
Hadoop
1.概念
分布式系统基础架构。主要包括分布式文件系统HDFS(Hadoop Distributed File System)、分布式计算系统Map Reduce和分布式资源管理系统YARN
大数据生态:Hive Pig Sqoop Flume Oozie Mahout
2.HDFS
分布式文件系统允许将一个文件通过网络在多台主机上以多副本(提高容错性)的方式进行存储,
实际上是通过网络来访问文件,用户和程序看起来就像是访问本地的磁盘一样。
HDFS提供了高可靠性(主要通过多副本来实现)、高扩展性(通过添加机器来达到线性扩展)和高吞吐率的数据存储服务
HDFS的基本原理是将数据文件以指定的块大小拆分成数据块,并将数据块以副本的方式存储到多台机器上
即使某个节点出现故障,该节点上存储的数据块副本丢失,但是在其他节点上还有对应的数据副本
HDFS将数据文件的切分、容错、负载均衡等功能透明化。我们可将HDFS看成一个容量巨大、具有高容错性的磁盘,在使用的时候完全可以当作普通的本地磁盘使用。
2.1 基础
2.1.1 数据块
最基本的存储单位是数据块(Block),默认的块大小是64MB(有些发布版本为128MB)
HDFS中的文件是分成以Block Size为大小的数据块存储的。如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间,文件大小是多大就占用多少存储空间。
2.1.2 元数据节点
Name Node的职责是管理文件系统的命名空间,它将所有的文件和文件夹的元数据保存在一个文件系统树中,如一个文件包括哪些数据块,这些数据块分布在哪些数据节点上,这些信息都要存储下来。
2.1.3 数据节点
Data Node是文件系统中真正存储数据的地方,一个文件被拆分成多个Block后,会将这些Block存储在对应的数据节点上。
客户端向Name Node发起请求,然后到对应的数据节点上写入或者读出对应的数据Block。
2.1.4 从元数据节点
Secondary Name Node并不是Name Node节点出现问题时的备用节点,它和元数据节点分别负责不同的功能。
其主要功能就是周期性地将Name Node的namespace image和edit log合并,以防日志文件过大。
合并后的namespace image也在元数据节点保存了一份,以防在Name Node失效的时候进行恢复
2.2 架构
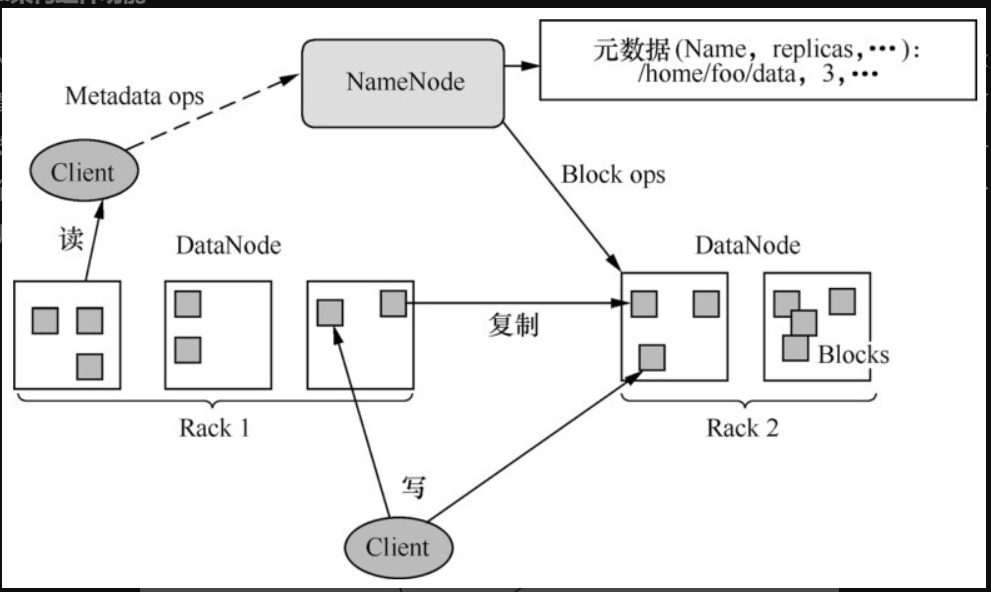
