
PostgreSQL基础
1.数据类型
1.1 数字类型
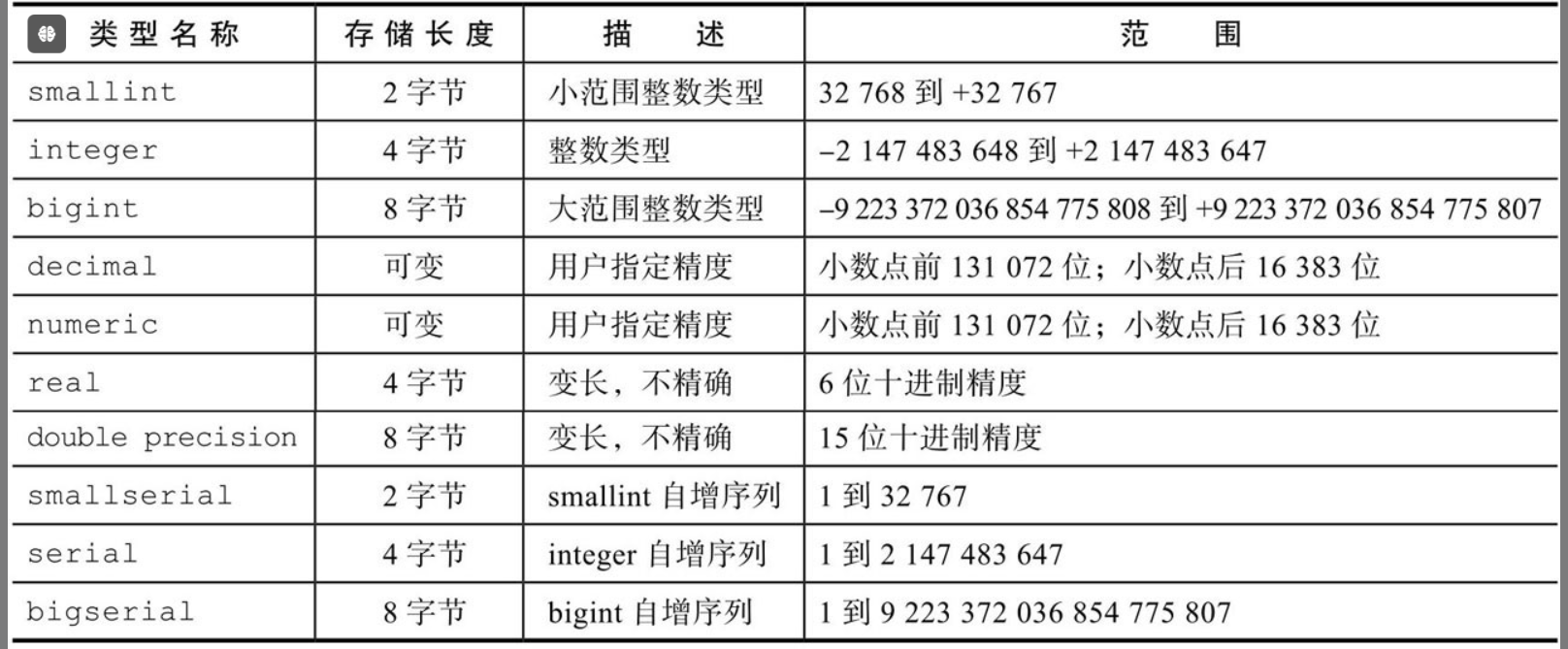
1.1.1 函数
- mod 取模
- round 四舍五入
- ceil 返回大于或等于给出参数的最小整数
- floor 返回小于或等于给出参数的最大整数
1.2 字符类型

1.2.1 函数
- char_length: 字符个数
- octet_length:字节长度
- position('a' in 'abcd');:字符位置
- substring('francs' from 3 for 4) 子串
- split_part('abc@def1@nb', '@',2); 拆分字符串 第二个开始
1.3 时间类型

1.3.1 类型转换
- now: 2024-08-29 10:42:59.69699+08
- now()::timestamp without time zone 2024-08-29 10:43:57.833769
- now()::date; 2024-08-29
- now()::time without time zone; 10:44:59.509909
- now()::time with time zone; 10:45:38.637009+08
- now()+interval'1 day'; //时间间隔 hour、day、month、year
1.3.2 函数
- SELECT current_date, current_time;
- EXTRACT( year FROM now()); 抽取年、月、日、时、分、秒
1.4 布尔类型
bool
1.5 网络地址类型

- cidr:对ip和子网掩码合法性做校验,输出时会带子网掩码
- inet:对ip做校验,输出时有可能带子网掩码
- macaddr和macaddr8:MAC地址
1.5.1 操作符
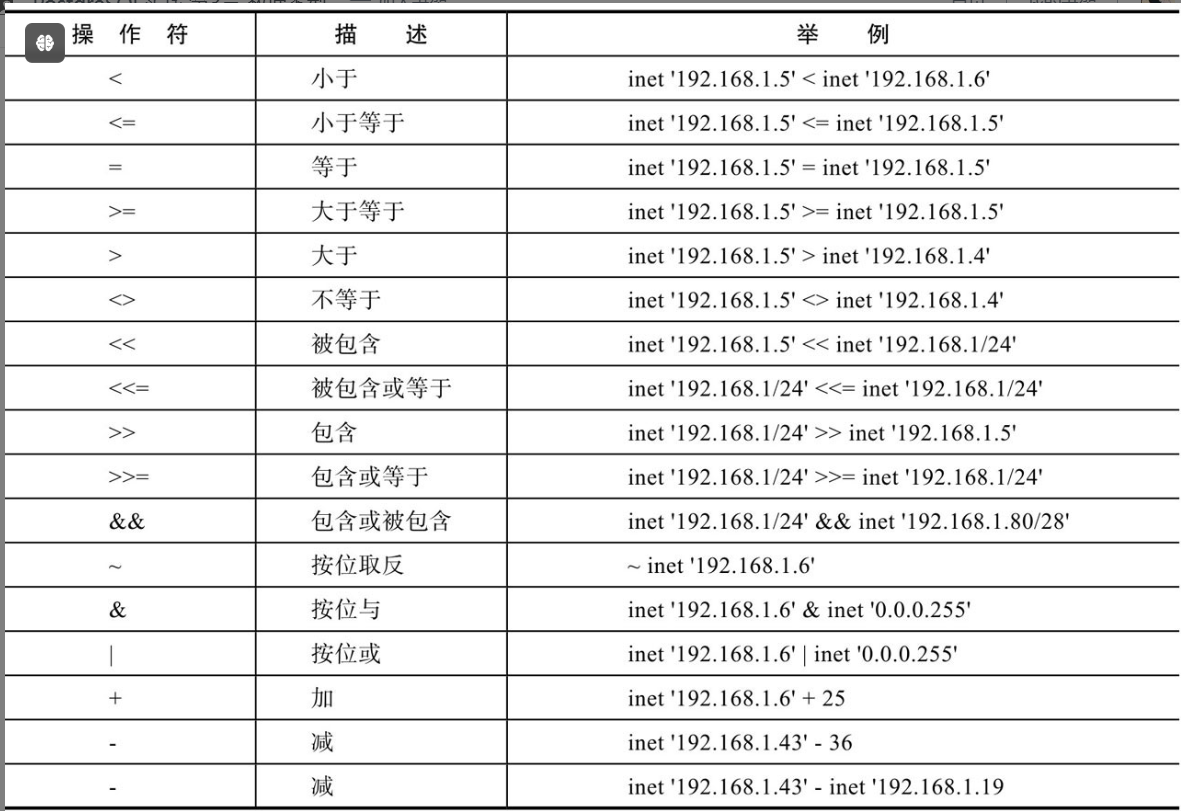
1.5.2 函数
- host: 取ip地址 SELECT host(cidr '192.168.2.0/24')
- text: 取ip和子网掩码 SELECT text(cidr '192.168.2.0/24')
