Diffusion Model扩散模型
1、扩散模型基本原理:
扩散模型包括两个步骤:
-
固定的(或预设的)前向扩散过程q:该过程会逐渐将高斯噪声添加到图像中,直到最终得到纯噪声。
2.可训练的反向去噪扩散过程pθ:训练一个神经网络,从纯噪音开始逐渐去噪,直到得到一个真实图像 。
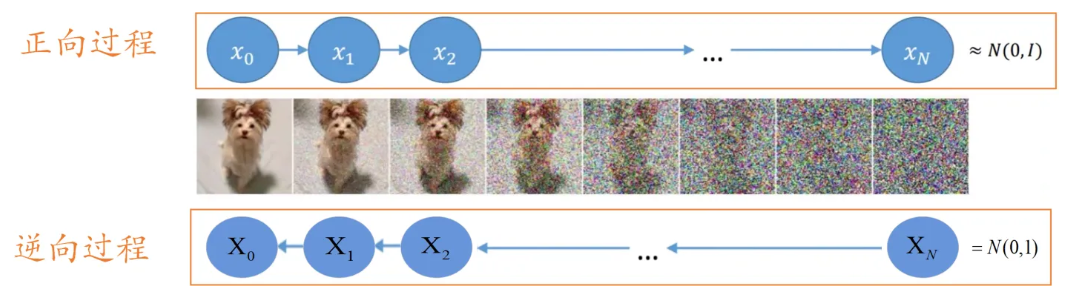
正向过程
首先,对于一张原始图片,我们给加一个高斯噪声,图片由变成x1。【注意:这里必须要加高斯噪声,因为高斯噪声服从高斯分布,后面的一些运算需要用到高斯分布的一些特性】,重复上述添加高斯噪声步骤,直到图片变成xn,由于添加了足够多的高斯噪声,现在的近似服从高斯分布(又称正态分布)。
每一步添加高斯噪声的量一直是不变的吗? 答案是每步添加高斯噪声的量是变化的,且后一步比前一步添加的高斯噪声更多。我想这一点你通过上图也非常容易理解,一开始原图比较干净,我们添加少量高斯噪声就能对原图产生干扰;但越往后高斯噪声量越多,如果还添加一开始少量的高斯噪声,那么这时对上一步结果基本不会产生任何影响。【注:后文所述的每个时刻图像和这里的每一步图像都是一个意思,如时刻图像表示的就是这个图像】
