

1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现
Apache Hadoop:Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google档案系统的论文自行制作而成。称为社区版Hadoop。
第三方发行版Hadoop:Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop,也正因此,市面上出现了很多Hadoop版本。其中有很多厂家在Apache Hadoop的基础上开发自己的Hadoop产品,比如Cloudera的CDH,Hortonworks的HDP,大快的DKhadoop产品等。
€Hortonworks发行版:Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具。
MAPR发行版:mapR有免费和商业两个版本,免费版本在功能上有所减少。
华为hadoop发行版:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底。
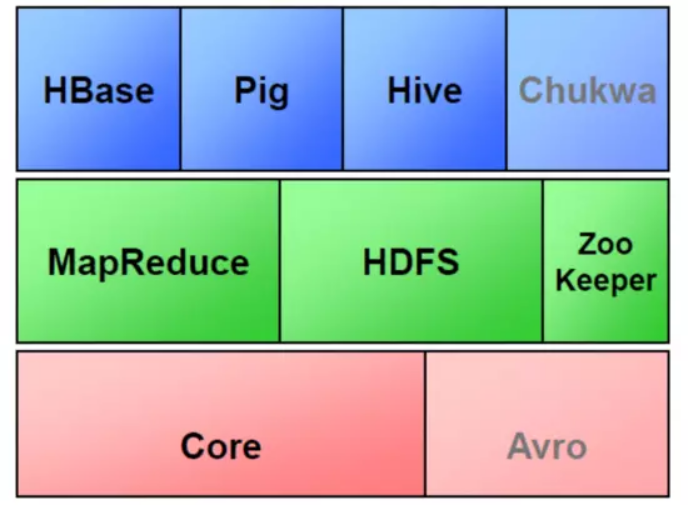
2、Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
生态系统,顾名思义就是很多组件组成的一个生态链,经过多年的发展,Hadoop生态系统不断完善和成熟,目前已经包括了多个子项目,除了核心的HDFS和MapReduce以外,Hadoop生态系统还包括要ZoopKer、HBase、Hive、Pig、Mahout、Sqoop、Flume、Ambari等功能组件。这些组件几乎覆盖了目前业界对数据处理的所有场景。
HBase:Google Bigtable的开源实现,列式数据库,可集群化,可以使用shell、web、api等多种方式访问,NoSQL的典型代表产品
Hive:支持一种与SQL几乎完全相同的语言HiveQL。除了不支持更新、索引和事务,几乎SQL的其它特征都能支持,可以看成是从SQL到Map-Reduce的映射器
Zookeeper:Google Chubby的开源实现,用于协调分布式系统上的各种服务。例如确认消息是否准确到达,防止单点失效,处理负载均衡等,应用场景:Hbase,实现Namenode自动切换,工作原理:领导者,跟随者以及选举过程
Sqoop:
用于在Hadoop和关系型数据库之间交换数据
通过JDBC接口连入关系型数据库
Chukwa:
架构在Hadoop之上的数据采集与分析框架
主要进行日志采集和分析
通过安装在收集节点的“代理”采集最原始的日志数据
代理将数据发给收集器
收集器定时将数据写入Hadoop集群
指定定时启动的Map-Reduce作业队数据进行加工处理和分析
Pig:
Hadoop客户端
使用类似于SQL的面向数据流的语言Pig Latin
Pig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数
Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼
Avro:
数据序列化工具,由Hadoop的创始人Doug Cutting主持开发 n
用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据 n
动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
Thrift接口
Cassandra:
NoSQL,分布式的Key-Value型数据库,由Facebook贡献
与Hbase类似,也是借鉴Google Bigtable的思想体系
只有顺序写,没有随机写的设计,满足高负荷情形的性能需求
3、官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
http://www.apache.org/
→Projects
→Projects List
一.hadoop安装及注意事项
1.安装hadoop的环境,必须在你的系统中有java的环境。
2.必须安装ssh,有的系统默认就安装,如果没有安装需要手动安装。
可以用yum install -y ssh 或者 rpm -ivh ssh的rpm包进行安装
二.安装并配置java环境
hadoop需要在java的环境中运行,需要安装JDK。