- netmask:取子网掩码 SELECT netmask(cidr '192.168.2.0/24')
1.6 数组
插入方式:
- {val1,val2}:
- array函数: array[1,2,3]
查询: 下标1-n SELECT d_array[1] FROM test
1.6.1 函数
- 追加: SELECT array_append(ARRAY[1,2,3], 4) / SELECT ARRAY[1,2,3] || 4
- 删除: SELECT array_remove(ARRAY[1,2,3], 2)
- 更新: update test set d_array[2] = 3 / update test set d_array = array[1,2]
- 数组纬度: SELECT array_ndims(ARRAY[1,2,3])
- 数组长度: SELECT array_length(ARRAY[1,2,3], 1) // 第二个参数为纬度,二维数组填2
- 元素位置: SELECT array_position(ARRAY[1,2,3], 1)
- 元素替换: SELECT array_replace(ARRAY[1,2,3], 1,3)
- 以字符串输出: SELECT array_to_string(ARRAY[1,2,null], ',', '0') // 第二参数为分隔符,第三个为替换null的数
1.6.2 操作符
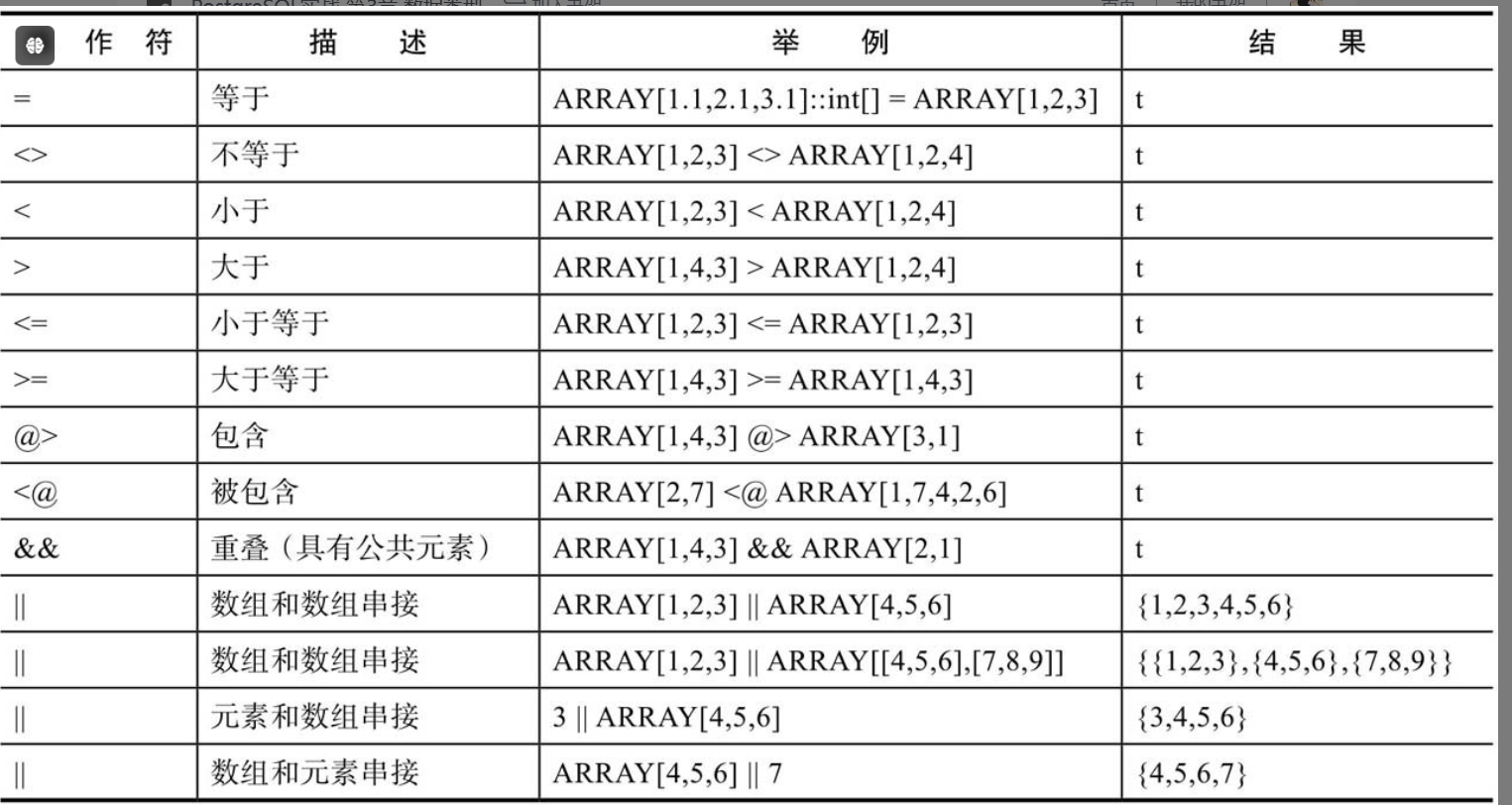
1.7 范围类型
- int4range
- int8range
- numrange
- tsrange : 不带时区的timestamp范围类型
- tstzrange: 带时区的timestamp范围类型
- daterange
1.7.1 操作符
- int4range(4,7) @> 4;
1.7.2 函数
- lower : 取下界
- higher: 取上界
- isempty
1.8 json
- SELECT f_json -> 'name' from test: 从json查key