逆向过程
首先,我们会随机生成一个服从高斯分布的噪声图片,然后一步一步的减少噪声直到生成预期图片。

正向过程实现细节
正向过程其实就是一个不断加噪的过程,后一时刻的图像主要由两个量决定,其一是上一时刻图像,其二是所加噪声量。可以用一个公式来表示时刻和时刻两个图像的关系,如下:

其中,Xt表示t时刻的图像,Xt-1表示t-1时刻图像,Z1表示添加的高斯噪声,其服从N(0,1)分布。【注:N(0,1)表示标准高斯分布,其方差为1,均值为0】
其实,还和另外一个量有关:
![]()
其中,是预先给定的值,它是一个随时刻不断增大的值,论文中它的范围为[0.0001,0.02]。既然
越来越大,则
越来越小,
越来越小,1−
越来越大。

公式4得到了什么——其得到了时刻图像和
时刻图像的关系。按照我们先前的理解,我们再列出
时刻图像和
时刻图像的关系,如下:

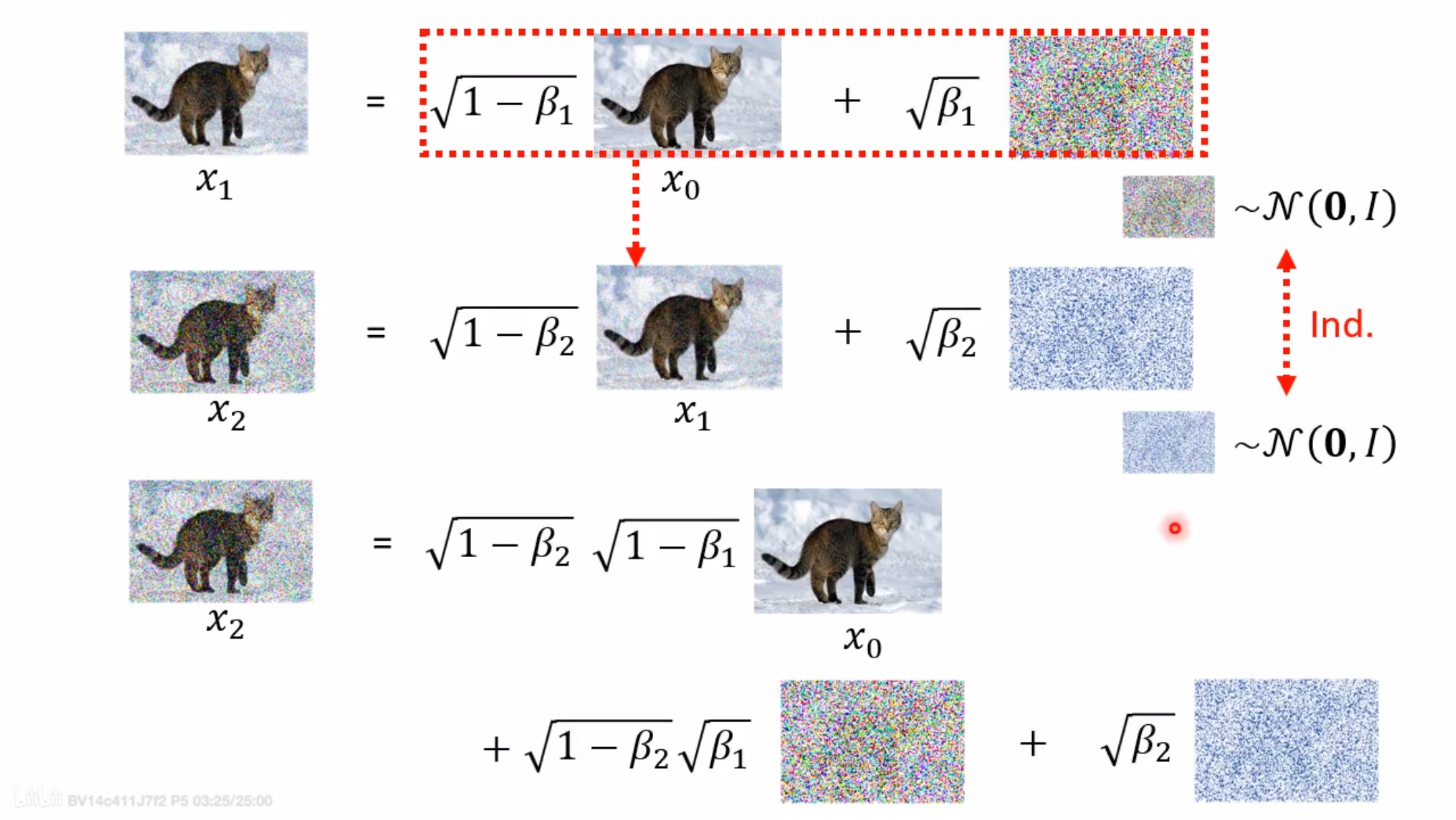

