


分布式消息Kafka初步认识及基本应用
主要内容
1. Kafka产生背景
2. Kafka的架构
3. Kafka的安装部署及集群部署
4. Kafka的基本操作
5. Kafka的应用
Kafka产生背景
kafka 作为一个消息系统,早起设计的目的是用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)。活动流数据是所有的网站对用户 的使用情况做分析的时候要用到的最常规的部分,活动数据包括页面的访问量(PV)、被查看内容方面的信息以及搜索内容。这种数据通常的处理方式是先 把各种活动以日志的形式写入某种文件,然后周期性的对这些文件进行统计分 析。运营数据指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日 志等)。
使用消息系统的原因
1. 解耦: 消息系统在处理过程中插入一个隐含的,基于数据的接口层。
2. 冗余:消除队列持久化,防止数据丢失。
3. 扩展性:消除队列解耦处理过程,容易扩展处理。
4. 可恢复性:处理过程失效,恢复后可继续处理。
5. 顺序保证:Partition内部保证顺序。
6. 异步通信:消息先放入队列,等需要时再处理
术语
1. Broker:Kafka 集群内的一个或多个服务实例。一般一个物理节点上启动一个Broker,也可以启动多个。
2. Topic:发布到Kafka集群的消息的类别。
3. Partition:Partition 数据分区,是物理上的概述。每一个Topic有一个或多个Partition。
4. Producer:消息生产者
5. Consumer:消息消费者
6. Consumer Group:一组Consumer的集合
Kafka应用场景
- 构建可在系统或应用程序之间可靠获取数据的实时流数据管道。
- 构建实时流应用程序,可以转换或响应数据流。
分布式消息和订阅系统、高性能、高吞吐量;scala语言
内置分区、实现集群
行为跟踪:kafka可以用于跟踪用户浏览页面、搜索及其他行为。通过发布-订阅模式实时记录到对应的 topic 中,通过后端大数据平台接入处理分析,并做更进一步的实时处理和监控
日志收集:日志收集方面,有很多比较优秀的产品,比如ApacheFlume,很多公司使用 kafka 代理日志聚合。日志聚合表示从服务器上收集日志文件,然后放到一个集中的平台(文 件服务器)进行处理。在实际应用开发中,我们应用程序的 log 都会输出到本地的磁盘上, 排查问题的话通过 linux 命令来搞定,如果应用程序组成了负载均衡集群,并且集群的机器 有几十台以上,那么想通过日志快速定位到问题,就是很麻烦的事情了。所以一般都会做一 个日志统一收集平台管理 log 日志用来快速查询重要应用的问题。所以很多公司的套路都是 把应用日志几种到 kafka 上,然后分别导入到 es 和 hdfs 上,用来做实时检索分析和离线 统计数据备份等。而另一方面,kafka 本身又提供了很好的 api 来集成日志并且做日志收集
Kafka架构
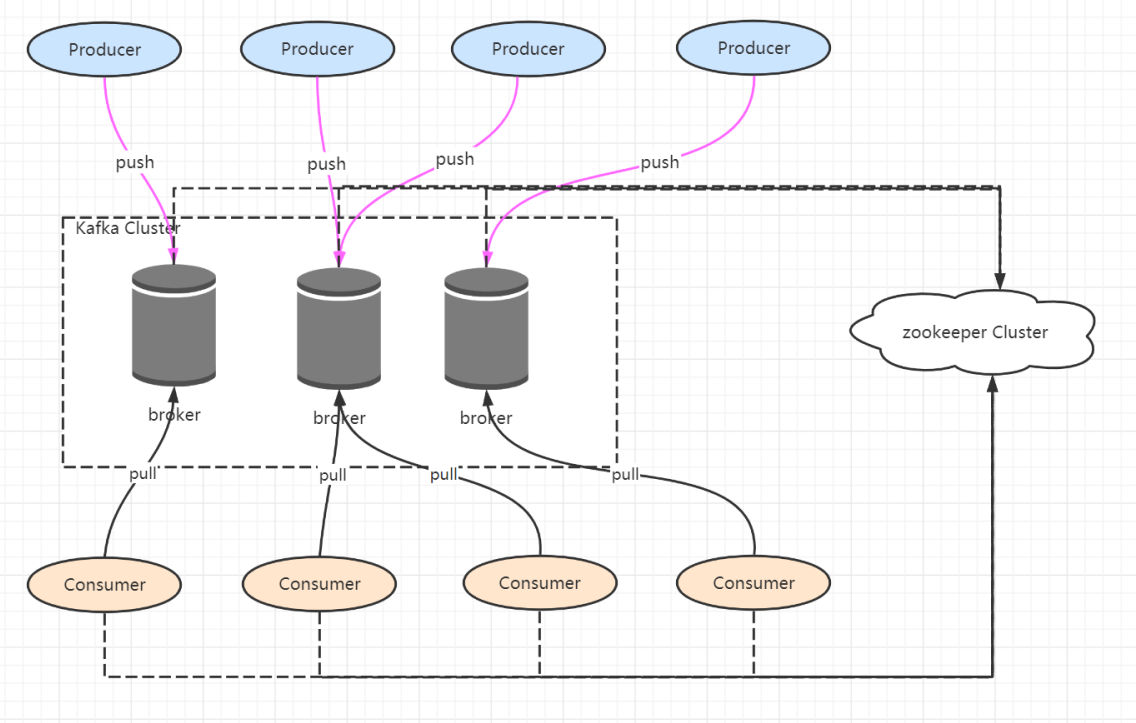
一个典型的Kafka集群包含若干个Producer、若干Broker、若干Consumer Group以及一个Zookeeper集群。 Kafka通过Zookeeper管理集群配置,选举Leader,以及在Consumer Group发生变化时进行rebalance。 Producer使用Push方式将消息发布到Broker,Consumer使得Pull模式从Broker订阅并消费消息。
1、Kafka环境搭建
1.1、下载kafka安装包,安装包格式为tgz
下载地址
http://archive.apache.org/dist/kafka/
2、解压kafka tgz包
tar -zxvf kafka_2.12-2.1.1.tgz
3、解压结果如下:
4、kafka目录
-
/bin 操作 kafka 的可执行脚本
-
/config 配置文件
-
/libs 依赖库目录
-
/logs 日志数据目录
5、解压完成后、直接进入bin目录
官方文档
http://kafka.apache.org/quickstart
6、kafka安装目录下的config文件夹为其配置文件,我们需要修改的有 server.properties和zookeeper.properties。
Kafka用到了Zookeeper,所有首先启动Zookper,下面简单的启用一个单实例的Zookkeeper服务。可以在命令的结尾加个&符号,这样就可以启动后离开控制台。
单机实例

7、Kafka服务器启动命令
# 启动命令、加上配置文件 sh kafka-server-start.sh ../config/server.properties
后台运行命令
# 后台服务运行命令 sh kafka-server-start.sh -daemon ../config/server.properties

1 #!/bin/sh 2 # system env 3 ENV_FILE=~/.bash_profile 4 # 判断是否有bash_profile文件 5 if [ ! -f "${ENV_FILE}" ]; then 6 source ${ENV_FILE} 7 fi 8 9 #source /etc/profile 10 ##java env 11 export JAVA_HOME=/home/java/jdk-12 12 export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH 13 export PATH=$PATH:$JAVA_HOME/bin 14 15 # kafka运行日志 16 kafka_home=/temp 17 18 # startApp="/home/programs/kafka_2.12-2.1.1/bin/kafka-server-start.sh -daemon /home/programs/kafka_2.12-2.1.1/config/server.properties" 19 20 startApp="$PWD/bin/kafka-server-start.sh -daemon $PWD/config/server.properties" 21 22 # 停止Kafka服务 23 function stop(){ 24 echo "stopping kafka" 25 SIGNAL=${SIGNAL:-TERM} 26 PIDS=$(ps ax | grep java | grep -i Kafka | grep -v grep | awk '{print $1}') 27 28 if [ -z "$PIDS" ]; then 29 echo "No kafka server to stop" 30 exit 1 31 else 32 kill -s $SIGNAL $PIDS 33 34 cleanlog 35 fi 36 echo "stoped success" 37 } 38 # 启动Kafka服务 39 function start(){ 40 echo "starting kafka" 41 # $startApp 42 COMMAND=$(ps ax | grep java | grep -i Kafka | grep -v grep | awk '{print $1}') 43 for((i=1;i<=5;i++)); 44 do 45 if [[ $COMMAND -le 0 ]]; then 46 $startApp 47 echo "start $i times" 48 sleep 10s 49 else 50 echo "process alived" 51 break 52 fi 53 done 54 echo "started sucess" 55 } 56 57 # 重启kafka服务 58 function restart(){ 59 echo "restarting kafka" 60 echo "kafka process is $(ps ax | grep java | grep -i Kafka | grep -v grep | awk '{print $1}')" 61 stop 62 63 sleep 10s 64 start 65 echo "kafka process is $(ps ax | grep java | grep -i Kafka | grep -v grep | awk '{print $1}')" 66 echo "restarted success" 67 } 68 69 function cleanlog(){ 70 echo "删除kafka的临时目录$kafka_home" 71 # 删除kafka的临时目录 72 rm $kafka_home/kafka-logs/* -rf 73 echo "done 删除kafka的临时目录" 74 } 75 76 case "$1" in 77 start) 78 start 79 ;; 80 stop) 81 stop 82 ;; 83 restart) 84 restart 85 ;; 86 * ) 87 echo "no command" 88 ;; 89 esac 90 exit 0
2、创建Topic 命令
// 单实例
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test

--create: 指定创建topic动作
--topic: 指定新建topic的名称
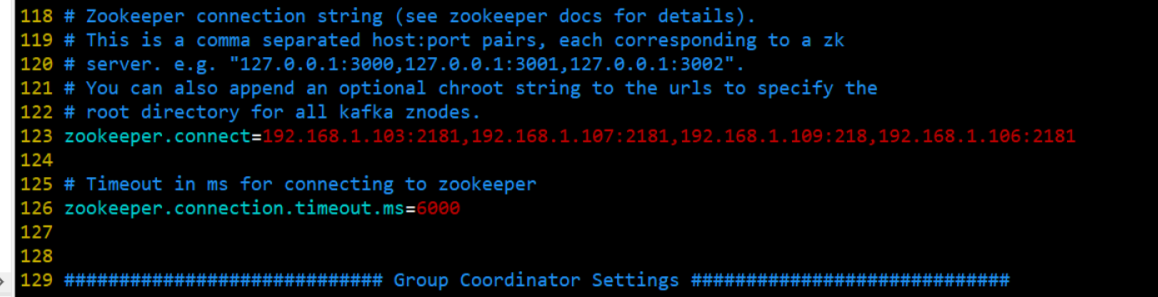
--zookeeper: 指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
--config: 指定当前topic上有效的参数值,参数列表参考文档为: [Topic-level configuration](http://kafka.apache.org/082/documentation.html#brokerconfigs)
--partitions: 指定当前创建的kafka分区数量,默认为1个
--replication-factor:指定每个分区的复制因子个数,默认1个
3、查看kafka中当前topic的情况
# 查看topic 列表 sh kafka-topics.sh --list --zookeeper localhost:2181
4、发送消息命令
sh kafka-console-producer.sh --topic test --bootstrap-server localhost:9092
5、Kafka consumer消费端开启监听 消费消息
sh kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server localhost:9092

集群环境部署
修改server.properties配置
-
修改 server.properties. broker.id=0 / 1
-
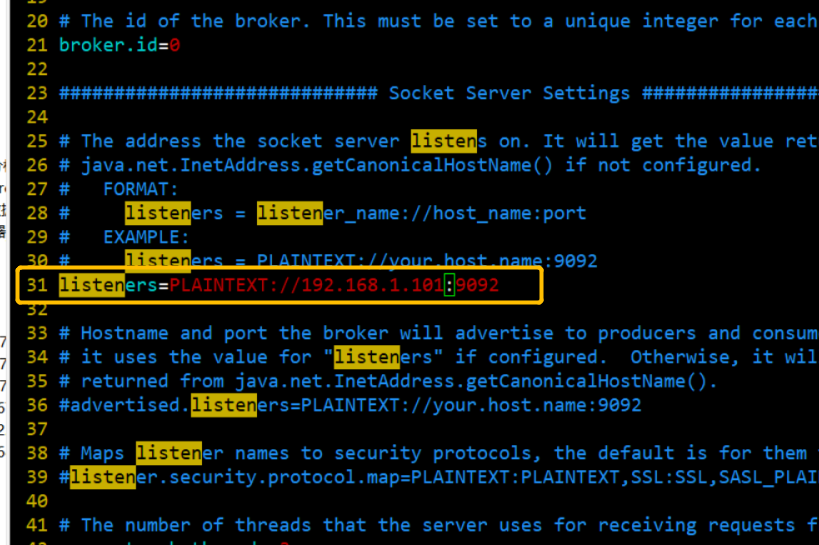
修改 server.properties 修改成本机 IP
advertised.listeners=PLAINTEXT://192.168.11.153:9092
如果要配置集群需要指定当前本机iP 地址,当 Kafka broker 启动时,它会在 ZK 上注册自己的 IP 和端口号,客户端就通过这个 IP 和端口号来连接
Kafka 基本使用
1、引入maven jar 包
<dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.0</version> </dependency> </dependencies>
2、kafka 消息生产者


