一、测试要求:
1、 数据采集(要求至少爬取三千条记录,时间跨度超过一星期):(10分)
要求Python 编写程序爬取京东手机的评论数据,生成Json形式的数据文件。
-
- python代码(一次只是爬取单个商品的用户评论、本次爬取了三个产品的用户评论):
- 需要修改的参数:agents、url、cookie、phone_id
- 爬取数据的相关格式请自行修改
import urllib.request
import json
import random
import time as time0
import re, os
import pandas as pd
# 设置代理
agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
def product_reviews(product_id=None, p=0, maxPage=99):
root_dir = '畅想_详细字典'
# 判断之前是否爬取过这个型号手机的评论(一种型号的手机,颜色和内存不同,但评论共享)
os.makedirs(root_dir, exist_ok=True)
phone_list = os.listdir(root_dir)
phone_txt = str(product_id) + '.txt'
if phone_txt in phone_list:
print(product_id)
return []
# 对每一页循环爬取
# "maxPage": 45
k_head = 0
while p < maxPage:
# 所有品牌评论
# url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={}&score=0&sortType=5&page={}&pageSize={}&isShadowSku=0&rid=0&fold=1'
# 只看当前商品的评论
# url = 'https://club.jd.com/comment/skuProductPageComments.action?callback=fetchJSON_comment98&productId={}&score=0&sortType=5&page={}&pageSize={}&isShadowSku=0&fold=1'
# url = 'https://club.jd.com/comment/skuProductPageComments.action?callback=fetchJSON_comment98&productId={}&score=0&sortType=5&page={}&pageSize={}&isShadowSku=0&fold=1'
url = 'https://club.jd.com/comment/skuProductPageComments.action?callback=fetchJSON_comment98&productId={}&score=0&sortType=5&page={}&pageSize={}&isShadowSku=0&fold=1'
url = url.format(product_id, p, maxPage)
