

python+selenium遇到元素定位不到的问题,顺便记录一下自己这次的错误(报错selenium.common.exceptions.NoSuchElementException)
今天在写selenium一个发送邮件脚本时,遇到一些没有找到页面元素的错误。经过自己反复调试,找原因百度,终于解决了。简单总结一下吧,原因有以下几点:
一:Frame控件嵌套,.Frame/Iframe原因定位不到元素:
一般大家经常使用的邮箱算是frame嵌套的典型,通常注册登录都是在一个frame控件里面,而且标题正文可能是frame中嵌套iframe,接下里用我今天的脚本为例子(qq邮箱)
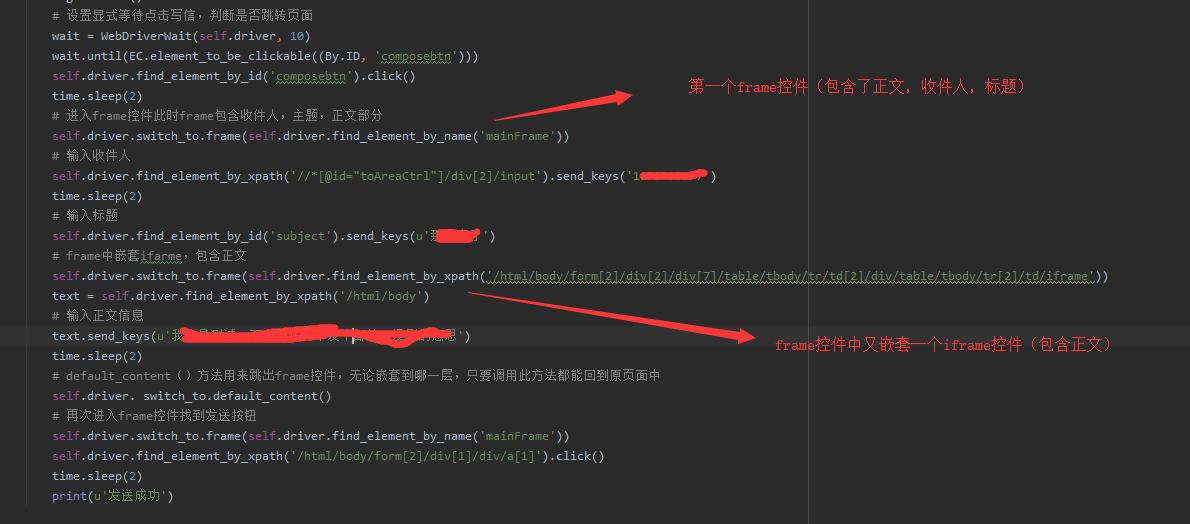
可以看到,如果我们要想找到收件人,标题就要先进到第一个Frame控件中,否则就会报错,但如果还要找到正文元素,就要进入第二个ifame控件中
可以使用 self.driver.switch_to.frame(传入id或者xpath值)方法进入Frame控件中。注(原来driver.switch_to_frame()这个方法在webdriver3.0中已经不支持了)
值得注意的一点的是:如果我此时我要点击发送按钮就需要先退出iframe控件,因为此时发送并不在正文所在的iframe控件当中,因此,无论你怎么定位,也定位不到。
此时就需要用到switch_to.default_content()这个方法。这个方法是无论你在哪一层级的frame控件中,只要调用此方法都会返回原始页面。如果我要找到发送按钮,就还要再次进入frame控件中去找
html界面结构如下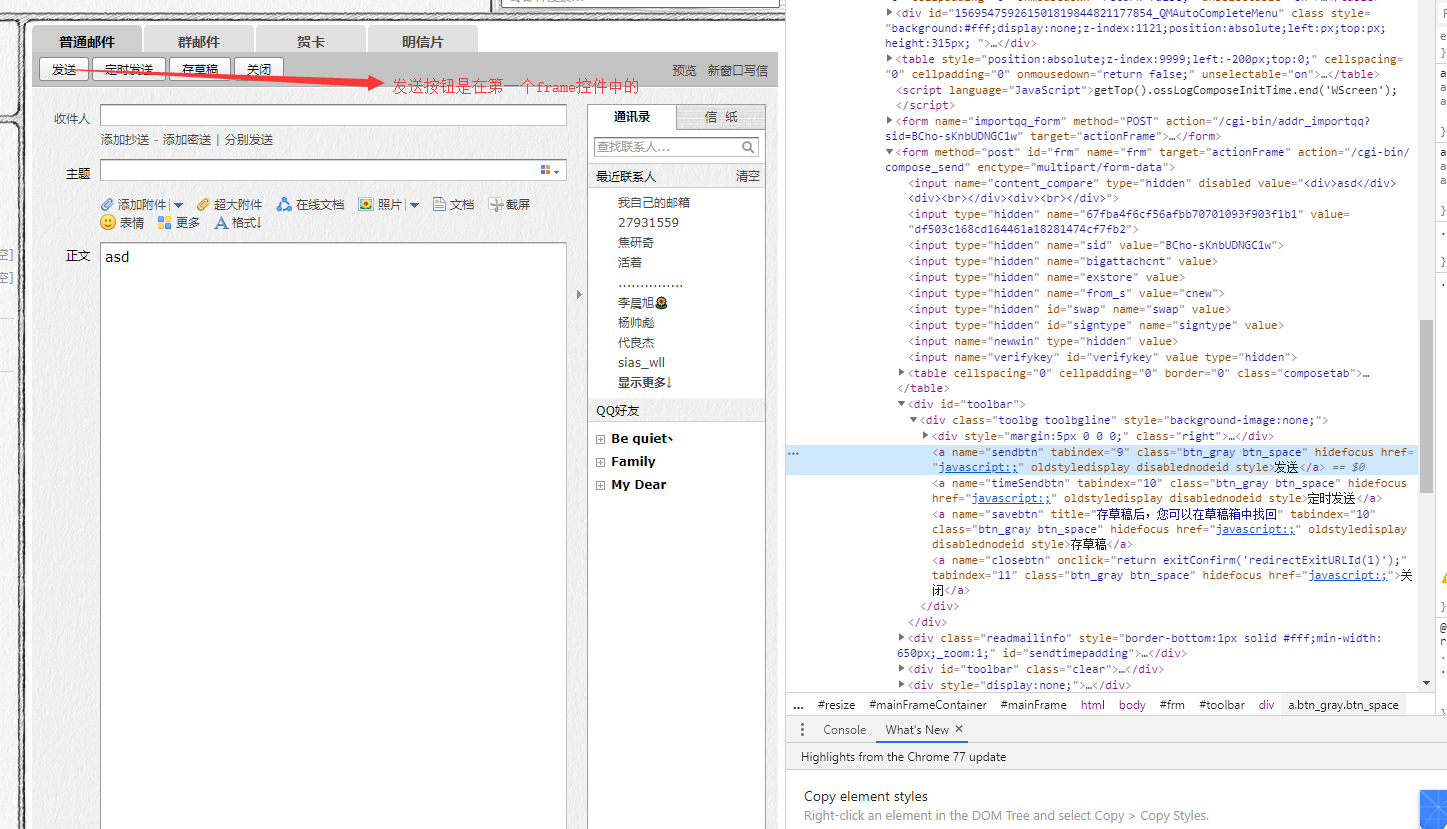
就是这个嵌套问题让我折腾一上午,总结一下吧:遇到多级Frame嵌套问题,一定要先仔细观察HTML的结构,别着急定位,观察好结构在往下进行,省的跟我一样浪费时间。
