
理解爬虫原理
本次作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2851
1. 简单说明爬虫原理
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。也就是请求网站并提取数据的自动化程序。
2. 理解爬虫开发过程
1).简要说明浏览器工作原理
模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中。主要由以下步骤:
发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
保存数据
数据库(MySQL,Mongdb、Redis)
文件
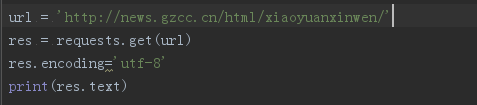
2).使用 requests 库抓取网站数据
代码如下:
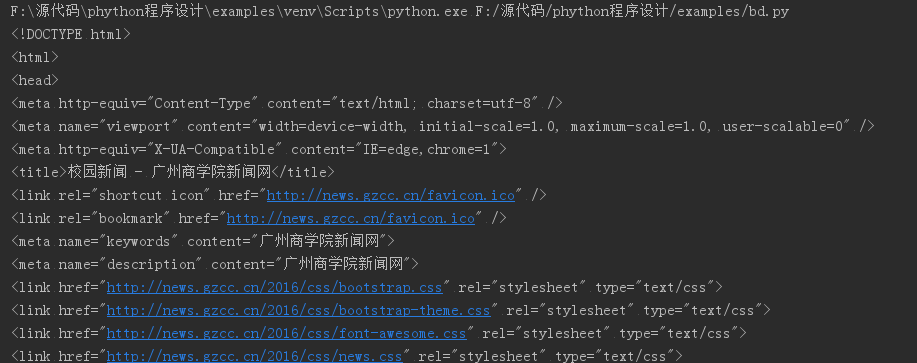
运行结果:
3).了解网页
写一个HTML界面代码如下:

运行界面如下:
4).使用 Beautiful Soup 解析网页
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
代码如下:
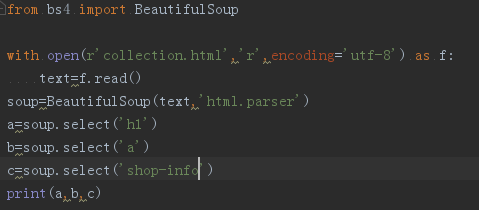
运行结果:

3.提取一篇校园新闻的标题、发布时间、发布单位
代码如下:
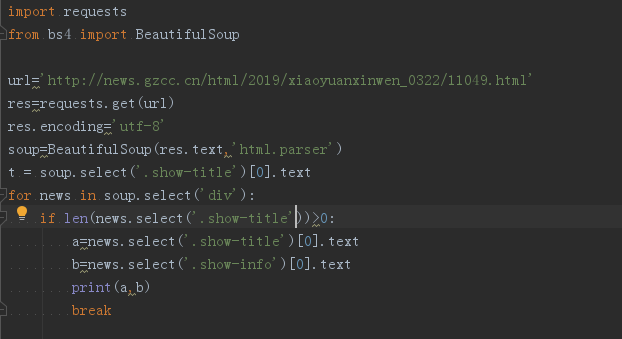
运行结果:



