
论文解读《Detection of GAN-generated Fake Images over Social Networks》
Detection of GAN-generated Fake Images over Social Networks 笔记
论文题目 通过社交网络检测GAN生成的伪造图像
年份 2018
出处 IEEE Conference on Multimedia Information Processing and Retrieval (MIPS)
作者 Francesco Marra, Diego Gragnaniello, Davide Cozzolino, Luisa Verdoliva Dep. of Electrical Engineering and Information Technology University Federico II of Naples Naples, Italy
摘要
本文研究比较了一些图像篡改检测器在理想条件(未经压缩)和在图像压缩的情况下的的表现。
数据集包括36302个图像,实验结果表明,在理想条件下常规的和基于深度学习的检测器能达到95%的检测准确率。但只有基于深度学习的检测器可以在压缩数据上保持89%的准确率。
关键词
图像篡改;GAN;卷积神经网络
Ⅰ 介绍
有工作研究了人类通过观察辨别图像经过篡改的能力:
[1]只有62%~66%的图像被正确分类了,而且人类定位篡改区域的能力还要更差。[2]做了相似的研究,有58%的图像被正确分类。在合适的假设下,自动化算法的检测表现比人类要好。例如,第一届 IEEE Image Forensics Challenge,由 [3] 训练的分类器达到90%以上的检测准确率。但对于计算机生成的伪造图像而言,这种情况几乎被扭转了。[4]表明,对于这种生成图像,人类的判断优于机器学习。这可能是由于当前的计算机图形工具无法提供良好的照片级逼真的效果。
有工作研究自动化算法辨别生成图像:
[5]提出基于小波分解提取的统计量检测计算机图形图像。[7]则依赖于记录设备所产生的不同噪音检测图像,[8]依赖于色差痕迹,[9]依赖于去马赛克过滤器的痕迹。[11] 利用局部边缘斑块的统计特性进行判别.[12] 提出人脸不对称是一种区分计算机生成的人脸与自然人脸的特征。直到最近,深度学习方法[4][13][14]应用到这个任务。最近,[16]-[21]设计出了基于计算机图形的图像处理的新形式,其特征在于更高的照片写实度。本文关注图像-图像转换,这是一个通过将一个场景的一种可能表示转换成另一种表示来修改目标图像属性的过程。图1表示了图像到图像的转换,CycleGAN应用于卫星图像的例子。左边是由算法产生的图像,右边是从谷歌地图下载的图片。
本文分析了大量基于学习的检测图像-图像转换的方法。目标是了解是否可以揭露这些攻击,在何种程度上以及在什么情况下。为此,本文将基于从图像取证文献中获取的最新方法,以及针对此任务进行了适当训练的通用超深度卷积神经网络(CNN),考虑几种解决方案。本文还将研究图像上传时例行执行压缩的情况下图像篡改检测器的性能,这也是最常见最具挑战性的情况。
接下来的部分,依据18 讨论论文中图像的生成过程,列出检测使用的方法,最终讨论实验结果。
Ⅱ GAN-BASED IMAGE-TO-IMAGE TRANSLATION
图像到图像的转换,某个域的图像可映射到另一个域中的对应图像,是一个非常普遍的问题。在大多数应用中,使用大量的来自两个领域的图像对训练GAN网络。但是,在某些情况下,这些对应关系不是先验已知的,并且没有成对的图像可用于训练。 为了继续使用GAN,必须使用其他训练步骤。
因此,[18]提出的CycleGAN在没有成对的训练数据的情况下,自动创建相互映射的图像对,以弥补缺少真实图像对的不足。参考图2
使用生成器GA首先把输入图像A从原始领域DA 转换到输出领域DB 。然后生成器GB 把图像B往回映射到原始领域DA 。除了与判别器相关的常规对抗损失用来确保生成图像适合于新领域,还使用了两个周期一致性损失来确保A=GA(GB(A)),即两个图像形成对应的一对。
图4,更多示例,其中原始图像和通过上下文更改获得的新版本并排显示:不同的绘画风格(用梵高代替莫奈)或不同的季节(用冬天代替夏天)。修改图像的上下文是一个非常强大的编辑工具,这可以进行重大更改而不会导致照明、阴影或透视图不一致。普通人很难将这些假图像与原始图像区分开。因此,这种方法显然具有创建可信的假新闻的潜力,如图3。