# print(url)
# 仿造请求头,骗过浏览器
# cookie可以查找自己浏览器中的cookie,直接复制过来
# cookie = '__jdu=16086454389902142527500; shshshfpa=428bc42a-e70a-655c-93f6-e3691985be43-1608645441; areaId=5; PCSYCityID=CN_130000_0_0; shshshfpb=zZdUWw6j4E+CLU7Oc2T9TPw==; jwotest_product=99; ipLoc-djd=5-142-42547-54561; unpl=JF8EAMlnNSttWR5cBhkFSREXSQ8HW10JS0RQam5RV1hcSlwMGFYfF0d7XlVdXhRKFR9vZRRUWlNKUA4aACsSEXteXVdZDEsWC2tXVgQFDQ8VXURJQlZAFDNVCV9dSRZRZjJWBFtdT1xWSAYYRRMfDlAKDlhCR1FpMjVkXlh7VAQrAhwTGUxYUFtfAUMfAmxnAFdZW01QBBoyKxUge21cX18PQxEzblcEZB8MF1YNEgMdEV1LWlVXWg1PEgFmbw1VXlhOVwEYBB8TEXtcZF0; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_0d9236c263cb4101bb48e2450982e54f|1647159858849; token=073f0cf5421b21eb907cb3d463424c0d,2,915089; __tk=yLrdvVbqNid3IaWAIDreOMTKOBrtHJ5QyghVqEbPzizsHLThyLr4OB5TIgKtwMblyg33rRbC,2,915089; shshshfp=3f1b5dd4917b58fe63ba3cdc71c35d33; shshshsID=2e60157b7de85966e3acbd0dc0063568_1_1647161877700; __jda=122270672.16086454389902142527500.1608645438.1647158698.1647161878.18; __jdb=122270672.1.16086454389902142527500|18.1647161878; __jdc=122270672; ip_cityCode=142; JSESSIONID=77C90B3806506F4FE8DA83EFC6A843FB.s1; 3AB9D23F7A4B3C9B=PYWTVSEEI7W7KUBCKF6CBWAXHNRJIWPF2VDYXRDH7USOJ4XIOOKLRQ4Z5JEMWWSSIBFD6MGMFEV5I2UWS2R6ZA6STM'
# cookie = '__jdu=16086454389902142527500; shshshfpa=428bc42a-e70a-655c-93f6-e3691985be43-1608645441; areaId=5; PCSYCityID=CN_130000_0_0; shshshfpb=zZdUWw6j4E+CLU7Oc2T9TPw==; jwotest_product=99; ipLoc-djd=5-142-42547-54561; unpl=JF8EAMlnNSttWR5cBhkFSREXSQ8HW10JS0RQam5RV1hcSlwMGFYfF0d7XlVdXhRKFR9vZRRUWlNKUA4aACsSEXteXVdZDEsWC2tXVgQFDQ8VXURJQlZAFDNVCV9dSRZRZjJWBFtdT1xWSAYYRRMfDlAKDlhCR1FpMjVkXlh7VAQrAhwTGUxYUFtfAUMfAmxnAFdZW01QBBoyKxUge21cX18PQxEzblcEZB8MF1YNEgMdEV1LWlVXWg1PEgFmbw