- SELECT f_json ->> 'name' from test: 文本格式
1.8.1 jsonb
json存储格式为文本而jsonb存储格式为二进制,由于存储格式的不同使得两种json数据类型的处理效率不一样,
json类型以文本存储并且存储的内容和输入数据一样,当检索json数据时必须重新解析,而jsonb以二进制形式存储已解析好的数据,当检索jsonb数据时不需要重新解析,
因此json写入比jsonb快,但检索比jsonb慢
- jsonb输出的键的顺序和输入不一样
- jsonb类型会去掉输入数据中键值的空格
- jsonb会删除重复的键
1.8.2 操作符
- ? 'a' 是否顶层key
-
- 'a' 删除key
1.8.3 函数
- || 追加或覆盖
- '#'- 删除
2.SQL高级特性
2.1 WITH查询
CTE:Common Table Expression
相当于中间表
WITH r as (
SELECT generate_series(3)
)
SELECT * from r
递归使用:
// 1-5 之和
WITH recursive t (x) as (
SELECT 1
UNION
SELECT x + 1
FROM t
WHERE x < 5
)
SELECT sum(x) FROM t;
2.2 批量插入
- INSERT INTO table_name SELECT...FROM source_table
- INSERT INTO tbl_batch3(id, info) VALUES (1, 'a'), (2, 'b'), (3, 'c');
- COPY: COPY pguser.tbl_batch4 FROM '/home/pg10/tbl_batch4.txt';
2.3 RETURNING
- 插入:INSERT INTO test(a_boolean) VALUES ('f') RETURNING *;
- 更新:UPDATE test SET a_boolean='f' RETURNING *;
- 删除:DELETE FROM test RETURNING *;
2.4 UPSERT
数据插入过程中数据冲突的情况,比如违反用户自定义约束
