网络通信编程------Java网络编程以及基于Selenium爬虫
网络通信编程------Java网络编程以及基于Selenium爬虫
网络通信是源于最早的UNIX操作系统设计的 socket API(套接字函数调用,C函数形式)实现的;应用程序通过调用这些API,驱动操作系统的低层网络内核模块(TCP/IP协议栈)进行基于TCP/IP协议的数据通信;这些API函数在运行方法上分为阻塞/非阻塞、同步/异步方式,各有优缺点,用户可灵活选择应用在各种场景下。Java(JDK)也实现了类似C函数socket的JAVA IO标准网络编程,然后JDK1.4实现高级网络编程 Java NIO,最后JBoss公司推出一个基于NIO的高性能异步事件驱动的非阻塞的高级网络编程框架 Netty。 请学习和理解网上参考案例,实践练习其中的demo代码,完成:1)分别基于IO、NIO、Netty的Java网络程序(如基于TCP的C/S模式的聊天程序);2)基于Web的聊天室(比如用Springboot+netty实现)
一、基于IO、NIO、Netty的Java网络程序
1、 IO简介
服务端阻塞点
server.accept();获取套接字的时候
inputStream.read(bytes);输入流读取数据的时候
传统socket是短连接,可以做短连接服务器,他无法做长连接,属于一问一答的模式,比如老的tomcat底层用的就是socket,用完就会关掉线程,因此不会出现线程一直被占用的情况,支持处理多个客户端连接。
(1)单线程情况下只能有一个客户端(一个线程维护一个连接,也就是一个socket客户连接)线程一直被占用。
(2)用线程池可以有多个客户端连接,但是非常消耗性能(用此案城池,就是老tomcat原理,只不过是用完后就释放)2. IO实现网络程序
2、IO实现网络程序
新建两个java项目(一个Server端,一个client端)
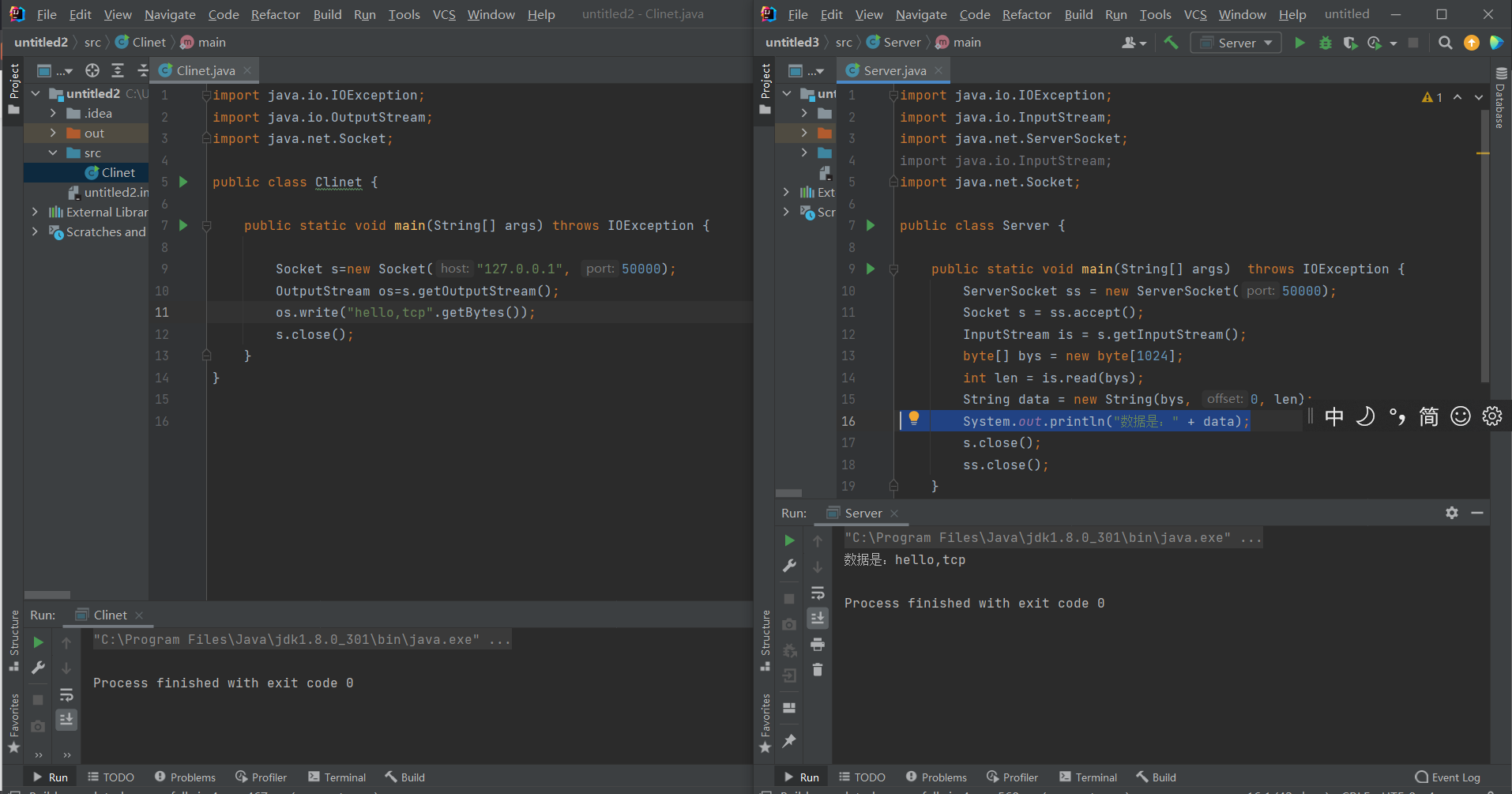
server端代码
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