Ⅲ DETECTORS UNDER TEST
本文对比了一些检测图像-图像转换的方法。
- [3][24][25]提出检测通用图像操作的方法
- [13]专为计算机图形图像检测而设计。
- [26]-[28]的方法基于流行的深度卷积网络结构
这些方法在ImageNet上预训练,我们微调使它检测图像-图像转换。 - 考虑了[18]的作者在其GAN体系结构中使用的完全相同的鉴别器作为基准。
GAN discriminator
把[18]中使用的判别器作为GAN的一部分。图2是其结构。判别器需要在可用的数据集上重新训练来避免偏差
Steganalysis features
隐写分析特征最初是[29]为隐写分析提出的,在[3]中成功应用到了图像篡改检测。隐写分析特征是从高通残差图像中提取的用来衡量细节微图案的共现。本文跟随[3],使用在[29]提出的表现最好的单个模型,后面是线性SVM分类器
Cozzolino2017
[24]设计了一个ad hoc CNN来提取非常类似上述特征的特征。然后移除结构约束,对网络微调来优化性能。这项技术适用于小的patch,因此本文实现了一个多数表决程序从而在更大的图像上做决定。
Bayar2016
[25]设计了一个约束CNN,其中第一个卷积层必须是一组高通滤波器。本文也在这里实施多数表决。
Rahmouni2017
[13]作者考虑了分辨真实图像和计算机生成图像的问题,比较了一些基于CNN的优化判别特征的方法。本文我们实现了性能最好的网络(Stats-2L),它由两个分别为32和64个过滤器的卷积层组成。每个第二层feature map计算4个全局统计量(mean, variance, maximum, minimum),每个patch得到256-d feature vector。采用多层感知器作为分类器,在不相交的patch上进行多数表决,给出图像级决策。
DenseNet
DenseNet是[26]基于[30]的ResNet而提出的非常深的CNN结构,是为了追求在网络内特征的有效传播和重用。对于denseNet的每一层,前面所有层的feature-map用作本层输入,而本层的feature-map用作所有后续层的输入。在输入和输出之间建立捷径,促进特征传播和重用,大大缓解了梯度消失问题。参数数量大大减少,确保了更快的训练。DenseNet和其他测试的结构一样,在imagenet上预训练,在我们的图像-图像转换数据集上微调。
InceptionNet v3
InceptionNet的核心概念是输入的多分辨率表示。第一版是[31]提出的GoogleNet,对输入图像并行使用1x1、3x3和5x5的卷积,然后拼接输出的feature-map。后来版本的[27]应用并扩展了相同的概念,结果改进了很多。
XceptionNet
[28]提出了对InceptionNet的极端的想法,采用完全可分离的过滤器。在每一层中,输入特征图的3d滤波都实现为1d深度方向卷积,然后是2d点方向卷积。这种强大的结构约束所导致的理论性能损失在很大程度上被以下事实所弥补:要学习的参数数量大大减少,从而使资源可以更有效地用于其他目的。XceptionNet是2016年google提出的,Xception: Deep Learning with Depthwise Separable Convolutions 由inception演化而来,主要采用depthwise separable convolution分离卷积核思想。
标准的卷积过程,一个2×2的卷积核在卷积时,对应图像区域中的所有通道均被同时考虑。
分离卷积是把通道和空间区域分开考虑。首先对每一个通道进行各自的卷积操作,有多少个通道就有多少个过滤器。得到新的通道feature maps之后,这时再对这批新的通道feature maps进行标准的1×1跨通道卷积操作。这种操作被称为 “DepthWise convolution”。这种操作是相当有效的,在imagenet 1000类分类任务中已经超过了InceptionV3的表现,而且也同时减少了大量的参数,我们来算一算,假设输入通道数为3,要求输出通道数为256,
两种做法:
1.直接接一个3×3×256的卷积核,参数量为:3×3×3×256 = 6,912
2.DW操作,分两步完成,参数量为:3×3×3 + 3×1×1×256 = 795,又把参数量降低到九分之一!
因此,一个depthwise操作比标准的卷积操作降低不少的参数量
参数量计算:卷积核为fxf,f x f x input channels x #filters
文中提到实施多数表决”implemented a majority voting procedure”
参考上网搜索到摩尔投票算法(Boyer-Moore majority vote algorithm)
Ⅳ EXPERIMENTAL RESULTS
数据集
本文使用在线提供的cycleGan代码 构建了一个大型图像数据集,图像-图像转换[18]中包含了不同类别的样本。每一个类别,包括真假图像。例如,apple2orange子集包括用于训练GAN的苹果和橙子的所有原始图像,以及训练后由GAN本身生成的相应假图(分别为橙子和苹果)。在图5中,显示了所有类别的示例。

使用cycleGAN训练ap2or数据集,首先有两个样本空间苹果和橘子。然后对于每一张苹果图,cycleGAN生成了对应的一张橘子图。

我觉得然后把原本的苹果图和生成的橘子图放一起,就是ap2or数据集。
作者使用cycleGAN训练出图5所列的10个数据集(作者将这10个数据集整体称为大型图像数据集)
包括apple2orange , horse2zebra , winter2summer, cityscapes , facades , map2sat等。
例如,ap2or数据集里,有两个类:真图和生成图。也就是,真苹果和假苹果(把生成的橘子看作假苹果)。
以下三个实验结果表格的每列,表示该网络结构在这个数据集上的分类准确度
这些图像可以根据其内容进一步分组。第一组是关于自然图像的翻译,包括apple2image,horse2zebra和winter2summer。第二组与从标记的城市景观图,建筑物立面图和卫星图像生成图像有关。在这种情况下,数据集中仅包括真实照片和生成的照片,而没有考虑手工标签映射(真实的和生成的)。最后一组是由真实照片生成的绘画,反之亦然。总体而言,数据集包含了超过36k 256×256彩色图像
协议
为了评估在实际操作中未知的情况下的性能,采用了leave-onemanipulation-
out(LOMO)。因此,在每次迭代中,所有引用到某个类别的图像都被用来进行验证,而其余的图像则用于训练。这样做,我们可以确保分类器不适应特定类别的转换,而是学习由这个过程生成的所有图像共享的模式,从而在不同的操作之间进行泛化。
文中提到LOMO算法:每次迭代时,取N-1个操作用于训练,剩余1 个操作用于验证,如此重复N次。类似于留一交叉验证法LOOCV-Leave-One-Out-Cross-Validation

方案1
表1,在原始数据集上训练和测试。
对于所有考虑的方法,我们展示了每种类型的操作获得的准确性,以及它们的平均值(最后一列),这些平均值由样本的数量加权。在考虑的方法中,Cozzolino2017获得了最高的平均精度。这个浅层网络为所有操作提供了近乎完美的分类,除了winter2summer,平均为95.07%的准确率。
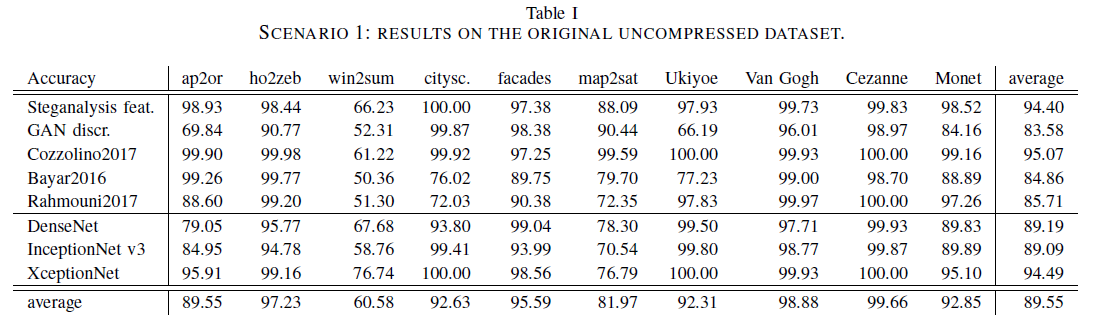
在深层网络中,手工特征[29]以及XceptionNet也提供了非常好的结果。表1最后一行是每个操作的平均分类准确度,表明最具挑战性的案例是winter2summer和map2sat。前者是一种图像-图像转换,主要是引入光照变化和颜色转换来模拟自然景观中的雪或植被,而不是大幅改变图像结构。后者以带标签的地图作为输入,从零开始生成非常类似于谷歌的卫星图像地图。这些图像看起来非常真实,并且很少包含人工痕迹。另一方面,最容易被检测到的操作是horse2zebra,以及一些绘画风格的转移。在所有这些情况下,图像中引入的新结构带来了人工痕迹,在第一种情况下这很明显。而在绘画中部分人工痕迹被良好的视觉外观所掩盖,这时,自动分类器很容易识别出假图像,而对于人类观察者则不是这样。
方案2
分类器仍在原始样本上进行训练,但在压缩样本上进行测试,如表2。
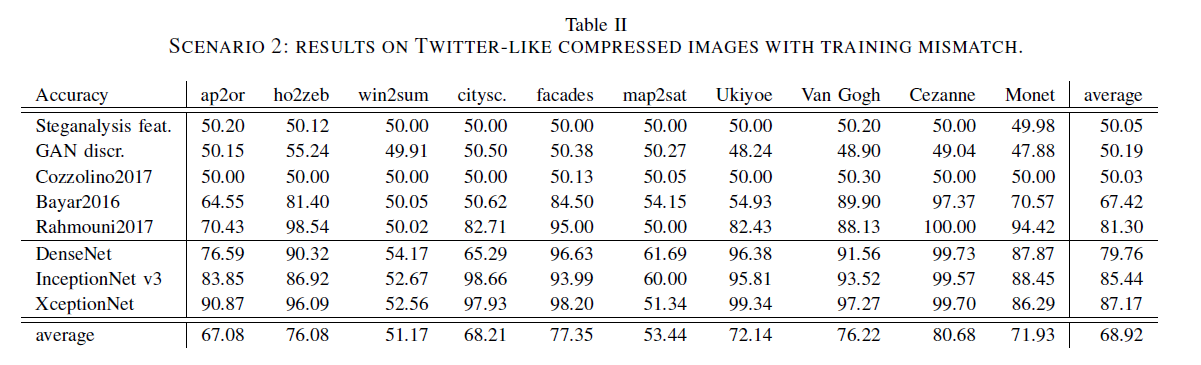
采用的压缩是Twitter-like,这意味着我们实现了相同的JPEG压缩(在量化表、色度子采样、质量因子方面)。这种简单的常规操作极大地削弱了大多数检测器的性能,特别是基于手工特征或浅神经网络的检测方法。深度网络表现出更高的鲁棒性,尤其是XceptionNet,准确率仅为87.17%比未压缩的差7%。这表明这样的网络不仅依赖于纹理微模式,还依赖于其他特征,这些特征在压缩后仍然存在。
方案3
当目标是在社交媒体上检测假图像时,直接在压缩图像上训练分类器。
在最后的实验中考虑了最坏的情况,训练和测试集不匹配。表3展示了结果。
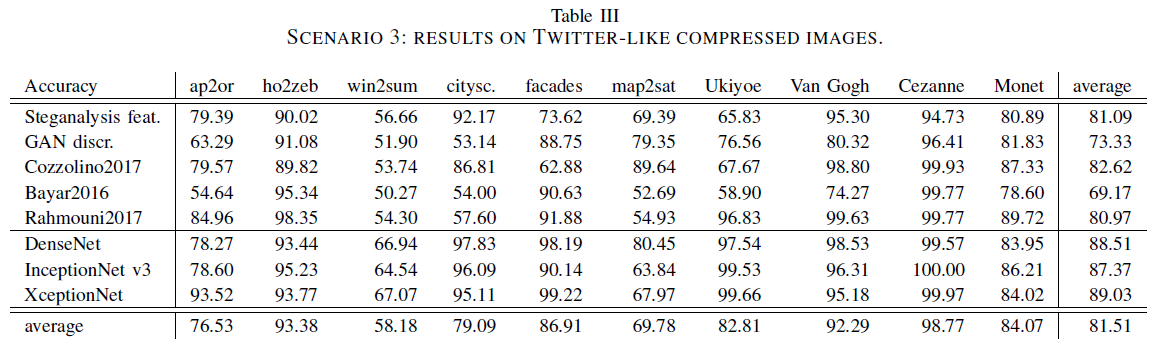
隐写分析特征和Cozzolino2017表现得很好,但比未压缩的情况低10%以上,因为一些有用的信息在有损压缩过程中丢失了,无法恢复。XceptionNet始终保持最佳性能,准确率达到89.03%。
Ⅴ CONCLUSIONS
本文研究了基于GAN图像-图像转换的检测。基于浅层网络的检测器在原始图像表现很好,但在压缩图像上表现减弱。深度网络的鲁棒性最好,尤其是XceptionNet,即使在训练-测试不匹配的情况下也能保持工作正常。
未来的研究,除了将分析扩展到更多的操作和检测器,还将研究交叉方法的性能,可能是在转移学习之后,也就是说其他合成图像生成器。此外,我们将在涉及不同社交网络的真实场景中测试性能。
参考链接
https://blog.csdn.net/dpengwang/article/details/84934197
https://blog.csdn.net/Regemc/article/details/80109596


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!