| 项目 |
内容 |
| 班级博客链接 |
点击这里 |
| 本次作业要求链接 |
点击这里 |
| 我的课程学习目标 |
(1)学习并掌握结对编程的相关知识。(2)通过实验提高自己的开发能力。 |
| 结对对方学号-姓名 |
201971010150-闫雨馨 |
| 结对方本次博客作业链接 |
闫雨馨的博客 |
| 本项目Github的仓库链接地址 |
刘温元的仓库 |
任务一:阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念
- 代码复审
- 代码复审的定义:看代码是否在代码规范的框架内正确地解决了问题。
- 目的
- 找出代码的错误。
- 发现逻辑错误。
- 发现算法错误。
- 发现潜在的错误和回归性错误。
- 发现可能需要改进的错误。
- 教育(互相教育)开发人员,传授经验,让更多的成员熟悉项目各部分的代码,同时熟悉和应用领域相关的实际知识。
- 步骤:
- 代码必须成功地编译。
- 程序员必须测试过代码。
- 程序员必须提供新的代码,以及文件差异分析工具。
- 在面对面的复审中,一般是开发者控制流程,讲述修改的前因后果。但是复审者有权在任何时候打断叙述,提出自己的意见。
- 复审者必须逐一提供反馈意见。
- 开发者必须负责让所有的问题都得到满意的解释或解答,或者在TFS中创建新的工作项以确保这些问题会得到处理。
- 对于复审的结果,双方必须达成一致的意见。
- 结对编程
- 好处:1.在开发层次,结对编程能提供更好的设计质量和代码质量,两人合作解决问题的能力更强。两人合作,还有相互激励的作用,工程师看到别人的思路和技能,得到实时的讲解,受到激励,从而努力提高自己的水平,提出更多创意。
2.对开发人员自身来说,结对工作能带来更多的信心,高质量的产出能带来更高的满足感。
3.在企业管理层次上,结对能更有效地交流,相互学习和传递经验,分享知识,能更好地应对人员流动。
- 两人合作的各个阶段:萌芽阶段 → 磨合阶段 → 规范阶段 → 创造阶段 → 解体阶段。
- 影响他人的方式:断言,桥梁,说服,吸引。
- 角色:驾驶员:控制键盘输入;领航员:起到领航、提醒的作用。
任务二:两两自由结对,对结对方《实验二 软件工程个人项目》的项目成果进行评价。
结对方信息:
- 博客地址
- 博文结构:博文结构清晰,版式整洁,错落有致,具有段落感。同时将一些重要的地方用高亮显示了出来,具有观看体验。
- 博文内容:实验内容完成度不错,基本实现了实验二中的要求,并对需求分析、功能设计及设计实现设计实现都进行了详细的称述。
- 博文结构与PSP中“任务内容”列的关系:博主的博文撰写流程是按照PSP的主要流程一步一步走下来的,具有较好的整体构思。
- PSP数据的差异化分析与原因探究:博主实际完成时间远大于计划完成时间,主要是在具体编码,代码复审与事后总结这三个阶段。结合我自己的开发经验,主要原因可能在于对PSP具体流程的不熟悉,自我估计不足等。也有可能是在开发过程中遇到了一些预料之外的突发情况等
代码核查表:
| 说明 |
内容 |
| 代码符合需求和规格说明么? |
基本符合,但部分功能完成度较差。 |
| 代码设计是否考虑周全? |
比较考虑周全 |
| 代码可读性如何? |
未采用模块化编程,可读性可以。 |
| 代码容易维护么? |
不易维护 |
| 代码的每一行都执行并检查过了吗? |
是 |
| 设计规范部分 |
|
| 设计是否遵从已知的设计模式或项目中常用的模式? |
没有 |
| 有没有硬编码或字符串/数字等存在? |
没有,采用的都是符合命名规范的变量名 |
| 代码有没有依赖于某一平台,是否会影响将来的移植? |
没有 |
| 开发者新写的代码能否用已有的Library/SDK/Framework中的功能实现? |
|
| 在本项目中是否存在类似的功能可以调用而不用全部重新实现? |
不知道 |
| 有没有无用的代码可以清除?(很多人想保留尽可能多的代码,因为以后可能会用上,这样导致程序文件中有很多注释掉的代码,这些代码都可以删除,因为源代码控制已经保存了原来的老代码) |
有 |
| 代码规范部分 |
|
| 修改的部分符合代码标准和风格么? |
不符合 |
| 具体代码部分 |
|
| 有没有对错误进行处理? |
|
| 对于调用的外部函数,是否检查了返回值或处理了异常 |
没有 |
| 参数传递有无错误,字符串的长度是字节的长度还是字符(可能是单/双字节)的长度,是以0开始计数还是以1开始计数? |
无错误;本项目中是以0开始计数。 |
| 有没有使用断言(Assert)来保证我们认为不变的条件真的得到满足? |
没有 |
| 对资源的利用是在哪里申请,在哪里释放的? |
|
| 有没有可能导致资源泄露(内存、文件、各种GUI资源、数据库访问的连接,等等)? |
|
| 有没有优化的空间? |
在内存中完成,有可能泄露 |
| 数据结构中有没有用不到的元素? |
没有 |
| 效能 |
|
| 代码的效能(Performance)如何? |
|
| 最坏的情况如何? |
基本达到要求 |
| 代码中,特别是循环中是否有明显可优化的部分(C++中反复创建类,C#中 string 的操作是否能用StringBuilder 来优化)? |
有 |
| 对于系统和网络调用是否会超时? |
|
| 如何处理? |
无相关功能 |
| 可读性 |
|
| 代码可读性如何? |
|
| 有没有足够的注释? |
代码注释较少,阅读比较困难 |
| 可测试性 |
|
| 代码是否需要更新或创建新的单元测试? |
|
| 针对特定领域的开发(如数据库、网页、多线程等),可以整理专门的核查表 |
需要 |
任务三完成情况说明:
PSP流程:
| PSP2.1 |
任务内容 |
计划完成需要的时间(min) |
实际完成需要的时间(min) |
| Planning |
计划 |
60 |
90 |
| Estimate |
估计这个任务需要多少时间,并规划大致工作步骤 |
70 |
85 |
| Development |
开发 |
2650 |