很明显的规律,这里我就根据这个规律直接写出 时刻图像和
时刻图像的关系,公式如下:

实际上就是,通过一次次的迭代太慢了,且每一次添加的噪声都独立且满足正态分布,正态分布相加还是正态分布,所以推导出了公式7
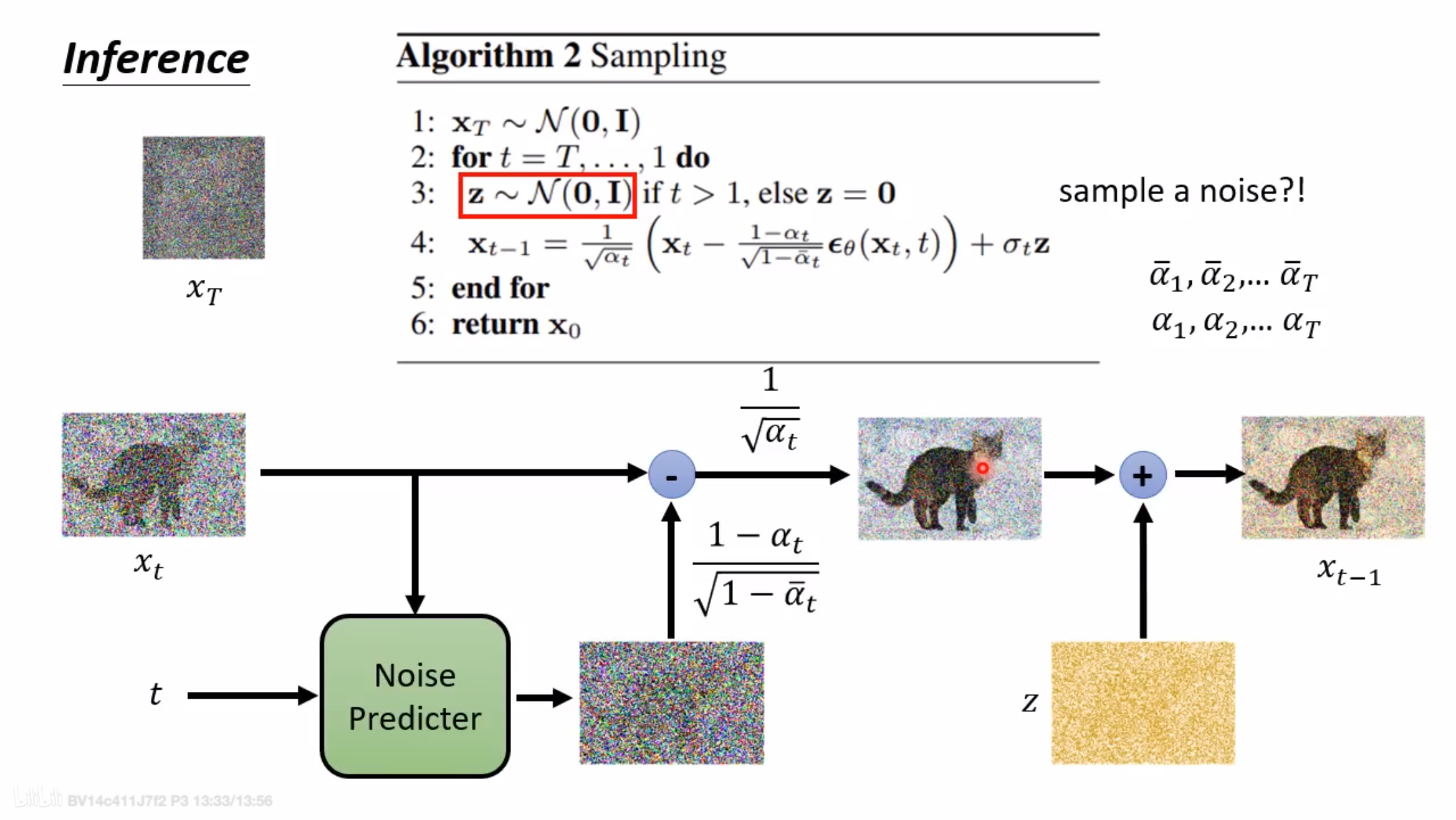
逆向过程实现细节
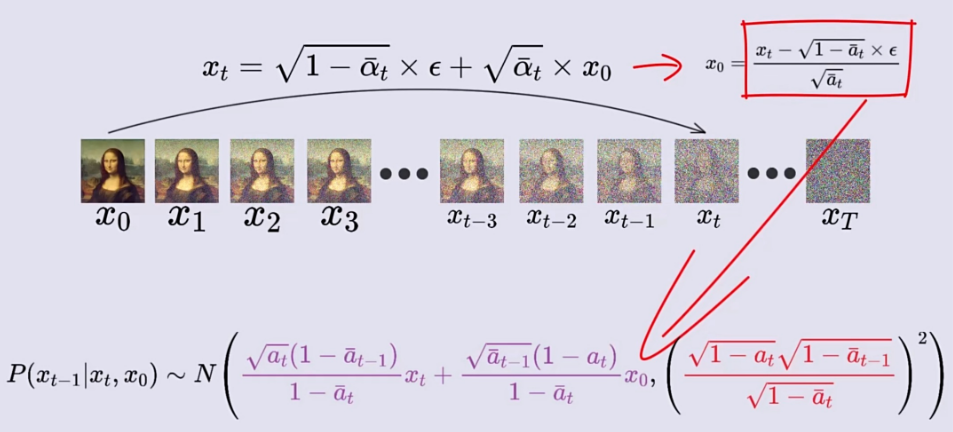
逆向过程是将高斯噪声还原为预期图片的过程。我们希望将时刻的高斯噪声变成时刻的图像,是很难一步到位的,因此我们思考能不能和正向过程一样,先考虑时刻图像和时刻的关系,然后一步步向前推导得出结论呢。
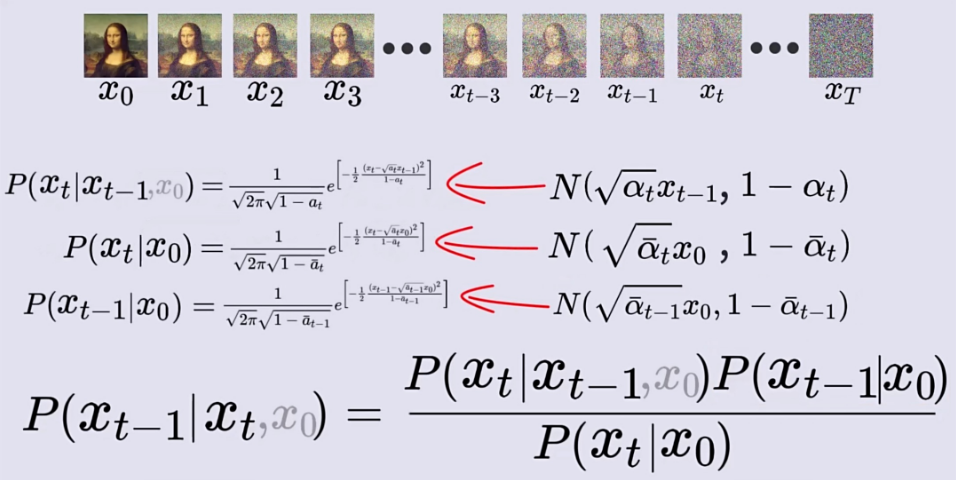
这里我们需要利用正向过程中的结论,我们在正向过程中可以由时刻图像得到 时刻图像,括号里的两个变量换了位置,这使我们很容易就联想到贝叶斯公式然后利用贝叶斯公式即可求解。贝叶斯公式的表达式如下:
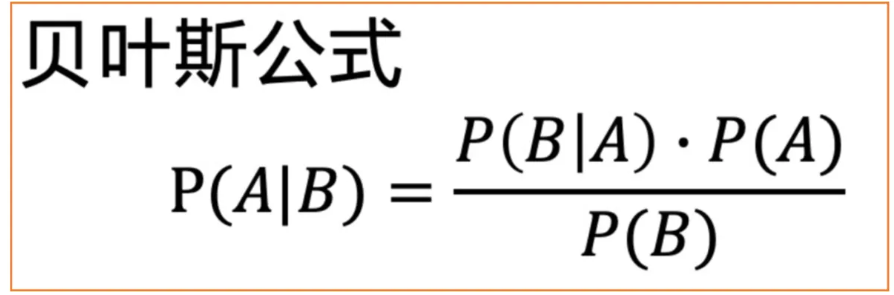