HDFS采用master/slave架构。
一个HDFS集群由一个Name Node和一定数量的Data Node组成。
Name Node是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
集群中的Data Node一般是一个节点对应一个,负责管理它所在节点上的存储数据。
HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。
从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Data Node上。
Name Node执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录,它也负责确定数据块到具体Data Node的映射。
Data Node负责处理文件系统客户端的读写请求,在Name Node的统一调度下进行数据块的创建、删除和复制
2.3 HDFS Shell
cmd中输入即可
-
创建HDFS目录
hadoop fs -mkdir /helloworld -
查看目录是否创建成功
hadoop fs -ls / -
运行wordcount测试案例
新建txt文件:hello world hellohello welcome world
上传文件 Hadoop fs -put C:\Users\lwx20\Desktop\hello.txt /
MapReduce分析 hadoop jar D:\BigData\Hadoop\hadoop-3.2.0\share\hadoop\mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /hello.txt /wc_out/
查看结果 hadoop fs -text /wc_out/part* -
递归查看
hadoop fs -ls -R /filename -
级联创建
hadoop fs -mkdir -p /filename/filename1/filename2 -
上传文件
hodoop fs -put 源 /目录名 -
下载文件
hdfs dfs -get 文件位置
下载到该目录C:\Windows\System32 -
查看内容
hadoop fs -text 文件位置
hadoop fs -cat 文件位置 -
统计目录大小