1VXlhOVwEYBB8TEXtcZF0; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_0d9236c263cb4101bb48e2450982e54f|1647163488743; __jda=122270672.16086454389902142527500.1608645438.1647158698.1647161878.18; __jdc=122270672; token=38fe0b7e85bcc8e668e7ee86b94f7374,2,915090; __tk=TLY2iIi5TUvviAa4TUqFiDfJinTvVIi5Skl5VIVKVUl2VnSEiLe2iG,2,915090; shshshfp=3f1b5dd4917b58fe63ba3cdc71c35d33; ip_cityCode=142; shshshsID=2e60157b7de85966e3acbd0dc0063568_7_1647163524505; __jdb=122270672.7.16086454389902142527500|18.1647161878; 3AB9D23F7A4B3C9B=PYWTVSEEI7W7KUBCKF6CBWAXHNRJIWPF2VDYXRDH7USOJ4XIOOKLRQ4Z5JEMWWSSIBFD6MGMFEV5I2UWS2R6ZA6STM; JSESSIONID=ED19674156BF5FC641C366B7E0FFAAD2.s1'
cookie = '__jdu=16086454389902142527500; shshshfpa=428bc42a-e70a-655c-93f6-e3691985be43-1608645441; areaId=5; PCSYCityID=CN_130000_0_0; shshshfpb=zZdUWw6j4E+CLU7Oc2T9TPw==; jwotest_product=99; ipLoc-djd=5-142-42547-54561; unpl=JF8EAMlnNSttWR5cBhkFSREXSQ8HW10JS0RQam5RV1hcSlwMGFYfF0d7XlVdXhRKFR9vZRRUWlNKUA4aACsSEXteXVdZDEsWC2tXVgQFDQ8VXURJQlZAFDNVCV9dSRZRZjJWBFtdT1xWSAYYRRMfDlAKDlhCR1FpMjVkXlh7VAQrAhwTGUxYUFtfAUMfAmxnAFdZW01QBBoyKxUge21cX18PQxEzblcEZB8MF1YNEgMdEV1LWlVXWg1PEgFmbw1VXlhOVwEYBB8TEXtcZF0; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_0d9236c263cb4101bb48e2450982e54f|1647163488743; __jdc=122270672; __jda=122270672.16086454389902142527500.1608645438.1647158698.1647161878.18; shshshfp=3f1b5dd4917b58fe63ba3cdc71c35d33; ip_cityCode=142; token=a50c44639af4e4879d72140e2e4b8af5,2,915091; __tk=kYj5AUeEjDftAUgyAVAqkVa1BVfqBVAsBVAqAVnFAz4,2,915091; shshshsID=2e60157b7de85966e3acbd0dc0063568_8_1647164950694; __jdb=122270672.8.16086454389902142527500|18.1647161878; 