import java.io.InputStream;
import java.net.Socket;
public class Server {
public static void main(String[] args) throws IOException {
ServerSocket ss = new ServerSocket(50000);
Socket s = ss.accept();
InputStream is = s.getInputStream();
byte[] bys = new byte[1024];
int len = is.read(bys);
String data = new String(bys, 0, len);
System.out.println("数据是:" + data);
s.close();
ss.close();
}
}
clinet端代码
import java.io.IOException;
import java.io.OutputStream;
import java.net.Socket;
public class Clinet {
public static void main(String[] args) throws IOException {
Socket s=new Socket("127.0.0.1", 50000);
OutputStream os=s.getOutputStream();
os.write("hello,tcp".getBytes());
s.close();
}
}
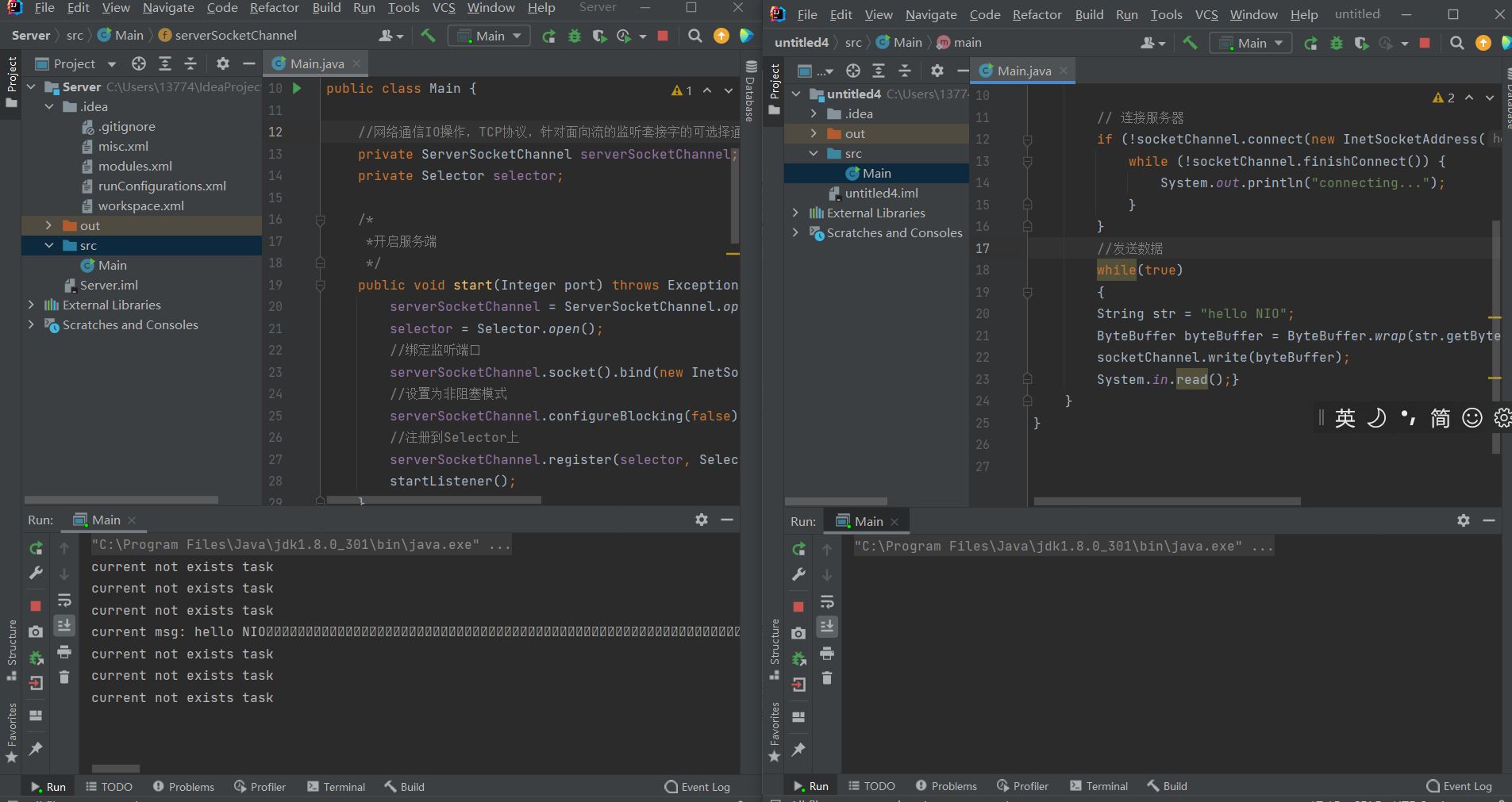
运行效果如下
3、NIO简介
NIO特点
NIO单线程模型,采用selector管理的轮询查询模式,selector每隔一段时间都去看一下client端有没有产生需要处理的消息(客户端连接请求、客户端发送数据请求、客户端下载数据请求),也就是说selector会同时管理client端的连接和通道内client端的读、写请求。
