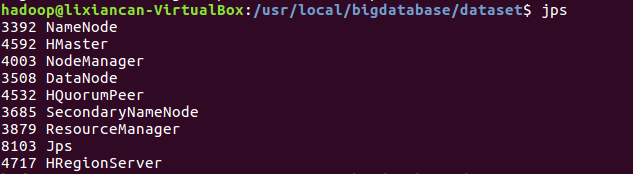
6.启动hdfs并启动MySQL服务

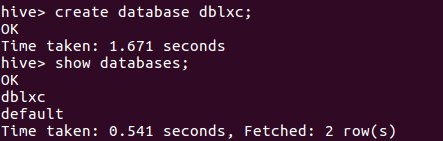
7.(1)在hive中创建数据库 dblxc:
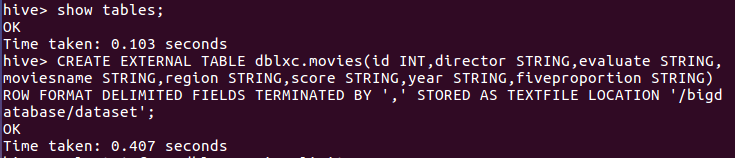
(2)把hdfs中“/bigdatabase/dataset”目录下的数据加载到了数据仓库的hive中的:

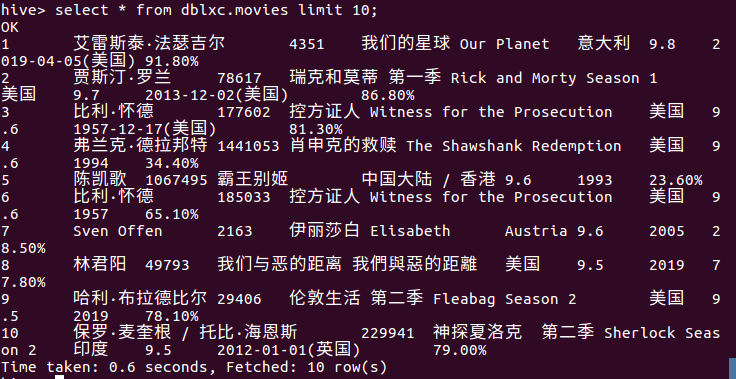
(3)在hive中查看数据,查找表的前10条记录:
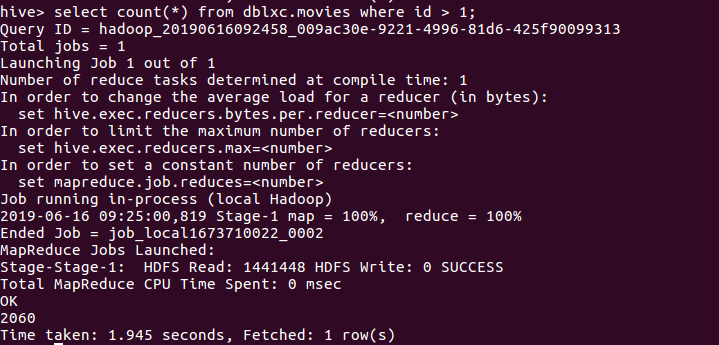
(4)在hive中查看数据,查找表的前10条记录(验证是否表数据录入成功)且查看本次2060条数据是否全部录入成功:
8.用hive进行数据分析
(1)查询豆瓣评分前20的电影的评价人数以及五星评分的比例
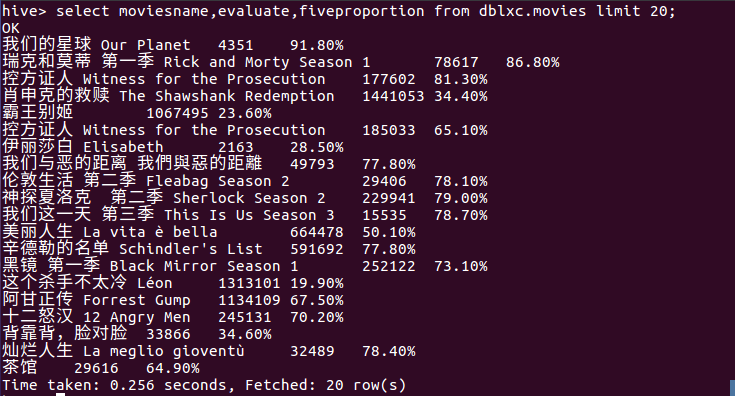