3AB9D23F7A4B3C9B=PYWTVSEEI7W7KUBCKF6CBWAXHNRJIWPF2VDYXRDH7USOJ4XIOOKLRQ4Z5JEMWWSSIBFD6MGMFEV5I2UWS2R6ZA6STM; JSESSIONID=D3446CA1DE4A705EFCCCCC073D47B42D.s1'
headers = {
'User-Agent': ''.join(random.sample(agents, 1)),
'Referer': 'https://item.jd.com/',
'Cookie': cookie
}
# 发起请求
request = urllib.request.Request(url=url, headers=headers)
time0.sleep(2.5)
# 得到响应ti'm
try:
content = urllib.request.urlopen(request).read().decode('gbk')
except:
print('第%d页评论代码出错' % p)
p = p + 1
continue
# 去掉多余得到json格式
content = content.strip('fetchJSON_comment98vv995();')
# 评论的最大页数
try:
maxPage = int(re.findall('"maxPage":(.*?),"', content, re.S)[0])
except:
pass
try:
obj = json.loads(content)
except:
print('信号不好,再次尝试!')
print([content])
print(url)
continue
comments = obj['comments']
# 产品评论总结
productCommentSummary = obj['productCommentSummary']
dict_pars_info = {}
# 平均分
# dict_pars_info['平均分'] = str(productCommentSummary['averageScore'])
# 好评率
dict_pars_info['好评率'] = str(productCommentSummary['goodRate'])
# 当前总评论数
dict_pars_info['中评率'] = str(productCommentSummary['generalRate'])
# 默认评论数
dict_pars_info['差评率'] = str(productCommentSummary['poorRate'])
# 好评、中评、差评
dict_pars_info['好评数'] = str(productCommentSummary['score5Count'])
dict_pars_info['中评数'] = str(productCommentSummary['score3Count'])
dict_pars_info['差评数'] = str(productCommentSummary['score1Count'])
if len(comments) > 0:
# print(comments)
for comment in comments:
# print(comment)
id = comment['id']