INSERT INTO user_logins(user_name, login_cnt)
VALUES ('matiler',1), ('francs',1)
ON CONFLICT(user_name)
DO UPDATE SET
login_cnt=user_logins.login_cnt+EXCLUDED.login_cnt, last_login_time=now();
- 冲突但是不做
INSERT INTO user_logins(user_name, login_cnt)
VALUES ('tutu',1), ('francs',1)
ON CONFLICT(user_name) DO NOTHING;
2.5 数据抽样
order by random 效率低
- SYSTEM抽样方式
SYSTEM抽样方式为随机抽取表上数据块上的数据,理论上被抽样表的每个数据块被检索的概率是一样的
查询总数的0.01条
SELECT * FROM test_sample TABLESAMPLE SYSTEM(0.01);
- BERNOULLI抽样方式
BERNOULLI抽样方式随机抽取表的数据行,并返回指定百分比数据,BERNOULLI抽样方式基于数据行级别,理论上被抽样表的每行记录被检索的概率是一样的,因此BERNOULLI抽样方式抽取的数据相比SYSTEM抽样方式具有更好的随机性,但性能上相比SYSTEM抽样方式低很多
SELECT * FROM test_sample TABLESAMPLE BERNOULLI (0.01);
2.6 聚合函数
- string_add: 将输出的结果集连接成字符串 SELECT country, string_agg(city, ', ') FROM city GROUP BY country;
- array_agg: 返回的类型为数组 SELECT country, array_agg(city) FROM city GROUP BY country;
2.7 窗口函数
分类:
数据库 / PostgreSQL


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律