人工智能与机器学习----基于SVM实现微笑识别
SVM算法应用综合练习--人脸表情识别
利用所提供的人脸微笑数据集(genki4k),训练一个微笑/非微笑识别模型,完成对人脸图片的微笑与非的识别,输出训练(train)和测试(test)的精度值(F1-score和ROC);然后保存这个模型,将其应用到人脸实时采集视频的微笑检测中,当检测到微笑人脸,视频窗口输出“smile”,否则输出“non smile”;当识别结果准确时,按“s”键,保存10张对应分类的图片到本地目录。人脸表情特征的选择不限,可以是HoG、SIFT、dlib(68个关键点), 训练算法采用SVM(sklearn或libsvm)。
一、提取图片特征
下载genki4k数据集
预览一下它文件夹中所有图片如下
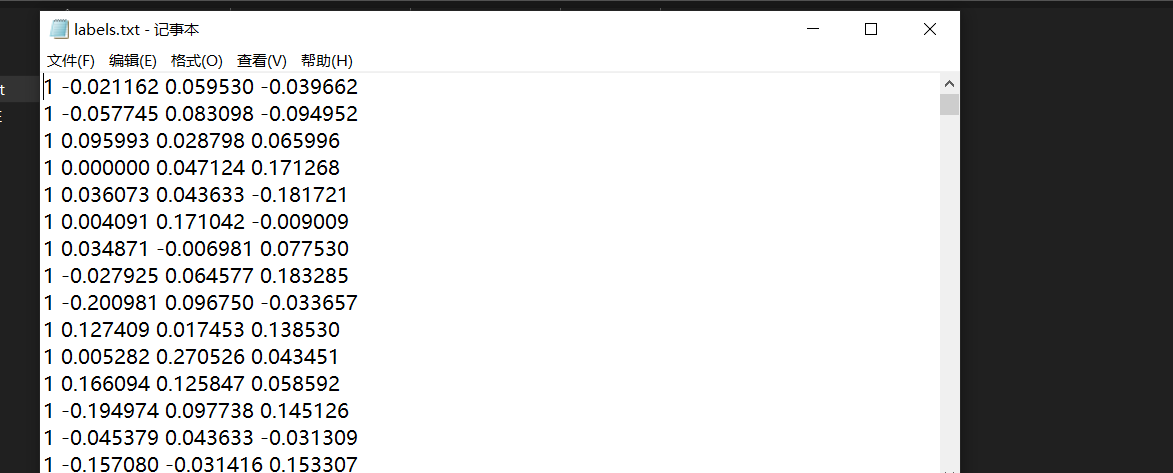
查看他的label文件得知他的每张图片标签以及相关信息
通过之前学习人脸识别时使用的dlib的68个特征值的模型,将genki4k中的4000张图片每一张都进行提取特征进行保存。
代码如下
from cv2 import cv2 as cv2
import os
import dlib
from skimage import io
import csv
import numpy as np
from libsvm.svmutil import *
#要读取人脸图像文件的路径
path_images_from_camera = "D:\\baidu\\genki4k"
# Dlib 正向人脸检测器
detector = dlib.get_frontal_face_detector()
# Dlib 人脸预测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# Dlib 人脸识别模型
# Face recognition model, the object maps human faces into 128D vectors
face_rec = dlib.face_recognition_model_v1("dlib_face_recognition_resnet_model_v1.dat")
# 返回单张图像的 128D 特征
def return_128d_features(path_img):
img_rd = io.imread(path_img)
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_BGR2RGB)
faces = detector(img_gray, 1)
if len(faces)==0:
return [0]
shape = predictor(img_gray, faces[0])
face_descriptor = face_rec.compute_face_descriptor(img_gray, shape)
return face_descriptor
# 按顺序读取每一张图片输出每一个特征值将其先进行保存
for i in range (1,4001):
if i<10:
a="000"+str(i)
elif i<100:
a="00"+str(i)
elif i<1000:
a="0"+str(i)
else :
a=str(i)
path="file"+a+".jpg"
folder_path="D:\\baidu\\genki4k\\files\\"
file_path=folder_path+path
with open('smile_face.csv','a', newline="") as f:
f_csv = csv.writer(f)
f_csv.writerow(return_128d_features(file_path))
print("完成了第"+str(i)+"张图片完成")
二、划分数据集并通过svm进行分类训练
在genki4k中有label.txt里面数据是每一张图片的标签第一个数字中的1或零就是笑或者不笑,将特征数据通过这个0和1进行分类
首先手动划分一个训练集和测试集,由于这个图片集前半部分为笑后半为不笑,取出1-50和3950-4000号作为测试集合,其他的作为训练集.