1.在官网上下载jdk,网址:http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html
a.进入选择相应的rpm包或者tar包,进行安装。我这里是下载的rpm包,因为这样比较方便。用rpm包不需要进行环境变量的配置就可以使用了。
# rpm -ivh /usr/java/jdk1.8.0_60.rpm
b.检查java环境是否安装成功,敲入如下命令:
# java -version 显示相应的版本号
# javac javac相应的信息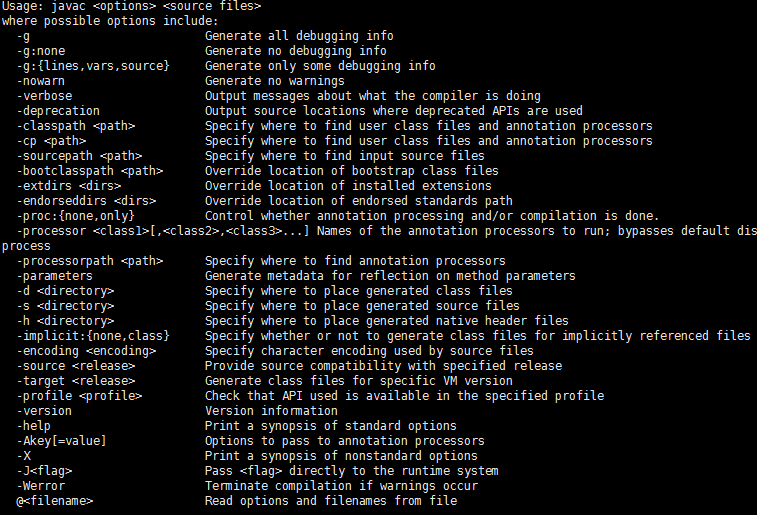
# java java相应的信息
如以上打印出来了,就表示成功。
三.下载并安装hadoop
1.进入hadoop的官网进行下载相应hadoop的版本。地址为:http://hadoop.apache.org/releases.html
a.下载相应的tar包
b.进行tar解包
# tar -ivh /usr/local/hadoop/hadoop-2.7.1.tar.gz
c.修改相应的配置文件信息,制定相应的java_home
#vi /usr/local/hadoop/hadoop-2.7.1/ etc/hadoop/hadoop-env.sh
# set to the root of your Java installation
export JAVA_HOME=/usr/java/latest #显示当前jdk安装的目录 一般rpm是安装在 usr 目录下
d.配置hadoop的环境变量(使hadoop的命令加到path中,就可以使用hadoop的相关命令)
1.编辑/etc/profile文件,在文件的后面加上如下代码:
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.1
PATH=$HADOOP_HOME\bin:$PATH
export HADOOP_HOME PATH
2.使修改的文件生效
source /etc/profile
这样就可以进入hadoop的安装目录去进行相关的命令操作了!
三.执行相关的命令
1.运行一个MapReduce Job在当地:
进入hadoop的安装目录:$ cd /usr/local/hadoop/hadoop-2.7.1/
一:格式化文件系统 $ bin/hdfs namenode -format
二:开始一个NameNode后台进程 和 DataNode 后台进程。
$ ./sbin/start-dfs.sh
hadoop的后台进程的的日志文件输出到安装目录文件下的logs文件中。
三:进入网站可以进行查看相应的NameNode
NameNode - http://localhost:50070/
四:执行MapReduce Job,必须创建HDFS文件夹
$ bin/hdfs dfs -mkdir /usr
$ bin/hdfs dfs -mkdir /usr/<username>
五:复制输入文件到分布式文件系统
$ bin/hdfs dfs -put etc/hadoop input
六:运行提供的相应的例子
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-maegrop‘./bj-getoutpreduce-examples-2.7.1.jar grep input output ‘dfs[a-z.]+‘
七:检查输出的文件:从分布式文件系统中复制输出文件到本地,并测试。
$ bin/hdfs dfs -get output output
$ cat output/*
或者查看输出文件在分布式文件系统中
$ bin/hdfs dfs -cat output/*
八:停止后台进程
$ sbin/stop-dfs.sh
四.Hadoop的相关命令
所有的Hadoop命令通过bin/ hadoop脚本调用,Hadoop脚本运行不带任何参数打印描述为所有的命令。
1.Usage: hadoop [--config confdir] [--loglevel loglevel] [COMMAND] [GENERIC_OPTIONS] [COMMAND_OPTIONS],这些选项是可选的。
a.--config confdir:覆盖默认的配置目录 . 默认是 ${HADOOP_HOME}/conf
b.--loglevel loglevel:覆盖日志等级。日志等级有:FATAL, ERROR, WARN, INFO, DEBUG, 和 TRACE,默认为INFO等级。
c.GENERIC_OPTIONS :多命令支持的共同选项.