1 package com.learn.kafka; 2 3 import org.apache.kafka.clients.producer.KafkaProducer; 4 import org.apache.kafka.clients.producer.ProducerConfig; 5 import org.apache.kafka.clients.producer.ProducerRecord; 6 7 import java.util.Properties; 8 import java.util.concurrent.TimeUnit; 9 10 /** 11 * Kafka 消息生产者 12 * 13 * @Author: cong zhi 14 * @CreateDate: 2021/3/2 15:37 15 * @UpdateUser: cong zhi 16 * @UpdateDate: 2021/3/2 15:37 17 * @UpdateRemark: 修改内容 18 * @Version: 1.0 19 */ 20 public class KafkaProducerDemo extends Thread { 21 22 private final KafkaProducer<Integer, String> producer; 23 24 private final String topic; 25 26 27 public KafkaProducerDemo(String topic) { 28 Properties properties = new Properties(); 29 // kafka 集群地址 30 properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.101:9092,192.168.1.111:9092"); 31 properties.setProperty(ProducerConfig.CLIENT_ID_CONFIG, "KafkaProducerDemo"); 32 // 设置broke ACK应答机制 33 properties.setProperty(ProducerConfig.ACKS_CONFIG, "-1"); 34 // 设置key序列化 35 properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerSerializer"); 36 properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); 37 producer = new KafkaProducer<Integer, String>(properties); 38 this.topic = topic; 39 } 40 41 @Override 42 public void run() { 43 int num = 0; 44 while (num < 50) { 45 String message = "message_" + num; 46 System.out.println("begin send message:" + message); 47 producer.send(new ProducerRecord<Integer, String>(topic, message)); 48 try { 49 TimeUnit.SECONDS.sleep(1000); 50 num++; 51 } catch (InterruptedException e) { 52 e.printStackTrace(); 53 } 54 55 56 } 57 } 58 59 public static void main(String[] args) { 60 new KafkaProducerDemo("test").start(); 61 } 62 }
3、Kafka 消息消费者
1 package com.learn.kafka; 2 3 import org.apache.kafka.clients.consumer.ConsumerConfig; 4 import org.apache.kafka.clients.consumer.ConsumerRecord; 5 import org.apache.kafka.clients.consumer.ConsumerRecords; 6 import org.apache.kafka.clients.consumer.KafkaConsumer; 7 8 import java.util.Collections; 9 import java.util.Properties; 10 /** 11 * kafka 消费者 12 * @Author: cong zhi 13 * @CreateDate: 2021/3/2 15:38 14 * @UpdateUser: cong zhi 15 * @UpdateDate: 2021/3/2 15:38 16 * @UpdateRemark: 修改内容 17 * @Version: 1.0 18 */ 19 public class KafkaConsumerDemo extends Thread { 20 21 private KafkaConsumer kafkaConsumer; 22 23 @Override 24 public void run() { 25 while (true) { 26 ConsumerRecords<Integer, String> consumerRecord = kafkaConsumer.poll(1000); 27 for (ConsumerRecord<Integer, String> record : consumerRecord) { 28 System.out.println("message recevie:" + record.value()); 29 } 30 } 31 } 32 33 public KafkaConsumerDemo(String topic) { 34 Properties properties = new Properties(); 35 // kafka 集群地址 36 properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.101:9092,192.168.1.111:9092"); 37 // 消费组 38 properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerDemo"); 39 properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); 40 // 设置间隔时间 41 properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "10000"); 42 // 反序列化 43 properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerDeserializer"); 44 properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); 45 this.kafkaConsumer = new KafkaConsumer(properties); 46 kafkaConsumer.subscribe(Collections.singletonList(topic)); 47 48 } 49 50 public static void main(String[] args) { 51 new KafkaConsumerDemo("test").start(); 52 } 53 }
输出结果如下:
配置信息分析
**发送端的可选配置信息分析**
ProducerConfig.ACKS_CONFIG(acks) "-1"
acks 配置表示 producer 发送消息到 broker 上以后的确认值。有三个可选项
0: 表示producer不需要等待broker的消息确认。这个选项时延最小但同时风险最大(因为当 server 宕机时,数据将会丢失)。
1: 表示producer只需要获得kafka集群中的leader节点确认即可(leader/follower),这个选择时延较小同时确保了 leader 节点确认接收成功。
all(-1):需要ISR中所有的Replica给予接收确认,速度最慢,安全性最高,但是由于 ISR 可能会缩小到仅包含一个 Replica,所以设置参数为 all 并不能一 定避免数据丢失,
batch.size(16kb) producer对于同一个分区来说,会按照batch.size 的大小进行统一收集批量发送
linger.ms (1000) 默认值是0 ,意味着如果设置batch.size是不生效
Producer 默认会把两次发送时间间隔内收集到的所有 Requests 进行一次聚合 然后再发送,以此提高吞吐量,而 linger.ms 就是为每次发送到 broker 的请求 增加一些 delay,以此来聚合更多的 Message 请求。 这个有点像TCP 里面的 Nagle 算法,在 TCP 协议的传输中,为了减少大量小数据包的发送,采用了 Nagle 算法,也就是基于小包的等-停协议。
max.request.size 设置当前请求大小,默认请求是1M
总结
简单的开发一个kafka的程序需要以下步骤:
1. 成功搭建kafka服务器,并成功启动!
2. 得到kafka服务信息,然后在代码中进行kafka相应的配置。
3. 配置完成之后,监听kafka中的消息队列是否有消息产生。
4. 将产生的数据进行业务逻辑处理



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