算法竞赛——哈希表
一、哈希表介绍
什么是哈希表?
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
哈希表有什么用?
在 OI 中,最常见的情况应该是键值为整数的情况。当键值的范围比较小的时候,可以直接把键值作为数组的下标,但当键值的范围比较大,比如以 10^9范围内的整数作为键值的时候,就需要用到哈希表。即把一个庞大的空间/值域)映射到一个较小的空间,0~10^9 ---> 0~10^5,即0 ~ N的一个数
二、哈希函数两大操作
什么是哈希函数?
要让键值对应到内存中的位置,就要为键值计算索引,也就是计算这个数据应该放到哪里。这个根据键值计算索引的函数就叫做哈希函数,也称散列函数。
1.计算哈希函数
2.解决冲突
如果对于任意的键值,哈希函数计算出来的索引都不相同,那只用根据索引把 (key, value) 放到对应的位置就行了。但实际上,常常会出现两个不同的键值,他们用哈希函数计算出来的索引是相同的。这时候就需要一些方法来处理冲突。在 OI 中,最常用的方法是拉链法和开放寻址法。
2.1.拉链法
拉链法是在每个存放数据的地方开一个链表,如果有多个键值索引到同一个地方,只用把他们都放到那个位置的链表里就行了(链表的添加操作)。查询的时候需要把对应位置的链表整个扫一遍,对其中的每个数据比较其键值与查询的键值是否一致。
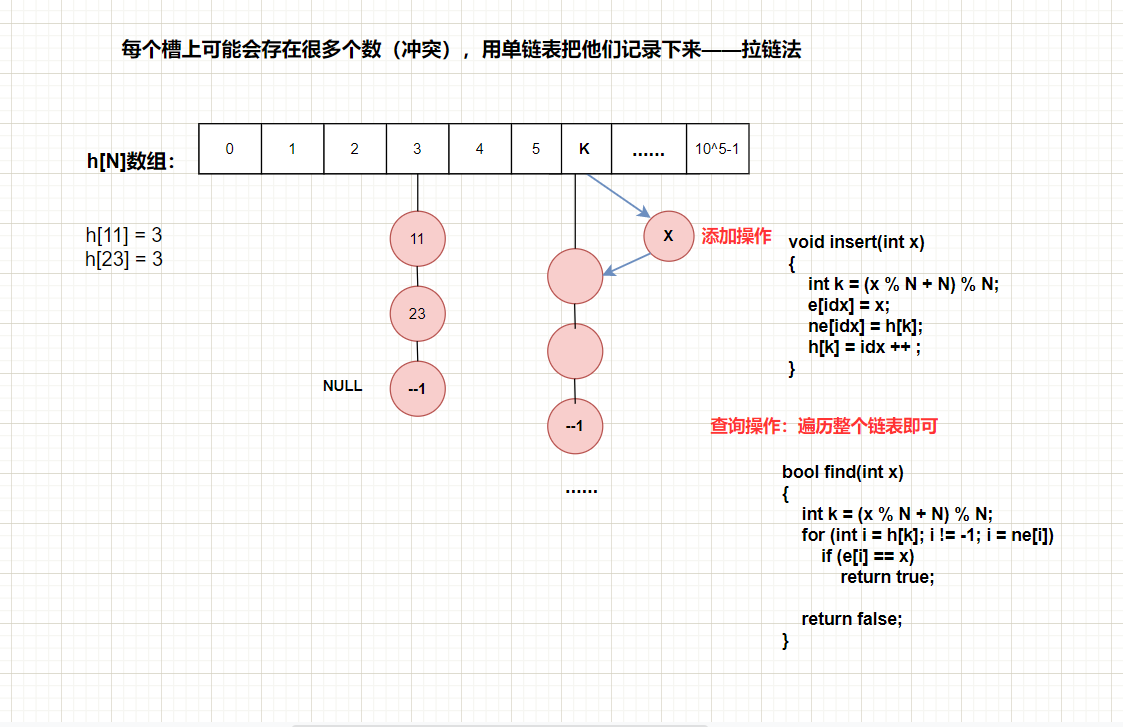
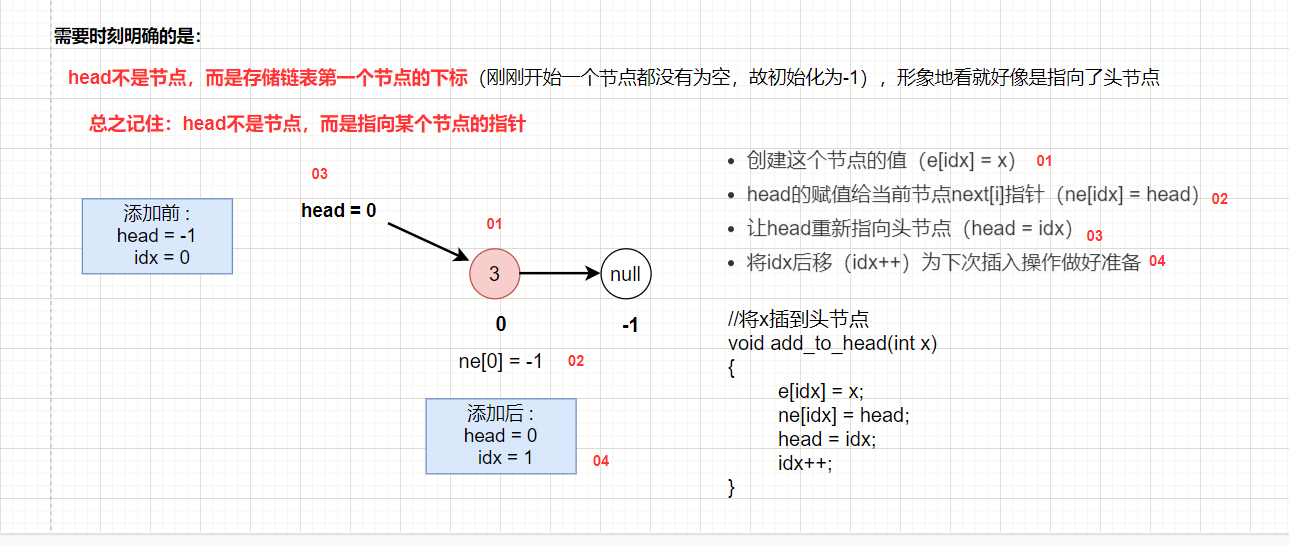