NIO单线程模型:采用selector管理的轮询查询模式,selector每隔一段时间都去看一下client端有没有产生需要处理的消息(客户端连接请求、客户端发送数据请求、客户端下载数据请求),也就是说selector会同时管理client端的连接和通道内client端的读、写请求。

4、NIO实现网络程序
Server端代码
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
public class Main {
//网络通信IO操作,TCP协议,针对面向流的监听套接字的可选择通道(一般用于服务端)
private ServerSocketChannel serverSocketChannel;
private Selector selector;
/*
*开启服务端
*/
public void start(Integer port) throws Exception {
serverSocketChannel = ServerSocketChannel.open();
selector = Selector.open();
//绑定监听端口
serverSocketChannel.socket().bind(new InetSocketAddress(port));
//设置为非阻塞模式
serverSocketChannel.configureBlocking(false);
//注册到Selector上
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
startListener();
}
private void startListener() throws Exception {
while (true) {
// 如果客户端有请求select的方法返回值将不为零
if (selector.select(1000) == 0) {
System.out.println("current not exists task");
continue;
}
// 如果有事件集合中就存在对应通道的key
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历所有的key找到其中事件类型为Accept的key
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
if (key.isAcceptable())
handleConnection();
if (key.isReadable())
handleMsg(key);
iterator.remove();
}
}
}
/**
* 处理建立连接
*/
private void handleConnection() throws Exception {
SocketChannel socketChannel = serverSocketChannel.accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ, ByteBuffer.allocate(1024));
}
/*
* 接收信息
*/
private void handleMsg(SelectionKey key) throws Exception {
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer attachment = (ByteBuffer) key.attachment();
channel.read(attachment);
System.out.println("current msg: " + new String(attachment.array()));
}
public static void main(String[] args) throws Exception {
Main myServer = new Main();
myServer.start(8888);
}
}
Clinet端代码
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
public class Main {
