网络协议抓包分析与爬虫入门-------网络通信编程(四)
网络协议抓包分析与爬虫入门-------网络通信编程(四)
一.网络协议抓包分析
1.在两台及两台以上的电脑(已知IPv4地址)上运行 “疯狂聊天”程序,通过wireshark抓包
1)分析此程序网络连接采用的是哪种协议(TCP、UDP)和什么端口号?
2)试着在抓取包中找到窃取到的聊天信息 (英文字符和汉字可能经过了某种编码转换,数据包中不是明文)3)如果是网络连接采取的是TCP,分析其建立连接时的3次握手,断开连接时的4次握手;如果是UDP,解释该程序为何能够在多台电脑之间(只有是同一个聊天室编号)同时传输聊天数据?
1.打开软件开始测试
打开软件第一步输入一个昵称,两个人进入一个聊天室,点击确定进入聊天界面
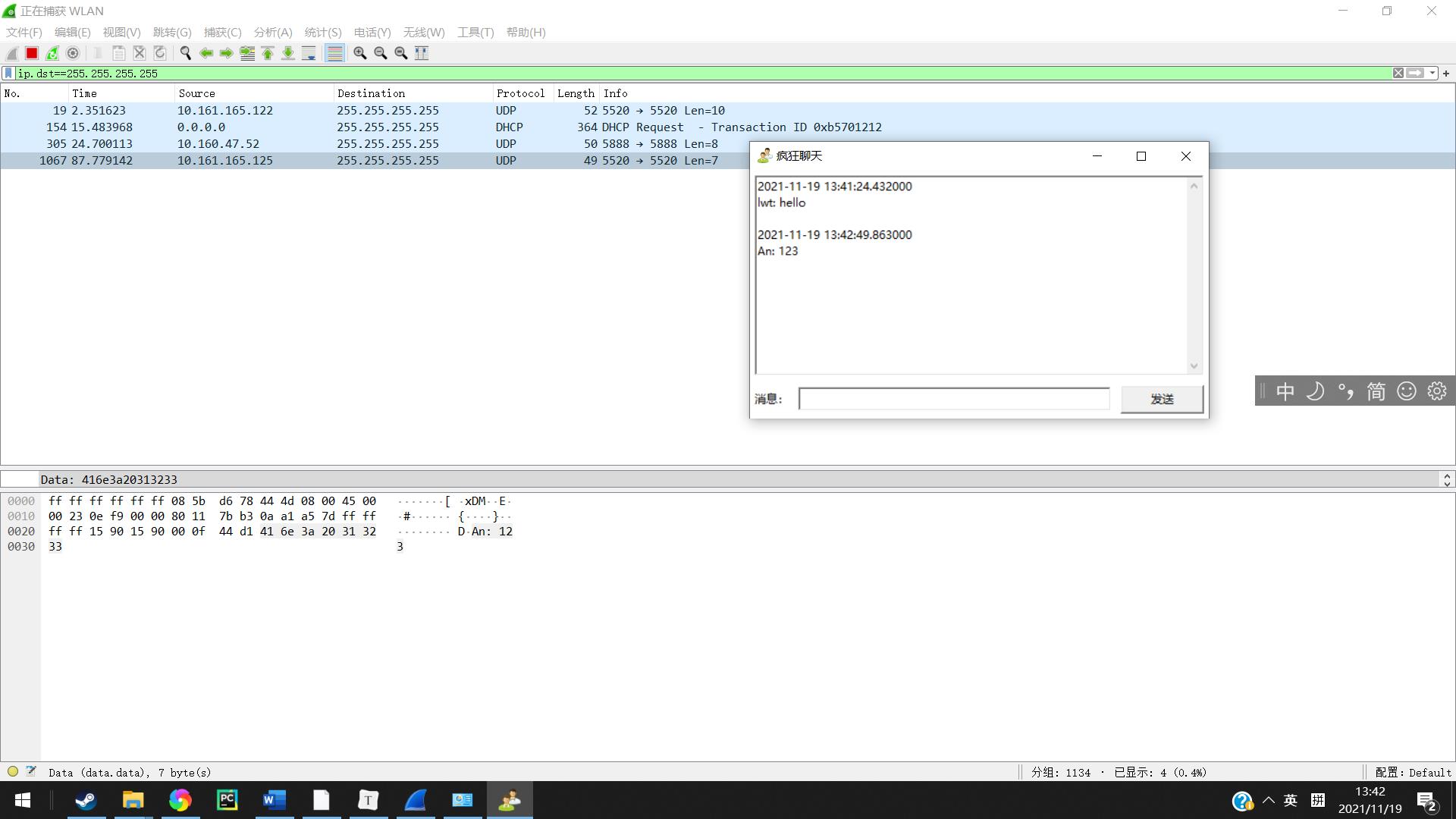
在输入框中输入hellorworld将数据发送,打开wireshark软件,在上方输入i.dst==255.255.255.255进行筛选,可以发现刚刚发出的网络包便被找到了
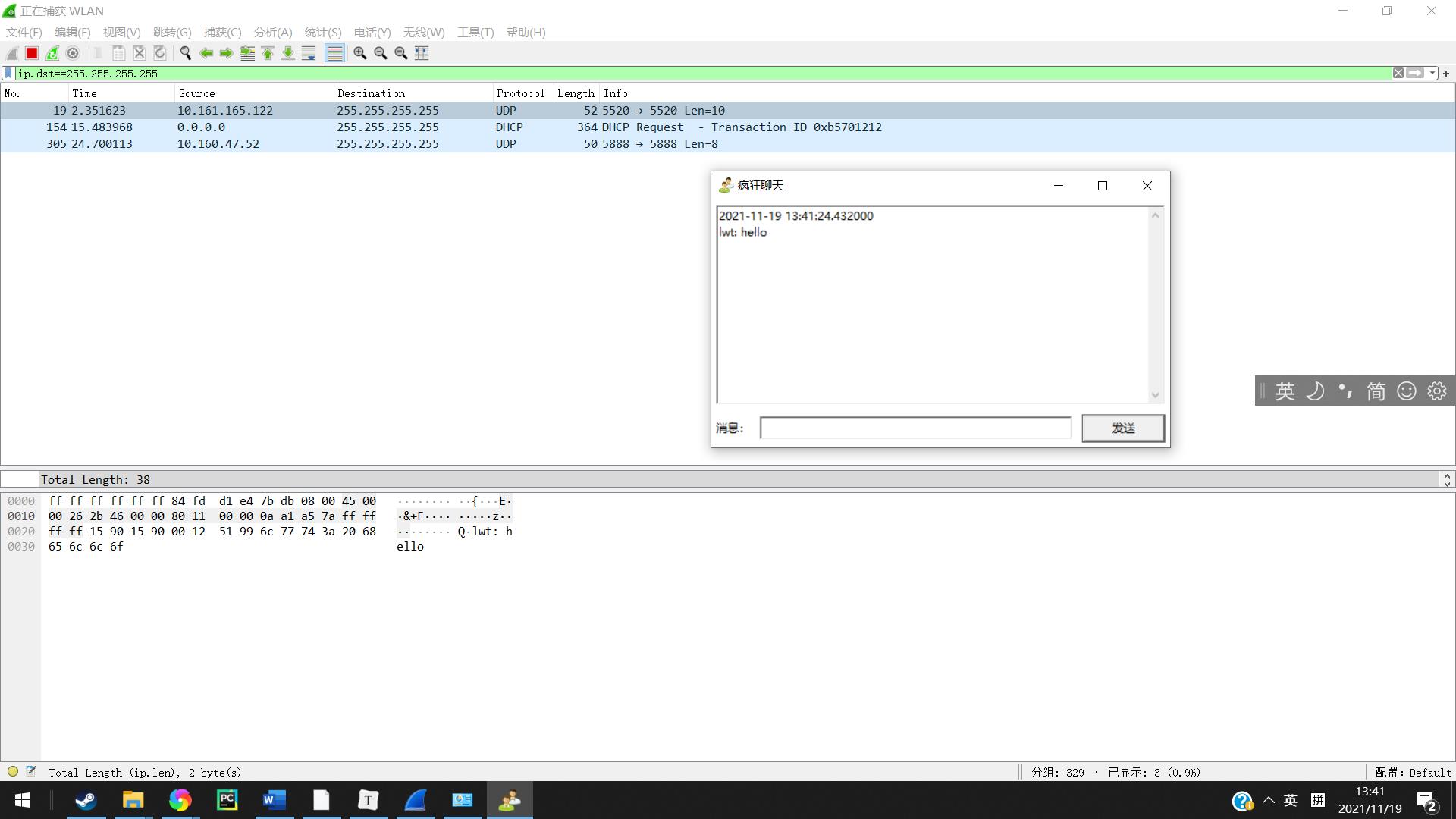
2.抓包分析数据
英文及数字
在包的data部分便可以发现我们传输的信息也就是账号名字以及内容。
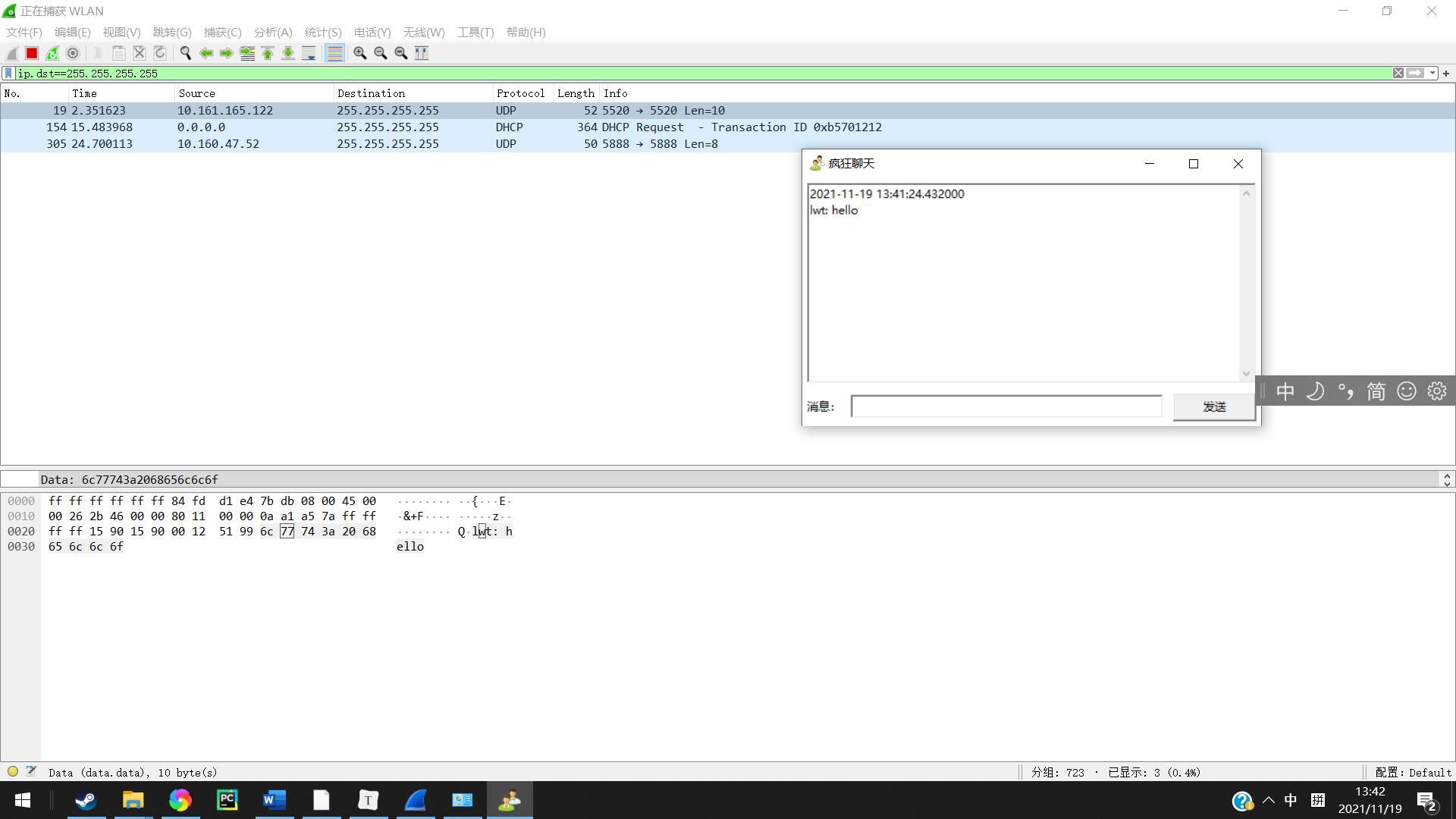
在让对方发送也可以发现接收到的网络的包
汉字
我们再进行对汉字抓包的一个测试,发现汉字在传输过程之中是通过utf-8编码后进行传输的。
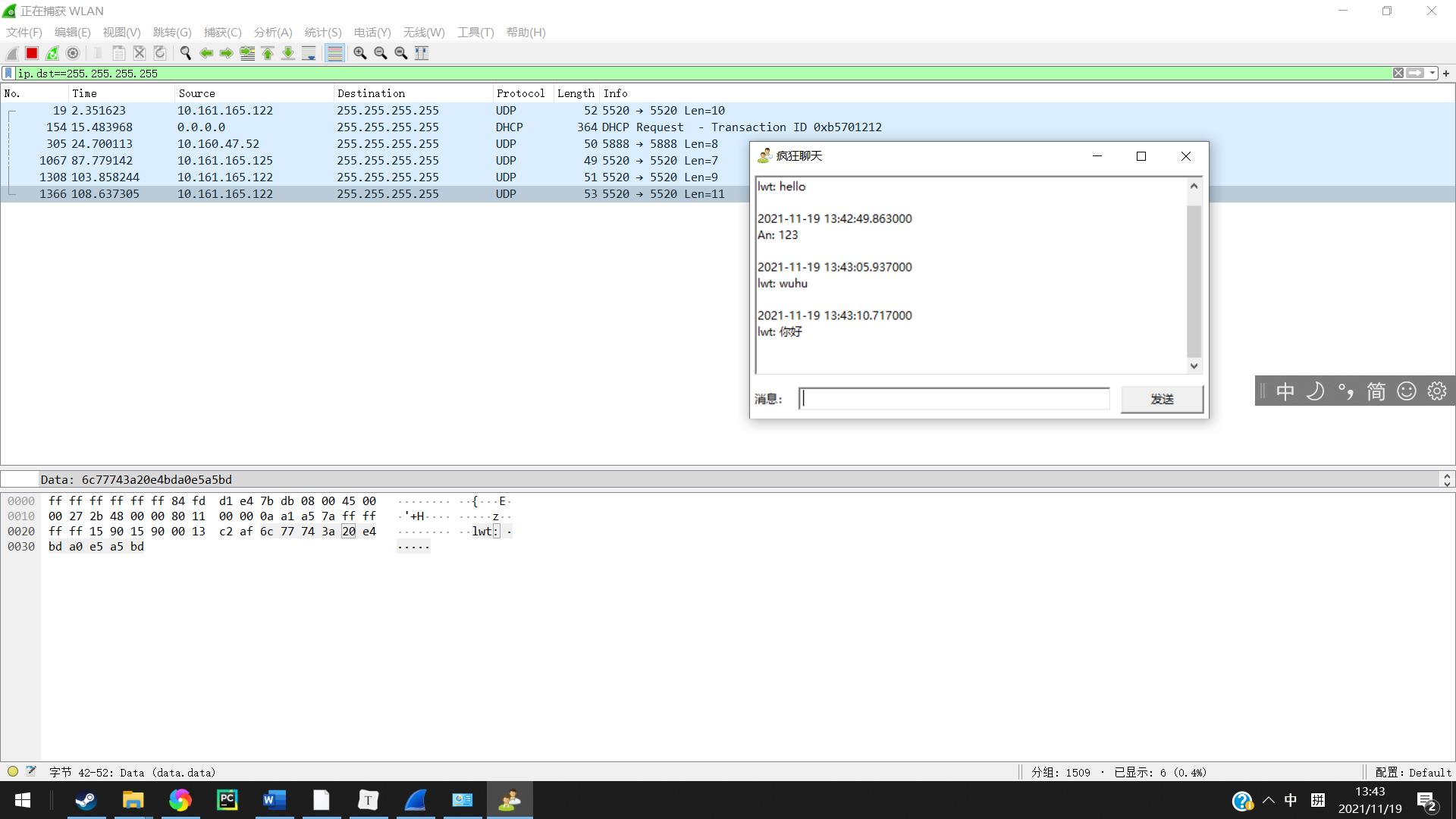
“你好”所对找到UTF-8编码便是E4BDA0 E5A5BD

3.总结
软件使用的协议是UDP,连接端口是5005,能在多台电脑上同时传输聊天数据的原因是发送信息时使用的广播地址。
二.爬虫入门学习------爬取校园网新闻
通过爬虫程序的编写,进一步理解HTTP协议。用conda建立一个名为crawler的python虚拟环境,在此虚拟环境中用pip或conda安装requests、beautifulsoup4等必要包(若有网络问题,请切换国内镜像网站或国外网站仓库,注意两个安装工具使用不同的仓库)。当使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要自己选择设置IDE后台使用的python版本或虚拟环境。比如当使用jupyter notebook时,,在jupyter运行的web界面中选择对其应的python内核Kernel(有虚拟环境列表)。
1.分析网址找到需要爬取的内容的位置
打开网站右键审查元素可以轻易的发现我们要爬取的信息的位置以及他们所在的结构。这里我们需要爬取的是信息的时间和标题。
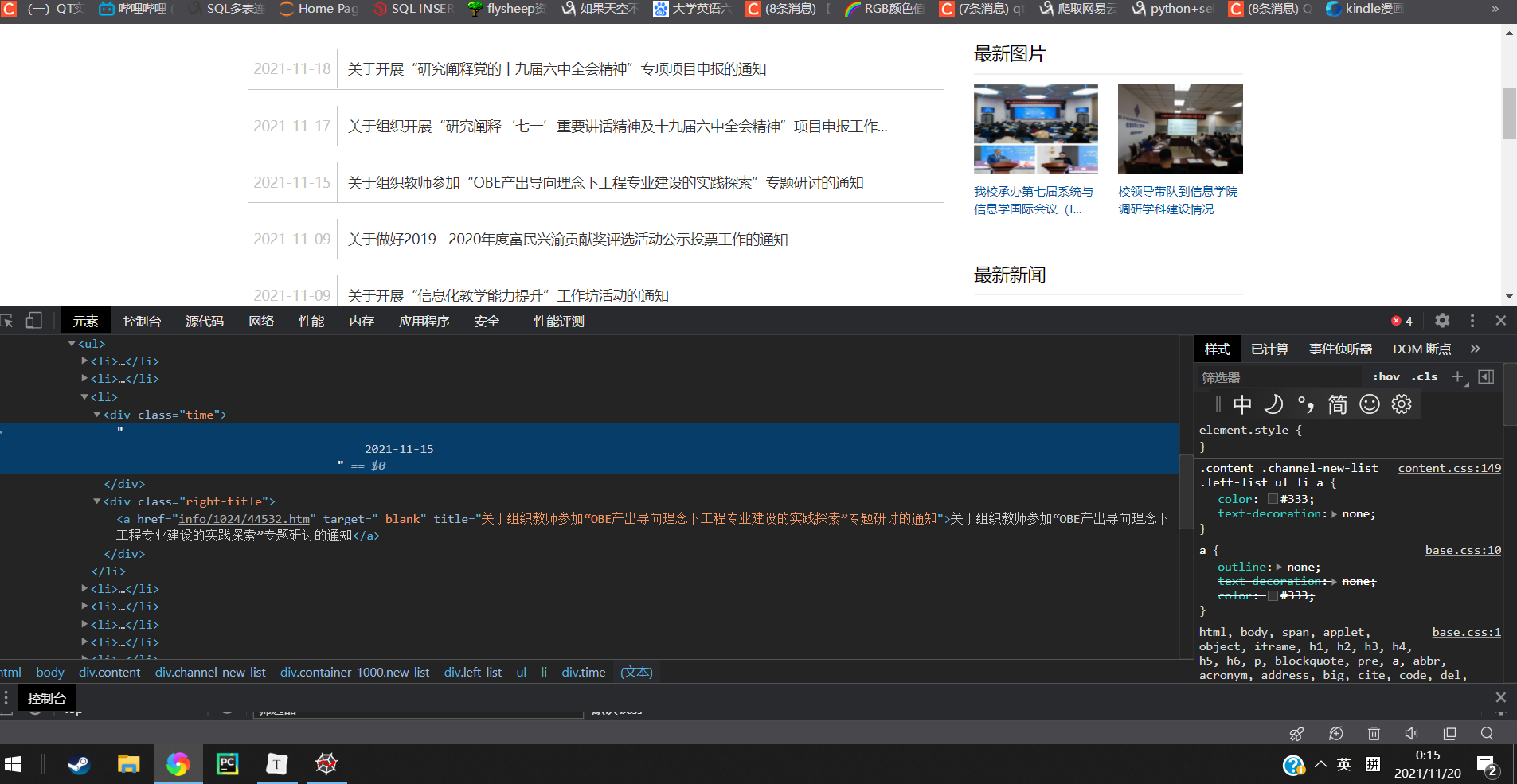
时间在class="time"的div标签之中.
再由于要爬取所有页面的信息所以要获取每个页面的url,通过观察可以发现他一共又66页,第一面url是http://news.cqjtu.edu.cn/xxtz.htm,末页url是http://news.cqjtu.edu.cn/xxtz/1.htm,每个页面的网址最后的数字可以得知是从最后一页递增到第二页
2.编写代码
1.引入相关的包
requests用于访问网页,bs4对获取到的网页进行解析,pandas用于对解析后的数据保存到一个csv文件之中
import requests
import bs4
import pandas as pd
2.构造要爬取页面的urlist列表
定义一个urlist数组加载所有的网址,并将网址顺序调整
urllist=[]
for i in range(1,66):
urllist.append('http://news.cqjtu.edu.cn/xxtz/'+str(i)+'.htm')
urllist.append("http://news.cqjtu.edu.cn/xxtz.htm")
urllist.reverse()
3.开始进行爬取
设置useragent模仿浏览器访问
user_agent = [
"user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"]
开始爬取每个网页之中的信息,根据之前的分析通过bs4模块进行解析,并且根据实际情况进行微调
for url in urllist:
respond=requests.get(url=url,headers={'User-Agent': user_agent[0]})
respond.encoding = 'UTF-8'
text=bs4.BeautifulSoup(respond.text,"html.parser")
da=[]
me=[]
for i in text.select('div[class="time"]'):
te=i.get_text().lstrip().rstrip()
da.append(te)
datee=text.select('a[target="_blank"]')
for i in range(1,len(da)+1):
stri=datee[i].get_text().rstrip().lstrip()
if stri=="百度一下":
break;
me.append(stri)
for i in range(0,len(da)):
records.append([da[i],me[i]])
4.将数组进行存储
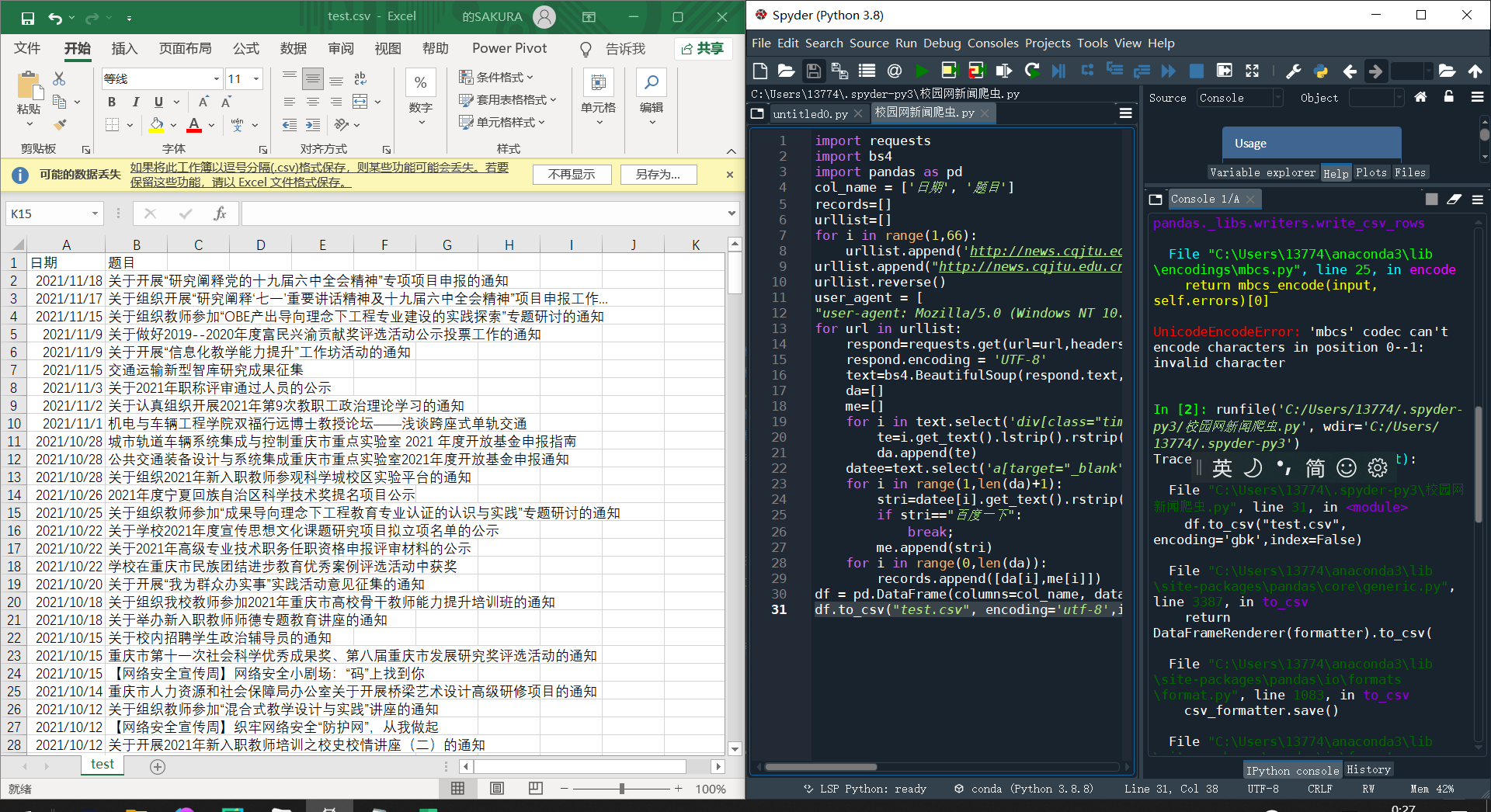
df = pd.DataFrame(columns=col_name, data=records)
df.to_csv("test.csv", encoding='utf-8',index=False)
代码运行结果如下