


Java 集合框架
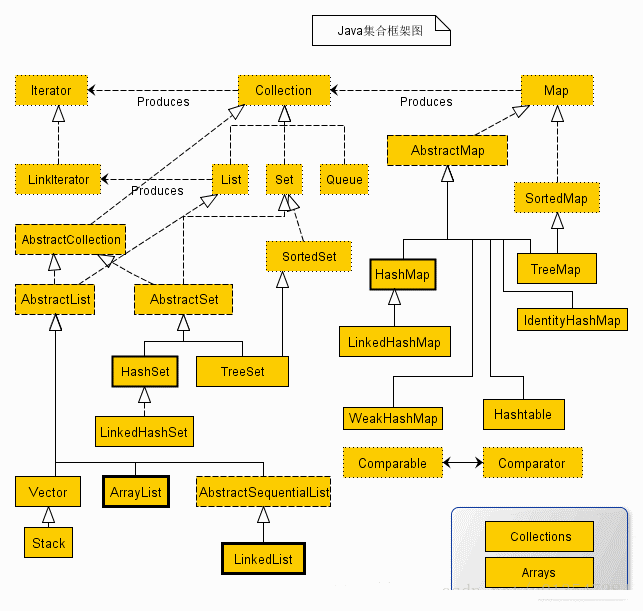
集合类的由来:
对象用于封装特有数据,对象多了需要存储,如果对象的个数不确定。就使用集合容器进行存储。
集合特点:
1、用于存储对象的容器。
2、集合的长度是可变的。
3、集合中不可以存储基本数据类型值。
集合容器因为内部的数据结构不同,有多种具体容器。不断的向上抽取,就形成了集合框架。
框架的顶层Collection接口:
Collection的常见方法:
1、添加:
boolean add(Object obj);
boolean addAll(Object obj); //将指定 collection 中的所有元素都添加到此 collection 中(可选操作)。
2、删除:
boolean remove(Object obj);
boolean removeAll(Collection coll); //将两个集合中的相同元素从调用removeAll的集合中删除。
void clear();
3、判断:
boolean contains(Object obj);
boolean containsAll(Collection coll); //如果此 collection 包含指定 collection 中的所有元素,则返回 true。
boolean isEmpty(); //判断集合中是否有元素。
4、获取:
int size(); //返回此 collection 中的元素数。
Iterator iterator(); //取出元素的方式,迭代器
该对象必须依赖于具体容器,因为每一个容器的数据结构都不同。所以该迭代器对象是在容器中进行内部实现的。对于使用容器者而言,具体的实现不重要,只要通过容器获取到该实现的迭代器的对象即可。也就是iterator方法。
5、其他:
boolean retainAll(Collection coll); //取交集,保留和指定的集合相同的元素,而删除不同元素。
Object[] toArray(); //将集合转成数组。
------------------------------------------------------------------------
list和Set的特点:
Collection
| -- List:有序(存入和取出的顺序一致),元素都有索引(角标),元素可以重复。
| -- Set:元素不能重复,无序。
List:特有的常见方法:有一个共性特点就是都可以操作角标。
1、添加:
void add(index,element);
void add(index,collection);
2、删除:
Object remove(index);
3、修改:
Object set(index,element);
4、获取:
Object get(index);
int indexOf(Object);
int lastIndexOf(Objectj);
List subList(from,to);
List集合是可以完成对元素的增删改查。
List:
| -- Vector:内部是数组数据结构,是线程安全的。增、删、查都很慢!效率低
| -- ArrayList:内部是数组数据结构,是线程不安全的。替代了Vector。查询的速度很快、增删慢。ArrayList是List接口实现类,可以动态调整大小的数组。
不同步,默认初始容量为10,当元素超过10个以后,会重新分配内存空间,并将所有的对象从较小的数组中拷贝到较大数组中,那么容量变化的规则是(旧容量*3)/2+1
| -- LinkedList:内部链表的数据结构,是线程不安全的。增、删除元素的速度很快,查询很慢效率高。
底层数据结构由链表和哈希表组成。由链表保证元素有序。
由哈希表保证元素唯一。
LinkedList:
addFirst();
addLast();
getFirst(); // 获取但不移除,如果链表为空,抛出NoSuchElementException
getLast();
jdk1.6
peekFirst(); //获取但不移除,如果链表为空,返回Null
peekLast();
removeFirst();
removeLast();
jdk1.6
pollFirst(); // 获取但不移除,如果链表为欧诺个,抛出NoSuchElementException
pollLast(); //获取但不移除,如果链表为空,返回Null
----------------------------------------------------------------------------
Set:元素唯一、是无序。
set接口中的方法和collection一致。
| -- HashSet:内部数据结构是哈希表,是不同步的。
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值是true:说明元素重复,不添加是false:就直接添加到集合。
否:就直接添加到集合
最终:自动生成hashCode()和equals()即可
| -- TreeSet:可以对Set集合中的元素进行排序。底层数据结构是红黑树。(是一种自平衡的二叉树)
判断元素的唯一性的方式,就是根据比较方法的返回结果是否是0,是,就是相同元素,不存
TreeSet对象元素进行排序的方式一:
让元素自身具备比较功能,元素就需要实现comparble接口。覆盖compareTo方法。如果不要按照对象中具备的自然顺序进行排序,如果对象中不具备自然顺排序,怎么办?