guid = comment['guid']
content = comment['content']
creationTime = comment['creationTime']
score = comment['score']
nickname = comment['nickname']
plusAvailable = comment['plusAvailable']
days = comment['days']
try:
mobileVersion = comment['mobileVersion']
except:
mobileVersion = ''
item = {
'id': id,
'guid': guid,
'content': content,
'creationTime': creationTime,
'score': score,
'nickname': nickname,
'plusAvailable': plusAvailable,
'mobileVersion': mobileVersion,
'days': days,
}
item.update(dict_pars_info)
# print(item)
string = str(item)
# 1.保存为csv格式
item_dataframe = pd.DataFrame([item])
# print(item_dataframe)
if k_head == 0:
item_dataframe.to_csv(root_dir + '/%d.csv' % product_id, mode='w', header=True, index=False,
encoding='gbk')
k_head += 1
else:
item_dataframe.to_csv(root_dir + '/%d.csv' % product_id, mode='a', header=False, index=False,
encoding='gbk')
# 2.保存成txt
fp = open(root_dir + '/%d.txt' % product_id, 'a', encoding='gbk')
fp.write(string + '\n')
fp.close()
print('%s-page---finish(%s/%s)' % (p, p, maxPage))
else:
return []
p = p + 1
if __name__ == '__main__':
phone_id = 100015154663
# phone_id = 100026796994
# phone_id = 100016944073
product_reviews(product_id=phone_id)
运行截图:
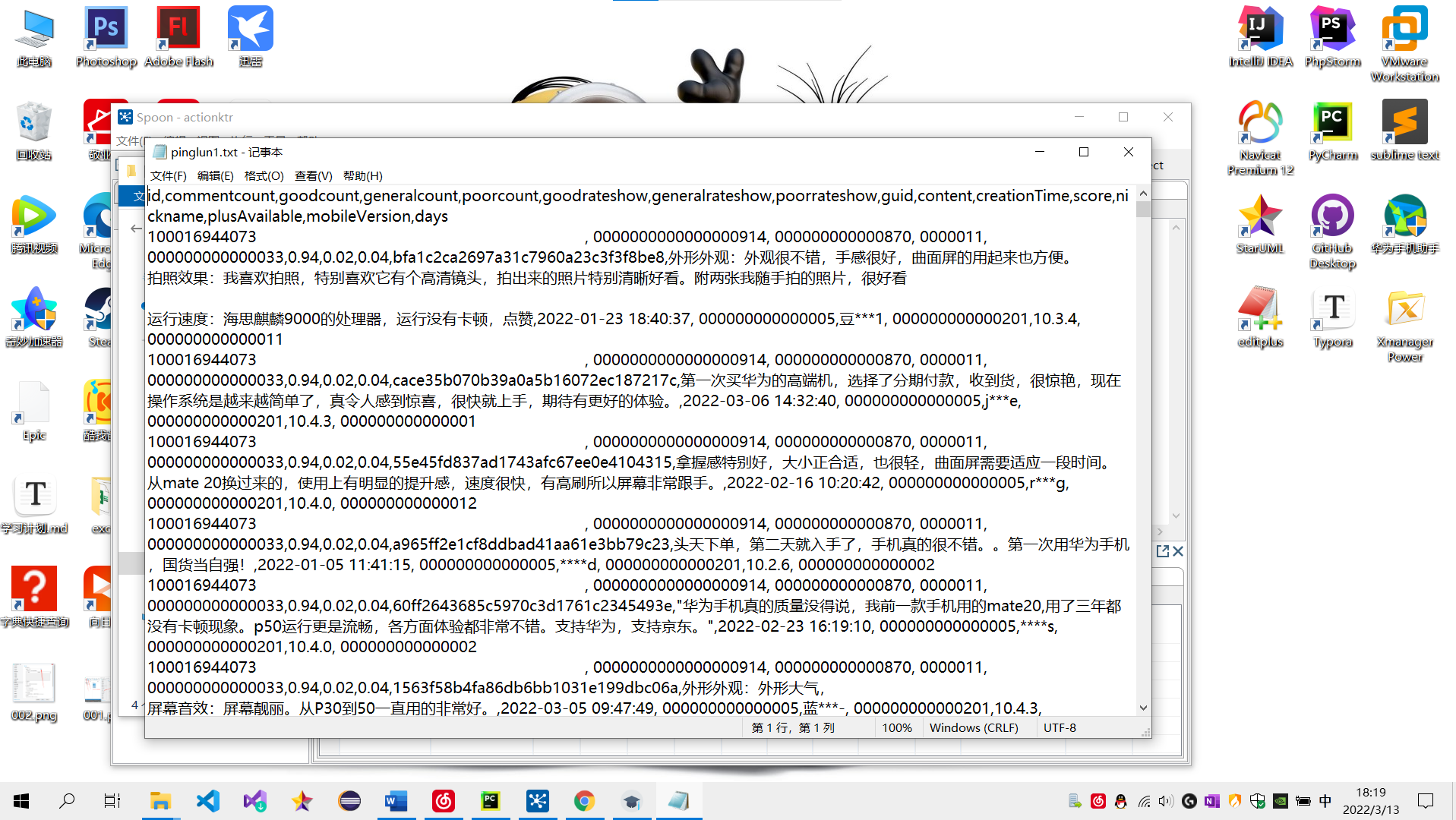
2、数据预处理:要求使用MapReduce或者kettle实现源数据的预处理,对大量的Json文件,进行清洗,以得到结构化的文本文件。(本人使用kettle进行的数据清洗)
3、 数据统计:生成Hive用户评论数据:
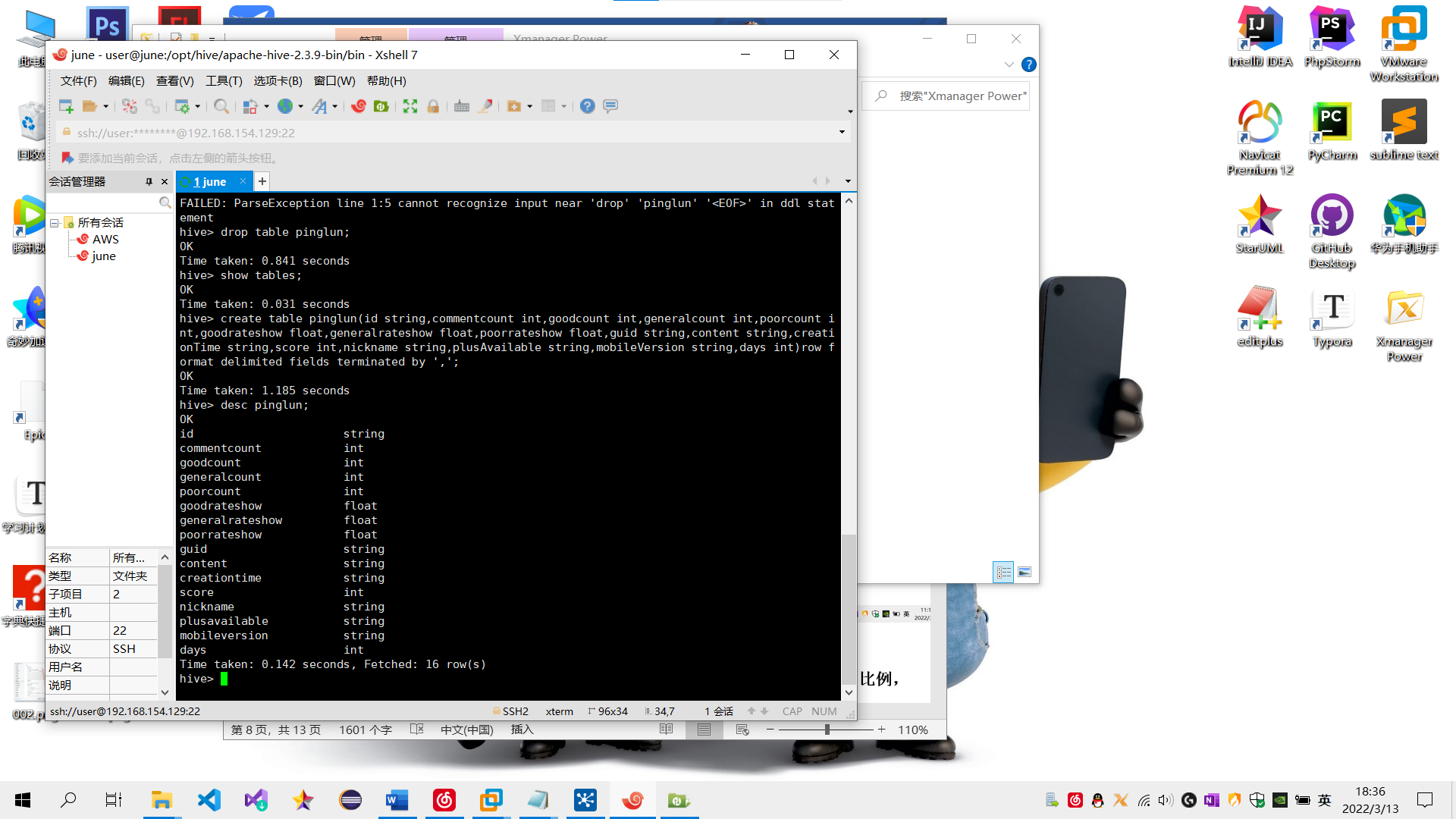
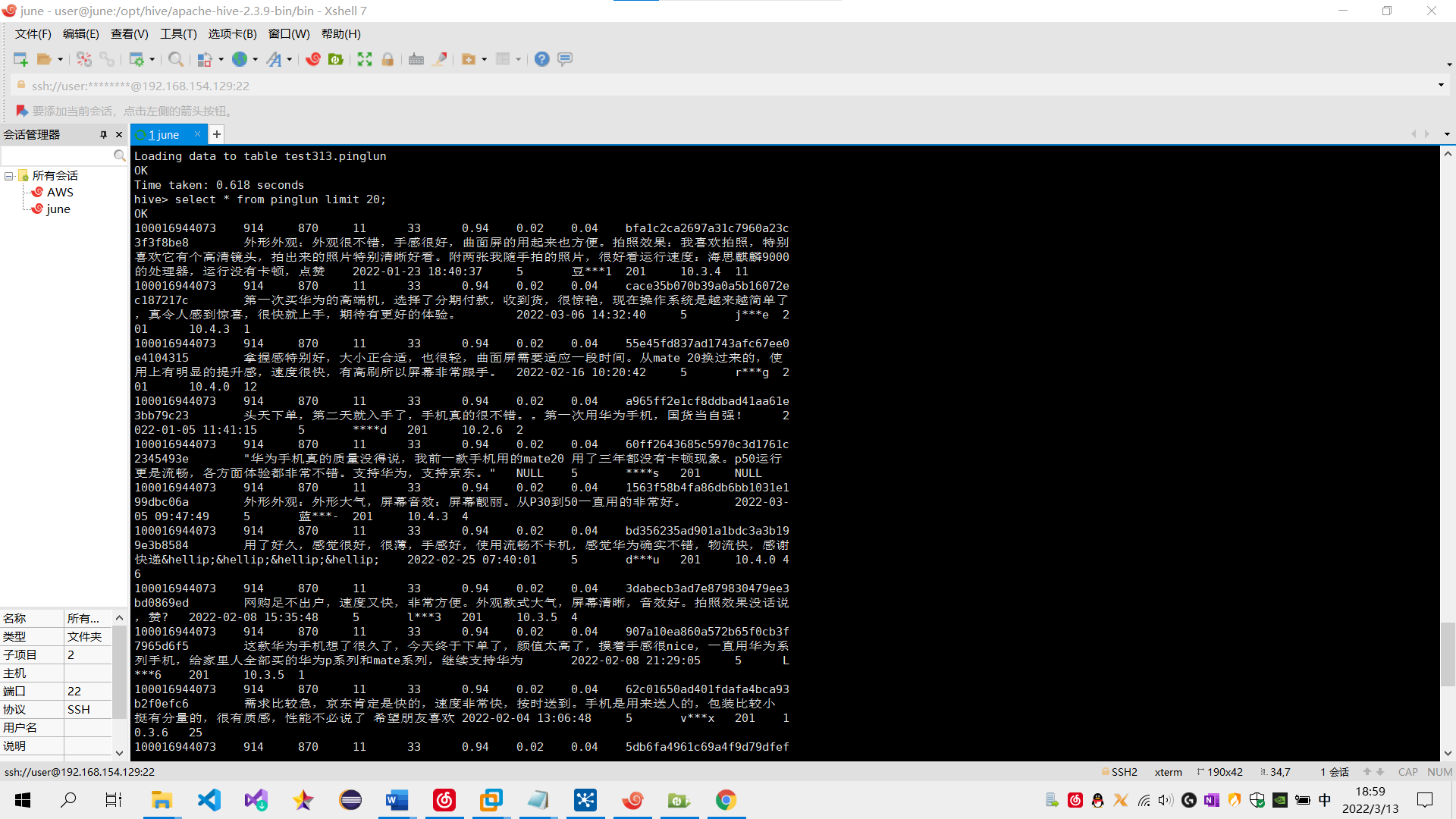
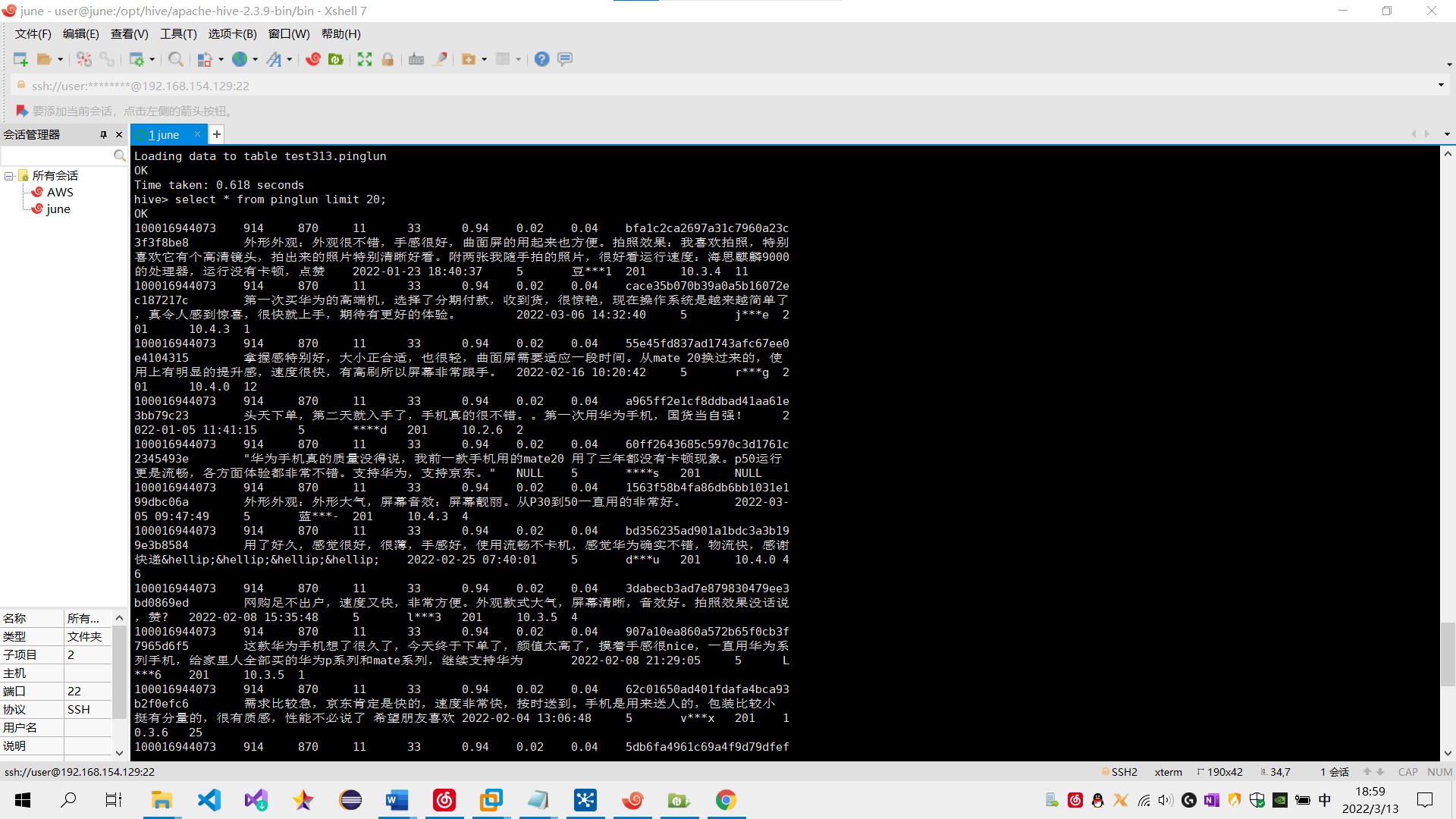
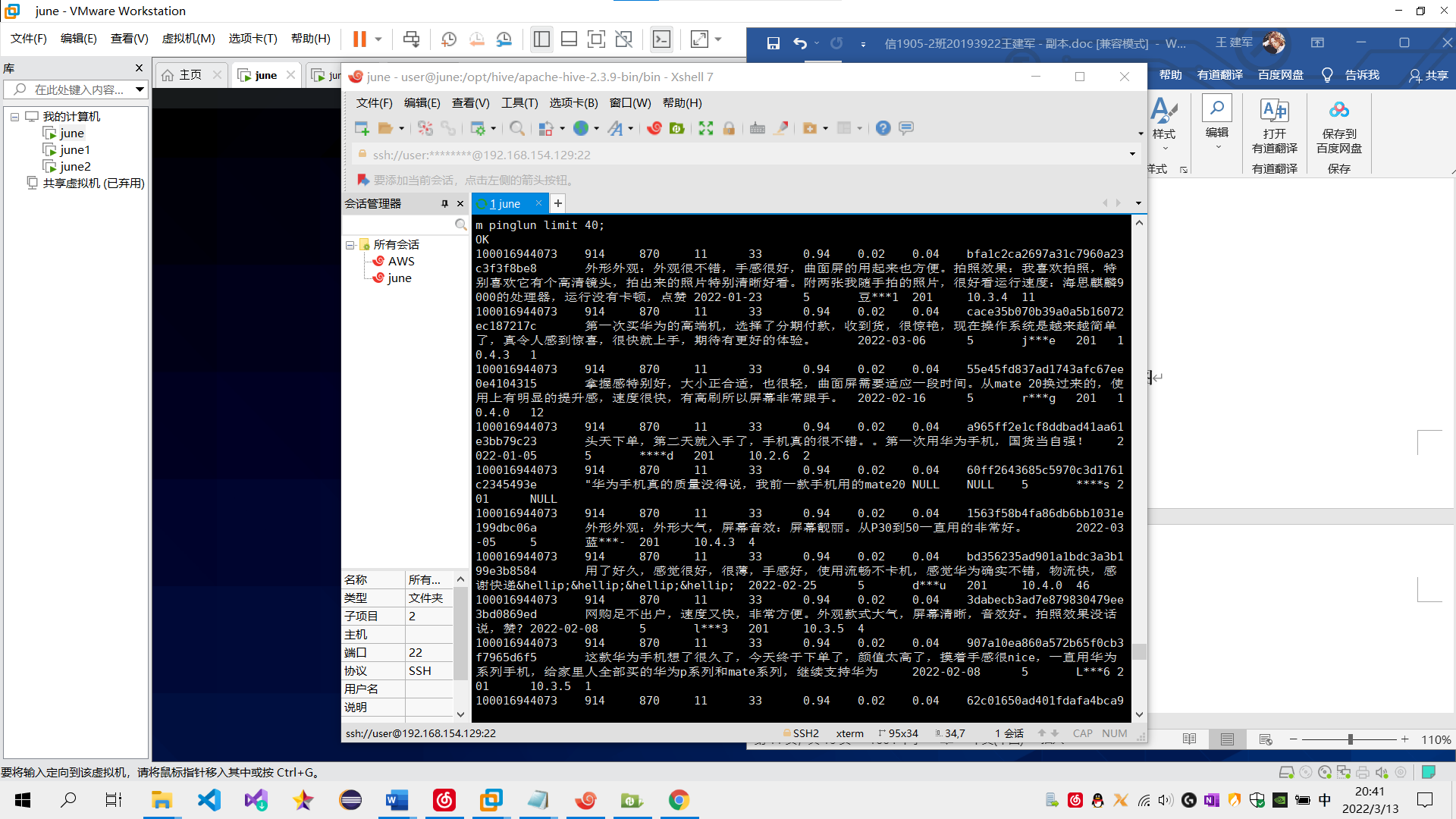
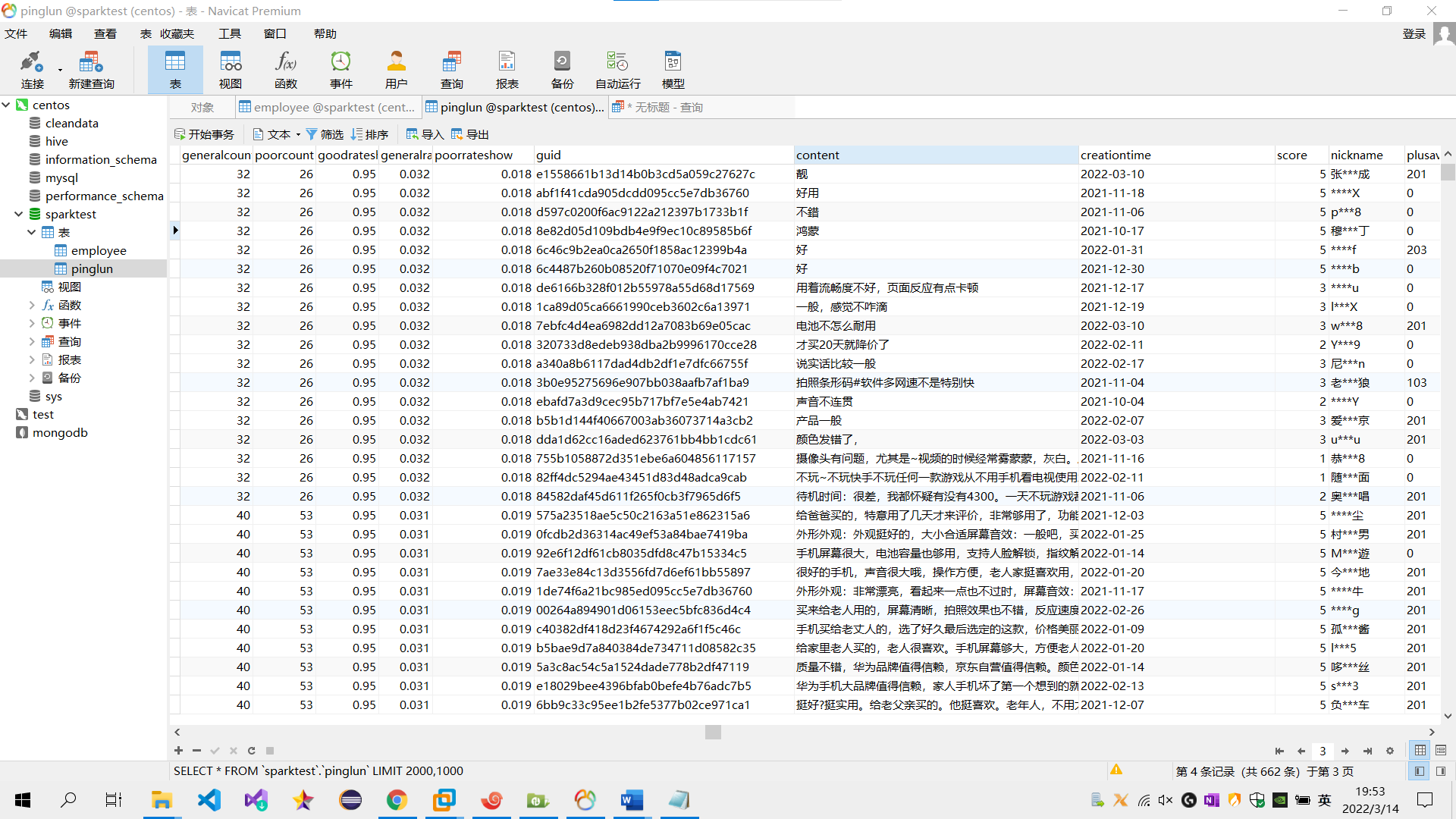