public static void main(String[] args) throws Exception {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false);
// 连接服务器
if (!socketChannel.connect(new InetSocketAddress("127.0.0.1", 8888))) {
while (!socketChannel.finishConnect()) {
System.out.println("connecting...");
}
}
//发送数据
while(true)
{
String str = "hello NIO";
ByteBuffer byteBuffer = ByteBuffer.wrap(str.getBytes());
socketChannel.write(byteBuffer);
System.in.read();}
}
}
二、通过Selenium进行爬虫
1、1.Selenium简介
Selenium 是ThoughtWorks专门为Web应用程序编写的一个验收测试工具。Selenium测试直接运行在浏览器中,可以模拟真实用户的行为。支持的浏览器包括IE(7、8、9)、Mozilla Firefox、Mozilla Suite等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好地工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。
2、安装Selenium
pip install selenium
3、启动浏览器并打开百度搜索
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
4、定位元素
在开发者工具中找到输入框以及搜索按钮
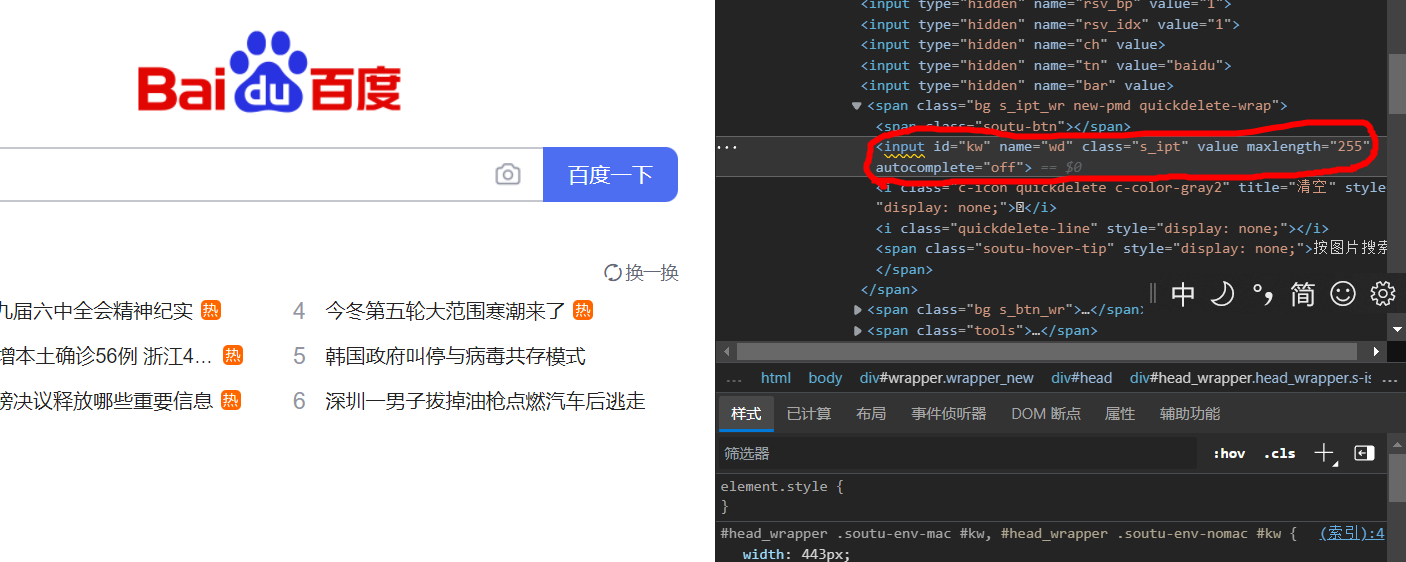
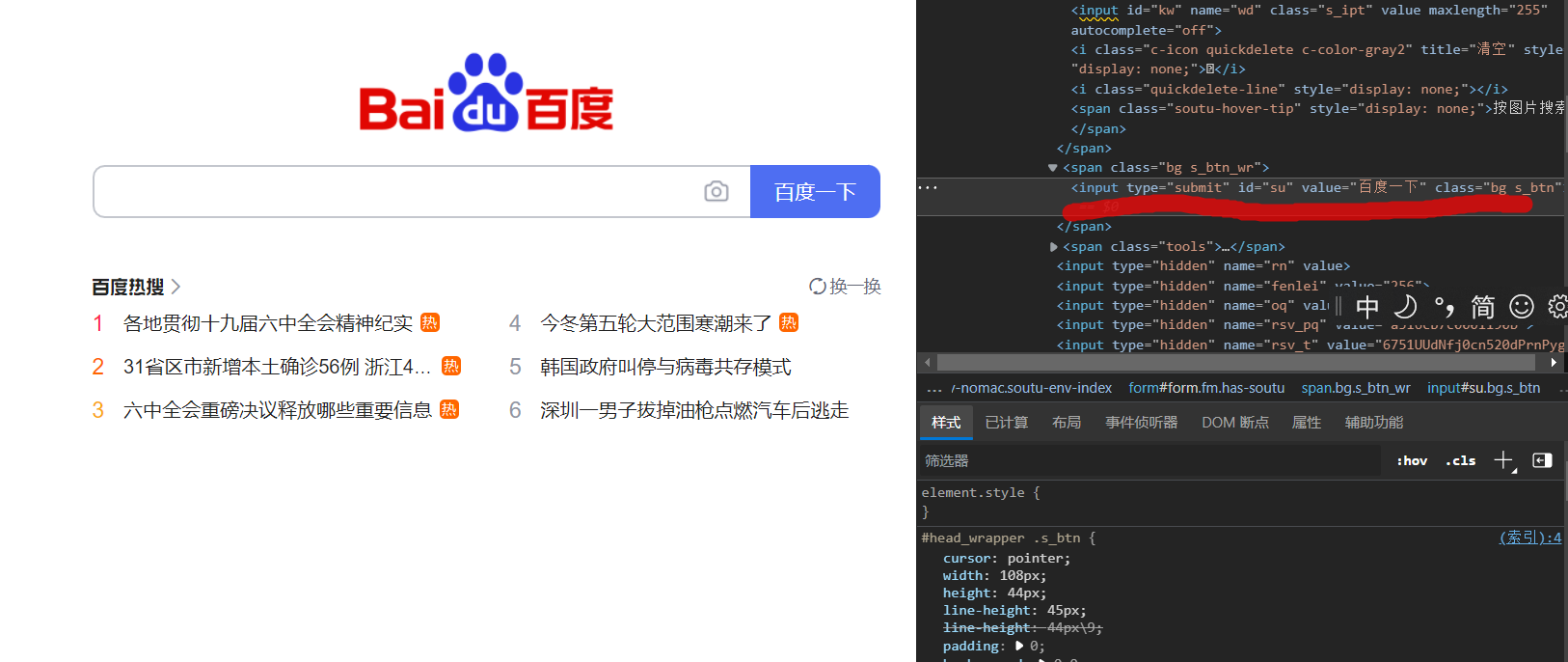
