

RabbitMQ概念
1.RabbitMQ的概念
RabbitMQ是一个消息中间件:它接受并转发消息。
你可以把它当做一一个快递站点,当你要发送一个包裹时,你把你的包裹放到快递站,快递员最终会把你的快递送到收件人那里
按照这种逻辑RabbitMQ是一个快递站,一个快递员帮你传递快件。
RabitMQ与快递站的主要区别在于,它不处理快件而是接收,存储和转发消息数据。
2.四大核心概念
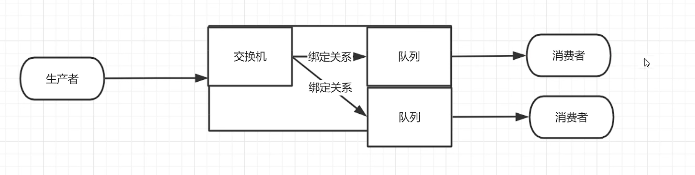
- 生产者
产生数据发送消息的程序是生产者 - 交换机
交换机是RabbitMQ非常重要的一个部件,
一方面它接收来自生产者的消息, 另一方面它将消息推送到队列中。
交换机必须确切知道如何处理它接收到的消息,是将这些消息推送到特定队列还是推送到多个队列,亦或者是把消息丢弃,这个由交换机类型决定 - 队列
队列是RabbitMQ内部使用的一种数据结构,尽管消息流经RabbitMQ和应用程序,但它们只能存储在队列中。
队列仅受主机的内存和磁盘限制的约束,本质上是一个大的消息缓冲区。
许多生产者可以将消息发送到一个队列,许多消费者可以尝试从一个队列接收数据。这就是我们使用队列的方式 - 消费者
消费与接收具有相似的含义。消费者大多时候是一个等待接收消息的程序。
请注意生产者,消费者和消息中间件很多时候并不在同一机器上。同一个应用程序既可以是生产者又是可以是消费者。
3.RabbitMQ核心部分
1 Hello World简单模式