可以使用TreeSet集合第二种排序方式二:
让集合自身具备比较功能,定义一个类实现comparator接口,覆盖compare方法。将该类对象作为参数传递给TreeSet集合的构造函数。
哈希值确定元素是否相同:
1、判断是否两个元素的哈希值是否相同。
如果相同,再判断两个对象的是否内容相同。
2、判断哈希值相同,其实判断的是对象的hashCode的方法。and内容相同,用的是euals方法。
注意:如果哈希值不同,是不需要判断equals。
HashSet集合数据结构是哈希表 ,所以存储元素的时候,使用的元素hashCode方法来确定位置,如果位置相同,在通过元素来确定是否相同。
---------------------------------------------------------------------------------------
Map :
一次添加一对元素。Map的每一个元素由两部分组成,分别是 key(键)和 value(值)Collection 一次添加一个元素。
Map 也称为双列集合,Collection集合称为单列集合。其实map集合中存储的就是键值对。Map集合中必须保证键的唯一性。
Map底层实现是数组和链表
常用方法:
1、添加:
value put(key,value); //返回前一个和key关联的值,如果没有则返回null。
2、删除:
void clear(); //清空map集合。
3、判断:
boolean containsKey(Object key) ; //如果此映射包含指定键的映射,则返回 true 。
boolean containsValue(Object value) ; //如果此地图将一个或多个键映射到指定的值,则返回 true 。
boolean isEmpty() ; //如果此地图不包含键值映射,则返回 true 。
4、获取:
value get(key); //返回到指定键所映射的值,或 null如果此映射包含该键的映射。
int size(); //获取键值对的个数。
Map常用子类
| -- HashTable :内部结构是哈希表,是线程同步的,效率低。不允许null值(key和value都不允许null)。
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值是true:说明元素重复,不添加是false:就直接添加到集合。
否:就直接添加到集合。
最终:自动生成hashCode()和equals()即可。
| -- Properties: 用来存储键值对型的配置文件的信息,可以和IO技术相结合。
| -- HashMap :内部结构是哈希表,不是同步的。允许null值(key和value都允许null)。HashMap扩容标准16 * 0.75 =12,
HashMap非线程安全扩容必须满足两个条件:
1、存放新值的时候当前已有元素的个数必须大于等于阈值。
2、存放新值的时候当前存放数据发送hash碰撞(当前key计算的hash值换算出来的数组下标位置已经存在值)。
ArrayList,Vector,LinkedList的存储性能和特性HashMap和Hashtable的区别
ArrayList实现了长度可变的数组,在内存分配连续的空间,遍历元素和随机 访问元素的效率比较高。
Vector:以数组的方式存储,增、删慢,查、改快。
ArrayList:线程不安全,速度快 (默认初始容量为10)
Vector:线程安全,速度慢(synchronized)。
LikedList:以单链表的方式存储,增,删快,查,改慢
HashMap和HashTable之间的区别:
这两个都是Map接口的实现类,实现了将唯一键映射到特定的值上。
HashMap类没有排序,可以有一个null键和多个null值,HashTable不可以有null键和null值。
HashTable:线程安全,线程安全就是防止覆盖更新。
HashMap:非线程安全(默认初始容量16)
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值是true:说明元素重复,不添加是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
| -- TreeMap :内部结构是二叉树,不是同步的 。可以对Map集合中的键进行排序。
如何保证元素唯一性呢?根据比较的返回值是否是0来决定
如何保证元素的排序呢?
两种方式
自然排序(元素具备比较性) 让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)让集合接收一个Comparator的实现类对象
| -- LinkedHashMap:底层数据结构由链表和哈希表组成。
由链表保证元素有序。
由哈希表保证元素唯一。
----------------------------------------------------------------------------------
泛型:
jdk1.5出现了安全机制
好处:
1、将运行时期的问题ClassCastException转到了编译时期。
2、避免了强制转换的麻烦。
< >:什么时候用?当操作的引用数据类型不确定的时候。 就使用< >。将要操作的引用数据类型传入即可。其实< >就是一个用于接收具体引用数据类型的参数范围。
在程序中只要用到带有< >的类或者接口,就要明确传入的具体引用数据类型泛型技术是给编译器使用的技术,用于编辑时期,确保了类型的安全。
运行时,会将泛型去掉,生成的class文件中是不带泛型的,这个称为泛型的擦除。为什么擦除?因为是为了兼容运行的类加载器。
泛型补偿:在运行时,通过获取元素的类型进行转换动作。不用使用者再强制转换了。当方法静态时,不能访问类上定义的泛型。如果静态方法使用泛型只
能将泛型定义在方法上。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