2850 |
| Analysis |
需求分析 (包括学习新技术) |
60 |
60 |
| Design Spec |
生成设计文档 |
50 |
60 |
| Design Review |
设计复审 (和同事审核设计文档) |
60 |
60 |
| Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
40 |
50 |
| Design |
具体设计 |
80 |
85 |
| Coding |
具体编码 |
2000 |
2300 |
| Test |
测试(自我测试,修改代码,提交修改) |
150 |
160 |
| Reporting |
报告 |
200 |
210 |
| Test Report |
测试报告 |
60 |
60 |
| Size Measurement |
计算工作量 |
50 |
55 |
| Postmortem & Process Improvement Plan |
事后总结 ,并提出过程改进计划 |
120 |
150 |
- 需求分析:
- 平台基础功能:实验二中的任务3
- D{0-1}KP实例数据集存储到数据库
- 平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据
- 人机交互界面要求为GUI界面
- 设计遗传算法求解D{0-1}KP
- 软件设计说明
- 前端界面
- 前端的GUI使用的是layui的框架,前端界面的显示是通过layui提供的模板,以及themeleaf、js等要素构成。
- 通过layui封装的js,即可实现数据的异步传输。
- 后台功能
- 路由转发:通过controller进行处理和转发
- 数据库的操作:通过从数据库中获取数据,构造json对象,返回到前端即可。
- 遗传算法
- 算法介绍:是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法通过数学的方式,利用计算机仿真运算,将问题的求解过程转换成类似生物进化中的染色体基因的交叉、变异等过程。是一种近似算法。
- 算法流程:
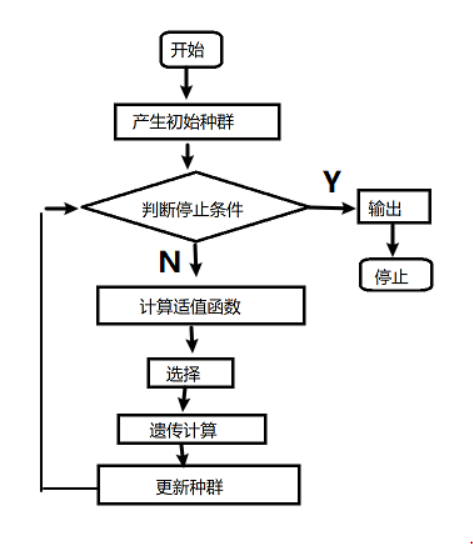
- 关键步骤如下:
- 基因编码:在这个过程中,尝试对一些个体的基因做一个描述,构造这些基因的结构,有点像确定函数自变量的过程。
- 设计初始群体:在这里需要造一个种群出来,这些种群有很多生物个体但基因不同。
- 适应度计算:这里对那些不符合要求的后代进行剔除,不让他们产生后代。否则他们产生的后代只会让计算量更大而对逼近目标没有增益。
- 产生下一代:有3种方法,即:直接选择,基因重组,基因突变
而后回到第三步进行循环,适应度计算,产生下一代,这样一代一代找下去,直到找到最优解为止。
- 项目测试
- GUI界面:

- 数据集有效信息:
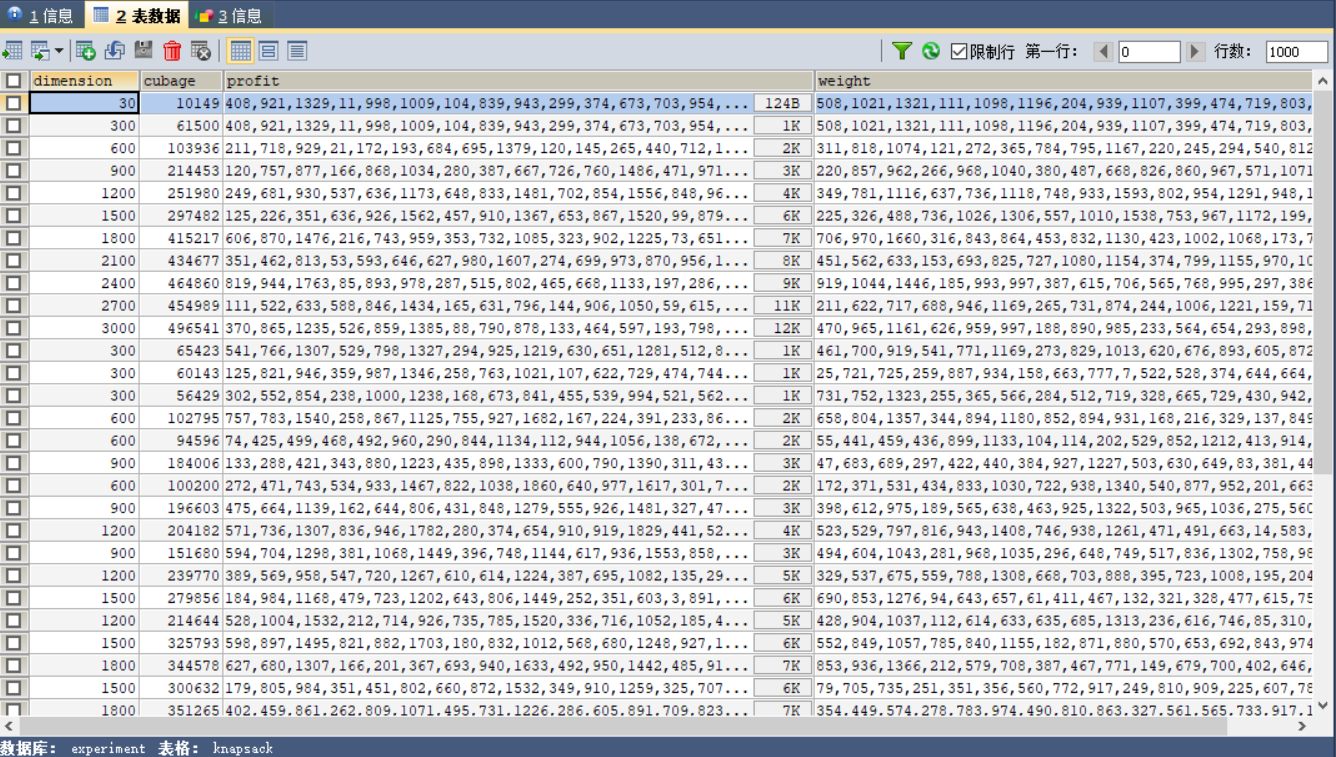
- 实验二任务3的移植:
- 数据集的查看:
- 散点图:

- 数据排序:
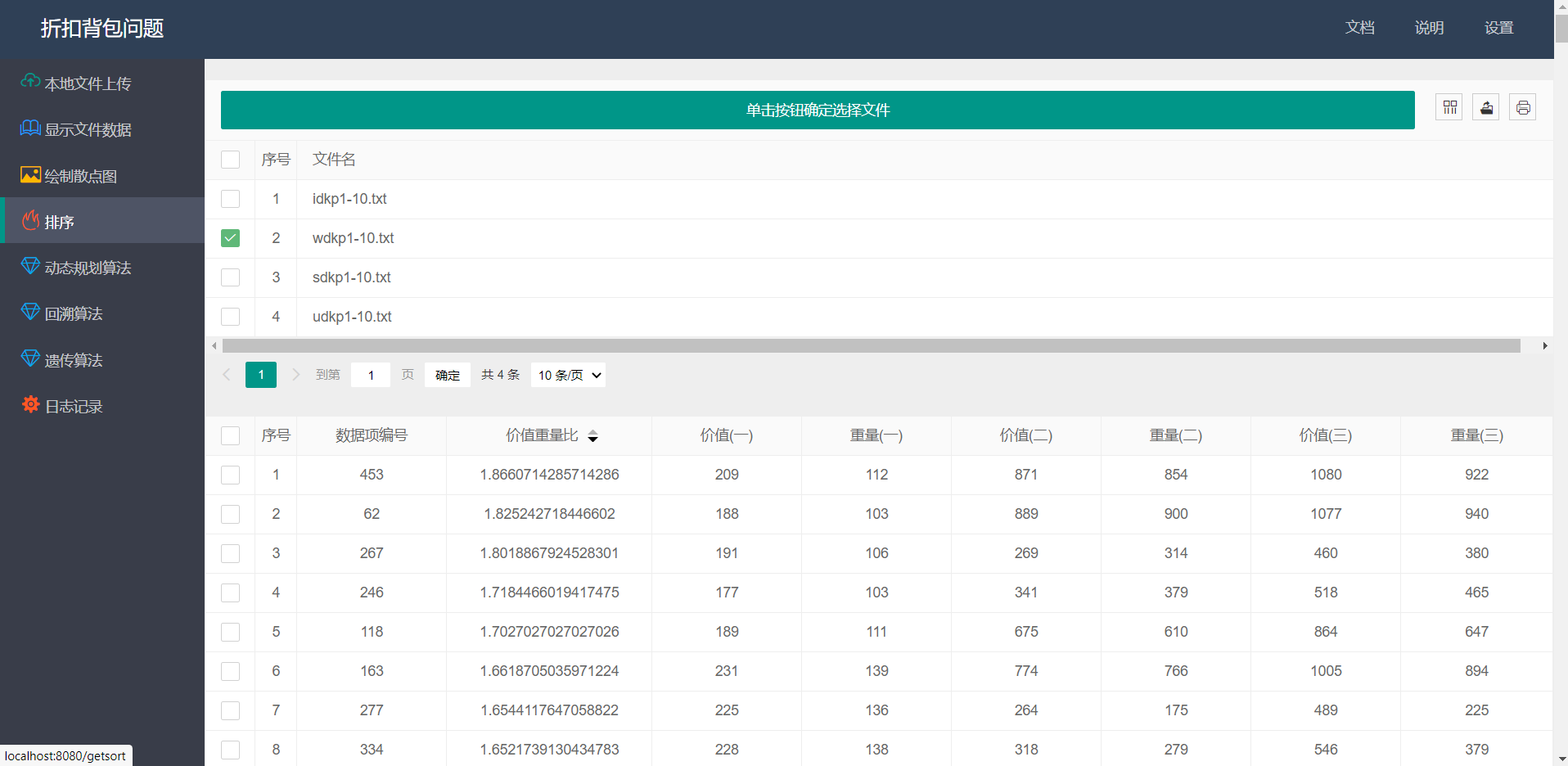
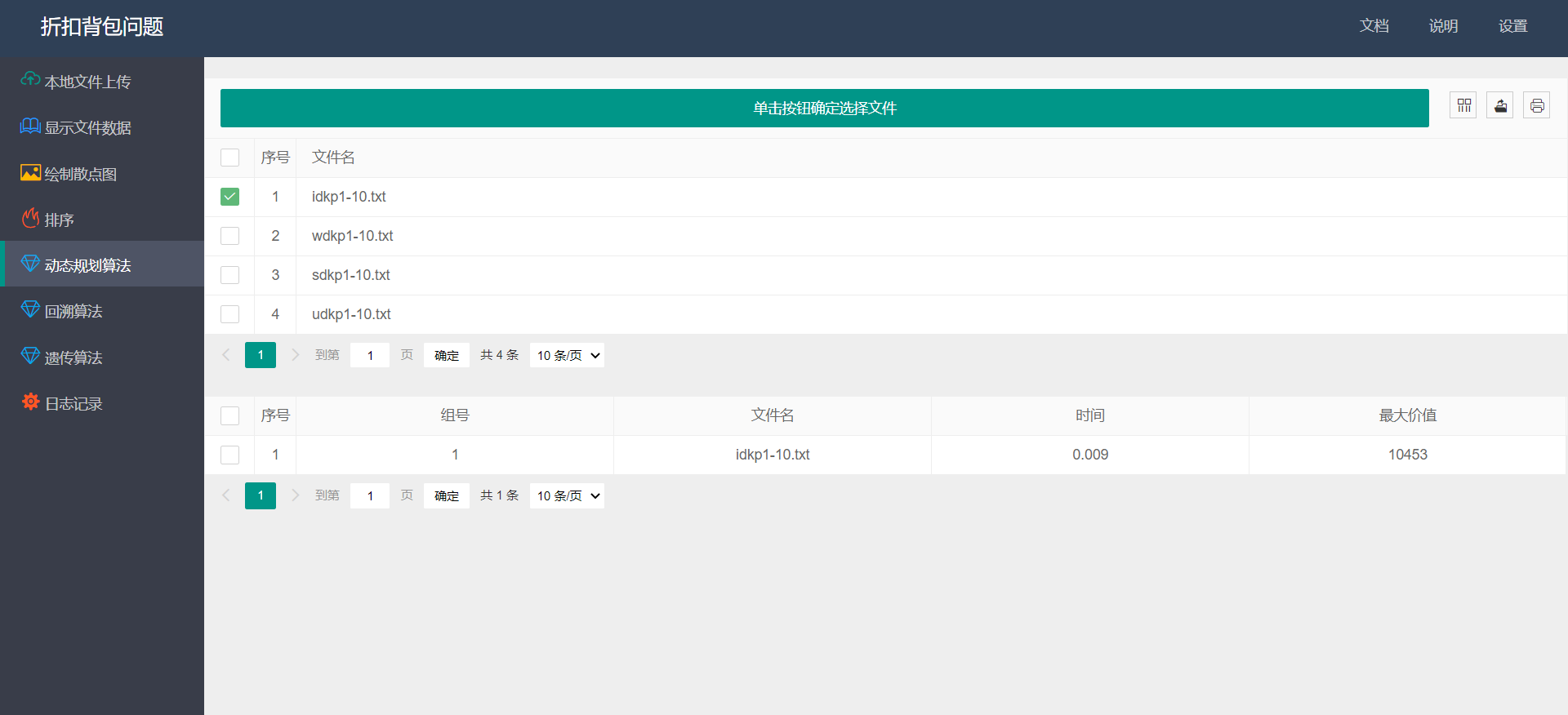
- 动态规划算法:
- 回溯算法:

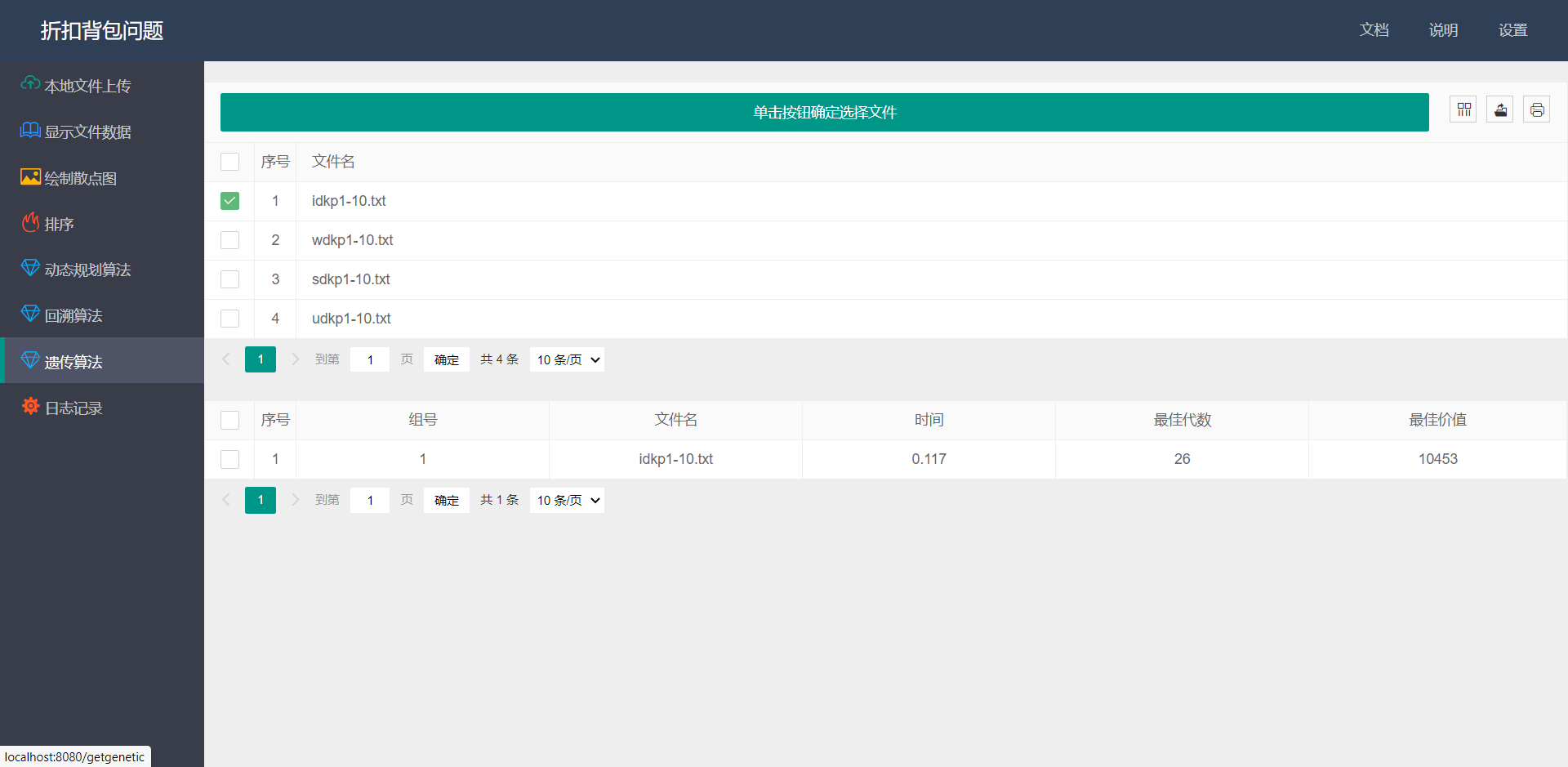
- 遗传算法:
软件实现及核心功能代码展示:
private void dfs(int x){
back_count++;
if(back_count>INF){
res=-1;
return ;
}
if(x>=row) {
return ;
}
else {
if(weight[x+1][2]<=back_weight) {
back_weight-=weight[x+1][2];
back_value+=value[x+1][2];
if(res<back_value) {
res=back_value;
}
dfs(x+1);
back_weight+=weight[x+1][2];
back_value-=value[x+1][2];
}
dfs(x+1);
if(weight[x+1][0]<=back_weight) {
back_weight-=weight[x+1][0];
back_value+=value[x+1][0];
dfs(x+1);
if(res<back_value) {
res=back_value;
}
back_weight+=weight[x+1][0];
back_value-=value[x+1][0];
}
if(weight[x+1][1]<=back_weight) {
back_weight-=weight[x+1][1];
back_value+=value[x+1][1];
if(res<back_value) {
res=back_value;
}
dfs(x+1);
back_weight+=weight[x+1][1];
back_value-=value[x+1][1];
}
}
}
private Long knapSack(int[] weight, int[] profit, int C)
{
int n = profit.length/3;//profit一定是3的倍数
int[][] maxvalue = new int[n + 1][C + 1];//价值矩阵
long before=System.currentTimeMillis();
for (int i = 0; i < maxvalue.length; i++) {
maxvalue[i][0] = 0;
}
for (int i = 0; i < maxvalue[0].length; i++) {
maxvalue[0][i] = 0;
}
for (int i = 1; i < maxvalue.length; i++) {//不处理第一行
