
ChatGPT背后的算法——RLHF总结
ChatGPT背后的算法——RLHF总结
参考链接:抱抱脸:ChatGPT背后的算法——RLHF | 附12篇RLHF必刷论文 (qq.com)
背景
(文本生成的语言模型评价不在训练中)
chatGPT训练4步骤
1 预训练 [prompt, text] 无监督, 数据语料来源可能都是 爬虫web
2为了模仿人类可能答案。有监督 学习人工标注的 问答预料,如河南最高的山是哪座?答;登封市的少林寺金刚山,海拔高度为1474.2米。
3 teacher model 为了模仿人类偏好。 对输出的结果 人工标注分数。
4 RLHF
总结
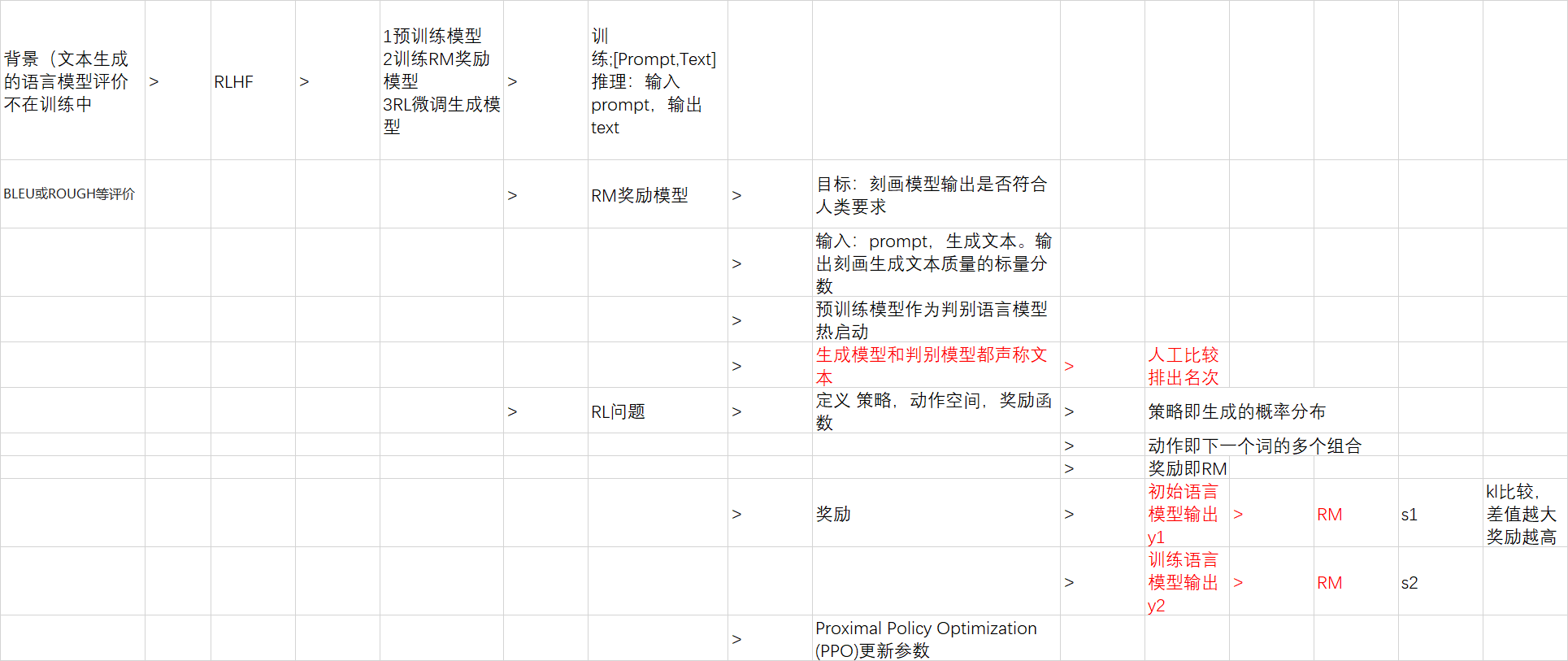
待改进1 人工标注成本高 2 ppo 算法比较老。
红色部分还未完全明白具体做法。
未完---