那么我们将利用贝叶斯公式来求时刻图像,公式如下:
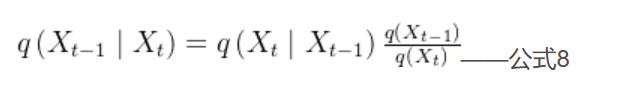
公式8中我们可以求得,就是刚刚正向过程求的嘛。 但
和
是未知的。又由公式7可知,可由
得到每一时刻的图像,那当然可以得到
和
时刻的图像,故将公式8加一个
作为已知条件,将公式8变成公式9,如下:
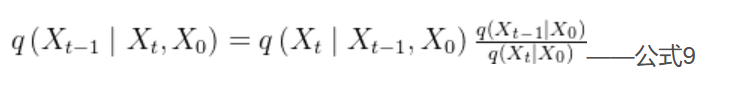
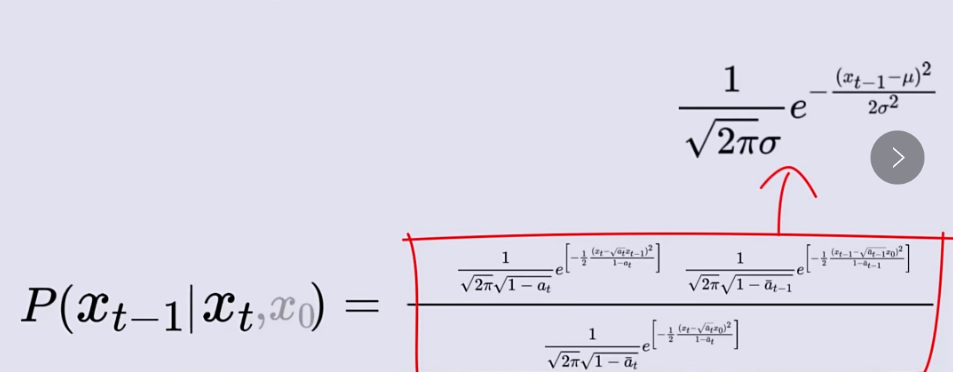
知道了公式9等式右边3项服从的分布,我们就可以计算出等式左边的。这个计算很简单,没有什么技巧,就是纯算。在附录->高斯分布性质部分我们知道了高斯分布的表达式为:
。那么我们只需要求出公式9等式右边3个高斯分布表达式,求出µ和σ,然后进行乘除运算即可求得
。 在一个高斯分布前面乘上一个系数相当于改变它的标准差,给一个高斯分布加上或减去某个数相当于改变它的均值,第三张图的右边三个式子又全部是高斯分布了!!!