(1) 在Hive创建一张表,用于存放清洗后的数据,表名为pinglun,(创建数据表SQL语句),创建成功导入数据截图:
sql语句:
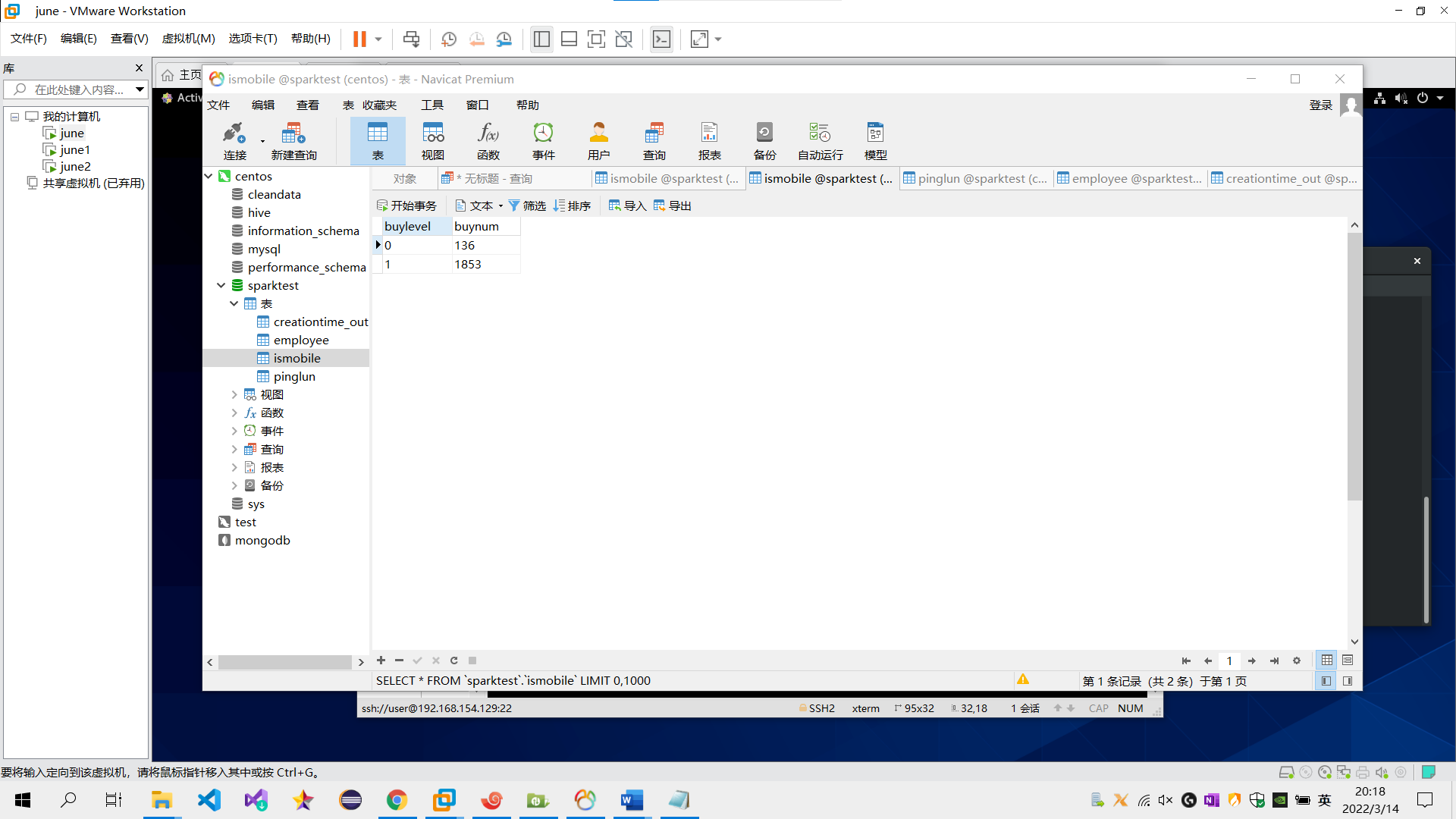
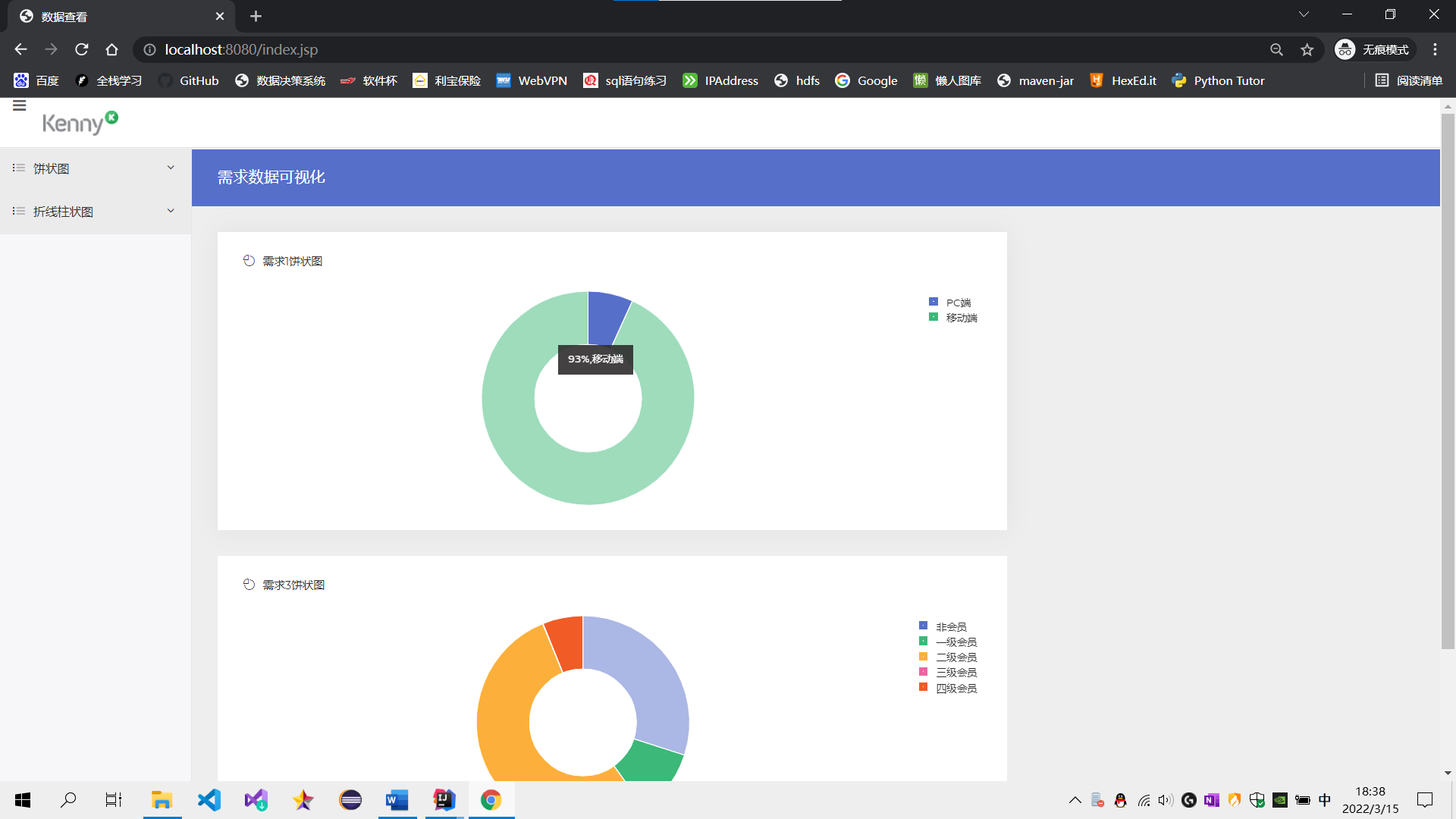
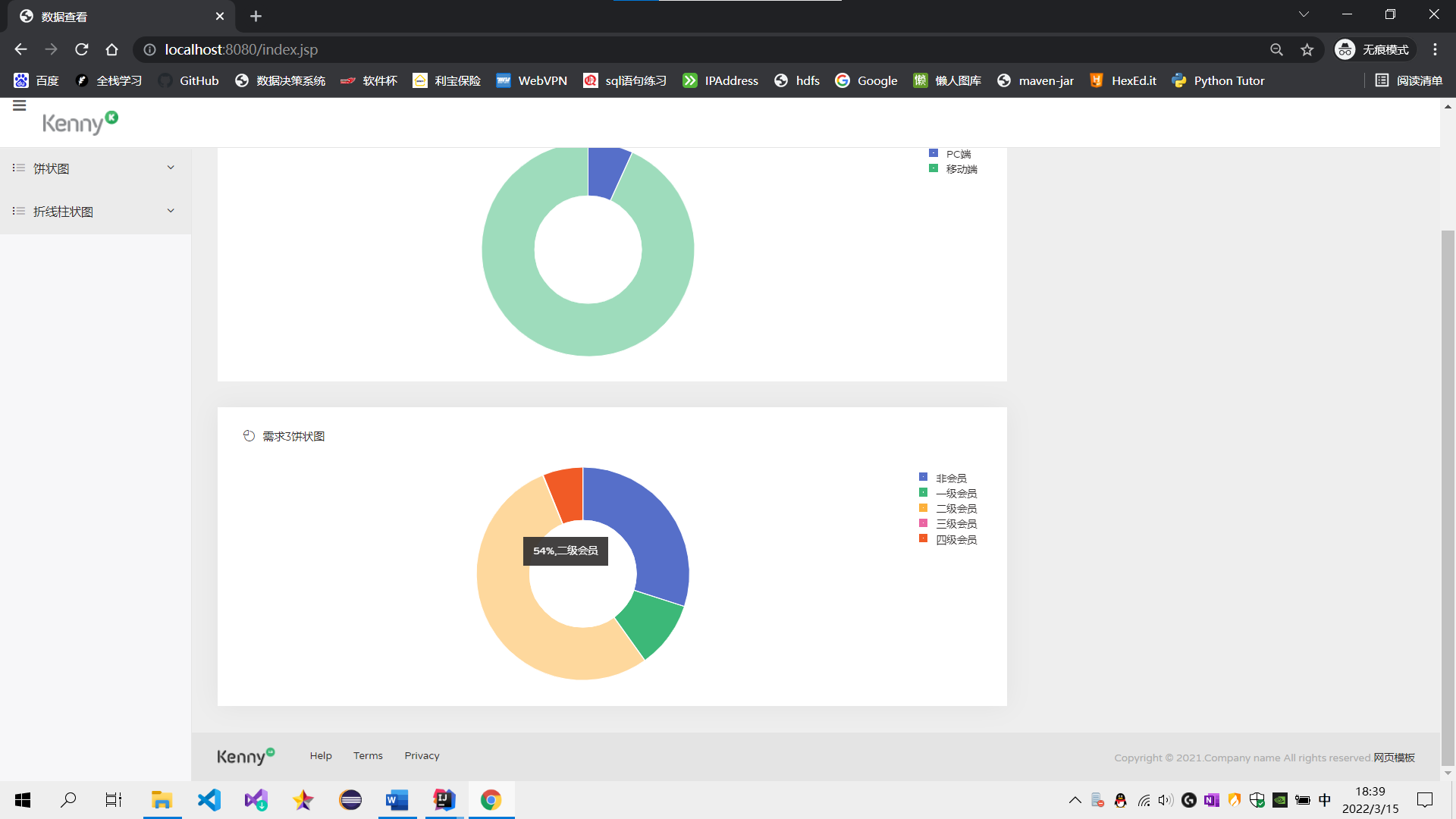
需求1:分析用户使用移动端购买还是PC端购买,及移动端和PC端的用户比例,生成ismobilehive表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
sql语句:(所出结果均使用代码中所爬取数据)
create table ismobile(buylevel string,buynum int);
select count(*) from pinglun where mobileVersion='';
insert into ismobile(buylevel,buynum) values('0',136);
select count(*) from pinglun where mobileVersion!='';
insert into ismobile(buylevel,buynum) values('1',1853);
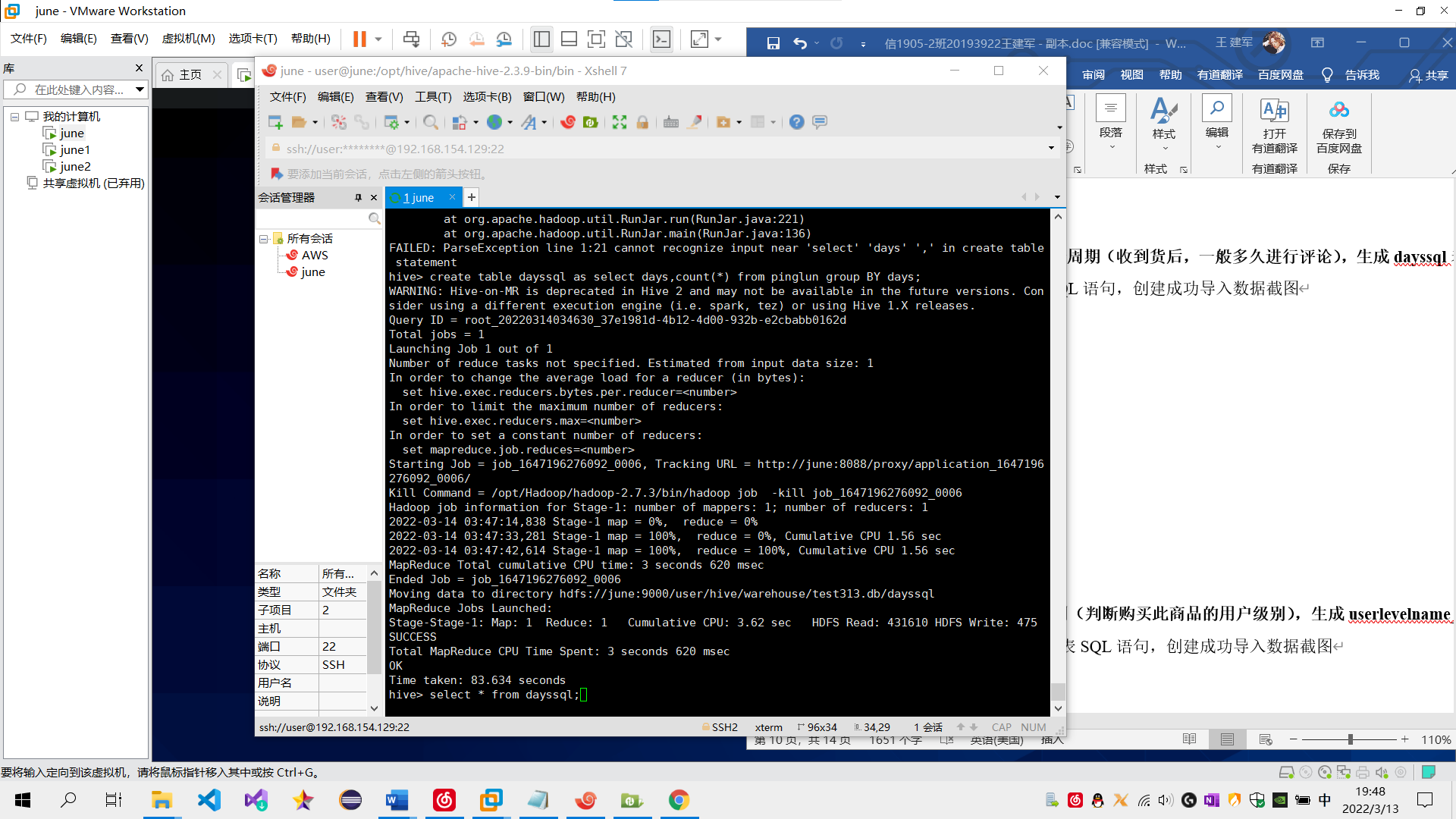
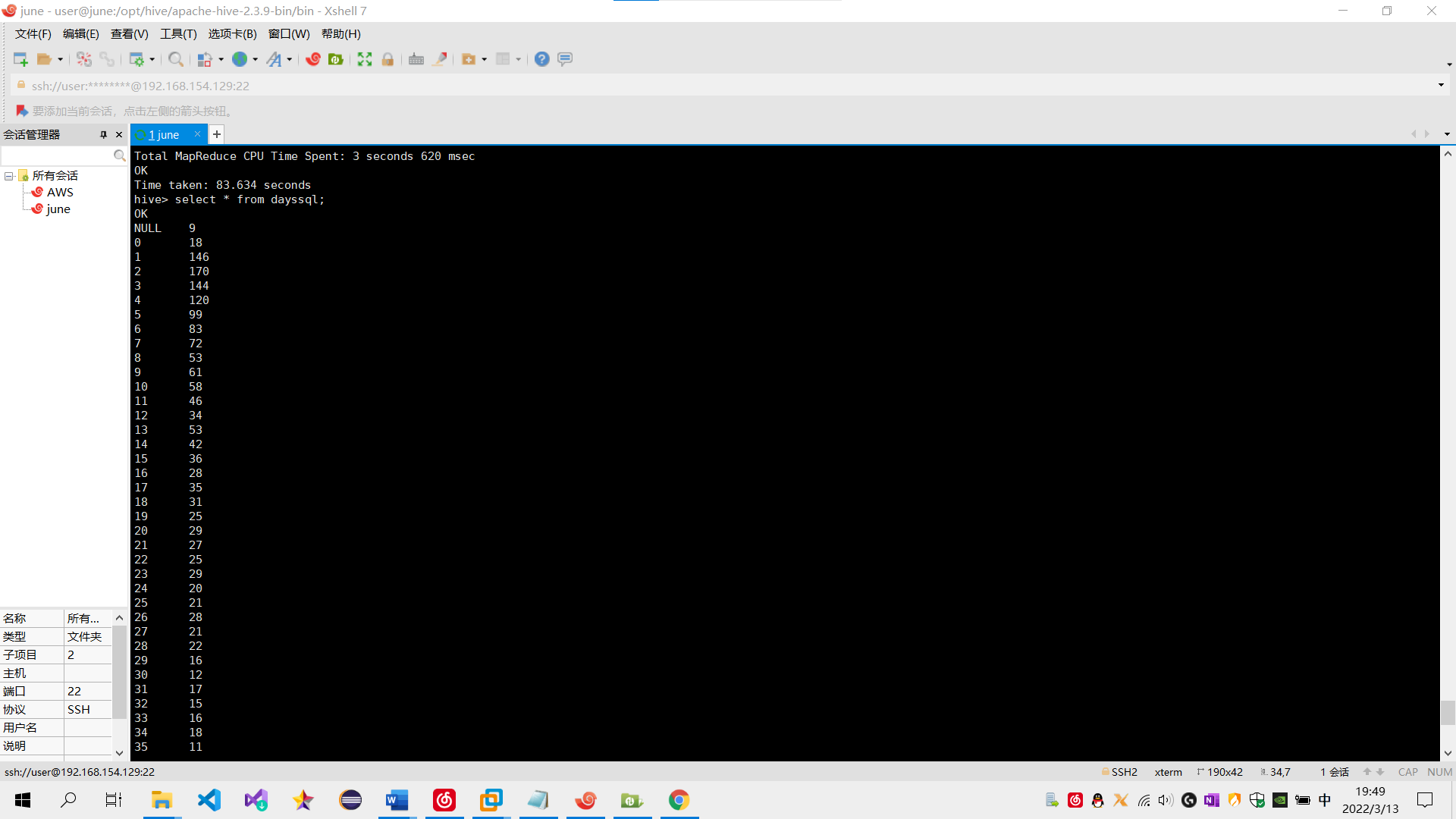
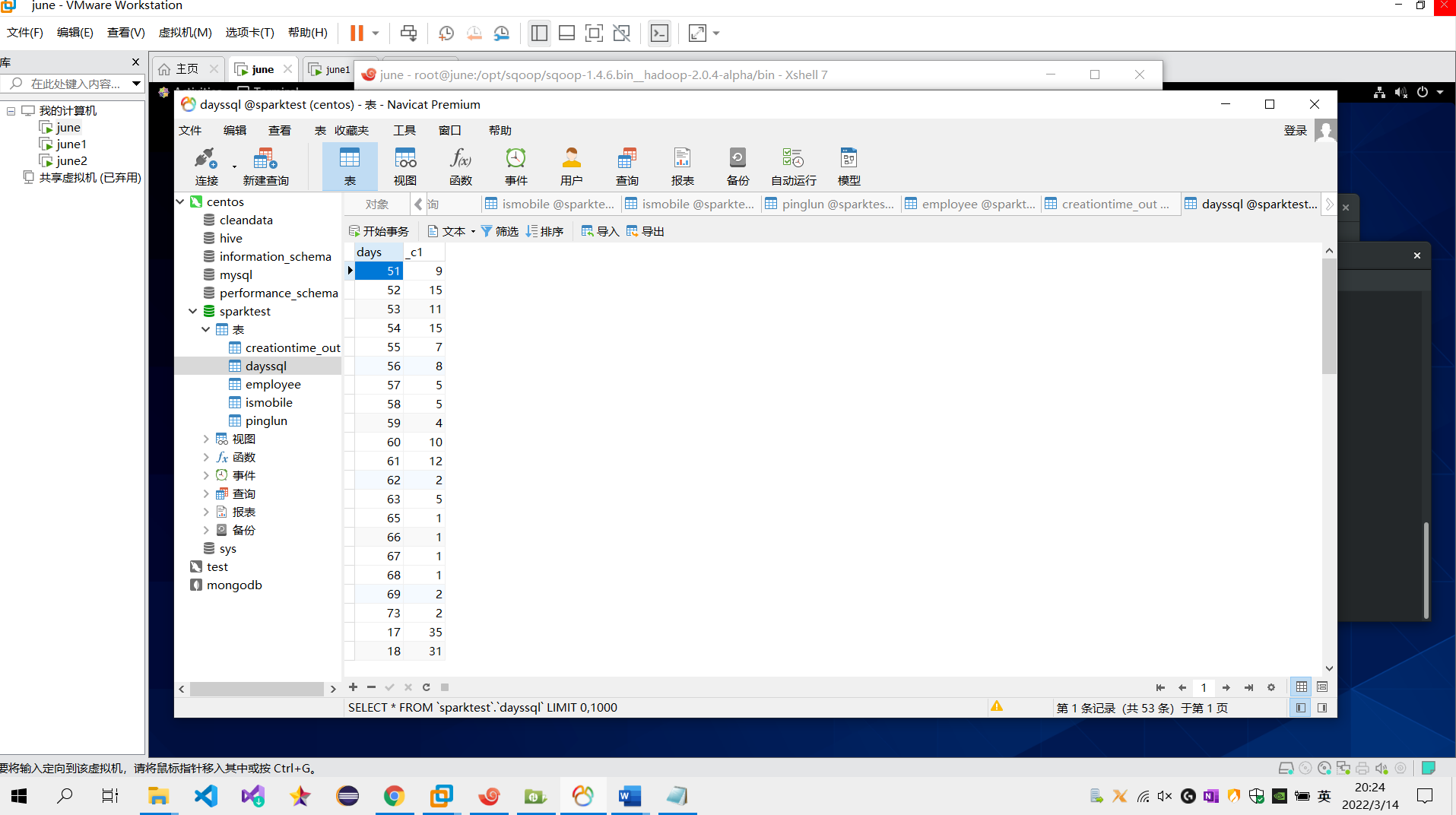
需求2:分析用户评论周期(收到货后,一般多久进行评论),生成dayssql表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
sql语句:create table dayssql as select days,count(*) from pinglun group BY days;
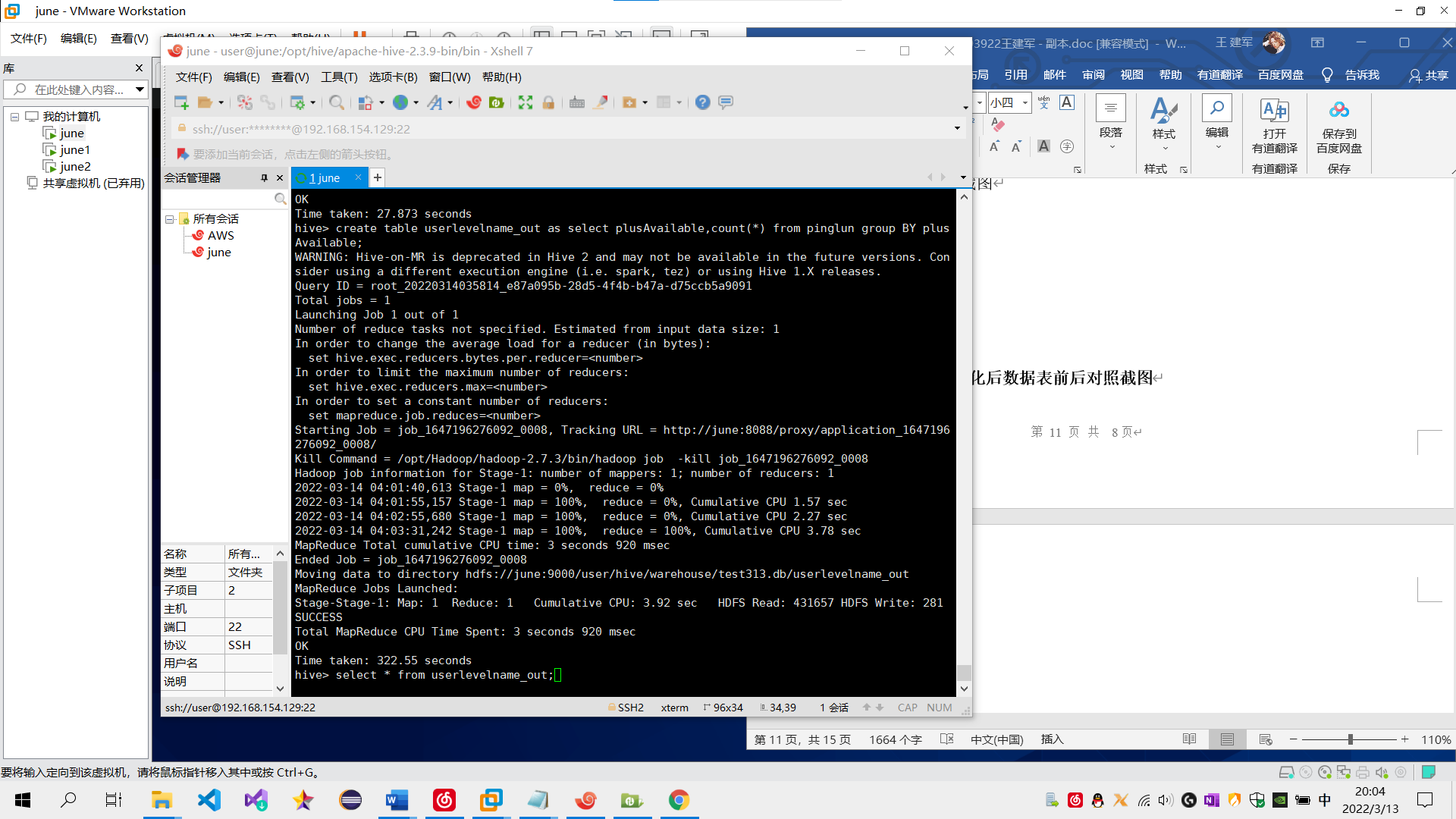
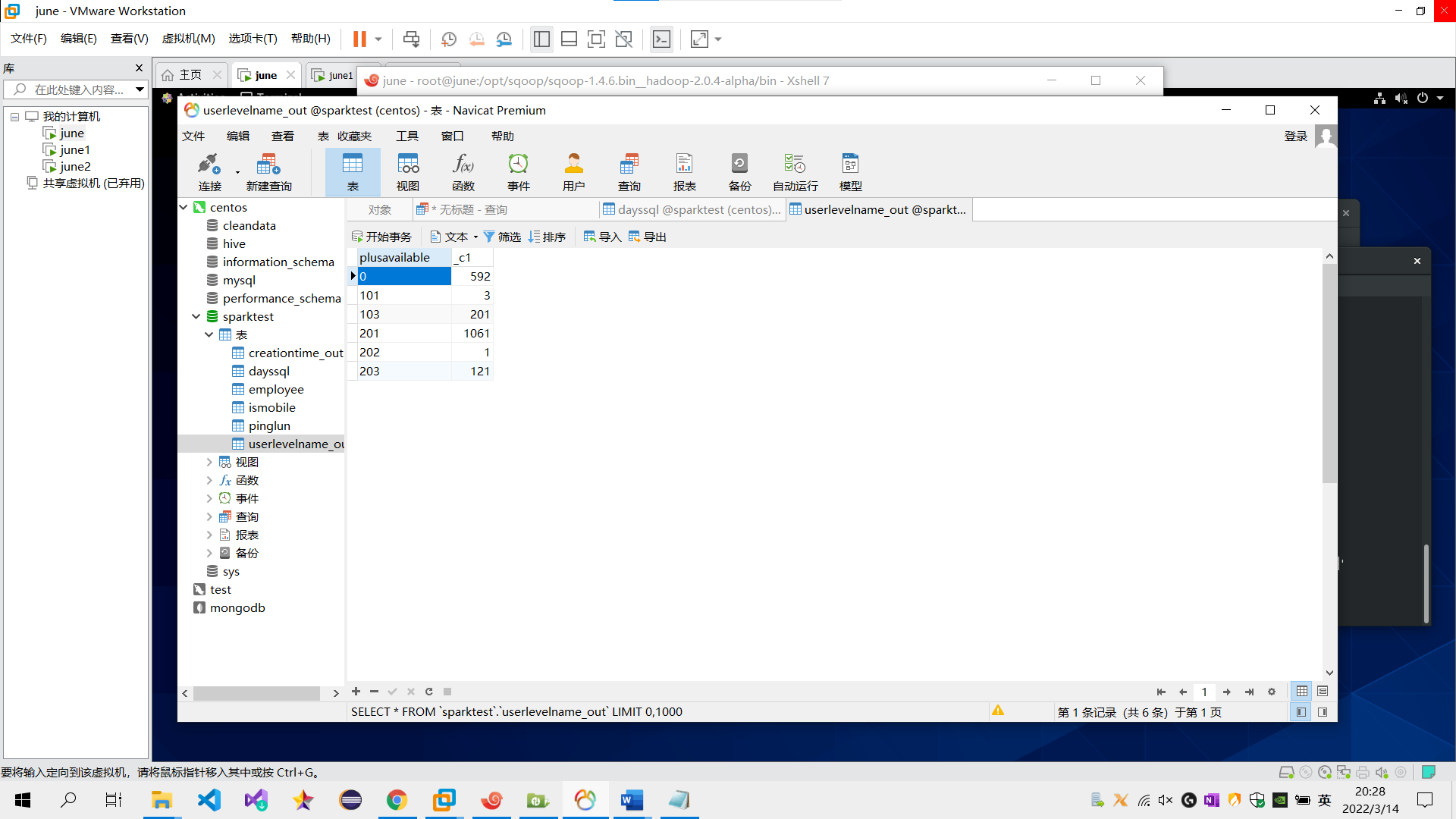
需求3:分析会员级别(判断购买此商品的用户级别),生成userlevelname_out表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
sql语句:create table userlevelname_out as plusAvailable,count(*) from pinglun group BY plusAvailable;
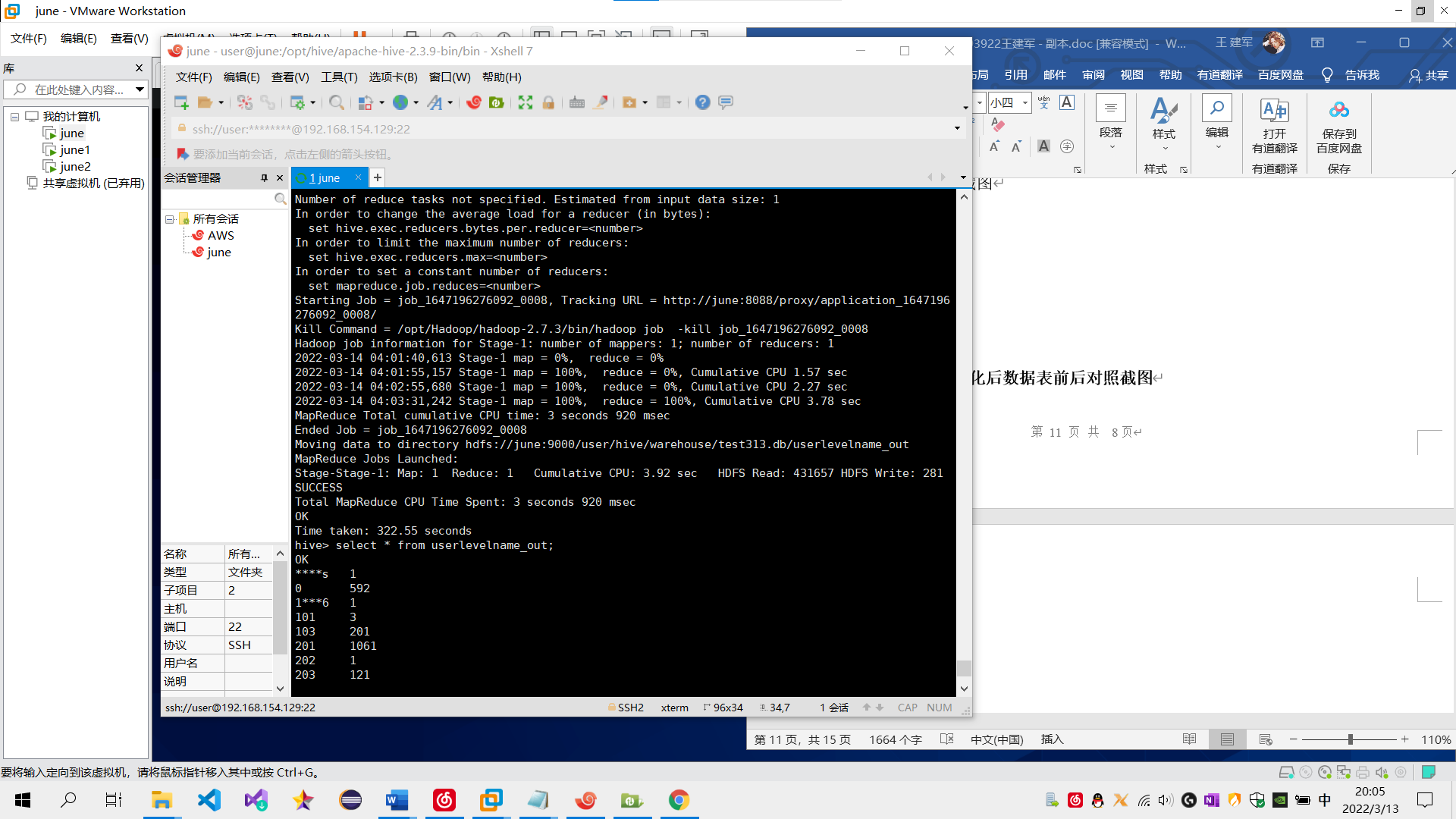
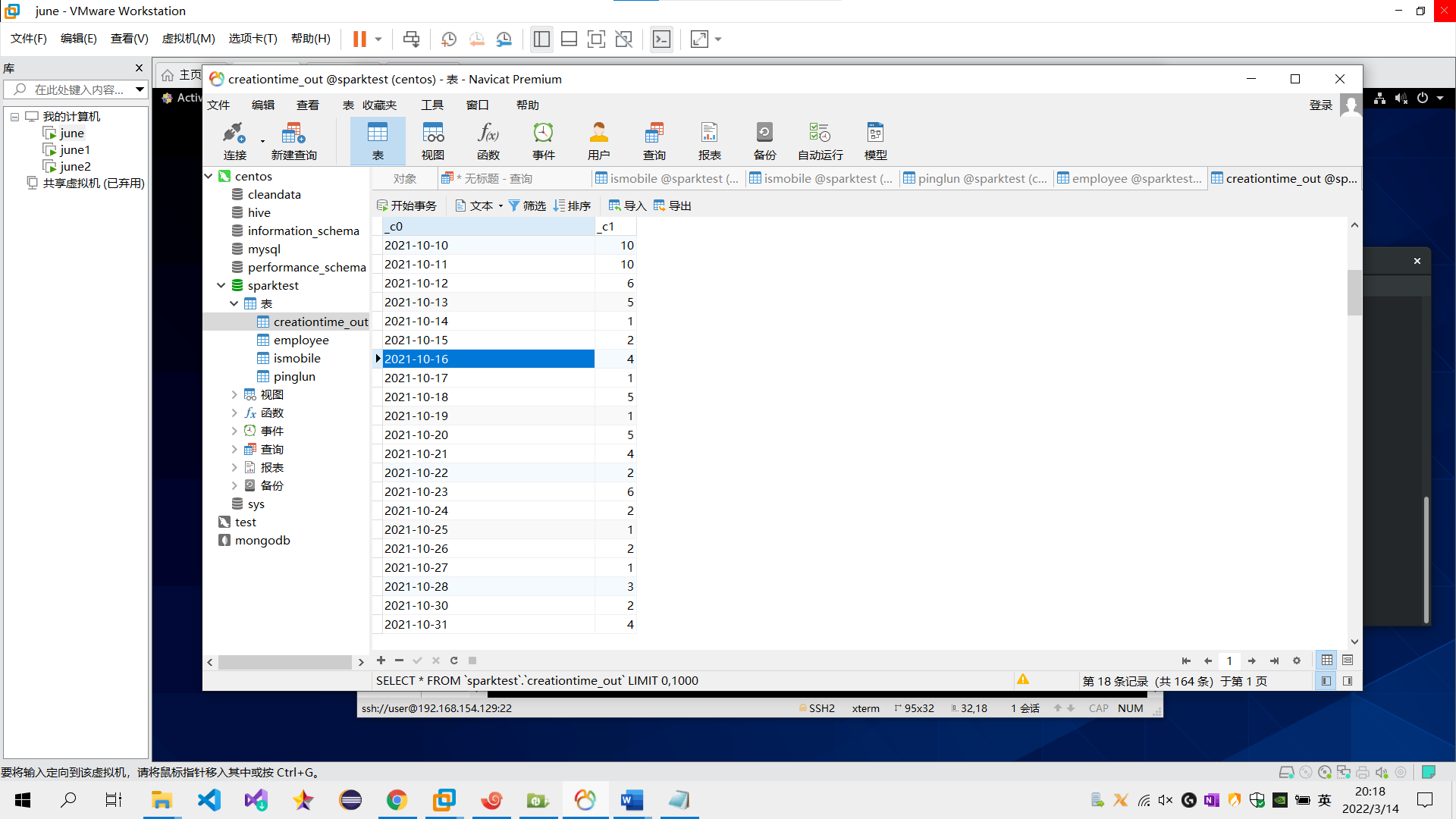
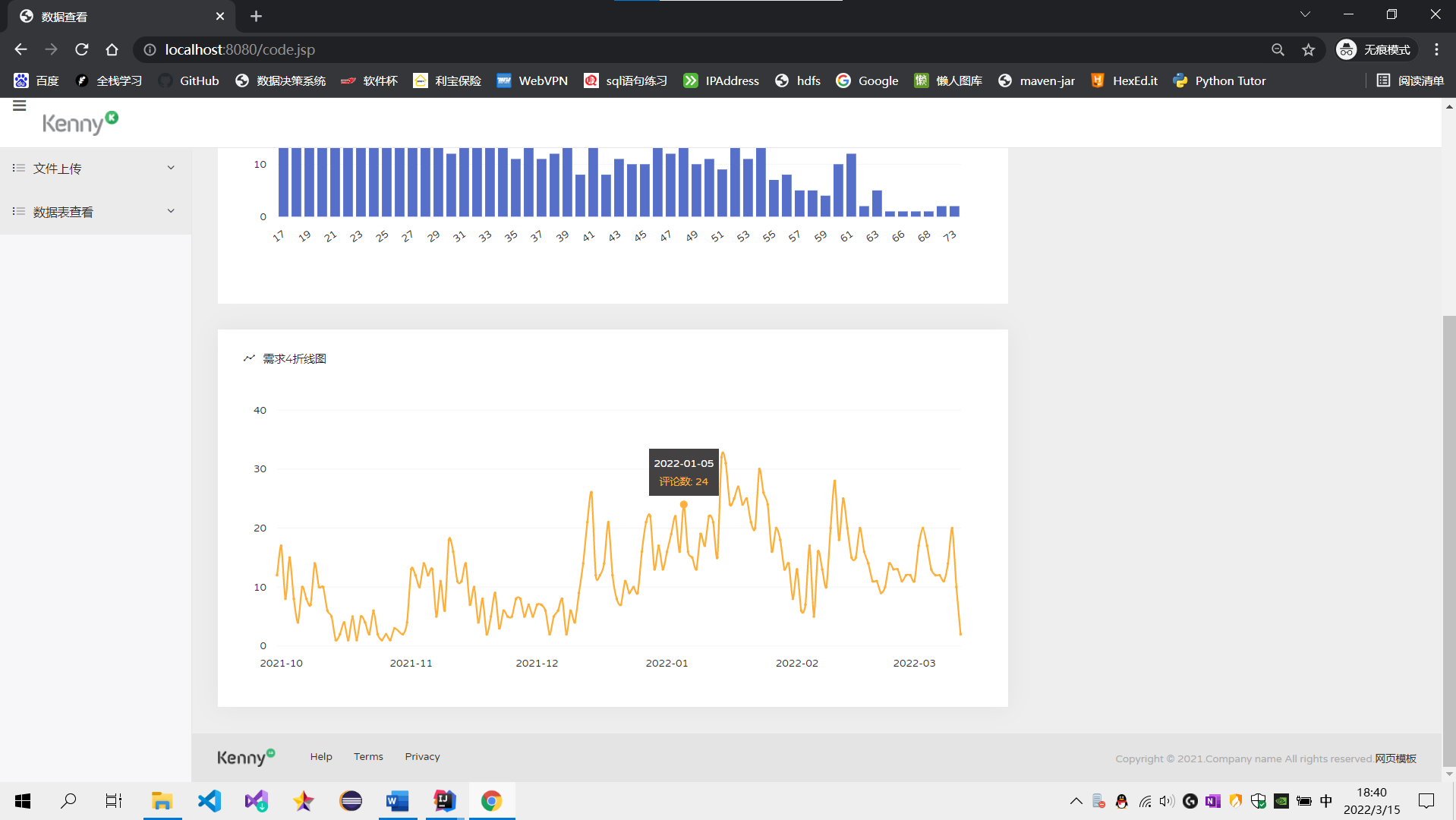
需求4:分析每天评论量,生成creationtime_out表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
sql语句:create table creationtime_out as select to_date(creationtime),count(*) from pinglun group BY to_date(creationtime);
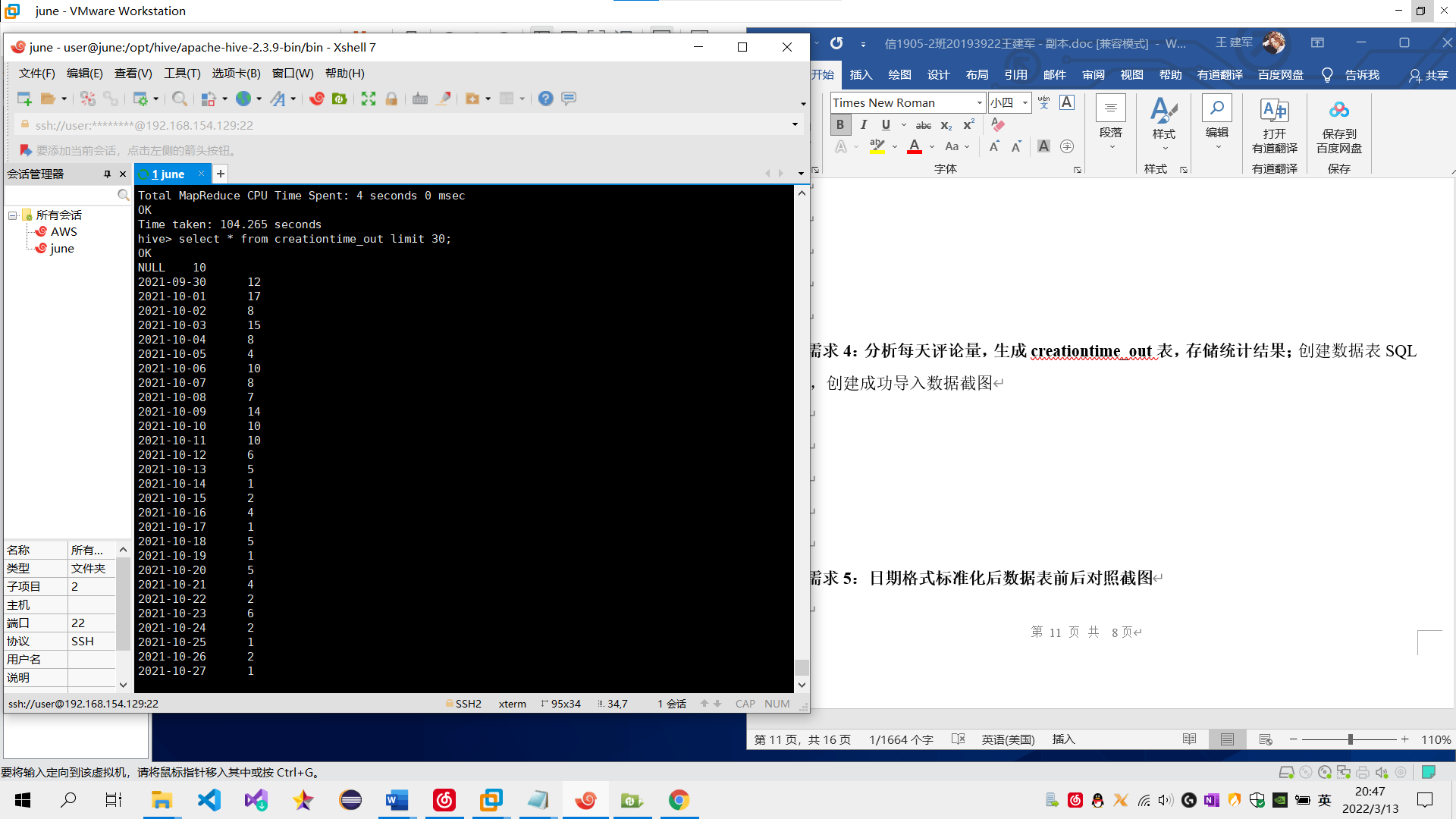
