

Scrapy学习篇(三)之创建项目和Scrapy的安装
安装Scrapy
了解了Scrapy的框架和部分命令行之后,创建项目,开始使用之前,当然是安装Scrapy框架了。
关于Scrapy框架的安装,请参考:https://cuiqingcai.com/5421.html
创建项目
创建项目是爬取内容的第一步,之前已经讲过,Scrapy通过scrapy startproject <project_name>命令来在当前目录下创建一个新的项目。
下面我们创建一个爬取网址(http://quotes.toscrape.com/)的名言,作者和tags为例讲解。
scrapy startproject quotes #项目名称
scrapy genspider quotes quotes.com # quotes为爬虫名称,quotes.com为允许爬取的域名限制
其中quotes是你的项目的名字,可以自己定义。
其目录结构如下
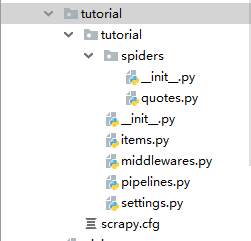
下面简单的讲解一下各目录/文件的作用:
- scrapy.cfg
项目的配置文件,带有这个文件的那个目录作为scrapy项目的根目录 - items.py
定义你所要抓取的字段 - pipelines.py
管道文件,当spider抓取到内容(item)以后,会被送到这里,这些信息(item)在这里会被清洗,去重,保存到文件或者数据库。 - middlewares.py
中间件,主要是对功能的拓展,你可以添加一些自定义的功能,比如添加随机user-agent, 添加proxy,cookies;当需要使用selenium时,也是在这里设置。 - settings.py
设置文件,用来设置爬虫的默认信息,相关功能开启与否,比如是否遵循robots协议,设置默认的headers,设置文件的路径,中间件的执行顺序等等。 - spiders/
在这个文件夹下面,编写你自定义的spider。
编写爬虫
编写spider文件
在项目中的spiders文件夹下面创建一个文件,命名为quotes.py我们将在这个文件里面编写我们的爬虫。先上代码再解释。
class QuotesSpider(scrapy.Spider): name = 'quotes' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/'] def parse(self, response): quotes = BeautifulSoup(response.text,'lxml') for quote in quotes.find_all(name = 'div',class_='quote'): item = QuoteItem() #使用items中定义的数据结构 for s in quote.find_all(name = 'span',class_='text'): item['text'] = s.text for s in quote.find_all(name= 'small',class_='author'): item['author'] = s.text for s in quote.find_all(name='div', class_='tags'): item['tags'] = s.text.replace('\n','').strip().replace(' ','') yield item nexts = quotes.find_all(name='li', class_='next') #获取下一页的地址 for next in nexts: n = next.find(name='a') url = 'http://quotes.toscrape.com/' + n['href'] yield scrapy.Request(url = url,callback = self.parse)
- 导入scrapy模块
- 定义一个spider类,继承自scrapy.Spider父类。
下面是三个重要的内容
- name: 用于区别Spider。 该名字必须是唯一的,不可以为不同的Spider设定相同的名字。这一点很重要。
- start_urls: 包含了Spider在启动时进行爬取的url列表。第一个被获取到的页面将是其中之一。即这是爬虫链接的起点,爬虫项目启动,便开始从这个链接爬取,后续的URL则从初始的URL获取到的数据中提取。
- parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
修改settings.py文件
将settings.py文件里面的下列内容修改如下,其余的内容不动。
ROBOTSTXT_OBEY = False #不遵循robots协议 #去掉下面的这个注释,以设置请求头信息,伪造浏览器headers,并手动添加一个user-agent,也可以在下载器中间件中设置更灵活的user-agent获取方法 DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', #user-agent新添加 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" }
编写Pipeline
我们将在pipeline文件中处理在spider中获取到的item,将其存储到mongodb数据库中。
class MongoPipeline(object): def __init__(self,mongo_url,mongo_db): self.mongo_url = mongo_url self.mongo_db = mongo_db @classmethod def from_crawler(cls,crawler): return cls( mongo_url=crawler.settings.get('MONGO_URL'), mongo_db = crawler.settings.get('MONGO_DB') ) def open_spider(self,spider): self.client = pymongo.MongoClient(self.mongo_url) self.db = self.client[self.mongo_db] def process_item(self,item, spider): name = item.__class__.__name__ self.db[name].insert(dict(item)) return item def close_spider(self,spider): self.client.close()
运行我们的爬虫项目
至此,项目必要的信息已经全部完成了,下面就是运行我们的爬虫项目
进入带有scrapy.cfg文件的那个目录,前面已经说过,这是项目的根目录,执行下面的命令scrapy crawl quotes
查看mongodb数据库,数据应该已经获取下来了。
作者: liangxb
出处:https://www.cnblogs.com/lxbmaomao/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

