
分布式存储
1.数据库读写分离
业务读多写少,分离读操作和写操作
将访问压力从主库转移到从库
但是需要动态更新的业务场景,不进行读写分离
由于关系型数据库对事务支持,一般选择性能高的NoSQL
1.1 实现
- 一主一从
- 一主多从
1.2 MySQL主从复制技术-binlog日志
InnoDB引擎的主从复制,通过二进制日志binlog实现,除了select语句外,日志记录其他各类数据写入操作,包括DDL,DML语句
三种格式:
- Statement:基于语句的复制binlog记录一条修改数据的SQL操作,从库拿到后在本地回放
- Row:基于行信息复制,记录每一行数据修改的细节,仅记录行数据的修改
- Mixed:混合模式复制,前俩个格式结合,不同的SQL操作不同对待,一般的数据操作用row,表结构的变更语句用statement
1.3 过程
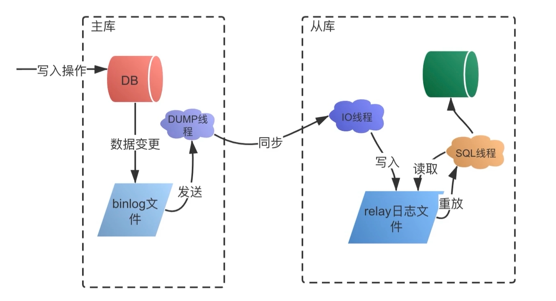
1.4 延时问题
主库数据写入后,同时写入binlog日志中,从库通过binlog同步数据,由于额外执行日志同步和写入操作,会有一定延迟,可能引起业务问题
解决方法:
- 敏感业务强制读主库:业务需要实时读数据的,可以强制读主库
- 关键业务不读写分离:对一致性不敏感的业务,评论等可以进行读写分离。一致性要求高的业务,金融支付,不进行读写分离
1.5 数据丢失问题
主从同步时,主库宕机,数据没有同步到从库,会出现数据丢失和不一致
解决方法:
- 异步复制:主库处理写入请求,直接返回结果,不关心从库是否成功,主库宕机,可能会有操作没有同步到从库,数据丢失
- 半同步复制:主库等待至少一个从库完成同步之后,完成写操作。主库执行完客户端请求事务后,从库将日志写入本地relay log之后,返回响应结果给主库,主库确认从库完成,才会结束写操作。避免主库宕机出现的数据丢失,但增加耗时
- 全同步复制:主库等待所有从库同步完成后才完成写操作,性能最差。
2.分库分表
阿里巴巴Java开发手册建议:单表超过500万行或单表容量超过2G,才推荐分库分表。
分表是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内
分库是一个库一般最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
数据库连接有限制,不能无限创建:MYSQL使用max_connections查看最大连接数,访问过多就会失败。使用数据库连接池,可以优化连接数问题,更好的方式是分库分表,避免数据库连接成为业务瓶颈。
2.1 原理
存储于单个数据库的数据拆分到多个数据库,单个数据表拆分到多个数据表。
- 垂直切分:按业务类型,把一个有很多字段的表给拆分成多个表,或者是多个库上去。
每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。
因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
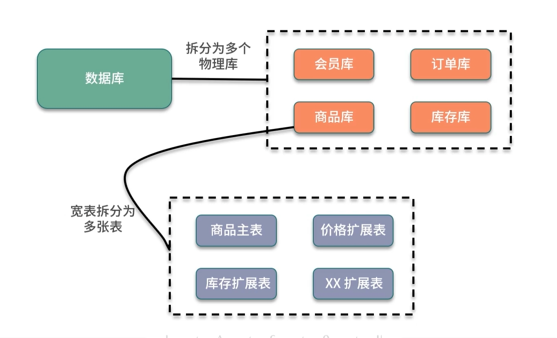
- 水平切分:相同表结构分散到不同数据库和数据表中,把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。
水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
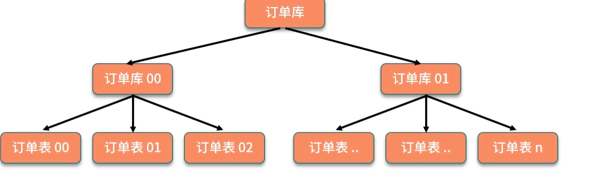
