分布式并行计算MapReduce
本次作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
(1)MapReduce的功能:
- 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算框架,并发运行在hadoop集群上。引入MapReduce框架后,开发人员可以将绝大部分的工作集中于业务逻辑上的开发,具体的计算只需要交给框架就可以。用于处理海量的数据分析计算工作,但目前因为性能问题,正在被spark替代。
(2)MapReduce的工作流程:
- MapReduce的完整运行流程:
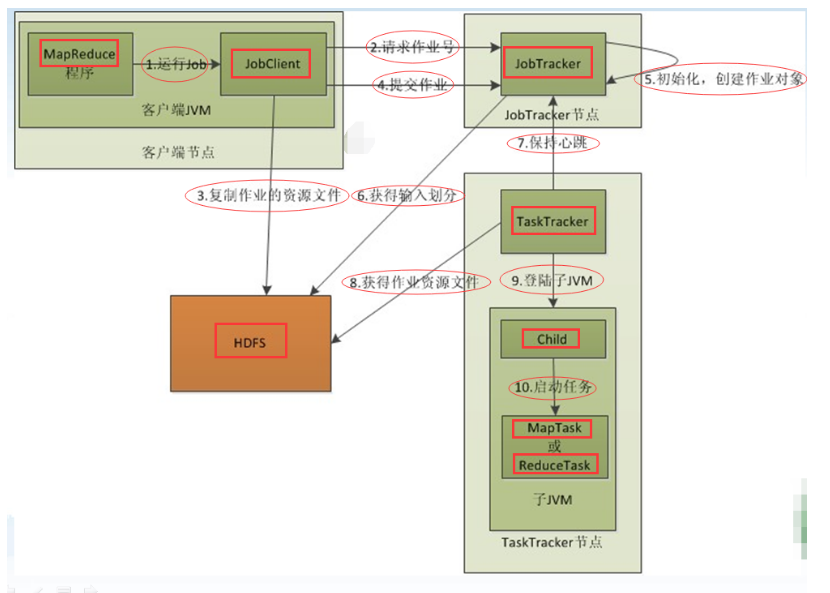
- 解析:
1 在客户端启动一个作业。
2 向JobTracker请求一个Job ID。
3 将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的jar文件、配置文件和客户端计算所得的计算划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。jar文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
4 JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度(这里是不是很像微机中的进程调度呢),当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同事将程序jar包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
5 TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带者很多信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobTracker查询状态时,它将得知任务已完成,便显示一条消息给用户。
(3)MapReduce的工作原理
- 一个Map简要的图,来说明MapReduce计算框架有哪些构成,Map --》Shuffle(包括sort copy merge)-->Reduce -->输出;Split 由我们的HDFS完成。
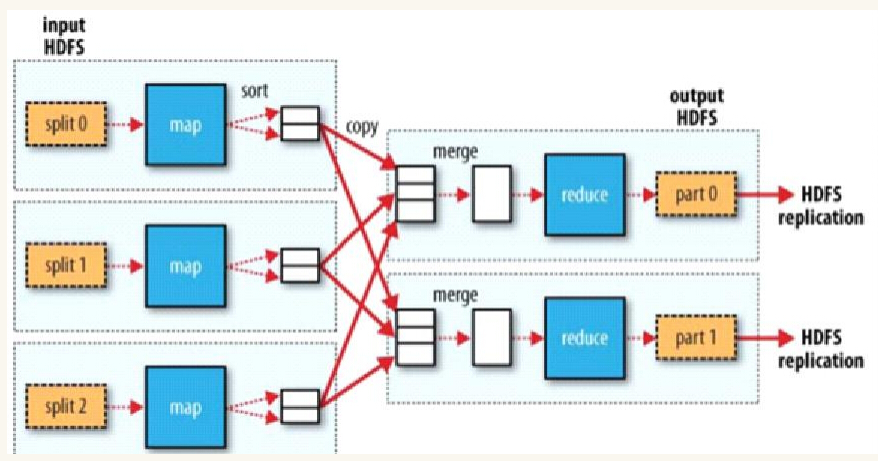
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc
- 查看是否已安装Python(默认状态下Ubuntu已安装)

