
一直不太清楚这个概念,今天看了OGL上的讲解,来翻译下理论部分
原文地址:http://ogldev.atspace.co.uk/www/tutorial35/tutorial35.html
一般传统的光照是 forward rendering(shading) ,即我们在顶点着色器(VS, 大多是法线和位置到剪切空间的变换)中做一系列的顶点变换,再到片元着色器(FS)中对每个像素进行光照计算。由于每个物体的每个像素只有一次单独的FS调用,所以我们不得不提供给FS所有光源信息,并在计算每个像素光照效果时将它们都考虑进去。这是一个很简单的方法,但是有缺点。如果场景十分复杂(譬如在现代游戏中),场景中有很多物体和复杂的深度(同一个屏幕像素被多个物体覆盖),那么我们会浪费很多GPU周期。例如,如果深度复杂度是4,那么就意味着,其中有3个像素的计算毫无用处,因为只显示最上面的像素。当然,我们可以试着去将物体从前到后排序,但是在复杂物体的情况下,通常不行。
forward rendering 的另一个问题是,当场景中有很多光源时,每个光源往往很小,只能作用于有限范围,但是我们的FS可能会计算离光源很远的地方的光照效果。你可以试图去计算从像素到光源的距离,但是那只能增加负担。forward rendering 在多光源情况下不能很好得扩展。
deferred shading(延迟渲染)技术在很多游戏中很流行。其关键技术点就在于将几何计算(位置和法线变换)和光线计算分开,其处理分为两个主要阶段(pass):
第一阶段 --- 运行一般的VS,但是并不发送处理过的属性给FS来计算光线,而是将它们转发到G Buffer。这是一个由几个2D纹理组成的逻辑分组,每个纹理都有顶点属性,将FS中的属性分割并使用OpenGL的MRT(多渲染目标)来写入不同的纹理。G buffer 中的属性值是光栅化后插值的结果。(译者注:G buffer并不是存储color值,而是存储影响objects的lighting passs数据用于计算场景中所有pixels的最终color值)这一步称为Geometry pass,每个物体都在这里被处理了。由于深度测试,当geometry pass 完成时,G buffer 中的纹理就是离相机最近的像素的插值属性。这就意味着,所有“不相干”像素都在深度测试中失败了并被抛弃了,G buffer中剩下的只有光照必须被计算的像素。下面是一个单个帧的 G buffer 的典型例子。
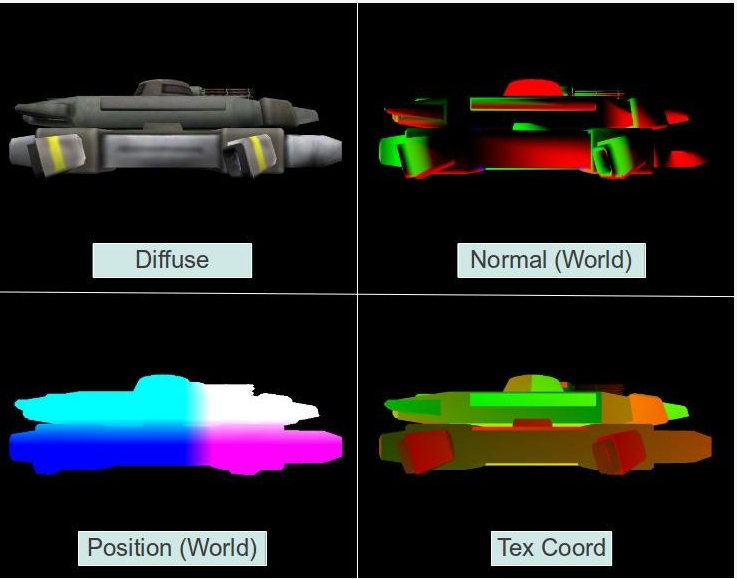
第二阶段(lighting pass) --- 逐个遍历 G buffer 中的每个像素,从不同的纹理中采样所有像素属性,然后用通常的方法计算光照。由于“不相干”像素已经被drop了,每个像素我们只需要计算一次。
我们怎么才能逐个像素地转换G buffer? 最简单的方法就是渲染一个屏幕空间的四边形。但是有更好的方法。我们之前说过,由于光源作用于有限区域,我们可以认为许多像素跟它无关。当一个像素上的光源影响足够小的时候,我们最好忽略它。在 forward rendering 中我们没有有效的方法这么做,但是,在 deferred shading 中我们可以计算光源周围的球星区域半径(对于点光源;对于聚光灯,我们用锥体)。这个球形代表光源的作用区域,超出这个区域我们可以忽略光源。我们可以使用球的粗略模型,由一些多边形组成,简单地以光源为中心渲染它。VS只会将位置转换为剪切空间,FS只会在相关像素上执行一次,我们会在那里做光源计算。有些人甚至会更进一步计算一个最小化边界四边形(bounding quad)来覆盖球形。渲染四边形比球形更容易因为只有两个三角形。
前向渲染和延迟渲染是两种光照渲染模式。
假设有1个光源和1000个具有光照反射的三角形在view coordinate沿着z轴正方形延伸摆放,法线与z轴平行,即所有三角形xy全相同,只有z不同,但是这里增加一个条件:摆放顺序是无序的。
从屏幕上其实你只能看到一个带光照的三角形,其他的都被挡住了。
那么前向渲染会这样做:
1.遍历1000个三角形片元
2.进行深度检测,没通过的忽略
3.通过检测的进行光照计算
4.更新帧缓冲区
5.返回1继续直到遍历结束
由于上面的要求是无序摆放,那么如果运气差一点 1000次深度检测全部都能通过,那么光照会计算1000次,可是因为只能看见最上面的,那么999次光照计算都是多余的。如果光源越多第三步的重复次数越多,整体复杂度也会越高。
延迟渲染引入了GBuffer,它会这样做:
1.遍历1000个三角形片元
2.进行深度检测,没通过的忽略
3.通过的将坐标、光照等信息写入GBuffer
4.返回1继续直到遍历结束
5.遍历Gbuffer
6.利用Gbuffer中的数据进行光照计算
7.更新帧缓冲区
8.返回5继续直到遍历结束
延迟渲染先把可以显示在屏幕上的像素点的相关参数保存下来,然后只进行了一次光照计算就实现了最终效果。这样大大节约了光照计算复杂度。每增加一个光源,只会增加一次整体的光照计算。所以延迟渲染的好处显而易见了。
然而,世间无完美之事,GBuffer只能给屏幕上的每一个点保存一份光照数据,但是如果这些三角形都是半透明的怎么办?无解–# Blend已废。
由于Gbuffer存的都是像素值,无法体现出每个像素对应的原始模型,那么多重采样抗锯齿功能也无法实现。三角形可能还好点,画圆就悲剧了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号