需求5:日期格式标准化后数据表前后对照截图 功能为:去掉评论时间的时分秒,只保留年月日
4、 利用Sqoop进行数据迁移至Mysql数据库:(5分)
五个表导入mysql数据库中五个表截图。
5、 数据可视化:利用JavaWeb+Echarts完成数据图表展示过程(20分)
需求1:可视化展示截图
需求2:可视化展示截图
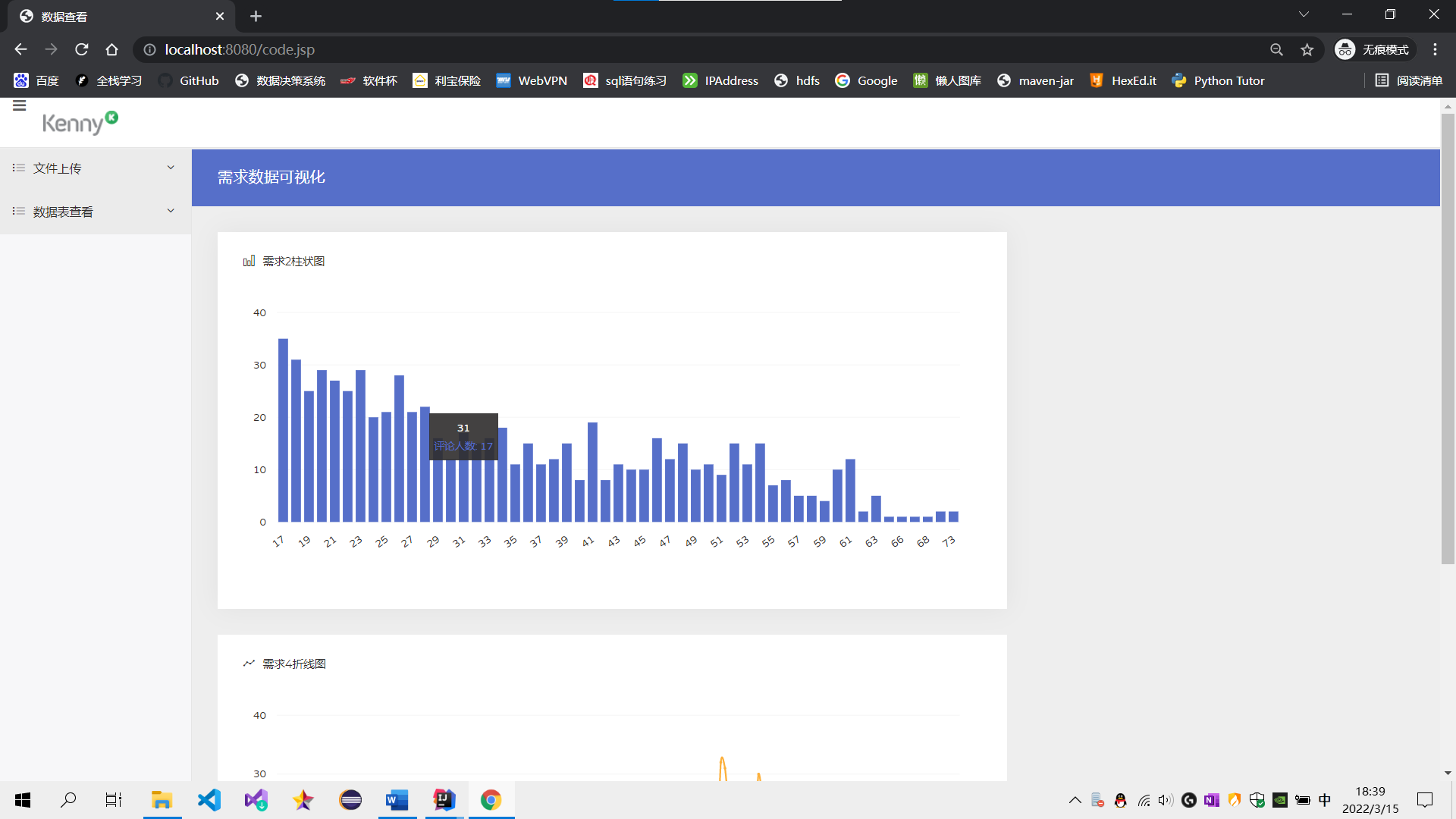
需求3:可视化展示截图
需求4:可视化展示截图
6、 中文分词实现用户评价分析。(20分)
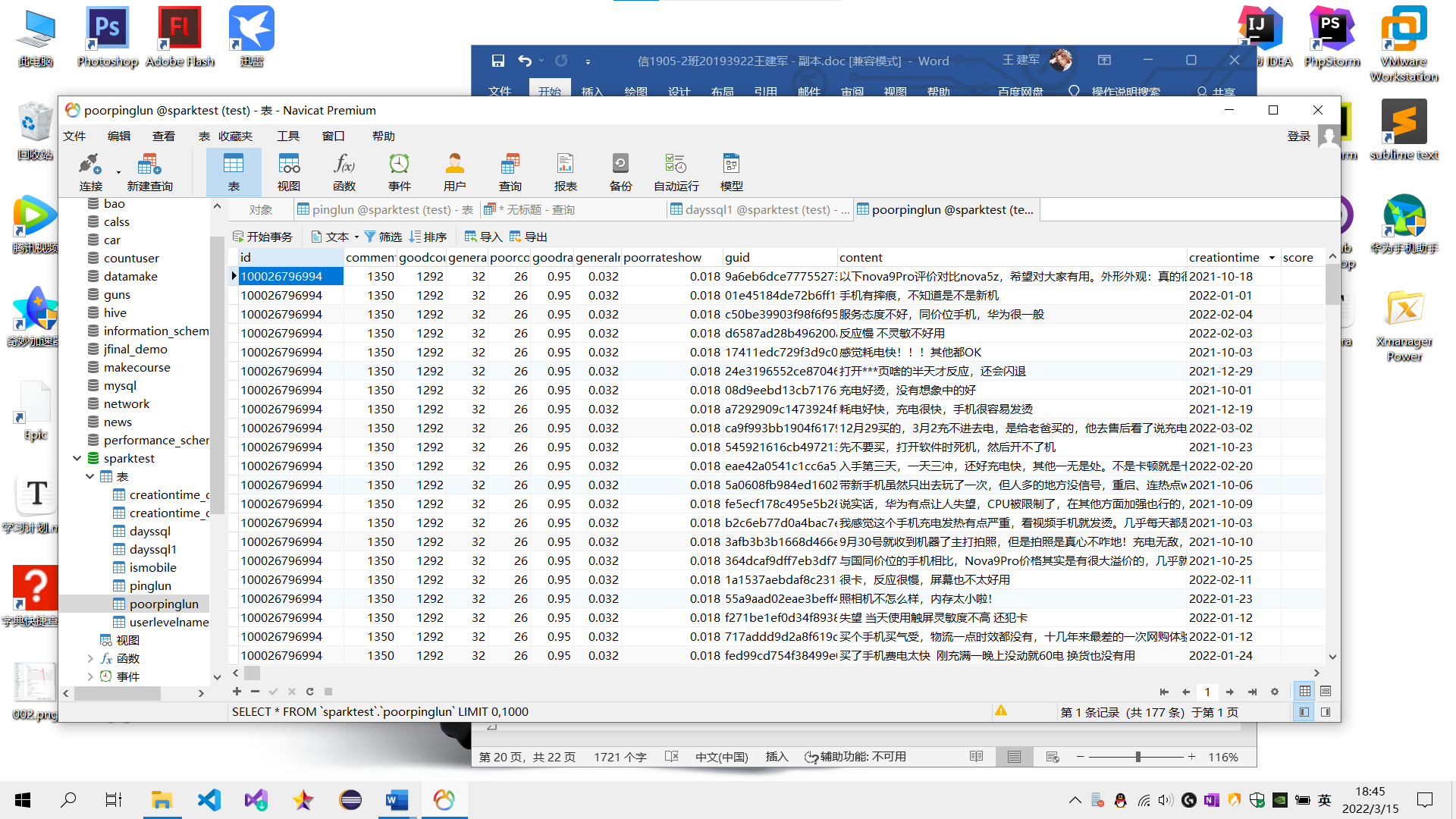
(1) 本节通过对商品评论表中的差评数据,进行分析,筛选用户差评点,以知己知彼。(筛选差评数据集截图)
Sql:create table poorpinglun as select * from pinglun where score < 4;
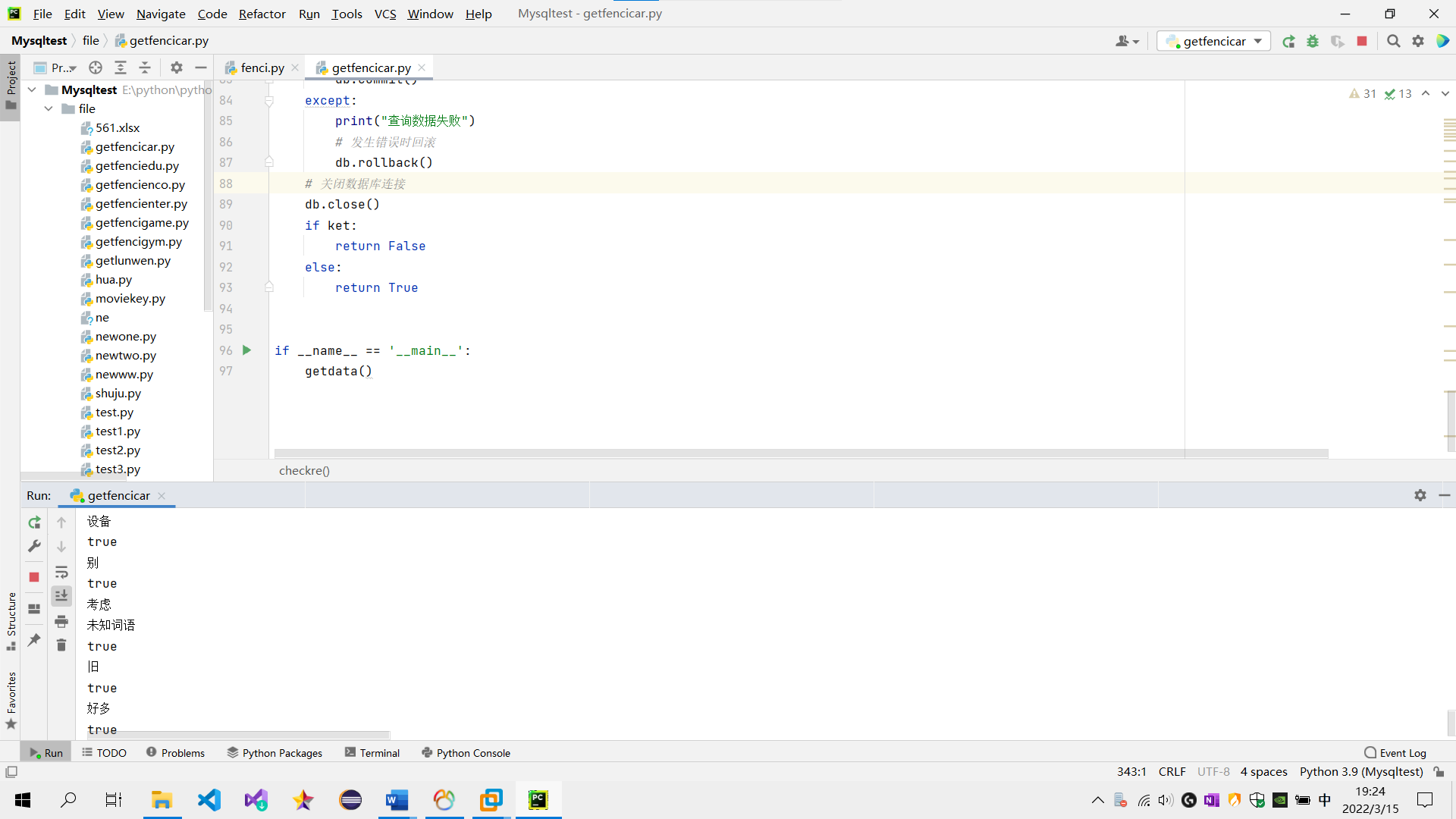
(2) 利用 python 结巴分词实现用户评价信息中的中文分词及词频统计;(分词后截图)
# -*- coding: utf-8 -*-
import pandas as pd
import pymysql
import jieba
def getdata():
dbconn=pymysql.connect(host="127.0.0.1", database="sparktest", user="root", password="lin0613", port=3306, charset='utf8')
#sql语句
sqlcmd="select content from poorpinglun limit 177"
#利用pandas 模块导入mysql数据
titles=pd.read_sql(sqlcmd,dbconn)
keywords =""
print(titles.values)
for i in range(len(titles)):
str =(",").join(titles.values[i])
word_list = jieba.cut(str)
keywords = list(word_list)
count = 0
for count in range(len(keywords)):
if checkword(keywords[count]):
flag = checkre(pymysql.connect(host="127.0.0.1", database="sparktest", user="root", password="lin0613", port=3306, charset='utf8'), keywords[count])
if flag:
save_keywords(pymysql.connect(host="127.0.0.1", database="sparktest", user="root", password="lin0613", port=3306, charset='utf8'), keywords[count])
print(keywords[count])
else:
updatenum(pymysql.connect(host="127.0.0.1", database="sparktest", user="root", password="lin0613", port=3306, charset='utf8'), keywords[count])
else:
print("未知词语")
