IDEA配置Hadoop开发环境&编译运行WordCount程序
有关hadoop及java安装配置请见:https://www.cnblogs.com/lxc1910/p/11734477.html
1、新建Java project:
选择合适的jdk,如图所示:

将工程命名为WordCount。
2、添加WordCount类文件:
在src中添加新的Java类文件,类名为WordCount,代码如下:
1 import java.io.IOException; 2 3 import java.util.StringTokenizer; 4 5 import org.apache.hadoop.conf.Configuration; 6 7 import org.apache.hadoop.fs.Path; 8 9 import org.apache.hadoop.io.IntWritable; 10 11 import org.apache.hadoop.io.Text; 12 13 import org.apache.hadoop.mapreduce.Job; 14 15 import org.apache.hadoop.mapreduce.Mapper; 16 17 import org.apache.hadoop.mapreduce.Reducer; 18 19 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 20 21 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 22 23 import org.apache.hadoop.util.GenericOptionsParser; 24 25 public class WordCount { 26 public static class TokenizerMapper //定义Map类实现字符串分解 27 extends Mapper<Object, Text, Text, IntWritable> 28 { 29 private final static IntWritable one = new IntWritable(1); 30 private Text word = new Text(); 31 //实现map()函数 32 public void map(Object key, Text value, Context context) 33 throws IOException, InterruptedException 34 { //将字符串拆解成单词 35 StringTokenizer itr = new StringTokenizer(value.toString()); 36 while (itr.hasMoreTokens()) 37 { word.set(itr.nextToken()); //将分解后的一个单词写入word类 38 context.write(word, one); //收集<key, value> 39 } 40 } 41 } 42 43 //定义Reduce类规约同一key的value 44 public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> 45 { 46 private IntWritable result = new IntWritable(); 47 //实现reduce()函数 48 public void reduce(Text key, Iterable<IntWritable> values, Context context ) 49 throws IOException, InterruptedException 50 { 51 int sum = 0; 52 //遍历迭代values,得到同一key的所有value 53 for (IntWritable val : values) { sum += val.get(); } 54 result.set(sum); 55 //产生输出对<key, value> 56 context.write(key, result); 57 } 58 } 59 60 public static void main(String[] args) throws Exception 61 { //为任务设定配置文件 62 Configuration conf = new Configuration(); 63 //命令行参数 64 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 65 if (otherArgs.length != 2) 66 { System.err.println("Usage: wordcount <in> <out>"); 67 System.exit(2); 68 } 69 Job job = Job.getInstance(conf, "word count");//新建一个用户定义的Job 70 job.setJarByClass(WordCount.class); //设置执行任务的jar 71 job.setMapperClass(TokenizerMapper.class); //设置Mapper类 72 job.setCombinerClass(IntSumReducer.class); //设置Combine类 73 job.setReducerClass(IntSumReducer.class); //设置Reducer类 74 job.setOutputKeyClass(Text.class); //设置job输出的key 75 //设置job输出的value 76 job.setOutputValueClass(IntWritable.class); 77 //设置输入文件的路径 78 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); 79 //设置输出文件的路径 80 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); 81 //提交任务并等待任务完成 82 System.exit(job.waitForCompletion(true) ? 0 : 1); 83 } 84 85 }
3、添加依赖库:
点击 File -> Project Structure -> Modules,选择Dependencies,点击加号,添加以下依赖库:

4、编译生成JAR包:
点击 File -> Project Structure ->Artifacts,点击加号->JAR->from modules with dependencies,
Mainclass选择WordCount类:
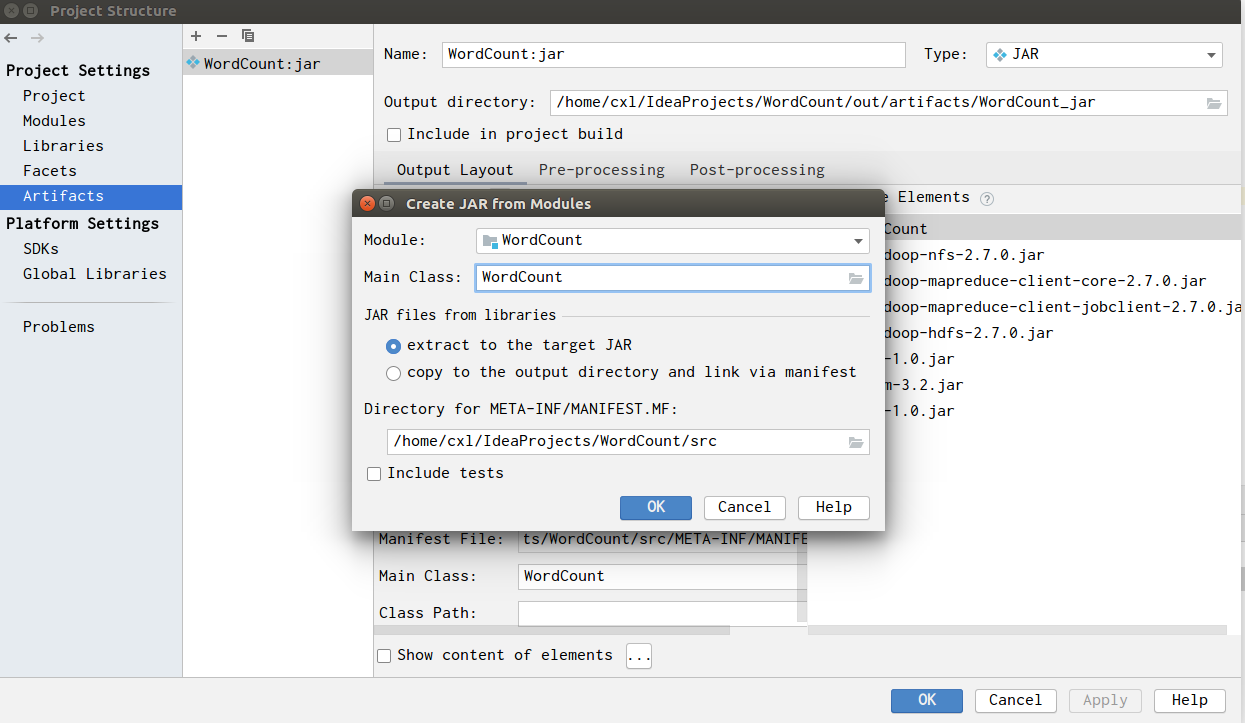
下面开始编译生成JAR包:
点击 build->build Artifacts->build,完成编译后,会发现多出一个目录output.