将测试集手动分隔到另一个txt文件中。
首先分别读取数据
# -*- coding: utf-8 -*-
"""
Created on Mon Nov 29 13:30:13 2021
@author: 13774
"""
from libsvm.svmutil import *
import pickle
#读取标签数据
y=open('labels.txt')
yy = y.readlines()
datay = []
index=[]
formatdatax= []
for i in range(1,129):
index.append(i)
#对数据进行整理
for i in range(0,3900):
if(len(datax[i])==1):
continue
datay.append(int(yy[i][0]))
tempx=[]
for ii in range (0,len(datax[i])):
tempx.append(float(datax[i][ii]))
formatdatax.append(dict(zip(index,tempx)))
#读取测试标签
ty=open('labels.txt')
testy=[]
tyy = ty.readlines()
formattestx=[]
#读取测试面部特征数据
tx = open("testx.txt")
testx = [i[:-1].split(',') for i in tx.readlines()]
x=open("smile_face.csv")
datax = [i[:-1].split(',') for i in x.readlines()]
进行训练并将模型保存
options = '-t 0 -c 0.9 -b 1' # 训练参数设置
model = svm_train(datay,formatdatax,options) # 进行训练
svm_save_model('mymodel.txt',model)
三、对训练完成的模型进行测试
再读取测试集的数据并且根据刚刚保存的模型进行测试
from libsvm.svmutil import *
#读取刚刚保存的模型
model=svm_load_model("../mymodel.txt")
#读取一开始分割的测试集的50张笑脸以及50张不笑的特征
x=open("testx.txt")
#设置好测试集的标签a
datay=[]
for i in range(0,50):
datay.append(1)
for i in range(0,50):
datay.append(0)
#设置测试集数据
datax = [i[:-1].split(',') for i in x.readlines()]
index=[]
for i in range(1,129):
index.append(i)
formatx=[]
for dx in datax:
for i in range(0,len(dx)):
dx[i]=float(dx[i])
for dx in datax:
formatx.append(dict(zip(index,dx)))
p_label, p_acc, p_val = svm_predict(datay,formatx, model,"-b 1") # 使用得到的模型进行预测
print(p_label)
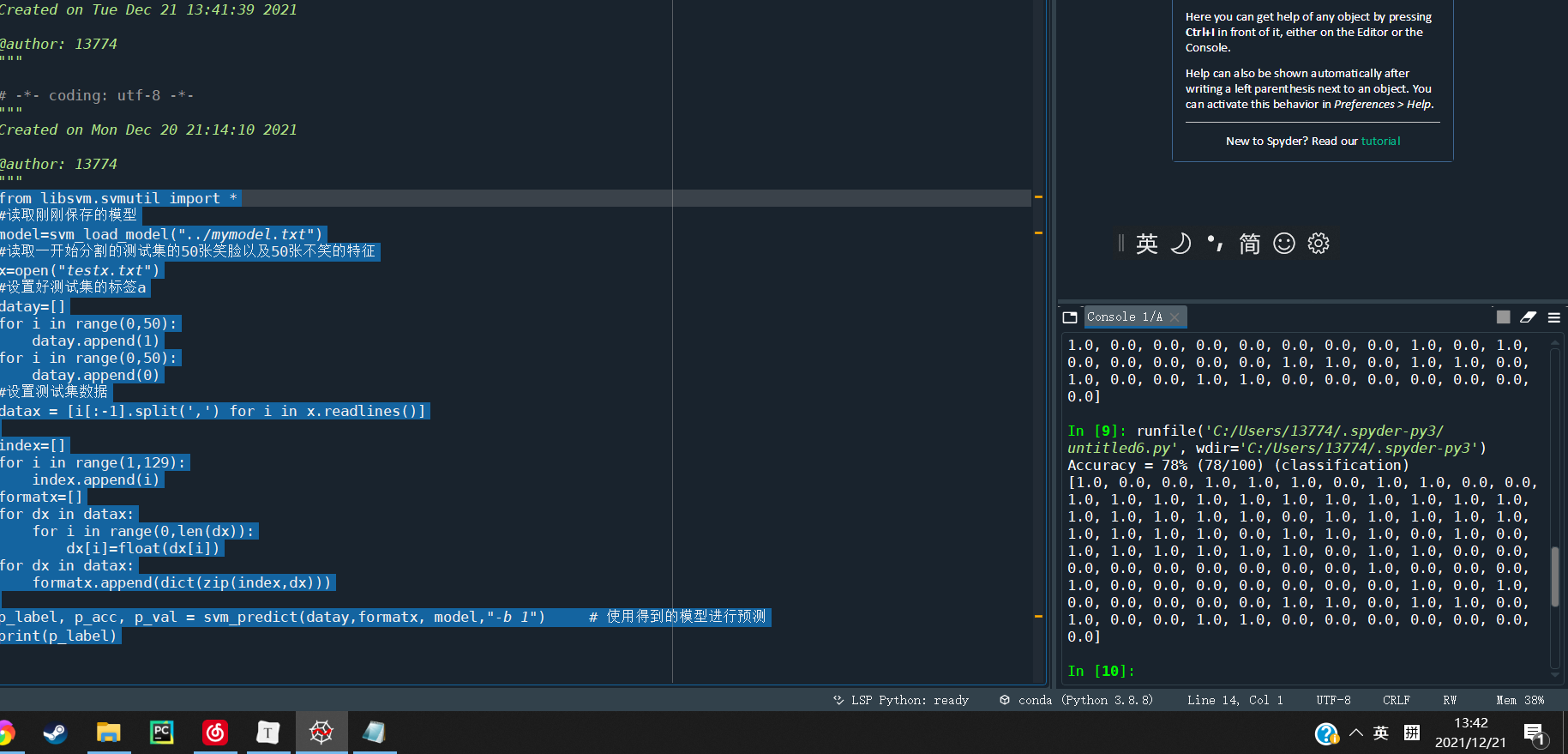
结果如下,可以发现准确率似乎并不是十分理想
将它分开看可以发现判断的图片是笑脸的时候误判的概率更小一点

四、检测别的图片的效果
虽然正确率不是很高但是在一些微笑的比较标准的图片还是可以检测出来的。