输入要查询的值并通过button点击事件实现
代码如下
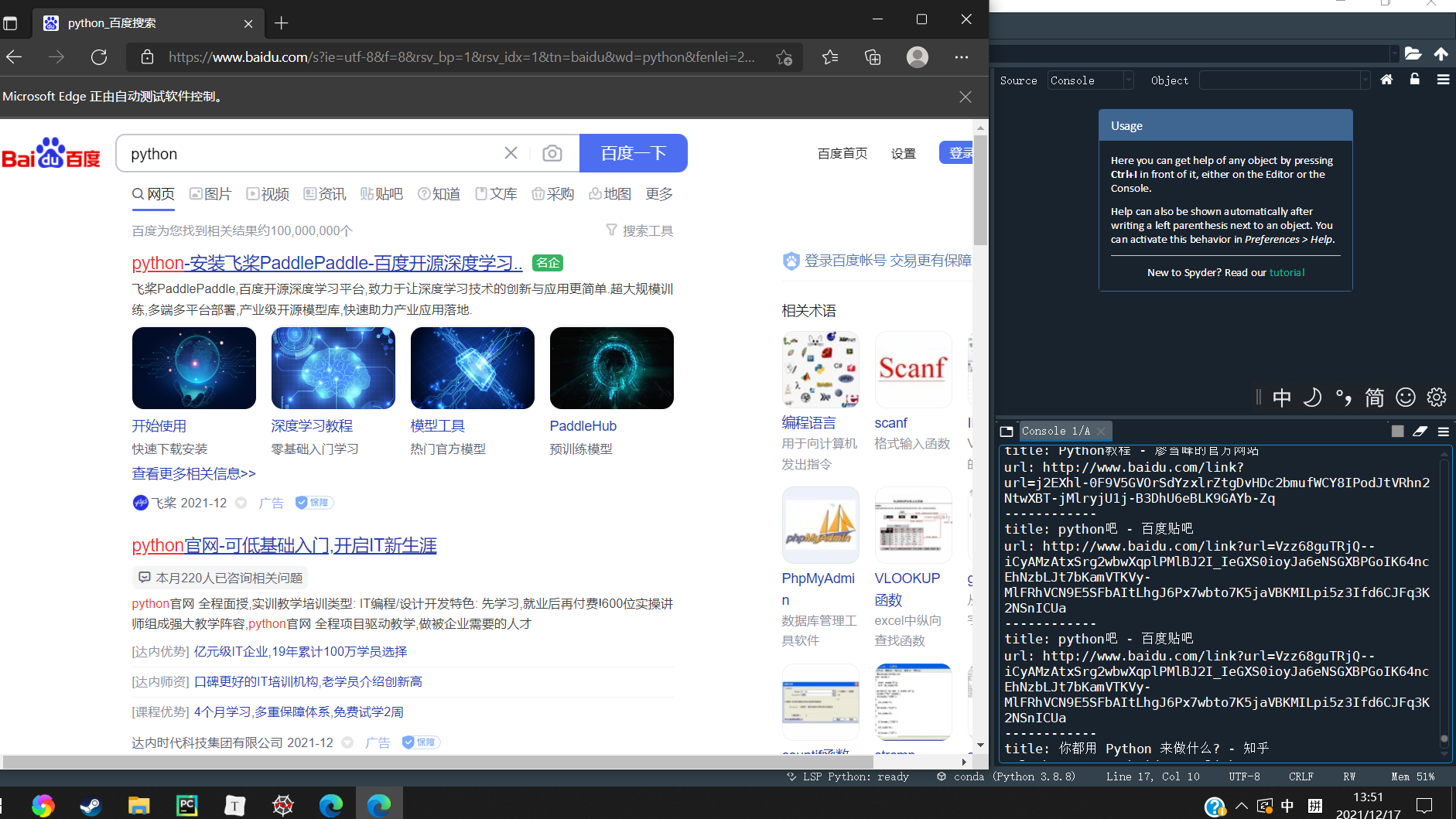
from selenium import webdriver
import time
driver = webdriver.Edge(executable_path="msedgedriver.exe")
web=driver.get("https://www.baidu.com/")
p_input = driver.find_element_by_id('kw')
p_input.send_keys('python')
p_btn = driver.find_element_by_id('su')
p_btn.click()
time.sleep(3)
ads = driver.find_elements_by_css_selector("div.c-container")
print('count:', len(ads))
for a in ads:
try:
x = a.find_element_by_css_selector('h3:nth-child(1) > a:nth-child(1)')
print('title:', x.text)
print('url:', x.get_property('href'))
print('------------')
except Exception as e:
print(e)
5、通过selenium爬取京东商城商品
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
web = Chrome(r"D:\\DevTools\\Anaconda\\download\\Anaconda3\\Lib\\site-packages\\selenium\\webdriver\\chrome\\chromedriver.exe")
web.get('https://www.jd.com/')
web.maximize_window()