无论分库还是分表,数据库中间件都是可以支持的。就是基本上那些中间件可以做到你分库分表之后,中间件可以根据你指定的某个字段值,比如说 userid,自动路由到对应的库上去,然后再自动路由到对应的表里去。
你就得考虑一下,你的项目里该如何分库分表?一般来说,垂直拆分,你可以在表层面来做,对一些字段特别多的表做一下拆分;
水平拆分,你可以说是并发承载不了,或者是数据量太大,容量承载不了,你给拆了,按什么字段来拆,你自己想好;
分表,你考虑一下,你如果哪怕是拆到每个库里去,并发和容量都 ok 了,但是每个库的表还是太大了,那么你就分表,将这个表分开,保证每个表的数据量并不是很大。
2.1.1 分库分表的方式:
- 一种是按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了。
- 或者是按照某个字段 hash 一下均匀分散,这个较为常用。range 来分,好处在于说,扩容的时候很简单,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了;缺点,但是大部分的请求,都是访问最新的数据。实际生产用 range,要看场景。
- hash 分发,好处在于说,可以平均分配每个库的数据量和请求压力;坏处在于说扩容起来比较麻烦,会有一个数据迁移的过程,之前的数据需要重新计算 hash 值重新分配到不同的库或表。
2.2 问题
2.2.1 分布式事务
2.2.2 跨库关联查询
跨库和跨表查询比较复杂,性能也低
- 使用额外存储,比如维护一件文件索引
- 通过合理数据库字段冗余,避免出现跨库查询
2.2.3 跨库跨表的合并和排序
如果查询指定数据列表,或对数据列表排序,需要在内存处理,性能差,可以使用分库分表中间件处理。
- ShardingSphere: 前身当当开源Sharding-JDBC,额外提供Sharding-Proxy 以及正在规划中的Sharding-Sidecar其中Sharding-JDBC用来实现分库分表,添加对分布式事务支持
- TDDL: 淘宝开发,解决分库分表下的访问路由
2.2.4 唯一主键问题
最直接方案使用单独自增数据表,无法保证性能,存在单点故障
-
UUID:作为主键太长,比较大的存储开销,无序UUID,降低写入性能。Mysql InnoDB引擎支持索引,底层B+树,主键自增ID,Mysql按磁盘顺序写入,非自增ID,写入时增加很多额外数据移动,插入数据时产生页分裂,降低数据写入性能
好处就是本地生成,不要基于数据库来了;
不好之处就是,UUID 太长了、占用空间大,作为主键性能太差了;更重要的是,UUID 不具有有序性,会导致 B+ 树索引在写的时候有过多的随机写操作(连续的 ID 可以产生部分顺序写),还有,由于在写的时候不能产生有顺序的append 操作,而需要进行 insert 操作,将会读取整个 B+ 树节点到内存,在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显。
适合的场景:如果你是要随机生成个什么文件名、编号之类的,你可以用 UUID,但是作为主键是不能用 UUID 的。 -
Snowflake:分布式ID生成算法,64位2进制数字组成。
第一位符号位。
41位时间戳,表示毫秒数,可以表示69年多一点。
10位工作机器ID,支持1024个节点。
12位序列号,作为当前时间戳和机器下的流水号,每个节点每毫米支持2^12区间,4096个ID,QPS409万,如果这个区间超过了4096,等待下一毫秒计算。
产生的ID趋势递增,不需要依赖数据库等。

