
爬虫综合大作业
本次作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
作业要求:
一.把爬取的内容保存取MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
本次作业主要是爬取豆瓣网上前240部科幻电影。
URL:https://movie.douban.com/tag/#/?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1,%E7%A7%91%E5%B9%BB
完整源代码如下:
#!/usr/bin/env python # _*_ coding:utf-8 _* import logging import random import string import requests import time import pandas as pd from bs4 import BeautifulSoup from urllib import parse from setting import User_Agents class DoubanSpider(object): """豆瓣爬虫""" def __init__(self): # 基本的URL self.base_url = 'https://movie.douban.com/j/new_search_subjects?' self.full_url = self.base_url + '{query_params}' # 从User-Agents中选择一个User-Agent self.headers = {'User-Agent': random.choice(User_Agents)} # 影视形式(电影, 电视剧,综艺) self.form_tag = None # 类型 self.type_tag = None # 地区 self.countries_tag = None # 特色 self.genres_tag = None self.sort = 'U' # 排序方式,默认是T,表示热度 self.range = 0, 10 # 评分范围 self.playable = '' self.unwatched = '' # TODO def get_query_parameter(self): """获取用户输入信息""" # 获取tags参数 self.form_tag = input('请输入你想看的影视形式(电影|电视剧|综艺...):') self.type_tag = input('请输入你想看的影视类型(剧情|爱情|喜剧|科幻...):') self.countries_tag = input('请输入你想看的影视地区(大陆|美国|香港...):') self.genres_tag = input('请输入你想看的影视特色(经典|冷门佳片|黑帮...):') def get_default_query_parameter(self): """获取默认的查询参数""" # 获取 sort, range, playable, unwatched参数 self.range = input('请输入评分范围[0-10]:') self.sort = input('请输入排序顺序(热度:T, 时间:R, 评价:S),三选一:').upper() self.playable = input('请选择是否可播放(默认不可播放):') self.unwatched = input('请选择是否为我没看过(默认是没看过):') def encode_query_data(self): """对输入信息进行编码处理""" if not (self.form_tag and self.type_tag and self.countries_tag and self.genres_tag): all_tags = '' else: all_tags = [self.form_tag, self.type_tag, self.countries_tag, self.genres_tag] query_param = { 'sort': self.sort, 'range': self.range, 'tags': all_tags, 'playable': self.playable, 'unwatched': self.unwatched, } # string.printable:表示ASCII字符就不用编码了 query_params = parse.urlencode(query_param, safe=string.printable) # 去除查询参数中无效的字符 invalid_chars = ['(', ')', '[', ']', '+', '\''] for char in invalid_chars: if char in query_params: query_params = query_params.replace(char, '') # 把查询参数和base_url组合起来形成完整的url self.full_url = self.full_url.format(query_params=query_params) + '&start={start}' def download_movies(self, offset): """下载电影信息 :param offset: 控制一次请求的影视数量 :return resp:请求得到的响应体""" full_url = self.full_url.format(start=offset) resp = None try: resp = requests.get(full_url, headers=self.headers) except Exception as e: # print(resp) logging.error(e) return resp def get_movies(self, resp): """获取电影信息 :param resp: 响应体 :return movies:爬取到的电影信息""" if resp: if resp.status_code == 200: # 获取响应文件中的电影数据 movies = dict(resp.json()).get('data') id_list = [] film_title = [] if movies: for item in movies: id_list.append(item['url']) if movies: # 获取到电影了, # print(id_list) return id_list else: # 响应结果中没有电影了! # print('已超出范围!') return None else: # 没有获取到电影信息 return None def main(): """豆瓣电影爬虫程序入口""" # 1. 初始化工作,设置请求头等 spider = DoubanSpider() # 2. 与用户交互,获取用户输入的信息 spider.get_query_parameter() ret = input('是否需要设置排序方式,评分范围...(Y/N):') if ret.lower() == 'y': spider.get_default_query_parameter() # 3. 对信息进行编码处理,组合成有效的URL spider.encode_query_data() id = offset = 0 allMoviesInfo = [] for index in range(0,240,20): # 4. 下载影视信息 reps = spider.download_movies(offset) # 5.提取下载的信息 movies = spider.get_movies(reps) print(movies) # TODO offset += 20 id = offset # 控制访问速速 time.sleep(5) a =0; for item in movies: detail = {} res = requests.get(item) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') detail['电影名'] = soup.find_all('span',property='v:itemreviewed')[0].text detail['影片详情链接'] = item detail['豆瓣评分'] = soup.select('.rating_num')[0].text detail['评价人数'] = soup.find_all('span',property='v:votes')[0].text detail['导演'] = soup.select('.attrs')[0].text detail['上映时间'] = soup.find_all('span',property='v:initialReleaseDate')[0].get('content') detail['五星比例'] = soup.select('.rating_per')[0].text detail['四星比例'] = soup.select('.rating_per')[1].text detail['三星比例'] = soup.select('.rating_per')[2].text detail['两星比例'] = soup.select('.rating_per')[3].text detail['一星比例'] = soup.select('.rating_per')[4].text allMoviesInfo.append(detail) a = a+1; print(a) if (a >= 10): time.sleep(5) a = 0; # print(allMoviesInfo) df = pd.DataFrame(allMoviesInfo) df.to_csv(r'D:\office\douban.csv',encoding='utf-8') print("录入成功.") if __name__ == '__main__': main()
将从豆瓣上爬取的数据导入.CSV文件中
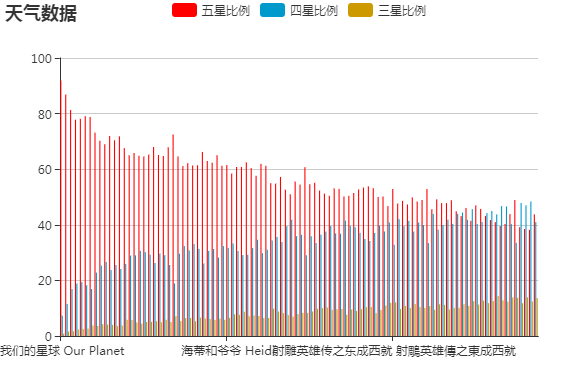
从表中可以看出这2000部电影中豆瓣分8以上的155部。其中“我们的地球”评分最高,大家都知道豆瓣电影评分都是有54321星的比例综合出来的。接下来,我们来看看这155部豆瓣分这么高,都是哪些星级最高。

接下来,我们对前一百步电影进行分析,如下图,可以看出豆瓣分高的,基本上都是五星四星三星占得比例较高。看来这豆瓣分高的电影还是不错的。
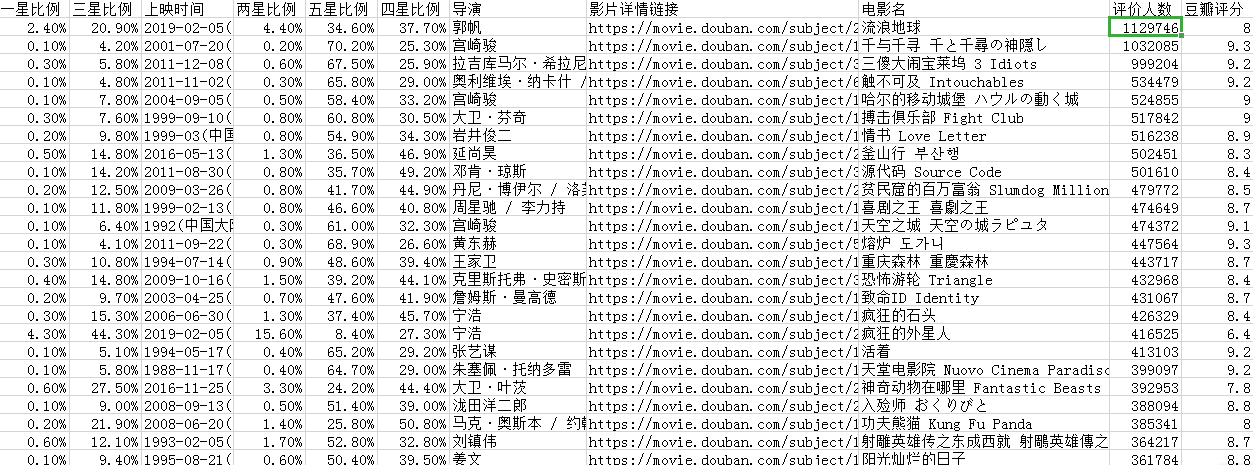
从.CSV文件可以看出评价人数跟豆瓣分的高低还是有很大的关系
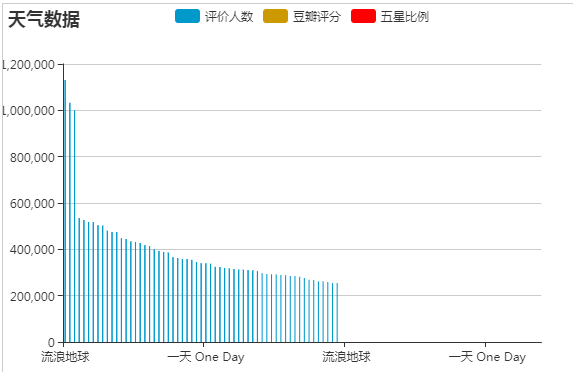
同样的,也是选出评价人数前100的电影看看其的豆瓣分是否与评价人数有关,如下图:
豆瓣分与评价人数及五星比例成正比关系。
接着,我们用词云分析这240部中哪位导演拍摄的电影比较多。如下图:
结果:可以看到宫崎骏这三个字,看来这位导演拍摄的电影还是很受人欢迎的嘛