web.find_element_by_id('key').send_keys('计算机图形学', Keys.ENTER) # 找到输入框输入,回车
在网页审查元素之中查看相关需要爬取的信息的位置
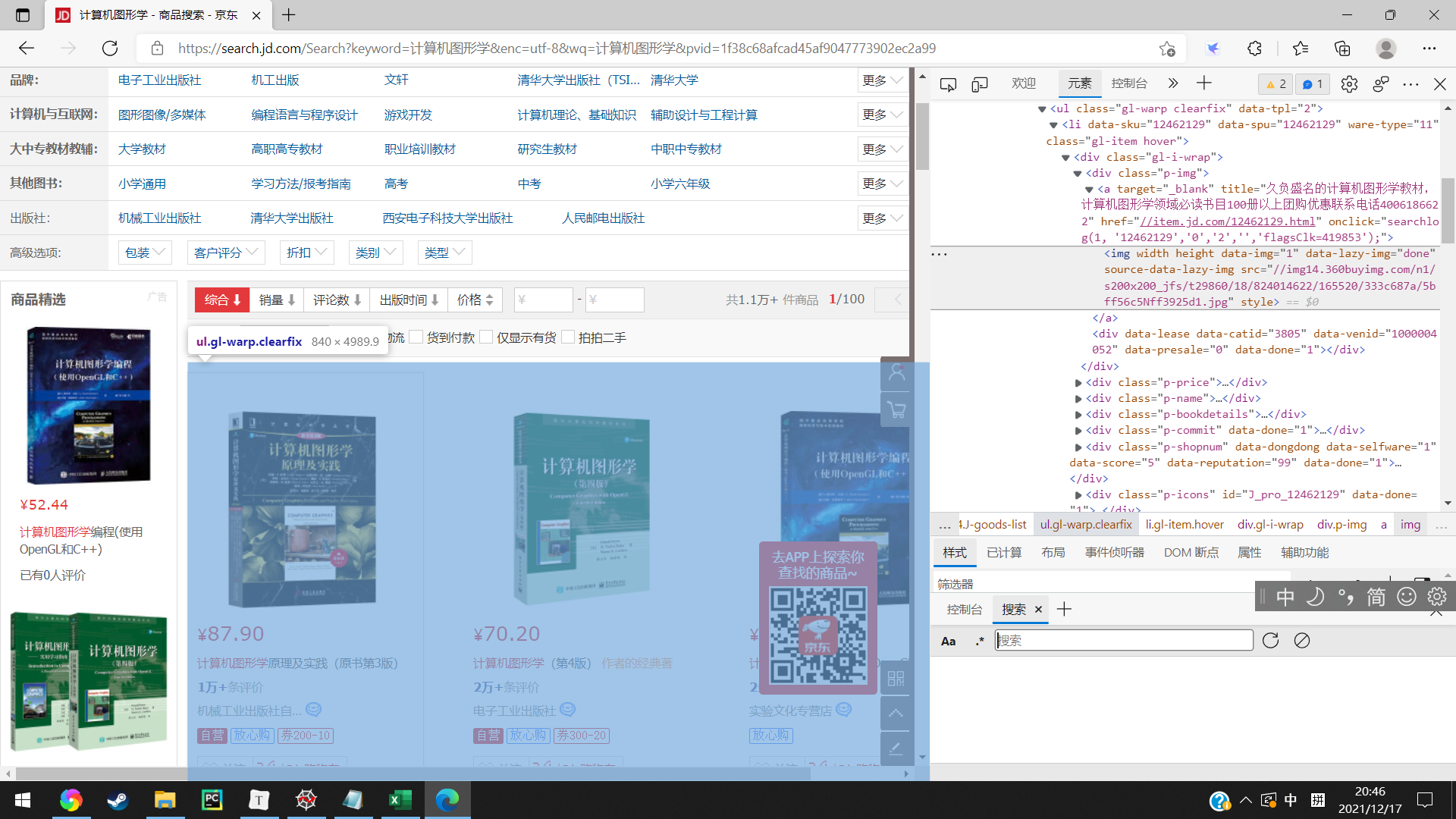
将爬取的数据进行保存,具体代码如下
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from lxml import etree
import csv
def get_onePage_info(web):
web.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(2)
page_text = web.page_source
# 进行解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//li[contains(@class,"gl-item")]')
book_infos = []
for li in li_list:
book_name = ''.join(
li.xpath('.//div[@class="p-name"]/a/em/text()')) # 书名
price = '¥' + \
li.xpath('.//div[@class="p-price"]/strong/i/text()')[0] # 价格
author_span = li.xpath('.//span[@class="p-bi-name"]/a/text()')
if len(author_span) > 0: # 作者
author = author_span[0]
else:
author = '无'
store_span = li.xpath(
'.//span[@class="p-bi-store"]/a[1]/text()') # 出版社
if len(store_span) > 0:
store = store_span[0]
else:
store = '无'