时钟回拨问题:为了防止不同用户访问服务器时间不同,需要保持服务器时间同步,通过NTP机制进行校对,网络时间协议,同步网络各个计算机的时间,如果同步NTP时出现不一致,那么计算时可能出现重复ID。润秒也会导致该问题
snowflake 算法是 twitter 开源的分布式 id 生成算法,采用 Scala 语言实现,是把一个 64 位的long 型的 id,1 个 bit 是不用的,用其中的 41 bits 作为毫秒数,用 10 bits 作为工作机器 id,12bits 作为序列号。 -
- 1 bit:不用,为啥呢?因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
-
- 41 bits:表示的是时间戳,单位是毫秒。41 bits 可以表示的数字多达 2^41 - 1 ,也就是可以标识 2^41 - 1 个毫秒值,换算成年就是表示69年的时间。
-
- 10 bits:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024台机器。但是 10 bits 里 5 个 bits 代表机房 id,5 个 bits 代表机器 id。意思就是最多代表2^5 个机房(32 个机房),每个机房里可以代表 2^5 个机器(32台机器)。
-
- 12 bits:这个是用来记录同一个毫秒内产生的不同 id,12 bits 可以代表的最大正整数是2^12 - 1 = 4096 ,也就是说可以用这个 12 bits 代表的数字来区分同一个毫秒内的4096 个不同的id。
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 1 1001 | 0000
-
- 41 bit 是当前毫秒单位的一个时间戳,就这意思;
-
- 5 bit 是你传递进来的一个机房 id(但是最大只能是 32 以内),另外 5 bit 是你传递进来的机器id(但是最大只能是 32 以内),
-
- 12 bit序列号,就是如果跟你上次生成 id 的时间还在一个毫秒内,那么会把顺序给你累加,最多在 4096 个序号以内。
所以你自己利用这个工具类,自己搞一个服务,然后对每个机房的每个机器都初始化这么一个东西,刚开始这个机房的这个机器的序号就是 0。然后每次接收到一个请求,说这个机房的这
个机器要生成一个 id,你就找到对应的 Worker 生成。利用这个 snowflake 算法,你可以开发自己公司的服务,甚至对于机房 id 和机器 id,反正给你预留了 5 bit + 5 bit,你换成别的有业务含义的东西也可以的。这个 snowflake 算法相对来说还是比较靠谱的,所以你要真是搞分布式 id 生成,如果是高并发啥的,那么用这个应该性能比较好,一般每秒几万并发的场景,也足够你用了。
-
数据库维护区间分配:基于数据库自增ID区间,结合内存分配的策略,淘宝的TDDL使用的策略。插入一条记录,需要获取主键时,服务器从表中取出对应ID区间缓存在本地,同时更新sequence表value最大值记录
当服务器获取主键增长区段时,首先访问对应库的sequence表,更新对应记录,占用一个对应的区段,比如设置步长为200,原先value值为1000,更新后value为1200。取到了对应ID区间后,在服务器内部分配,涉及到并发问题使用乐观锁等机制解决。有了对应ID增长区间,在本地使用AtomicInteger等方式分配ID。保证整体趋势递增,防止单点故障,sequence表所在数据库配置多个从库。
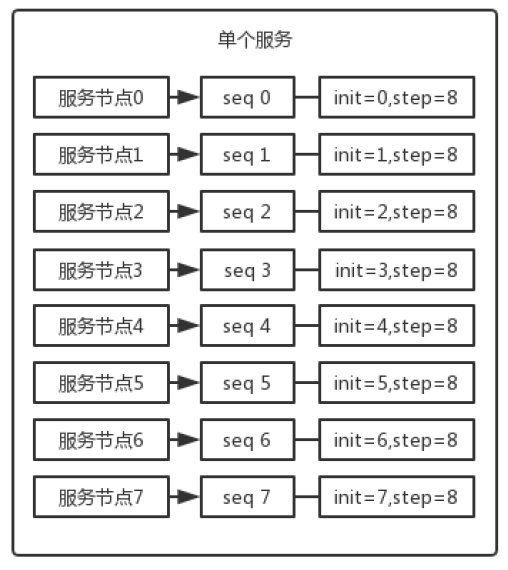