分析:豆瓣评分的高低主要与五星比例和评价人数有关,评价人数多且五星比例占80以上豆瓣评分就越高。
(2)查询豆瓣评分前20的电影中,那个国家占据最多:
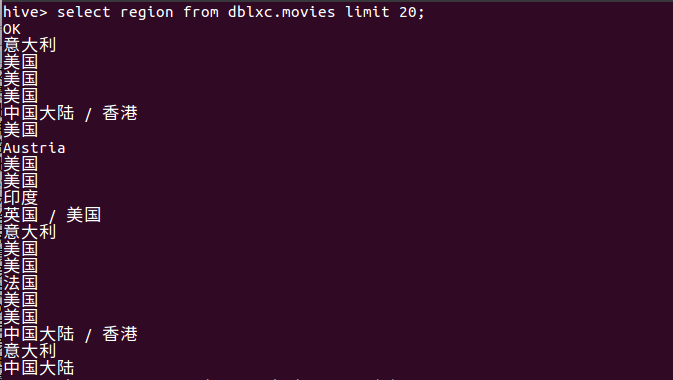
分析:从数据分析结果可看出,美国占据最大,占了差不多50%多,看来美国的影片还是很受人们的喜爱。
(3)查询豆瓣评分前20的电影中,哪个时间段的影片占据比例较大
分析:数据显示,人们还是喜欢90年代的电影多一点嘛。
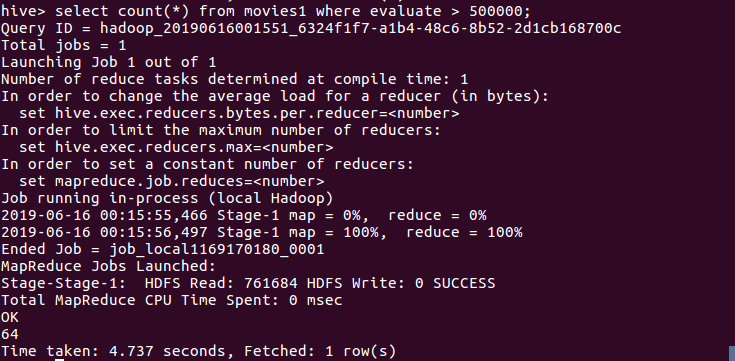
(4)查询所有电影2000条数据中,评价人数超过500000人的电影有多少。
(5)查询所有电影中,上映时间是2000后且豆瓣评分前20的电影。
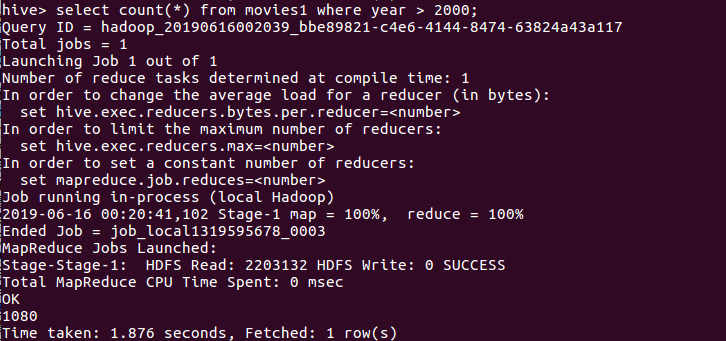
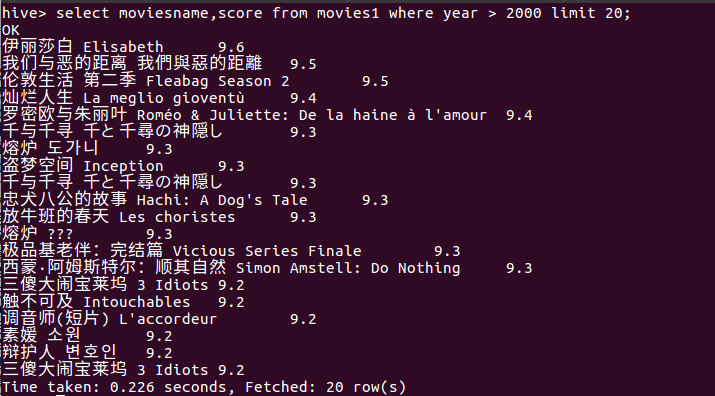
分析:数据显示,2000后的前20的电影评分都很高,都在9.2以上。
(6)查询豆瓣评分9以上且评价人数超过500000的数量。
