
GPT前世今生-transformer-注意力机制
GPT前世今生-transformer-注意力机制
背景:
心理学知识,随意线索和非随意线索。
启发:
注意力机制中概念:
query:你的要求 查询的东西。如问“你要干嘛?”
key:如杯子,本子
value:可以也是杯子本子,也可以是对应的分值(即注意力重要程度)
数学:
f(x) = xi,yi,即就是yi 函数表示 给定一个query x,f函数会找到它所最关注的xi,yi
深度学习原理(猜想):
cnn可以抽取feature,那么每个feature就是query,在下一个卷积/或别的运算时,求f(query) = 最关注的权值。
原始做法 非参数注意力池化层:
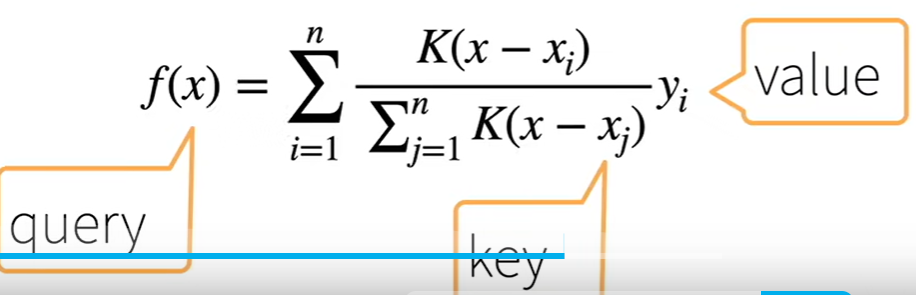
其中K 为kernel。
可以是高斯kernel, 本质度量x与xi的相近程度, 这里过程就类似knn找到这个最近xi。

若想训练,则可以添加参数:

小结:注意力机制可以写为
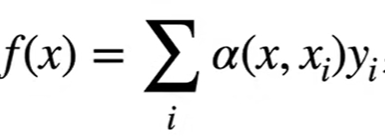
其中α就是对于每个yi值的权重。
那么问题是:
1 如何确定 x呢, 又如何确定 xi呢? 确定了xi 如何设定对应的yi value呢
加入x为 feature, x为后面的计算图,位置就是xi, 里面的值就是yi吗?
注意力层:

权重α 是 softmax(注意力分数)
原理图:
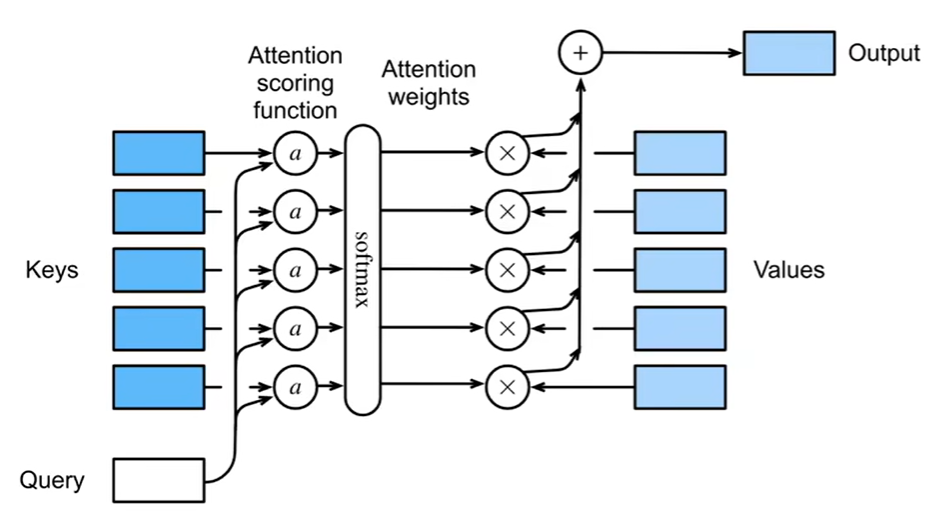
注意力分数:
如何拓展为高维 向量

扩展高维常见两种计算方法:
->方法一 等价于query和key 输入隐藏层大小为h,输出为1 的mlp。
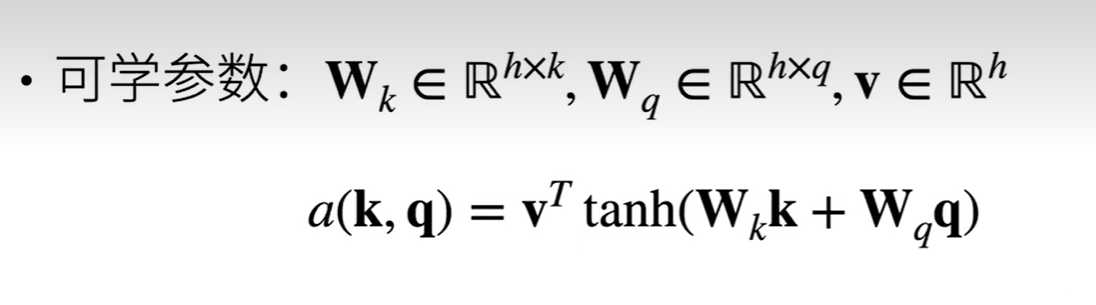
2 query 与key 内积
总结:
注意力分数是query与key的相似度, 注意力权重是分数的softmax结果。