hodoop fs -du 目录路径 -
删除文件
hodoop fs -rm 文件位置
目录下全部: hodoop fs -rmr 目录路径
2.4 Java API
2.5 原理
2.5.1 读流程
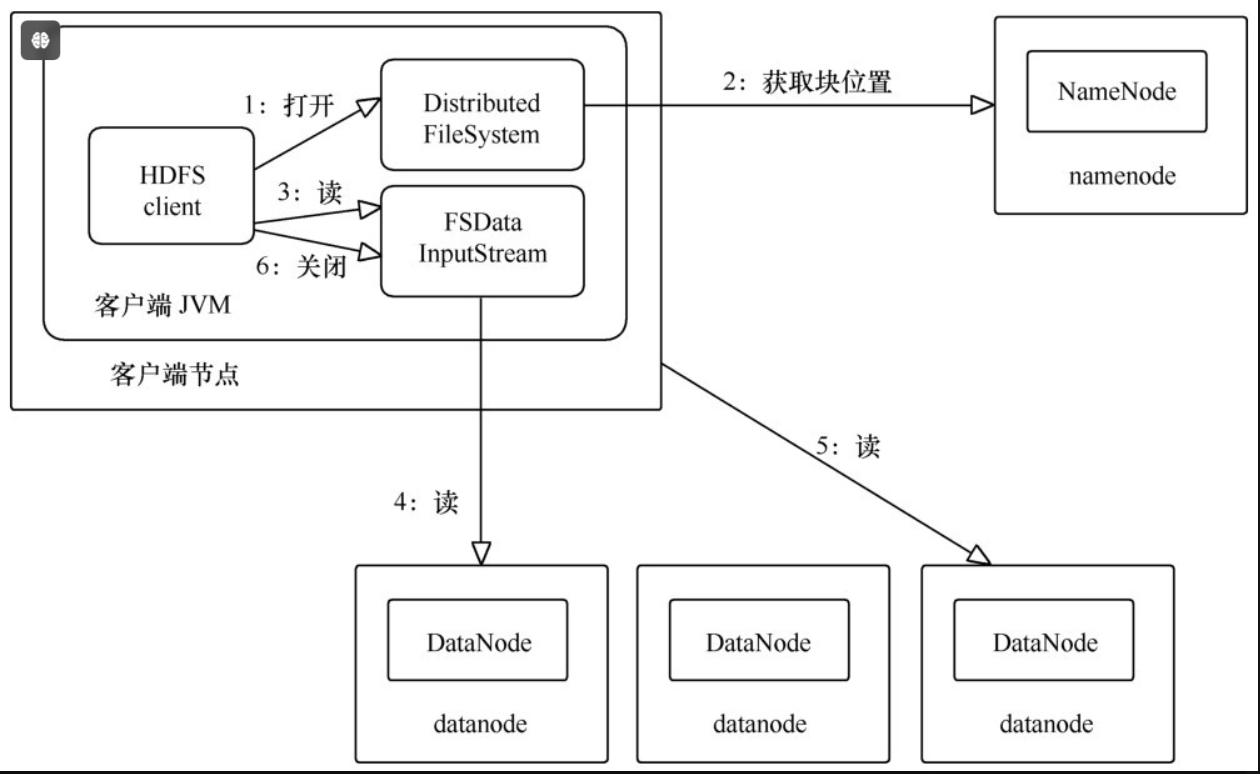
(1)客户端通过调用File System的open方法获取需要读取的数据文件,对于HDFS来说该File System就是Distribute File System。
(2)Distribute File System通过RPC来调用Name Node,获取到要读取的数据文件对应的Block存储在哪些Data Node之上。
(3)客户端先到最佳位置(距离最近)的Data Node上调用FSData Input Stream的read方法,通过反复调用read方法,可以将数据从Data Node传递到客户端。
(4)当读取完所有的数据之后,FSData Input Stream会关闭与Data Node的连接,然后寻找下一块的最佳位置,客户端只需要读取连续的流。
(5)一旦客户端完成读取操作后,就对FSData Input Stream调用close方法来完成资源的关闭操作。
2.5.2 写流程
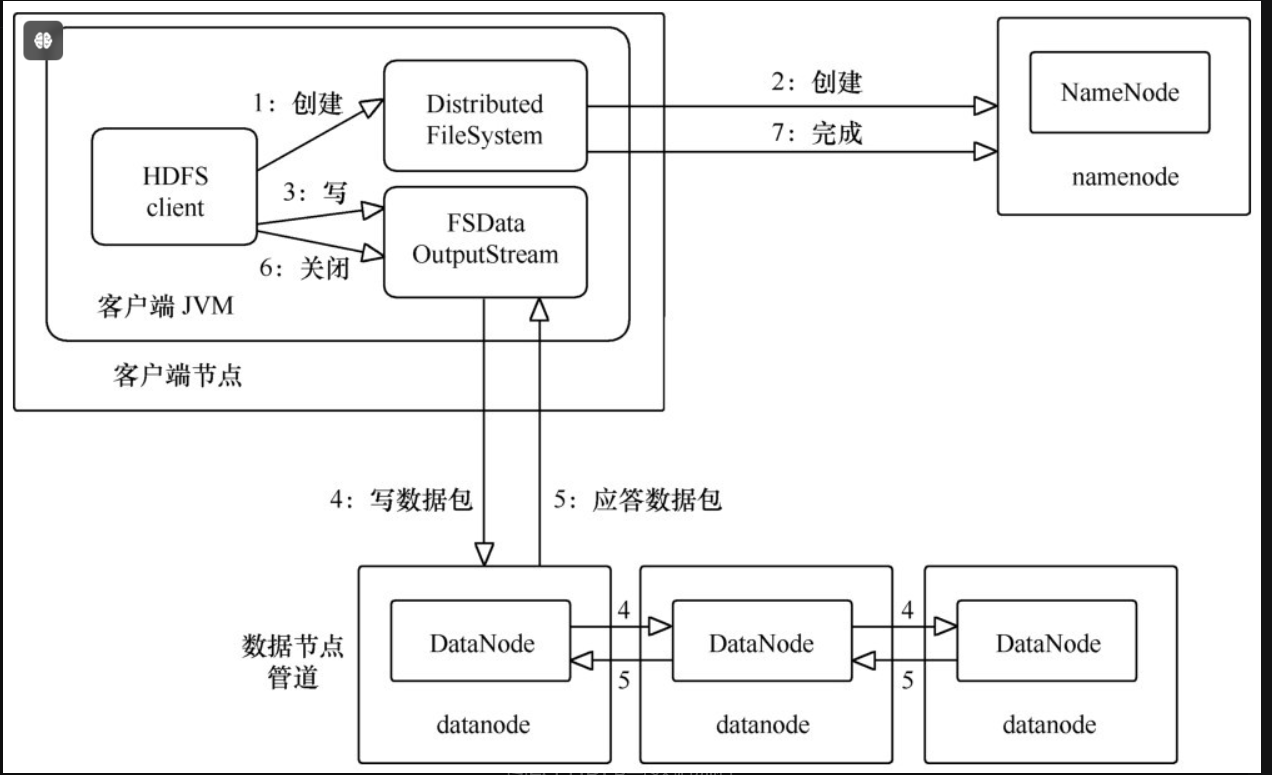
(1)客户端通过调用Distribute File System的create方法来创建一个文件。
(2)Distribute File System会对Name Node发起RPC请求,在文件系统的名字空间中创建一个新的文件,此时会进行各种检查,比如检查要创建的文件是否已经存在,如果该文件不存在,Name Node就会为该文件创建一条元数据记录。
(3)客户端调用FSData Output Stream的write方法将数据写到一个内部队列中。假设副本系数为3,那么将队列中的数据写到3个副本对应存储的Data Node上。
(4)FSData Output Stream内部维护着一个确认队列,当接收到所有Data Node确认写完的消息后,数据才会从确认队列中删除。
(5)当客户端完成数据的写入后,会对数据流调用close方法来关闭相关资源。
2.5.3 副本机制
HDFS上的文件对应的Block保存有多个副本且提供容错机制,因此副本丢失或宕机时能够自动恢复。默认保存3个副本。
2.6 高级知识
3.MapReduce