for (int j = 1; j <maxvalue[0].length; j++) {//不处理第一列
//处理每一个项集
int index=(i-1)*3;//计算当前的索引值,这里以项集为单位进行计算
ArrayList<Integer> item=new ArrayList<>();
if (j<weight[index]&&j<weight[index+1]&&j<weight[index+2])
{
maxvalue[i][j]=maxvalue[i-1][j];
continue;
}
if(j>=weight[index])
item.add(Math.max(maxvalue[i-1][j],profit[index]+maxvalue[i-1][j-weight[index]]));
if(j>=weight[index+1])
item.add(Math.max(maxvalue[i-1][j],profit[index+1]+maxvalue[i-1][j-weight[index+1]]));
if(j>=weight[index+2])
item.add(Math.max(maxvalue[i-1][j],profit[index+2]+maxvalue[i-1][j-weight[index+2]]));
item.sort((Integer o1, Integer o2)->{
if (o1>o2) return -1;
else if (o1==o2) return 0;
else return 1;
});
maxvalue[i][j]=item.get(0);
}
}
long after=System.currentTimeMillis();
this.setOptimalSolution(maxvalue[n][C]);
return (after-before);
}
// 初始化种群
private void initGroup() {
int k, i;
for (k = 0; k < scale; k++)// 种群数
{
// 01编码
for (i = 0; i < LL; i++) {
oldPopulation[k][i] = random.nextInt(65535) % 2;
}
}
}
private best_one evaluate(int[] chromosome) {
// 010110
int vv = 0;
int bb = 0;
int str[]=new int[LL];
// 染色体,起始城市,城市1,城市2...城市n
for (int i = 0; i < LL; i++) {
if (chromosome[i] == 1) {
int temp=random.nextInt(65535) % 64;
if(temp<2) {
vv += v[i][temp];
bb += b[i][temp];
str[i] = temp + 1;
}
else{
vv += v[i][2];