d.COMMAND_OPTIONS:各种命令的选项是在文档描述了Hadoop的共同子项目,HDFS和YARN 在其他的文档中说明。
2.常用操作
a.可以用多个操作命令结合使用,来配置相应的hadoop
1.-archives <comma separated list of archives>:指定用逗号分隔文档,仅适用于job。
2.-conf <configuration file>:指定一个应用的配置文件。
3.-D <property>=<value>:获取属性文件中的值
4.-files <comma separated list of files>:指定以逗号分隔的文件被复制map reduce集群,仅适用于job。
5.-jt <local> or <resourcemanager:port>:指定一个resourcemanager。仅适用于job。
6.-libjars <comma seperated list of jars>:指定以逗号分隔的jar文件,包含在classpath中,仅适用于job。
五.Hadoop的常用命令
所有的hadoop命令是通过hadoop shell 命令执行,包含User Commands和Admininistration Commands。
1.User Commands:在hadoop集群的情况下要慎用。
a.archive:创建一个hadoop archive,
b.checknative: Usage: hadoop checknative [-a] [-h]
-a : 选择全部可用的包
-h:打印帮助信息
c.classpath:Usage: hadoop classpath [--glob |--jar <path> |-h |--help]
--glob:通配符
--jar <path>:write classpath as manifest in jar named path
-h 、--help:打印帮助信息
d.credential:Usage: hadoop credential <subcommand> [options]
1.create alias [-provider provider-path] :
Prompts the user for a credential to be stored as the given alias. The hadoop.security.credential.provider.path within the core-site.xml file will be used unless a -provider is indicated.
2.delete alias [-provider provider-path] [-f]
Deletes the credential with the provided alias. The hadoop.security.credential.provider.path within the core-site.xml file will be used unless a -provider is indicated. The command asks for confirmation unless -f is specified
3.list [-provider provider-path]
Lists all of the credential aliases The hadoop.security.credential.provider.path within the core-site.xml file will be used unless a -provider is indicated.
e.CLASSNAME:Usage: hadoop CLASSNAME
运行一个类名为CLASSNAME的类
f.version:Usage: hadoop version
打印hadoop的版本信息
g.trace:查看和修改Hadoop tracing 设置。可以看相应的官方文档。
h.key:管理keys。
i.jar:Usage: hadoop jar <jar> [mainClass] args...
运行一个jar文件。
适用 yarn jar去运行 YARN 应用程序。
J.fs:可以查看相应的官方文档。
k.distcp:复制文件或者目录,更多查看相应的官方文档。
2.Administration Commands:在hadoop集群的情况下要慎用
后台进程日志:
a.daemonlog:Usage:
hadoop daemonlog -getlevel <host:httpport> <classname>
hadoop daemonlog -setlevel <host:httpport> <classname> <level>
1.-getlevel host:httpport classname:
Prints the log level of the log identified by a qualified classname, in the daemon running at host:httpport. This command internally connects to http://<host:httpport>/logLevel?log=<classname>
2.-setlevel host:httpport classname level
Sets the log level of the log identified by a qualified classname, in the daemon running at host:httpport. This command internally connects to http://<host:httpport>/logLevel?log=<classname>&level=<level>
在后台进程取得或者设置日志等级为相应的类。
4.评估华为hadoop发行版本的特点与可用性。
华为 在硬件上具有天然的优势,在网络,虚拟化, PC 机等都有很强的硬件实力。华为的 FusionInsight Hadoop 版本 基于 Apache Hadoop ,构建
NameNode 、 JobTracker 、 HiveServer 的 HA 功能,进程故障后系统自动 Failover ,无需人工干预,这个也是对 Hadoop 的小修补,远不如 MapR 解决的彻底。华为在 Hadoop 社区中的 Contributor 和 Committer 也是国内最多的,算是国内技术实力较强的公司。
华为Hadoop组件中的6大特色:
1、统一的SQL接口,可以支持各种组件进行统一查询,而不需要把数据从一个组件迁移到另一个组件。
2、SparkSQL,SparkSQL概念并非华为提出,但华为为社区做出了很多贡献,自己的产品能力更强,例如华为主导向Spark SQL贡献的CPU优化器,使得稳定性和高性能比社区的开源的SQL更强。
3、完全自研的SQL引擎EIK,华为的SQL引擎更接近数据库甚至超过数据库,用户能够得到跟数据库一样甚至超过数据库交互体验效果。
4、Apach,CarbonData是华为主导的一个社区开展项目,参与者有国内众多互联网公司和大型企业,也有国外IT企业,其特点是对上层的应用无感知,提升了数据分析、数据查询的性能。
5、多级租户管理功能,FusionInsight提供的多级租户管理功能来匹配企业的组织架构,也就是说,可以有这种公司级的租户和管理员,有部门级的综合管理员,还有子部门租户和管理员,在给用户设置权限、设置资源配合有更方便的对应。
6、对异构设备支持,既支持高低配的设备在同一个大集群里,又支持开发应用可以指定某些应用运行在不同的机器上。

