:)语言模型的评价-PPL迷惑度-从语言模型说起-|
语言模型的评价-PPL迷惑度-从语言模型说起
一语言模型
1.1语言模型概念:
1 计算一个句子的概率模型
2 也就是能够判断一个句子是否是人类语言,输出其概率。
1.2推导
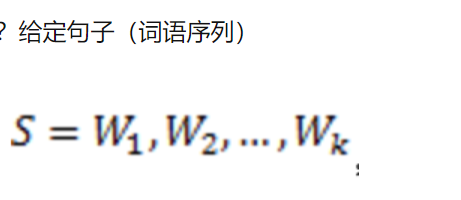
1.3它的概率表示为:
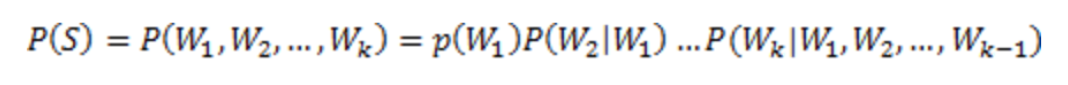
1.4存在两个缺陷:
1、參数空间过大:条件概率P(wn|w1,w2,..,wn-1)的可能性太多,无法估算,不可能有用; 通俗的解释为,w1到wn-1个词的组合很多,很多情况后面都会接 wn词。 2、数据稀疏严重:对于非常多词对的组合,在语料库中都没有出现,依据最大似然估计得到的概率将会是0。 通俗解释为,汉语中词组太多,词表中不一定都包含,所以计算结果可能为0.
1.5 最大似然估计
最大似然估计是一种用于估计模型参数的统计方法。
应用 的是 似然函数,求对数(乘法变加法), 然后 求导,获取最大值。
作用:最大似然估计 就是为了求这个连乘函数的结果即 概率值。

1.6 解决缺陷
为了解决參数空间过大的问题。引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
引出 一元语言模型 二元语言模型


二 评价语言模型
原理
参考链接:如何评价语言模型的好坏——困惑度、混淆度 (Perplexity) | Sentiment Mining (sentiment-mining.blogspot.com)
迷惑度基本思想:对 测试集中的句子,给出高概率值的 语言模型就是 性能较好的模型。
测试集中的句子都是正常的句子。
猜想:一个对话模型怎么测试, 句子输入,第一个字,给到模型,输出第二个字的概率,,然后前两个字输入 给出第三个字的概率,一直到最后一个字。那么会得到n-1个p,加权或其他计算,得到的值 应该越大越好。
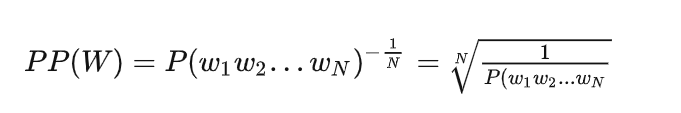
由公式, 概率越大越好, 迷惑度越小越好。
更直观的理解:
Perplexity其实表示的是average branch factor,大概可以翻译为平均分支系数。即平均来说,我们预测下一个词时有多少种选择。
举个例子来说,对于一个长度为N的,由0-9这10个数字随机组成的序列。由于这10个数字随机出现,所以每个数字出现的概率是<span id="MathJax-Span-196" class="mrow"><span id="MathJax-Span-197" class="mfrac"><span id="MathJax-Span-198" class="mn">1<span id="MathJax-Span-199" class="mn">10。也就是,在每个点,我们都有10个等概率的候选答案供我们选择,于是我们的perplexity就是10(有10个合理的答案)。
于是,在看到一个语言模型报告其perplexity是109时,我们就可以直观的理解为,平均情况下,这个语言模型预测下一个词时,其认为有109个词等可能地可以作为下一个词的合理选择。
代码实现

参考:
参考链接: 从语言模型说起:深入浅出讲解语言模型 - 知乎 (zhihu.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号