bb += b[i][2];
str[i] = 3;
}
}
else {
str[i]=0;
}
}
if (bb > pb) {
// 超出背包体积
best_one x =new best_one();
x.x=0;x.y=str;
return x;
} else {
best_one x =new best_one();
x.x=vv;x.y=str;
return x;
}
}
// 计算种群中各个个体的累积概率,前提是已经计算出各个个体的适应度fitness[max],作为赌轮选择策略一部分,Pi[max]
private void countRate() {
int k;
double sumFitness = 0;// 适应度总和
int[] tempf = new int[scale];
for (k = 0; k < scale; k++) {
tempf[k] = fitness[k];
sumFitness += tempf[k];
}
Pi[0] = (float) (tempf[0] / sumFitness);
for (k = 1; k < scale; k++) {
Pi[k] = (float) (tempf[k] / sumFitness + Pi[k - 1]);
}
}
// 挑选某代种群中适应度最高的个体,直接复制到子代中
// 前提是已经计算出各个个体的适应度Fitness[max]
private void selectBestGh() {
int k, i, maxid;
int maxevaluation;
int max_str[] = null;
maxid = 0;
maxevaluation = fitness[0];
for (k = 1; k < scale; k++) {
if (maxevaluation < fitness[k]) {
maxevaluation = fitness[k];
max_str=fitness_str[k];
maxid = k;
}
}
if (bestLength < maxevaluation) {
bestLength = maxevaluation;
best_str=max_str;
bestT = t;// 最好的染色体出现的代数;
for (i = 0; i < LL; i++) {
bestTour[i] = oldPopulation[maxid][i];
}
}
// 复制染色体,k表示新染色体在种群中的位置,kk表示旧的染色体在种群中的位置
copyGh(0, maxid);// 将当代种群中适应度最高的染色体k复制到新种群中,排在第一位0
}
// 赌轮选择策略挑选
private void select() {
int k, i, selectId;
float ran1;
for (k = 1; k < scale; k++) {
ran1 = (float) (random.nextInt(65535) % 1000 / 1000.0);