5、在hadoop系统中运行JAR包:
我之前在hadoop用户下安装了伪分布式的hadoop系统,因此首先把JAR包复制到hadoop用户目录下。
启动hadoop服务:(在hadoop安装目录的sbin文件夹下)
./start-all.sh
在hdfs下新建test-in文件夹,并放入file1.txt、file2.txt两个文件,
1 hadoop fs -mkdir test-in 2 hadoop fs -put file1.txt file2.txt test-in/
执行jar包:
1 hadoop jar WordCount.jar test-in test-out
因为之前生成JAR包时设置了主类,所以WordCount.jar后面不需要再加WordCount.
另外需要注意运行JAR包之前hdfs中不能有test-out文件夹。
6、查看运行结果
可通过http://localhost:50070/查看hadoop系统状况,
点击Utilities->Browse the file system即可查看hdfs文件系统:
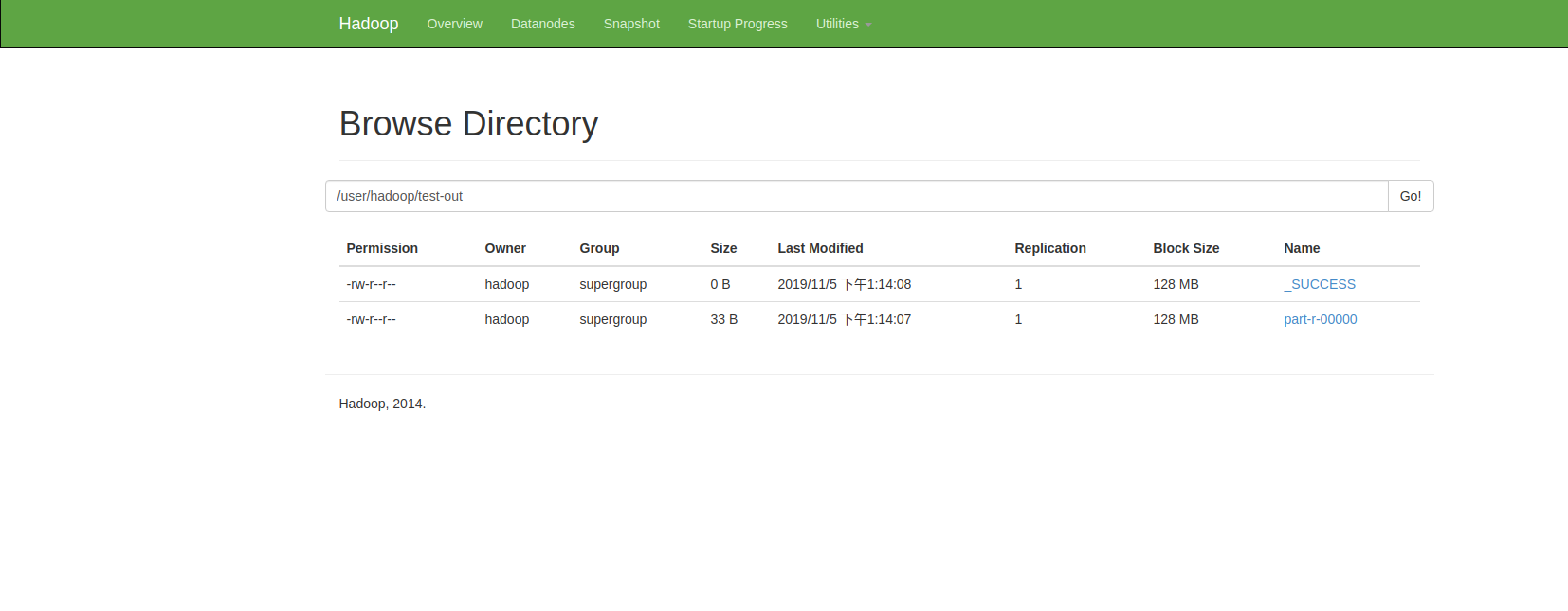
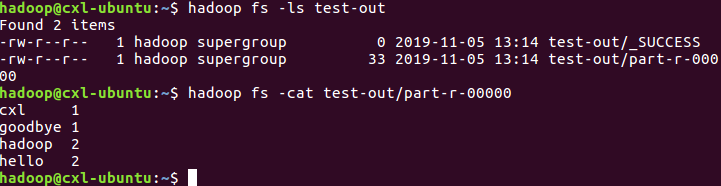
可以看到test-out文件下有输出文件,可通过命令:
1 hadoop fs -cat test-out/part-r-00000
查看文件输出情况:
7、参考
https://blog.csdn.net/chaoping315/article/details/78904970