2 Work queues工作队列模式

消费者竞争资源
3 Publish/Subscribe发布订阅模式
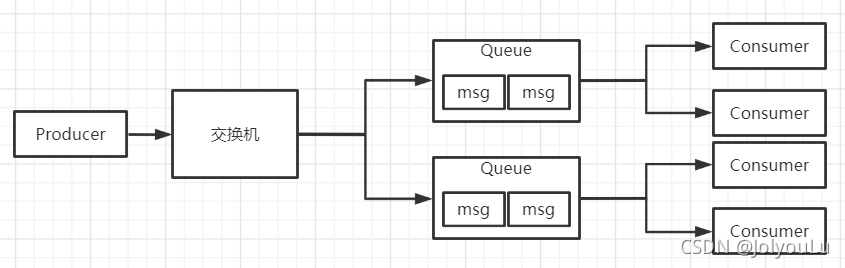
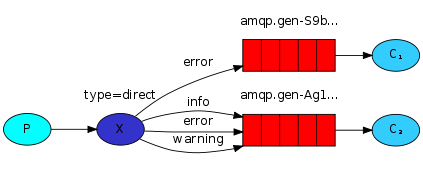
4 Routing路由模式
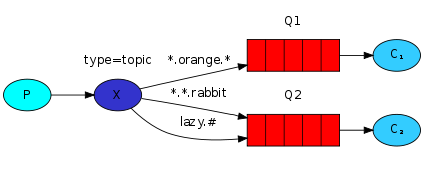
5 Topics主题模式
6 Publisher Confirms发布确认模式
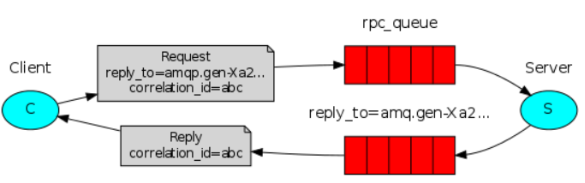
4.工作原理
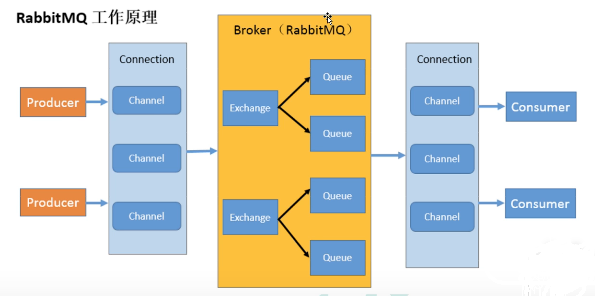
- Broker:接收和分发消息的应用,RabbitMQ Server就是Message Broker
- Virtual host:出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于网络中的namespace概念。
当多个不同的用户使用同一个RabbitMQ server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange/ queue等 - Connention: publisher / consumer和broker之间的TCP连接
- Channel信道:如果每一次访问RabbitMQ 都建立一个Connection,在消息量大的时候建立TCPConnection的开销将是巨大的,效率也较低。
Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,
AMQP method包含了channel id帮助客户端和message broker识别channel, 所以channel之间是完全隔离的。
Channel 作为轻量级的Connection极大减少了操作系统建立TCP connection的开销 - Exchange: message 到达broker的第一站, 根据分发规则,匹配查询表中的routing key,分发消息到queue中去。
常用的类型有: direct (point to point), topic (publish-subscibe) and fanout(multicast) - Queue:队列,每个消息投入到一个或多个队列
- Binding:绑定,将exchange和queue按照路由规则绑定起来
- RoutingKey: 路由关键字
4.1 消息传输
基于信道,建立在TCP上的虚拟链接,每个TCP连接上的信道无限制
5.高可用保证
RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,
RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。
- 单机模式
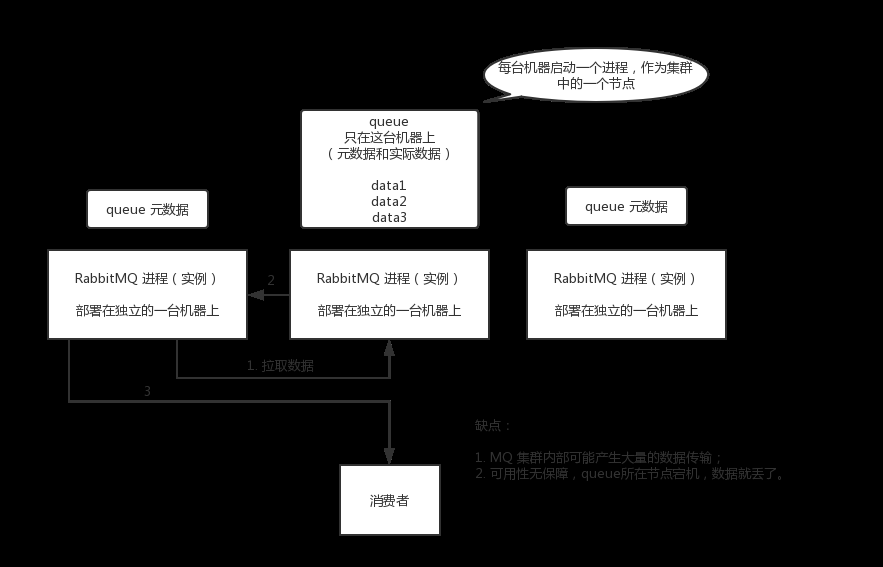
单机模式,就是 Demo 级别的,一般就是你本地启动,没人生产用单机模式。 - 普通集群模式(无高可用性)
普通集群模式,意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。
你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。
你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。
这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。
因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个 queue 所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放 queue 的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,
如果你开启了消息持久化,让 RabbitMQ 落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个 queue 拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
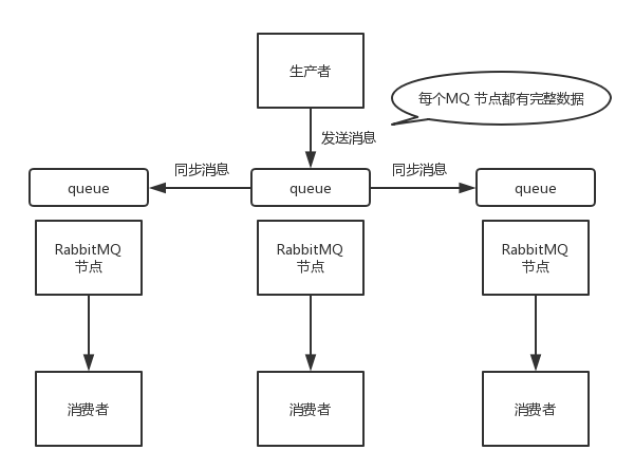
- 镜像集群模式
这种模式,才是所谓的 RabbitMQ 的高可用模式。
跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上
就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
那么如何开启这个镜像集群模式呢?其实很简单,RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有
节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
这样的话,好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。
坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!
第二,这么玩儿,不是分布式的,就没有扩展性可言了,如果某个 queue 负载很重,你加机器,新增的机器也包含了这个 queue 的所有数据,并没有办法线性扩展你的 queue。你想,如果这个
queue 的数据量很大,大到这个机器上的容量无法容纳了,此时该怎么办呢?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通