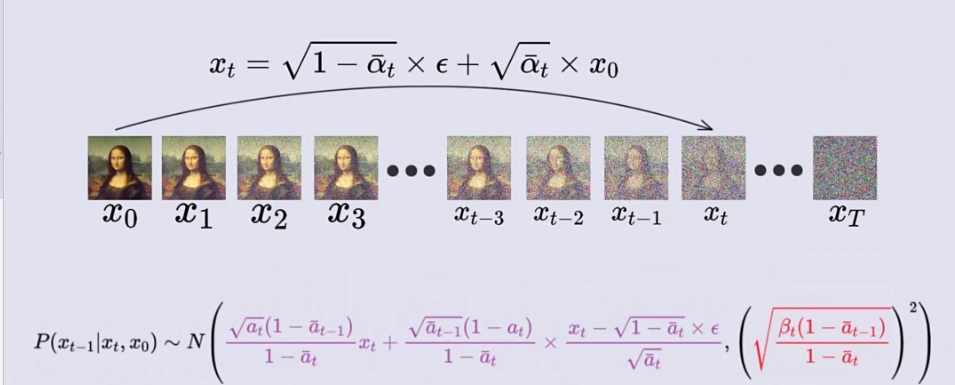
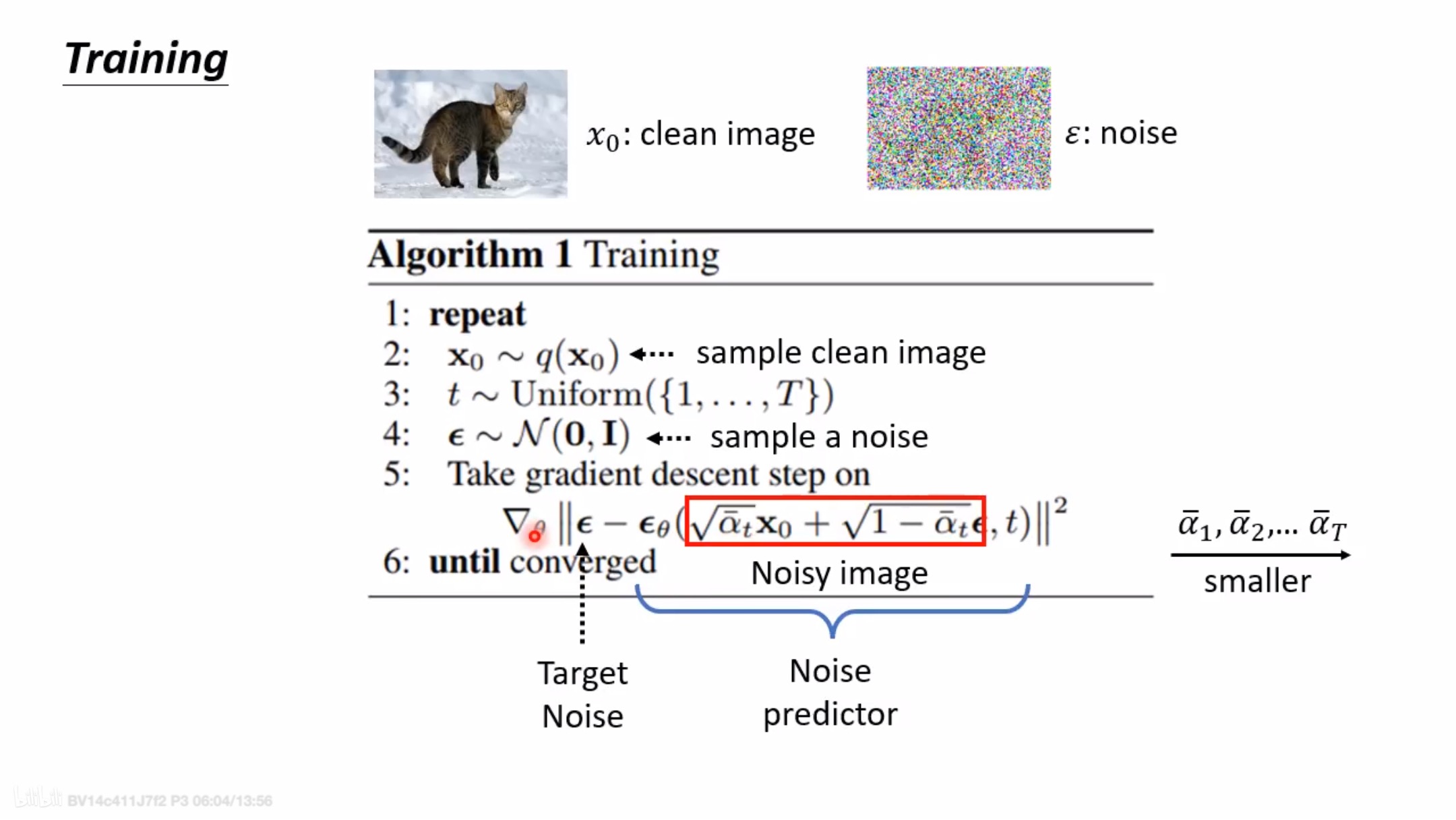
网络训练流程
我们最终要训练的实际上是一个噪声预测器。神经网络输出的噪声是![]() ,而真实的噪声取自于正态分布
,而真实的噪声取自于正态分布![]() ,则损失函数为:
,则损失函数为:
![]()
高斯分布性质
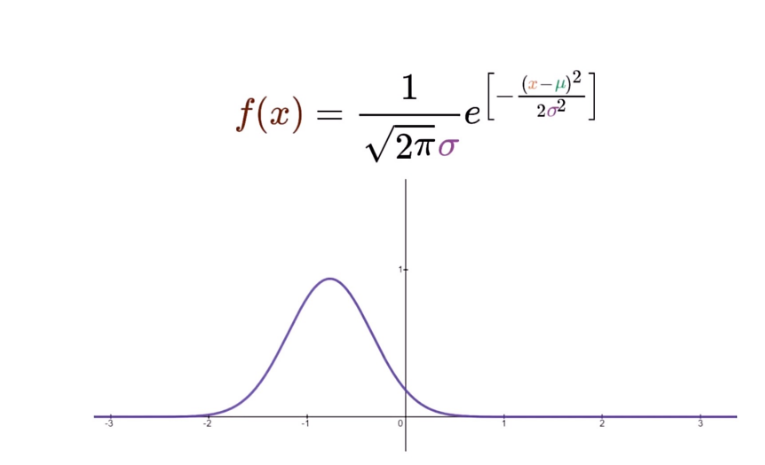
高斯分布又称正态分布,其表达式为:
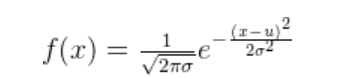
其中为均值,
为方差。若随机变量服
从正态均值为
,方差为
的高斯分布,一般记为
。此外,有一点大家需要知道,如果我们知道一个随机变量服从高斯分布,且知道他们的均值和方差,那么我们就能写出该随机变量的表达式。
高斯分布还有一些非常好的性质:
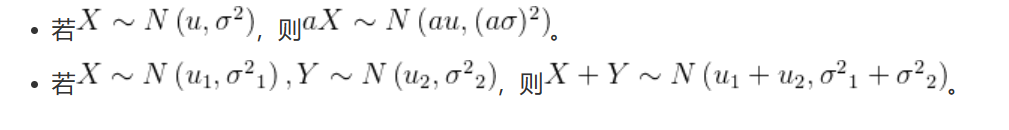

 浙公网安备 33010602011771号
浙公网安备 33010602011771号