在本地创建wc文件夹,并在该文件夹中创建lxc.txt文本文件。

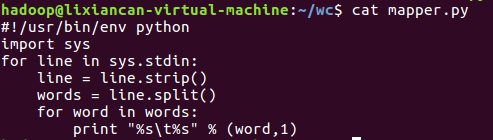
2)编写map函数和reduce函数,在本地运行测试通过
- 给mapper.py以及reducer.py加上相应的权限:

- 查看mapper.py以及reducer.py文件内容:
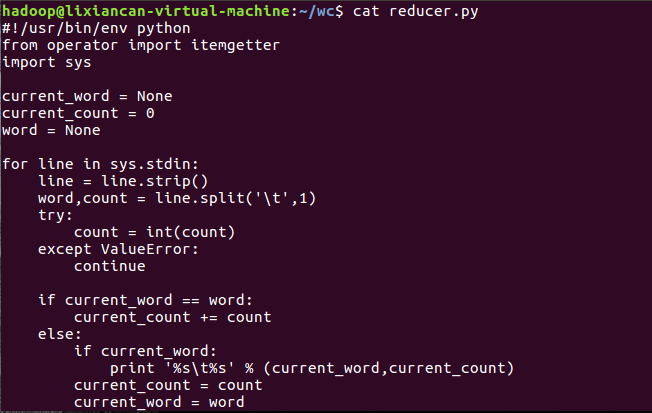
- 在本地上运行测试
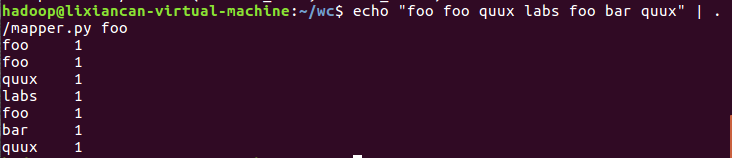

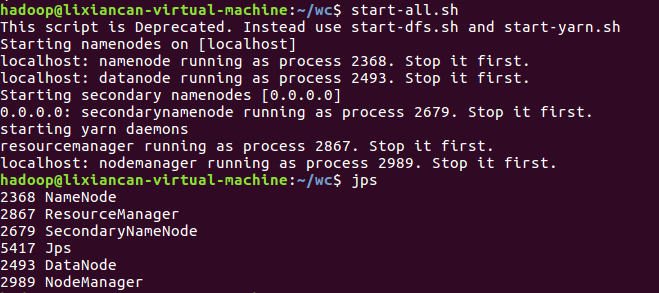
3)启动Hadoop:HDFS, JobTracker, TaskTracker
4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效
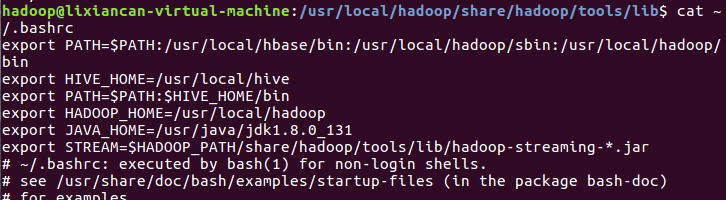
6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
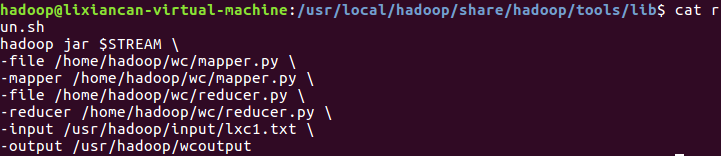
7)source run.sh来执行mapreduce


 浙公网安备 33010602011771号
浙公网安备 33010602011771号