思路:利用链表处理冲突。输入x,将x进行mod映射为k,然后h[k]作为链表的头指针(相当于head记录的是头节点位置的下标),然后就是链表头插法操作:e[idx] = x, ne[idx] = h[k], h[k] = idx ++;这样就把新元素像拉链一样挂在了h数组的下面了。寻找也是同理先求x的映射k,然后从h[k]开始链表的遍历。当然,在main函数中记得要把h数组全部初始化为-1(空指针)。下图为数组模拟单链表的头插法操作:
【拉链法——参考代码】
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1e5 + 3; // 大于10万的第一个质数
int h[N];
int e[N], ne[N], idx; // idx表示当前用到了哪一个位置
// 头插法,将x查到单链表h[k]的头部————看之前模拟单链表的头插法
void insert(int x)
{
int k = (x % N + N) % N; // 将x映射成哈希值
e[idx] = x;
// h[k]是hash之后下标为k的位置存放的idx(或者说指向的元素),之前原本h[]的所有值初始化为-1(head指向头节点的指针(下标))
ne[idx] = h[k];
h[k] = idx;
idx ++;
}
bool find(int x)
{
int k = (x % N + N) % N;
// 在k的链表链表找是否存在X,h[k]即为指向头节点的下标(指针)
for(int i = h[k]; i != -1;i = ne[i])
if(e[i] == x)
return true;
return false;
}
int main()
{
int n;
cin >> n;
// 千万别忘了初始化,不然链表就没有头节点啦!