实现我们刚刚自己的模型检测图片的代码步骤也很简单,就是先提取图片人脸的特征值,再用这个模型进行检测就可以了。
from cv2 import cv2 as cv2
import os
import dlib
from skimage import io
import csv
import numpy as np
from libsvm.svmutil import *
#要读取人脸图像文件的路径
path_images_from_camera = "D:\\baidu\\genki4k"
# Dlib 正向人脸检测器
detector = dlib.get_frontal_face_detector()
# Dlib 人脸预测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# Dlib 人脸识别模型
# Face recognition model, the object maps human faces into 128D vectors
face_rec = dlib.face_recognition_model_v1("dlib_face_recognition_resnet_model_v1.dat")
# 返回单张图像的 128D 特征
def return_128d_features(path_img):
img_rd = io.imread(path_img)
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_BGR2RGB)
faces = detector(img_gray, 1)
if len(faces)==0:
return [0]
shape = predictor(img_gray, faces[0])
face_descriptor = face_rec.compute_face_descriptor(img_gray, shape)
return face_descriptor
model=svm_load_model("../mymodel.txt")
index=[]
for i in range(1,129):
index.append(i)
testy=[]
testy.append(1)
testx=[]
testx.append(dict(zip(index,return_128d_features("test1.jpg"))))
p_label, p_acc, p_val = svm_predict(testy,testx , model,"-b 1")
# 使用得到的模型进行预测
if p_label==[1.0]:
res="simle"
else:
res="no simle"
img = cv2.imread("test1.jpg")
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, res, (30, 30),font, 1.2, (0, 0, 0),2)
cv2.imshow('video', img)
cv2.waitKey(0)
现在我们去找两张图片来试试吧
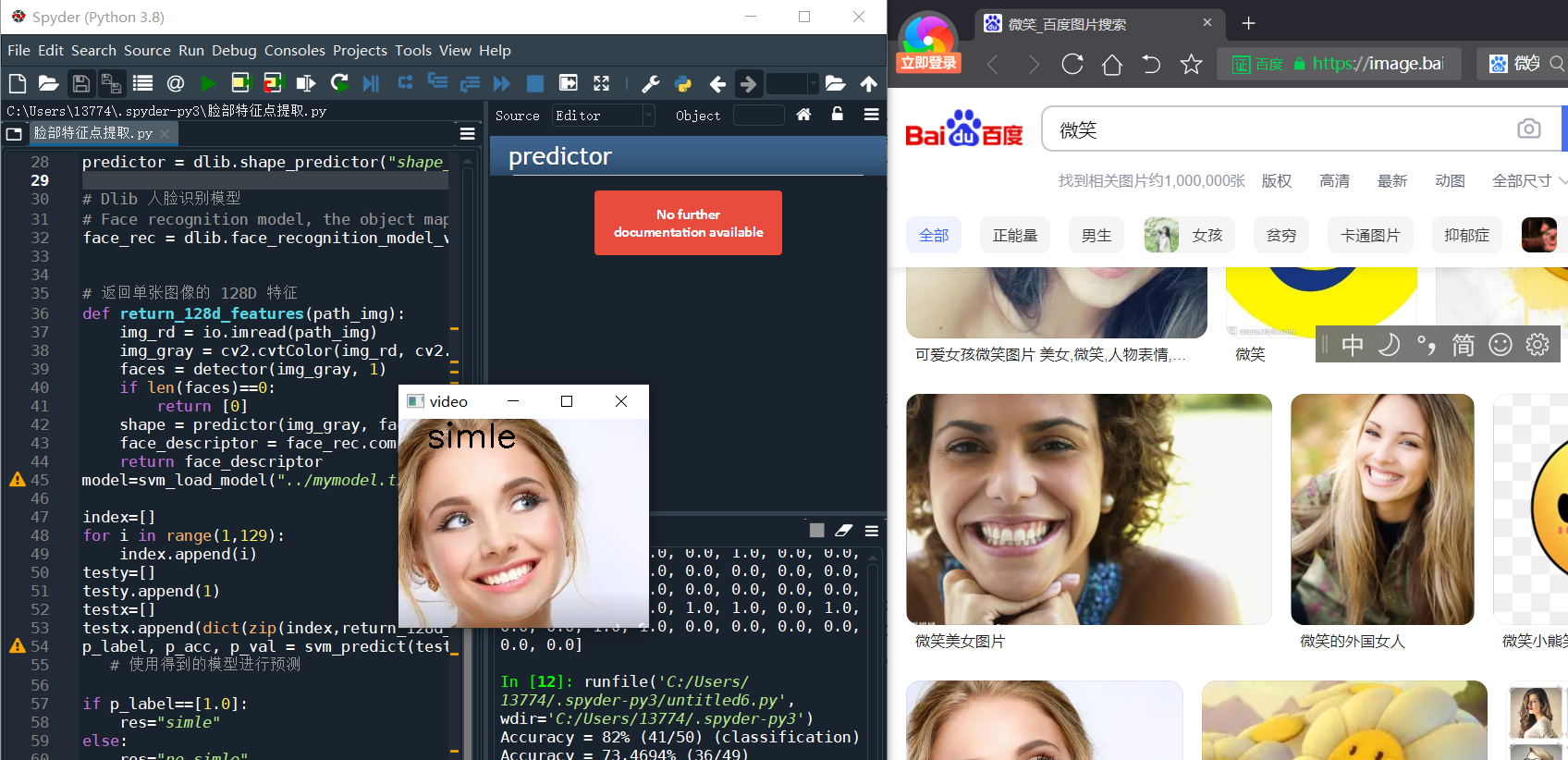
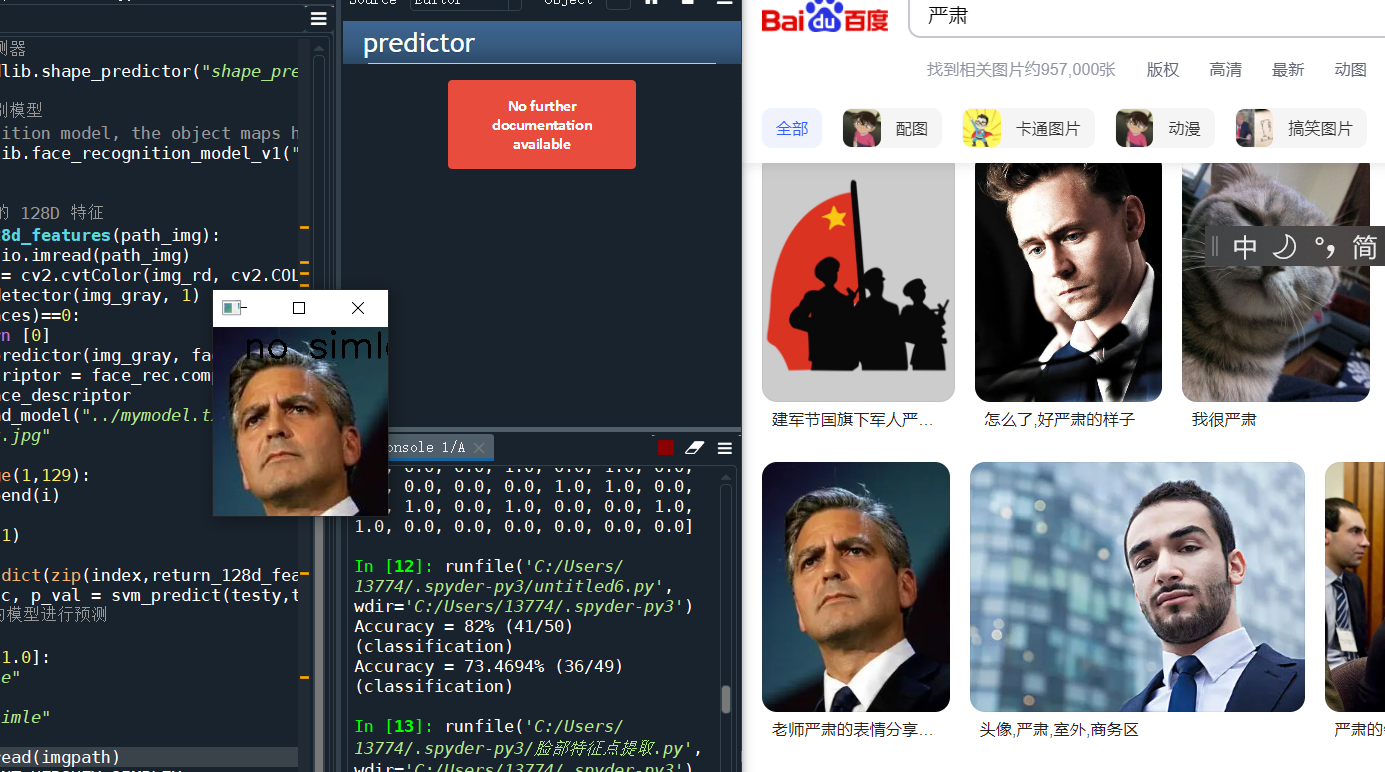
这样看来结果还是勉强算是成功的吧。
五、总结
通过这次实验,学习了自己实现一个基于SVM的机器学习的这样一个微笑识别的小项目,了解了对图像处理以及数据处理的简单方法和如何将实际的方面使用机器学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号