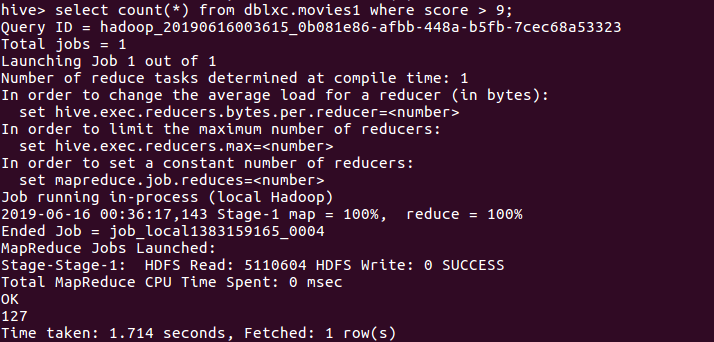
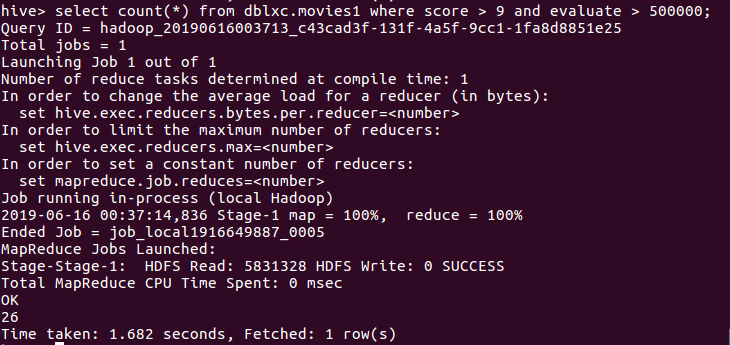
分析:豆瓣评分的高低,跟评价人数的多少没有正比的关系,可能与五星比例的多少有关。
(7)查询地点为美国的电影中,豆瓣分8.8以上的电影的数量。
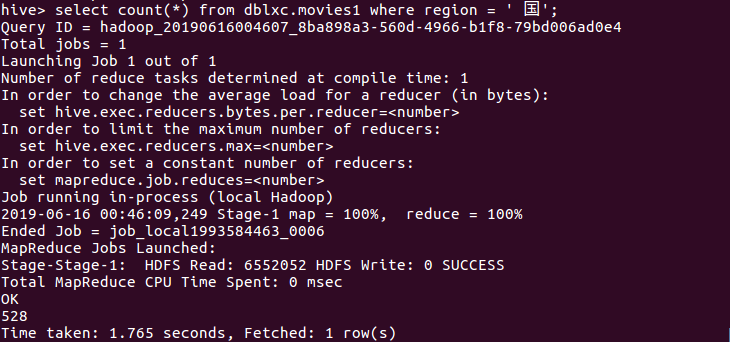
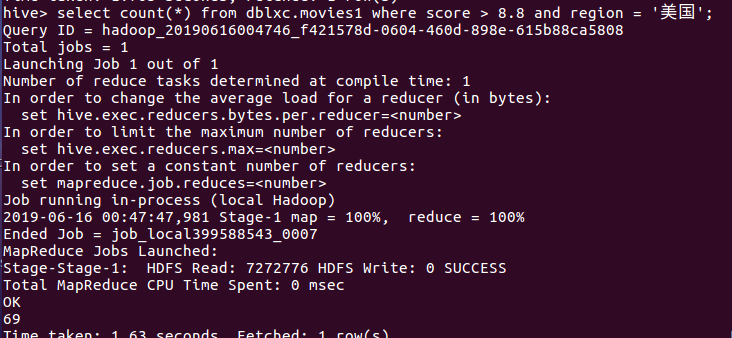
分析:数据显示,在526条美国电影中,有69部电影的豆瓣分在8.8以上。
(8)查询电影上映时间是1990以后的,以及豆瓣分在8.8以上的电影数量。
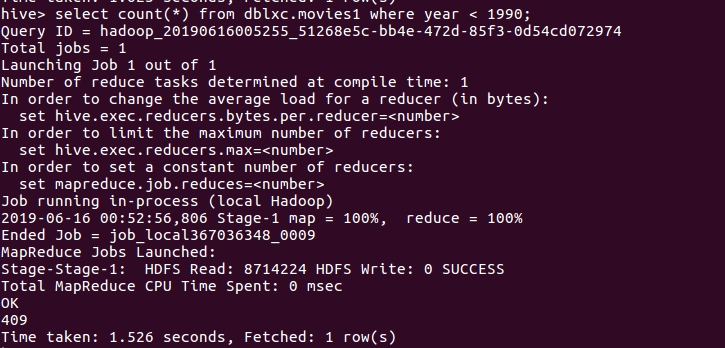
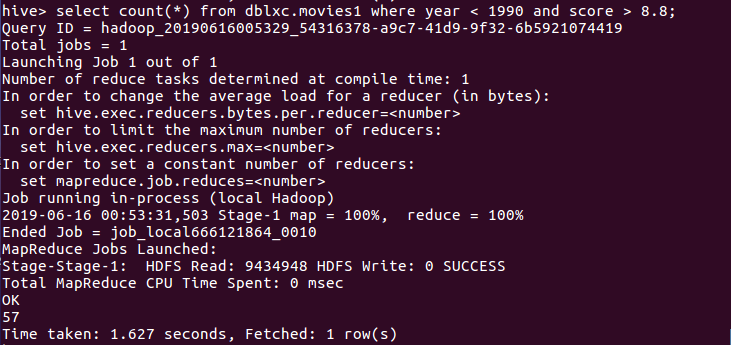
分析:在409部老电影中,只有57部8.8评分以上,看来也只有几步老剧深得人们喜爱啊。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号