memset(h, -1 , sizeof h); // 初始化链表,一开始为空:-1
while (n -- )
{
string opt;
int x;
cin >> opt;
if(opt == "I")
{
cin >> x;
insert(x);
}
else
{
cin >> x;
if(find(x)) cout << "Yes" << endl;
else cout << "No" << endl;
}
}
return 0;
}
注:
h[N]相当于每个单链表的head指针。idx存储当前用到了哪个节点,不同单链表里的节点都是从idx这里分配的,所以它们可以共用一个idx变量。之前原本h[]的所有值初始化为-1(head指向头节点的指针)
【C++ STL】
#include<bits/stdc++.h>
using namespace std;
set<int>s;
char op;
int main()
{
int n;
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
int r;
cin>>op>>r;
if(op=='I')
s.insert(r);
else {
if(s.find(r)==s.end())
cout<<"No"<<endl;
else cout<<"Yes"<<endl;
}
}
return 0;
}
2.2.开放寻址法
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
// 数组长度一般开到个数上限的2-3倍。足够存放,这样大概率就没有冲突了
// null 用来判断当前槽位是否被使用过(不超过int范围的无穷大的数)
//N 为大于范围的第一个质数
const int N = 2e5 + 3, null = 0x3f3f3f3f;
int h[N];
int find(int x)
{
int k = (x % N + N) % N;
while(h[k] != null && h[k] != x) // 如果当前位置被占了就往后找
{
k ++;
if(k == N) k = 0; // 找到尾了,从头再来
}
//返回:可以插入x的位置k,若位置k里已存在x直接返回k的位置
return k;
}
int main()
{
int n;
cin >> n;
memset(h, 0x3f, sizeof h); // 一开始所有槽全部初始化为null
while (n -- )
{
string opt;
int x;
cin >> opt;
if(opt == "I")
{
cin >> x;
//找到x能够插入的位置
int k = find(x);
h[k] = x;
}
else
{
cin >> x;
//找x的位置看看是否存在
int k = find(x);
// 判断h[]中是否存在x
if(h[k] != null) cout << "Yes" << endl;
else cout << "No" << endl;
}
}
return 0;
}
开放寻址法总结
- memse是按字节来初始化的,int中有四个字节,初始化成0x3f就是将每个字节都初始化成0x3f,所以每个int就是 0x3f3f3f3f。
- 数组长度一般开到个数上限的2-3倍。
三、memset总结**
memse是逐一字节的进行初始的!
- 使用memset初始化一定要慎重,一般只用来初始化0、-1、0x3f这几个数字,其他的建议使用循环初始化,其他值尽量用for循环吧。
- 作为无穷大,一个数除了要保证足够大外,还要保证不能溢出。
使用0x3f3f3f3f作为INF主要原因是,两个0x3f3f3f3f的和只比int类型的最大值小一点,这样既能保证一般情况下的足够大,在两个无穷相加时还能够保证不会溢出。
四、整数哈希模板总结
拉链法:
// 拉链法
const int N = 大于范围的第一个质数(先求一下)
int h[N], e[N], ne[N], idx;
// 插入x(头插法——可以回顾之前数组模拟单链表的操作)
void insert(int x)
{
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx;
idx ++;
}
// 查询是否存在x
bool find(int x)
{
int k = (x % N + N) % N;
for(int i = h[k], i != -1; i = ne[i])
{
if(e[i] == x) return true;
}
return false;
}
注:千万别忘记了初始化链槽数组h[]:memset(h, -1, sizeof h)
开放寻址法:
// 开放寻址法
const int N = 大于2~3倍范围的第一个质数(先求一下), null = 0x3f3f3f3f; // null用来判空
int h[N]; // 数组的长度一般开到范围的2~3倍
// 寻找可以插入x的位置k/返回已存在x的位置k
int find(int x)
{
int k = (x % N + N) % N;
while(h[k] != null && h[k] != x)
{
k ++;
if(k == N) k = 0;
}
return K;
}
注:千万别忘记了初始化数组h[]:memset(h, 0x3f, sizeof h)
五、字符串哈希
(字符串哈希) O(n)+O(m)
全称字符串前缀哈希法,把字符串变成一个p进制数字(哈希值),实现不同的字符串映射到不同的数字。
注意事项:
-
任意字符不可以映射成0,否则会出现不同的字符串都映射成0的情况,比如A,AA,AAA皆为0
-
\[冲突问题:通过巧妙设置P (131 或 13331) , Q (2^{64})的值,一般可以理解为不产生冲突。 \]
typedef unsigned long long ULL,当溢出时等价于 mod 2^64方
字符串前缀哈希法的好处:
利用前缀哈希值就可以算出任一子段的哈希值!