现在有 8 个服务节点,每个服务节点使用一个 sequence 功能来产生 ID,每个sequence 的起始 ID 不同,并且依次递增,步长都是 8。
-
Redis incr命令解决
3.扩容
业务场景,预估数据规模会增大特别多
3.1 路由规则与扩容方案
-
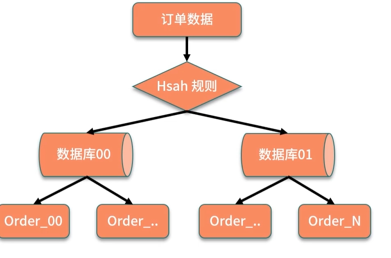
哈希取模:根据不同业务主键输入,对数据库取模,得到数据的位置。优点:数据拆分均匀。缺点:不利于后面扩容。
数据迁移方案:
停机迁移:暂停服务,将历史数据按新规则重新分配到新存储中
不停机规则:动态扩容,依赖业务双写操作实现。同时处理存量和增量数据,并做好数据校验。
步骤:
创建新数据库,在某时间,将历史数据按照新的路由规则分配到新数据库中,在旧数据库的操作中开启双写,同时写入到俩个数据库,用新的读写服务逐步代替旧服务,同步进行数据不一致校验,最后完成全面切流。
-
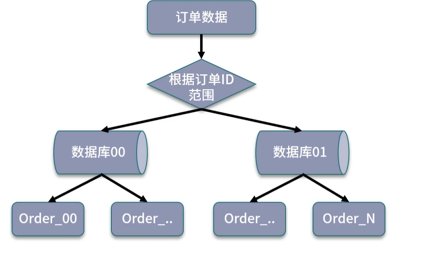
基于数据范围进行拆分: 根据特定的字段划分不同区间,对订单表可以根据订单ID范围进行划分。缺点:数据访问不均匀
-
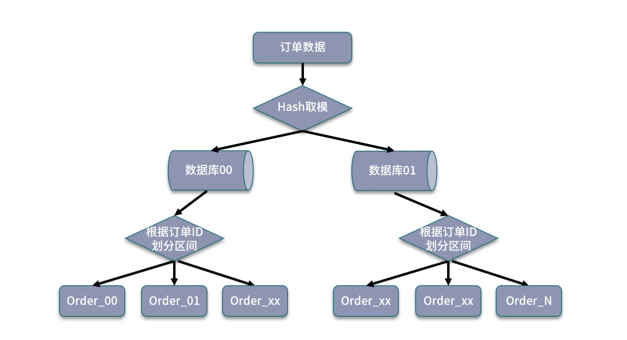
结合数据范围和哈希取模:
避免单纯基于数据范围可能出现的热点存储,后期拓展可以直接增加拓展表。
3.2 动态分库分表方案
- 双写迁移方案
简单来说,就是在线上系统里面,之前所有写库的地方,增删改操作,除了对老库增删改,都加上对新库的增删改,这就是所谓的双写,同时写俩库,老库和新库。
然后系统部署之后,新库数据差太远,用导数工具,跑起来读老库数据写新库,写的时候要根据 gmt_modified 这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库
里没有,或者是比新库的数据新才会写。简单来说,就是不允许用老数据覆盖新数据。
导完一轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,
直到两个库每个表的数据都完全一致为止。接着当数据完全一致了,就 ok 了,基于仅仅使用分库分表的最新代码,重新部署一次,不就仅仅基于分库分表在操作了么,还没有几个小时的停机时间, - 继续扩容
一个实践是利用 32 * 32 来分库分表,即分为 32 个库,每个库里一个表分为 32 张表。一共就是 1024 张表。根据某个 id 先根据 32 取模路由到库,再根据 32 取模路由到库里的表。
- 设定好几台数据库服务器,每台服务器上几个库,每个库多少个表,推荐是 32 库 * 32 表,对于大部分公司来说,可能几年都够了。
- 路由的规则,orderId 模 32 = 库,orderId / 32 模 32 = 表
- 扩容的时候,申请增加更多的数据库服务器,装好 MySQL,呈倍数扩容,4 台服务器,扩到8 台服务器,再到 16 台服务器。
- 由 DBA 负责将原先数据库服务器的库,迁移到新的数据库服务器上去,库迁移是有一些便捷的工具的。
- 我们这边就是修改一下配置,调整迁移的库所在数据库服务器的地址。
- 重新发布系统,上线,原先的路由规则变都不用变,直接可以基于 n 倍的数据库服务器的资源,继续进行线上系统的提供服务。
4.NoSQL
特性:良好拓展性,容易集群部署,读写性能高,支持大数据量,不限制数据结构,灵活数据模型。
性能角度:NoSQL优于关系型
持久化角度:关系型优于NoSQL
CAP角度:关系型强调CP,NoSQL强调AP
4.1 应用
- KV数据库:存储MAP结构支持高性能通过key定位和存储,通常用来实现缓存等应用:Redis Memcached.