二:.页面还没有加载出来,就对页面上的元素进行的操作:
这种情况一般说来,可以设置等待,等待页面显示之后再操作,这与人手工操作的原理一样:
1设置等待时间;缺点是需要设置较长的等待时间,案例多了测试就很慢;
2设置等待页面的某个元素出现,比如一个文本、一个输入框都可以,一旦指定的元素出现,就可以做操作。
3在调试的过程中可以把页面的html代码打印出来,以便分析。
解决方案:
导入时间模块。(或者利用隐式等待或者显式等待)
import time
time.sleep(3)
三:利用xpath进行定位:
由于Xpath层级太复杂,容易犯错。虽然有人说xpath不好,但它真的功能很强大,可以找到父亲/祖先,这是其他方式都做不到的,如果遇到定位不到元素不妨试试xpath
解决方案:
1可以使用Firefox的firePath,复制xpath路径。该方式容易因为层级改变而需要重新编写过xpath路径,不建议使用,初学者可以先复制路径,然后尝试去修改它。
2提高下写xpath的水平。
这里推荐一篇文章吧:[selenium+python元素定位方法总结](http://https://www.cnblogs.com/yufeihlf/p/5717291.html)
该博文详细总结了Xpath的使用,多组合定位一般都能实现定位问题。
如何检验编写的Xpath是否正确?编写好Xpath路径,可以直接复制到搜狐浏览器的firebug查看html源码,通过Xpath搜索:如下红色框,若无报错,则说明编写的Xpath路径没错。
find_element_by_xpath("//input[@id='kw']")
(注:如果是动态元素,直接使用xpath进行定位)
四:不可见元素定位
如上百度登录代码,通过名称为tj_login查找的登录元素,有些是不可见的,所以加一个循环判断,找到可见元素(is_displayed())点击登录即可。