// System.out.println("概率"+ran1);
// 产生方式
for (i = 0; i < scale; i++) {
if (ran1 <= Pi[i]) {
break;
}
}
selectId = i;
copyGh(k, selectId);
}
}
private void evolution() {
int k;
// 挑选某代种群中适应度最高的个体
selectBestGh();
// 赌轮选择策略挑选scale-1个下一代个体
select();
float r;
// 交叉方法
for (k = 0; k < scale; k = k + 2) {
r = random.nextFloat();// /产生概率
// System.out.println("交叉率..." + r);
if (r < Pc) {
// System.out.println(k + "与" + k + 1 + "进行交叉...");
OXCross(k, k + 1);// 进行交叉
} else {
r = random.nextFloat();// /产生概率
// System.out.println("变异率1..." + r);
// 变异
if (r < Pm) {
// System.out.println(k + "变异...");
OnCVariation(k);
}
r = random.nextFloat();// /产生概率
// System.out.println("变异率2..." + r);
// 变异
if (r < Pm) {
// System.out.println(k + 1 + "变异...");
OnCVariation(k + 1);
}
}
}
}
// 两点交叉算子
private void OXCross(int k1, int k2) {
int i, j, flag;
int ran1, ran2, temp = 0;
ran1 = random.nextInt(65535) % LL;
ran2 = random.nextInt(65535) % LL;
while (ran1 == ran2) {
ran2 = random.nextInt(65535) % LL;
}
if (ran1 > ran2)// 确保ran1<ran2
{
temp = ran1;
ran1 = ran2;
ran2 = temp;
}
flag = ran2 - ran1 + 1;// 个数
for (i = 0, j = ran1; i < flag; i++, j++) {
temp = newPopulation[k1][j];
newPopulation[k1][j] = newPopulation[k2][j];
newPopulation[k2][j] = temp;
}
}
// 多次对换变异算子
private void OnCVariation(int k) {