【acwing 字符串哈希】
给定一个长度为n的字符串,再给定m个询问,每个询问包含四个整数l1,r1,l2,r2l1,r1,l2,r2,请你判断[l1,r1l1,r1]和[l2,r2l2,r2]这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数n和m,表示字符串长度和询问次数。第二行包含一个长度为n的字符串,字符串中只包含大小写英文字母和数字。
接下来m行,每行包含四个整数l1,r1,l2,r2l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从1开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出“Yes”,否则输出“No”。每个结果占一行。
数据范围
1≤n,m≤1051≤n,m≤105
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
思路:
本题需要求到一个字符串中任意两个区间的子串是否相同
可以转换为求两个区间子串的哈希值是否相等
举例说明:
"ABCDEFGHI"
123456789 (下标)
L R
字符串"A"的 哈希值为 p^0+A
字符串"AB" 哈希值为 p^1+A + p^0+B
字符串"ABC" 哈希值为 p^2+A + p^1+B + C
字符串[1,L-1]的哈希值为 p^3+A + p^2+B + p^1+C + p^0+D
字符串[1,R] 的哈希值为 p^8+A + p^7+B + ... + P^0+I 从[1,L-1]每个数都多乘了p^5(p^(R - L + 1))
那么如何求[L,R]字符串的哈希值呢,根据前缀和的思想,就是h[R] - h[L-1] (h[R]表示从[1,R]的字符串哈希值)
但是发现h[R]从[1,L-1]这一段left,每个数都比right这一段多乘了p^(R-(L-1))
所以字符串从[L,R]的哈希值为h[R] - h[L - 1] * p^(R-L+1)
【参考代码】
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef unsigned long long ULL;//由于前缀值的值会很大 所以应该将数组中的数据定义为ULL型
const int N = 1e5 + 10, P = 131;// 注:这里不能用p = 131(小写——p代表p[]数组的首地址)
char str[N];
ULL h[N]; // h[i]表示前i个字符的哈希值(前缀哈希值)h[0] = 0
ULL p[N]; // p[i]表示p^i次方
int n, m;
// 计算子区间(l ~ r)的哈希值
int get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i ++ ) cin >> str[i];
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i]; // 求前缀哈希值
p[i] = p[i - 1] * P; // 计算p[i]
}
while (m -- )
{
int l1, r1, l2, r2;
cin >> l1 >> r1 >> l2 >> r2;
if(get(l1, r1) == get(l2, r2)) puts("Yes");
else puts("No");
}
return 0;
}
字符串前缀哈希法总结
`typedef unsigned long long ULL`,当溢出时等价于 mod 2^64方 ULL h[N],P[N]
冲突问题:通过巧妙设置或的值P=131/P=13331,一般可以理解为不产生冲突。
前缀和公式(前缀哈希值):h[i] = h[i] * p + str[i];
区间和公式[l,r]的哈希值 = h[r] - h[l -1] * p[l - r + 1];
学习内容参考自:
1、[哈希表 - OI Wiki (oi-wiki.org)](https://oi-wiki.org/ds/binary-heap/)
2、acwing算法基础课
注:如果文章有任何错误或不足,请各位大佬尽情指出,评论留言留下您宝贵的建议!如果这篇文章对你有些许帮助,希望可爱亲切的您点个赞推荐一手,非常感谢啦