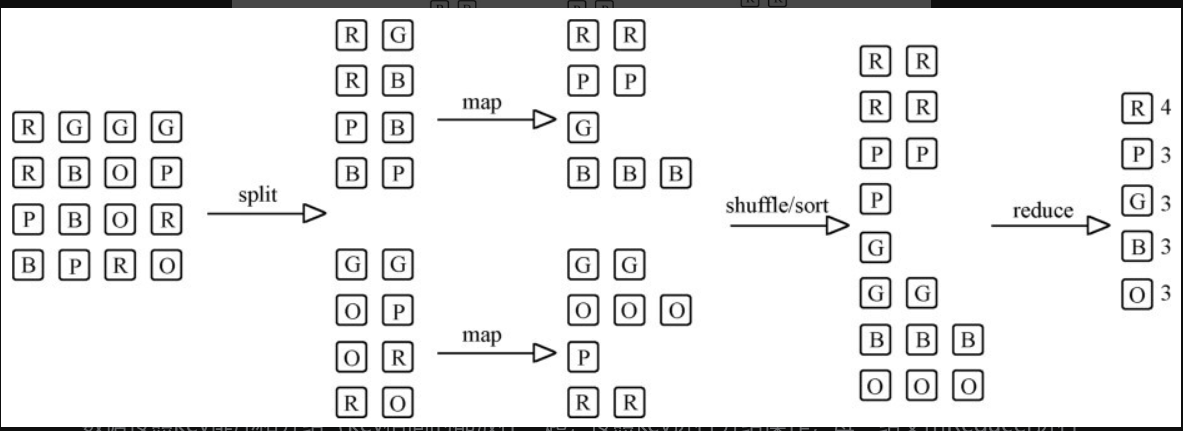
Map Reduce是一个编程模型,用以进行大数据量的计算
两项核心操作:Map(映射)和Reduce(归纳)
一个Map Reduce作业通常会把输入的数据集切分为若干独立的数据块
由map任务以并行的方式处理它们,对map的输出先进行排序,然后再把结果输入reduce任务,由reduce任务来完成最终的统一处理。
通常Map Reduce作业的输入和输出都是使用Hadoop分布式文件系统(HDFS)进行存储,换句话说,就是Map Reduce框架处理数据的输入源和输出目的地的大部分场景都是存储在HDFS上的。
3.1 编程模型
- map()函数
以key/value对作为输入,产生另外一系列key/value对作为中间输出写入本地磁盘。
Map Reduce框架会自动将这些中间数据按照key值进行聚集,
且key值相同(用户可设定聚集策略,默认情况下是对key值进行哈希取模)的数据被统一交给reduce()函数处理。 - reduce()函数
以key及对应的value列表作为输入,经合并key相同的value值后,产生另外一系列key/value对作为最终输出写入HDFS。
3.2 Java API
3.3 格式
- Map Reduce类型
遵守格式:
map: (k1,v1) -> list(l2,v2)
reduce: (k2, list(v2)) -> list(k3,v3)
reduce函数的输入类型必须与map函数的输出类型 - 常用设置
输入数据类型由输入格式(Input Format)设置: Text Input Format的Key的类型是Long Writable,Value的类型是Text。
map的输出的Key的类型通过set Map Output Key Class设置,Value的类型通过set Map Output Value Class设置。
reduce的输出的Key的类型通过set Output Key Class设置,Value的类型通过set Output Value Class设置。
3.3.1 输入格式
4.Yarn
ARN的基本思想是将Hadoop1.x中Map Reduce架构中的Job Tracker的资源管理和作业调度监控功能进行分离,解决了在Hadoop1.x中只能运行Map Reduce框架的限制。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律