int ran1, ran2, temp;
int count;// 对换次数
count = random.nextInt(65535) % LL;
for (int i = 0; i < count; i++) {
ran1 = random.nextInt(65535) % LL;
ran2 = random.nextInt(65535) % LL;
while (ran1 == ran2) {
ran2 = random.nextInt(65535) % LL;
}
temp = newPopulation[k][ran1];
newPopulation[k][ran1] = newPopulation[k][ran2];
newPopulation[k][ran2] = temp;
}
}
private void solve() {
int i;
int k;
// 初始化种群
initGroup();
// 计算初始化种群适应度,Fitness[max]
for (k = 0; k < scale; k++) {
best_one temp= evaluate(oldPopulation[k]);
fitness[k]=temp.x;
fitness_str[k]=temp.y;
}
// 计算初始化种群中各个个体的累积概率,Pi[max]
countRate();
for (t = 0; t < MAX_GEN; t++) {
evolution();
// 将新种群newGroup复制到旧种群oldGroup中,准备下一代进化
for (k = 0; k < scale; k++) {
for (i = 0; i < LL; i++) {
oldPopulation[k][i] = newPopulation[k][i];
}
}
// 计算种群适应度
for (k = 0; k < scale; k++) {
best_one temp= evaluate(oldPopulation[k]);
fitness[k]=temp.x;
fitness_str[k]=temp.y;
}
// 计算种群中各个个体的累积概率
countRate();
}
}
- 结对过程
- 总结:
在组员积极交流且按照极限编程的方式进行项目开发是可以带来1+1>2的效果。结对编程要特别注意代码的规范问题,结对编程时要多保持交流,积极反馈当前遇到的问题与解决措施。在结对初期,由于对每个人的定位不够清楚,导致合作效率并没有想象的快,在多次沟通后也是解决了这一问题。而且结对的人都要努力完成自己的目标,如果两个人在一起工作时,其中一个人想偷懒去干别的,那么就会拖延工作进度。毕竟要把每个人所负责的部分结合在一起并不是一件容易的事,只有两人互相监督工作,才可以更高效的完成项目。同时两个人互相监督工作,还可以增强代码和产品质量,并有效的减少BUG。这为之后软件的易维护性奠定了基础。在编程中,相互讨论,可以更快更有效地解决问题,互相请教对方,可以得到能力上的互补。