img_url_a = li.xpath('.//div[@class="p-img"]/a/img')[0]
if len(img_url_a.xpath('./@src')) > 0:
img_url = 'https' + img_url_a.xpath('./@src')[0] # 书本图片地址
else:
img_url = 'https' + img_url_a.xpath('./@data-lazy-img')[0]
one_book_info = [book_name, price, author, store, img_url]
book_infos.append(one_book_info)
return book_infos
def main():
web = webdriver.Edge("msedgedriver.exe")
web.get('https://www.jd.com/')
web.maximize_window()
web.find_element_by_id('key').send_keys('计算机图形学', Keys.ENTER)
time.sleep(2)
all_book_info = []
for i in range(0, 3):
all_book_info += get_onePage_info(web)
print('爬取第' + str(i+1) + '页成功')
web.find_element_by_class_name('pn-next').click() # 点击下一页
time.sleep(2)
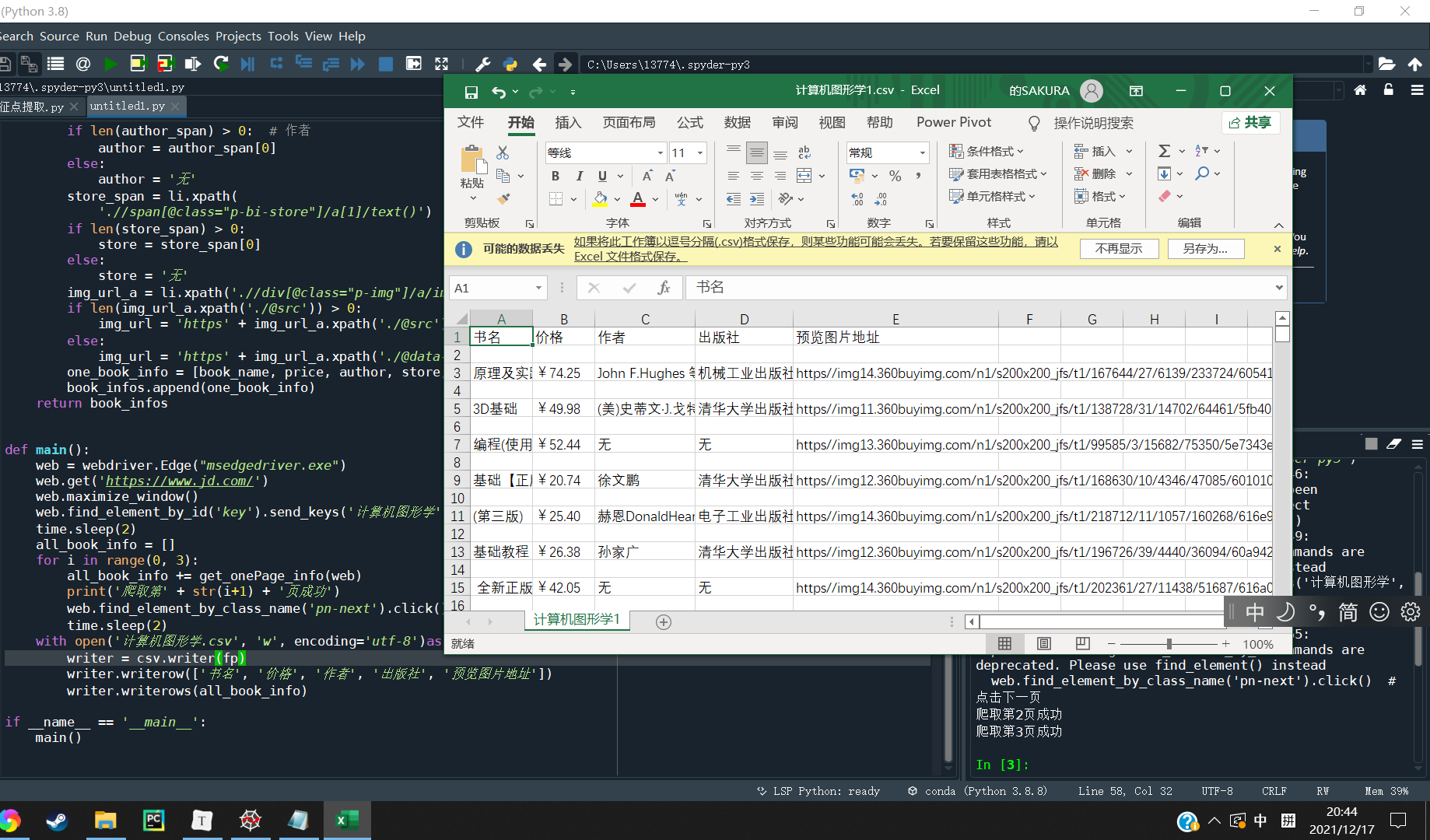
with open('计算机图形学.csv', 'w', encoding='utf-8')as fp:
writer = csv.writer(fp)
writer.writerow(['书名', '价格', '作者', '出版社', '预览图片地址'])
writer.writerows(all_book_info)
if __name__ == '__main__':
main()