性能角度:Redis一直使用单线程模型,并且支持IO多路复用的技术,最近版本开始支持多线程处理
存储结构的角度:redis支持多种数据结构,针对不同的数据规模等,redis采取多种内存优化方式,List结构内部有压缩列表和双向链表俩种实现,在数据规模较小时采用ZipList实现,新版本中添加QuickList实现,减少内存的消耗
高可用角度:Redis实现AOF和RDB的数据持久化机制,支持多种集群方式,包括主从同步,sentinel和Redis Cluster等机制 - 文档型数据库:存储结构化文档,比如JSON或XML,不需要预先定义表结构,并且支持文档之间的嵌套,MongoDB采用基于JSON拓展的BSON存储结构,可以进行自我描述,具备非常优秀的扩展能力,对分片集群部署支持非常全面,可以快速拓展集群规模
- 列式数据库:被用来存储海量数据,如Cassandra,HBase等,大数据量读写速度快,可拓展性强,更容易进行分布式部署,HBase支持海量数据的读写,特别是写入操作,支持TB级别的数据量,列式数据库通常不支持事务和各种索引优化,HBase使用LSM树组织数据
- 图形数据库:社交网络的用户关系可以使用图来存储
5.ES
存储中间件-文件索引
Lucene是一个开源的全文检索引擎类库,支持各种分词以及搜索的实现
ElasticSearch基于lucene的分布式全文检索框架,在Lucene类库基础上实现,对分布式场景下的应用有特别好的支持,包括良好拓展性,可以拓展到上百台服务器集群规模,以及近似实时分析的索引实现。
5.1 应用
5.2 ELK
ELK用于快速查询数据并且可视化分析,在日志处理,大数据领域有广泛应用
ES:用于数据分析和检索
Logstash:日志收集
Kibana:界面展示
5.3 索引如何建立
ES储存单元是索引,关系型数据库以关系表形式组织数据,大部分NoSQL数据库是KV键值对方式。
ES索引实现基于Lucene,使用倒排索引结构,在搜索引擎中,索引建立需要经过网页爬取,信息采集,分词,索引创建的过程,在ES内部存储实现中,数据写入可以对比搜索引擎对网页抓取和信息采集过程,只需关注分词和索引创建
- 分词:分词策略影响索引结果,分词器是一个可插拔的组件,包括内置的标准分词器,也可以引入对中文支持较好的IKAnalyze中文分词器,中文分词用的最多的是基于字典的最长字符串匹配方式,有一小部分天然存在歧义的文档无法处理
- 索引建立:索引存储的结构是倒排索引,描述一个映射关系,包括文档分词后的结果,以及分别包含这些单词的文档列表,索引描述的是关键词和文档的关系。
正排索引:文档-关键词的格式。
倒排索引:关键词-文档的格式2
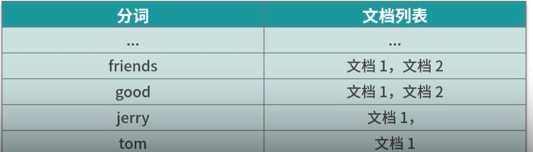
5.4 对比B+树
MySQL innoDB 索引基于B+树 描述索引数据结构,更好的事项通过主键以及通过区间范围查找的要求
倒排索引通过索引组织形式来命名,根据关键词去查找文档


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律