def checkword(word):
invalid_words = [',', '.', ',', '。', ':', '“', '”', '"', '?', '?', '《', '》', '(', '{', ')', '}', '!', '%', '℃', '¥', '#']
if word.lower() in invalid_words:
return False
else:
return True
def save_keywords(db, keyword):
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
sql = "INSERT INTO key_pinglun1(keyword,num) VALUES ('%s',1)" % (keyword)
try:
# 执行sql语句
cursor.execute(sql)
# 执行sql语句
print("true")
db.commit()
except:
print("数据插入失败")
# 发生错误时回滚
db.rollback()
# 关闭数据库连接
db.close()
def updatenum(db,keyword):
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
sql = "update key_pinglun1 set num=num+1 where keyword = '%s' " % keyword
try:
# 执行sql语句
cursor.execute(sql)
# 执行sql语句
db.commit()
except:
print("数据更新失败")
# 发生错误时回滚
db.rollback()
# 关闭数据库连接
db.close()
def checkre(db, keyword):
# 使用cursor()方法获取操作游标
cursor = db.cursor()
ket = []
# SQL 插入语句
ket = []
sql = "select keyword from key_pinglun1 where keyword = '%s'" % keyword
try:
# 执行sql语句
cursor.execute(sql)
ket = list(cursor.fetchall())
db.commit()
except:
print("查询数据失败")
# 发生错误时回滚
db.rollback()
# 关闭数据库连接
db.close()
if ket:
return False
else:
return True
if __name__ == '__main__':
getdata()
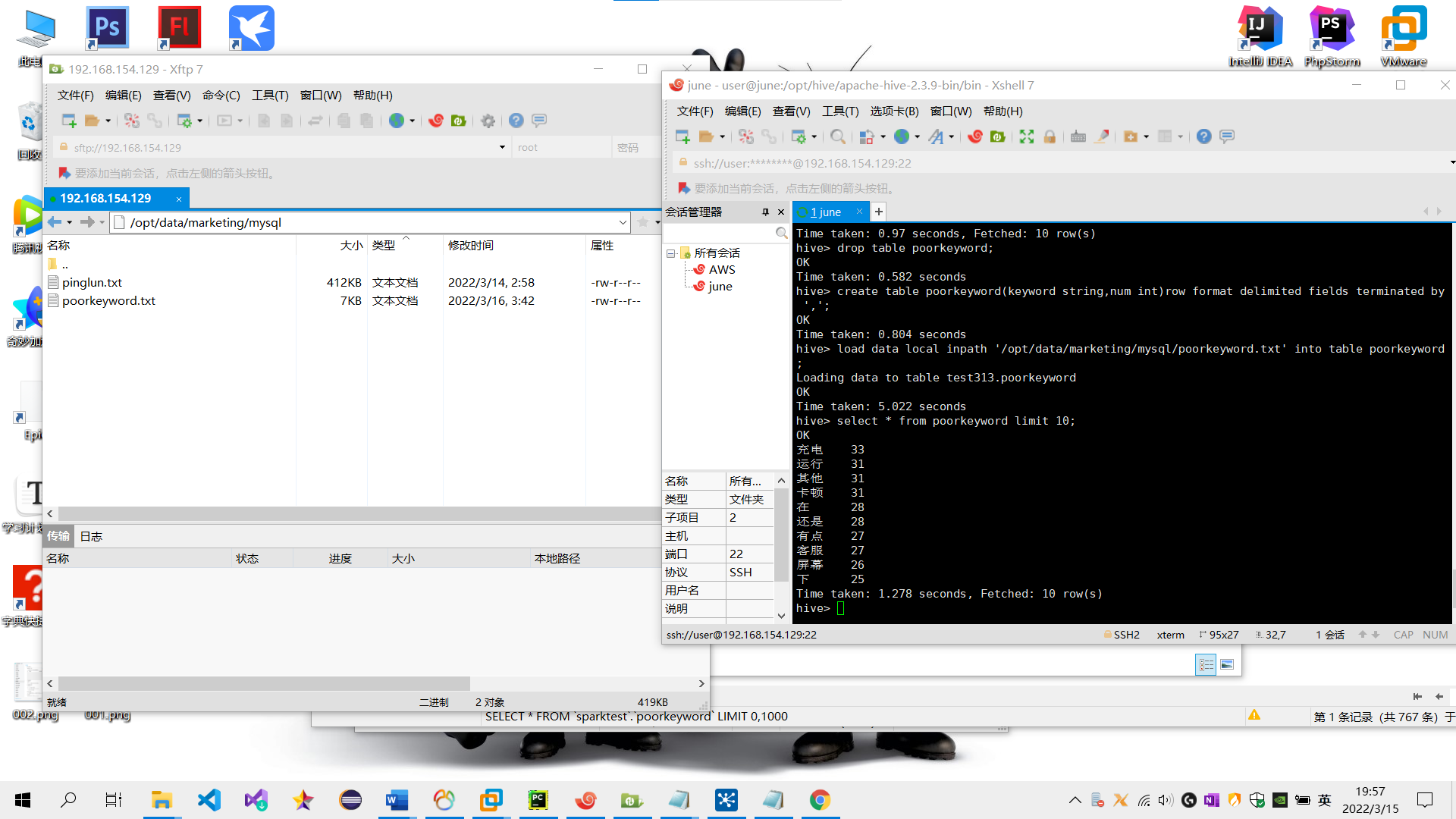
(3)在 hive 中新建词频统计表并加载分词数据;
④柱状图可视化展示用户差评的统计前十类。
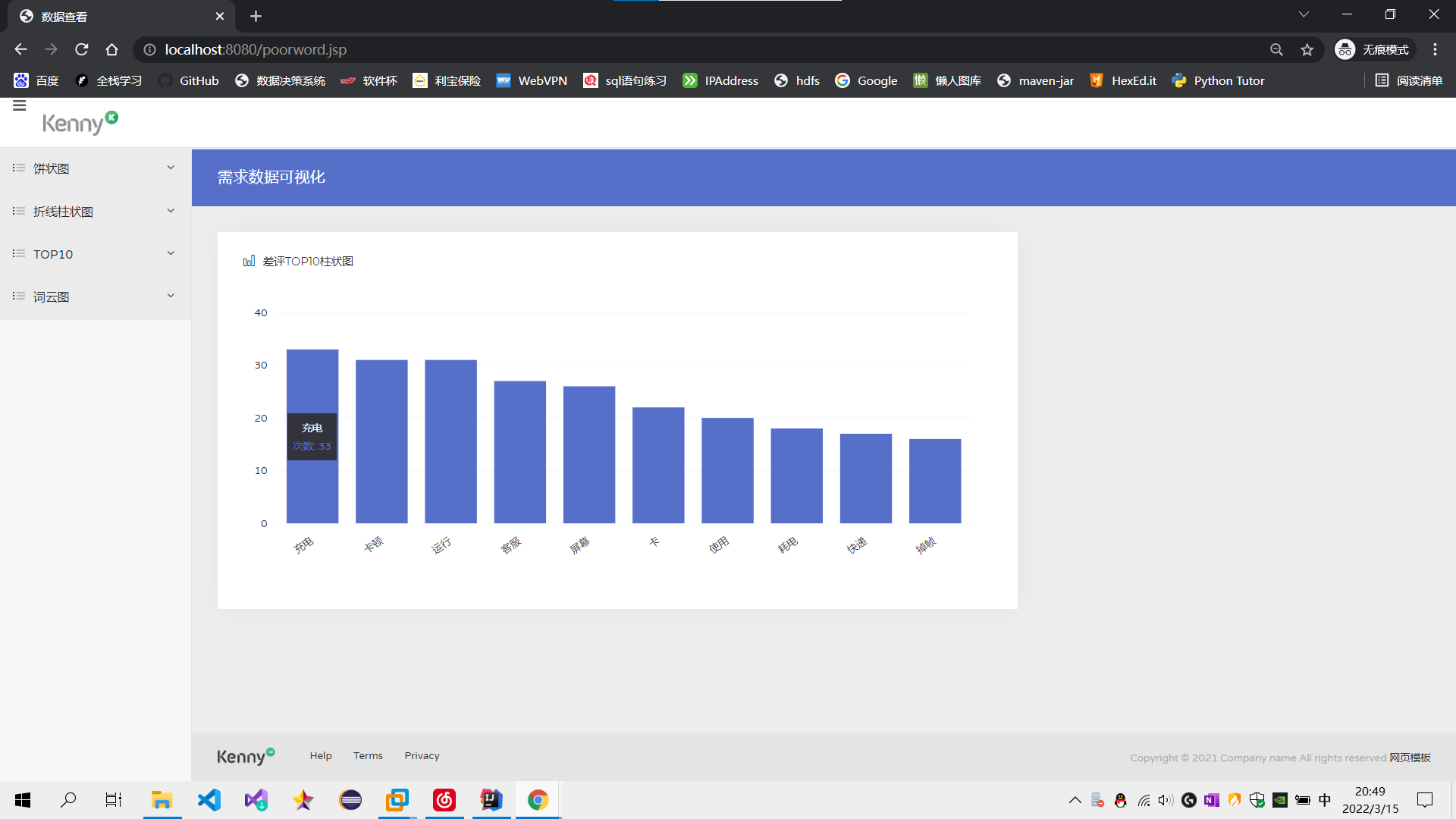
⑤用词云图可视化展示用户差评分词。
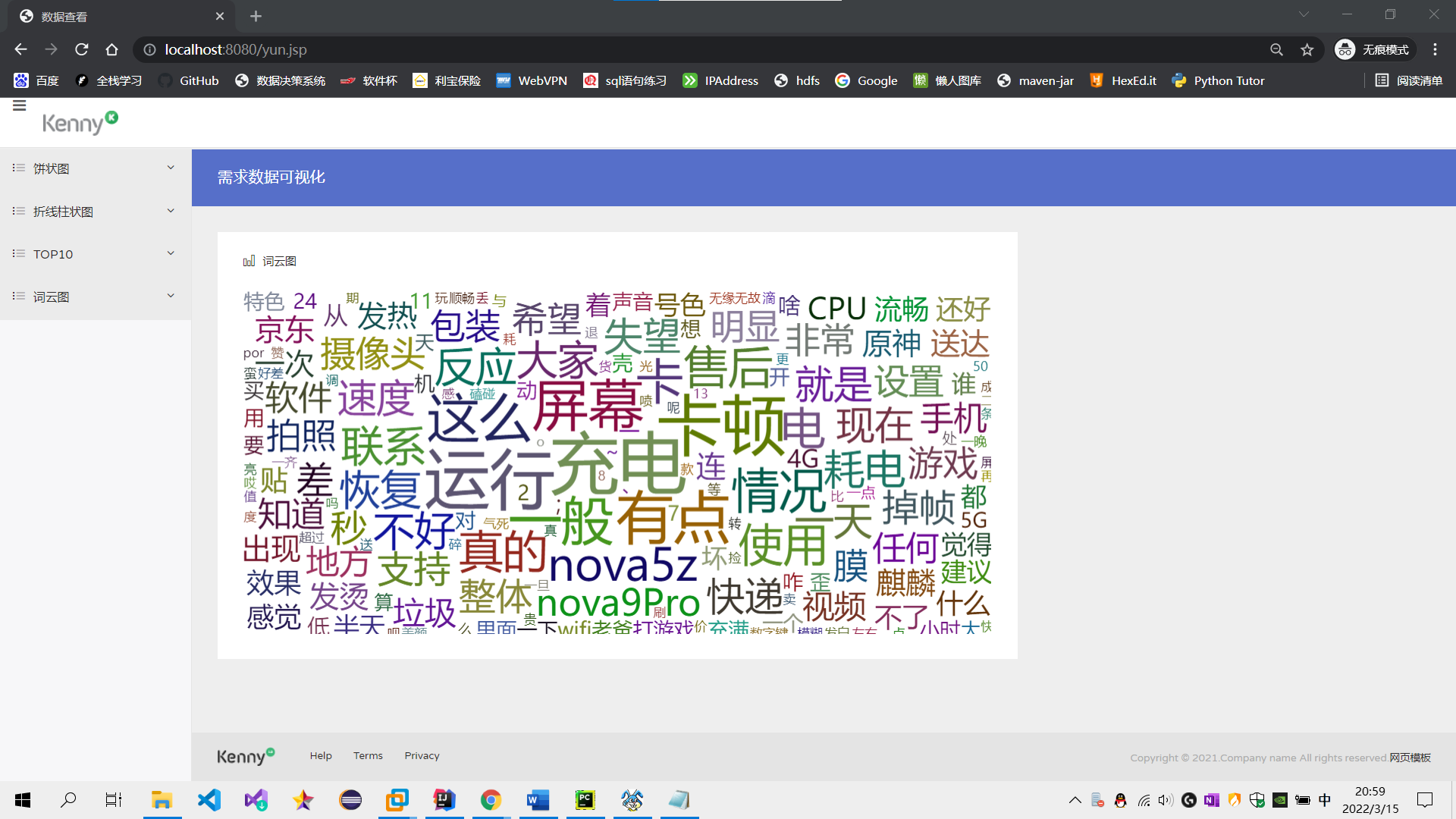
7、利用Spark进行实时数据分析。(20分)
本实验以京东商品评论为目标网站,架构采用爬虫+Flume+Kafka+Spark Streaming+Mysql,实现数据动态实时的采集、分析、展示数据。
__EOF__



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类
2021-03-14 Android学习笔记4