带你了解图像篡改检测的前世今生
带你了解图像篡改检测的前世今生
1 研究背景及意义
随着照相机、手机、平板电脑、摄像机等数码设备的飞速发展,数字图像生成已经变得非常容易。普通人可以随时举起手中的手机记录下身边的美好瞬间,各种各样的高清摄像机能够实时记录各种场景以及突发状况,专业人士可以通过计算机甚至AI模型来生成各种各样的图像。
此外,随着计算机和互联网的飞速发展,数字图像的存储和传递也变得非常简单。可以夸张地说,随着网络全球化的发展,数字图像等对媒体信息几乎遍布互联网和现实世界的每个角落,多媒体已经成为信息承载与共享的重要途径。
相对于以文字作为载体,通过图像传递信息更为直观,也更为可信。在过去,大家相信“眼见为实”、“有图有真相”,但随着数字媒体技术的不断发展,这种可信度也在不断被破坏。事实上,早在图像载体刚刚产生的时候,就有人通过操作技巧,将多个底片拼接为一张图片,但是这需要有特殊的设备和娴熟的技巧,这是普通人无法做到的。今天,随着多媒体采集设备的快速发展和使用,人们迎来了多媒体信息爆炸的时代,几乎人人都有能力制作、传递大量的数字图像。与此同时,Photoshop、美图秀秀、美颜相机等图像编辑软件操作简单,导致了图像修改变得越来越容易,普通人也能很轻易地对图像进行加工和修改,并且随着技术的发展,伪造图像也变得越来越不易察觉,甚至能够以假乱真。在当今社会,所谓的“眼见为实”已经变得越来越不可信,当人们面对一张图像的时候,往往首先对图像的真实性存在怀疑。日常生活中人们对图像进行修改,往往是出于美化、娱乐的目的,这并不会带来不良影响,但是在有些情况下,被恶意篡改的图像经过传播,就会影响人们对客观事物的判断,有时甚至会对社会和国家造成不良的影响,近些年,这类情况也越来越多。
历史上第一幅虚假图像出现在1860年,图1-1左图林肯的照片实际上是由右面参议员约翰·卡尔霍恩的头部替换为林肯头部得到的。
 图1-1 林肯照片的虚假图像
图1-1 林肯照片的虚假图像
2004年小布什竞选时选用的宣传图片,事实上是将小布什的照片移植到其他照片上得到的。虚假图像在选举时干扰了民众的决策,对选举的结果也造成了不小的影响。如图1-2所示。
 图1-2小布什选举虚假图像
图1-2小布什选举虚假图像
上面列举的事例从侧面也反映了图像溯源与取证的研究背景及意义。随着各类数字图像造假事件的频繁发生,使得人们对于数字图像的真实性产生了严重的怀疑。这样的行为不仅可能会对个人的声誉和利益造成巨大的影响,而且还会间接对社会的稳定与团结造成不良影响,甚至可能对国家安全造成巨大的影响,因此,一些重要的数字图像应用领域,如国家安全部门、政府部门、商业部门等应该加强图像真实性的检测,保证数字图像的真实性与原始性。
2 数字图像篡改技术介绍
随着多媒体技术和网络通信的发展,数字图像的安全隐患日益严重,由此引发的盗版问题和信息安全隐患同样已经成为社会问题。因此,对数字图像篡改的取证研究变得非常重要。要对数字图像的篡改进行取证,我们首先要了解对数字图像进行篡改的方法有哪些。周琳娜对数字图像的篡改方式进行了比较全面的总结与分类[1]。本文结合最近几年日益创新的篡改方式,将数字图像的篡改方式分为八个大类。下面分别对这八个大类篡改方式进行简单介绍。
(1) 合成 (Composited),合成操作是指把两幅不同的图片中部分区域合成到一张图片中,造成查看者错误的视觉效果。此外,合成操作还包括将同一幅图片中的一部分区域复制并粘贴到这幅图片的另外区域,以达到强调或隐藏目标物体的目的,即数字图像复制-粘贴篡改。
(2) 润饰 (Re-touched),主要是指利用图像编辑工具对图像中的内容进行美化、拉伸及磨皮等操作,从而达到隐藏图像中某些重要的细节信息或者修复某些破损图像的目的。在日益繁多的各类图像编辑工具中,Photoshop 与美图秀秀等图像编辑工具被大家所广泛使用。
(3) 计算机生成 (Computer Generated),这类图片是在专门的软件中利用计算机程序代码产生的图片。通常都是场面非常震撼,现实生活中不易存在的场景。随着科学技术的进步,计算机生成的图片已经可以达到以假乱真的程度。这也给我们平时的工作和生活带来一些麻烦,特别是一些不怀好意的人拿着计算机生成的图片来冒充真实图片,将会给社会带来一定的危害。
(4) 变种 (morphed), 是把一幅图像逐渐变化成为另外一幅图像。 主要是把一幅图像作为待变种图像,另一幅图像作为需要变成的图像。先找出两幅图像之间的特征点,然后利用不同的权重对两幅图像进行叠加得到不同的中间图像,从而得到一幅同时具有两幅图像特征的篡改图像。
(5) 增强 (enhanced),主要是通过改变图像的亮度、光线、对比度及色相等操作,以突出图像的部分区域。该方法通常情况下不会涉及到图像内容的改变,只是为了增强图像的整体可赏性。
(6) 绘画(painted),主要是利用画图软件 (例如 Photoshop与CAD 等) 或者其它画图工具绘画出来的图像。这类图像往往与现实生活中的照片有一定的差距,人眼比较容易分辨出,但也有画得比较逼真的图片。篡改者善于利用这类图片进行一些商业宣传活动,给人们的生活带来一定的困扰。
(7) 二次获取图像 (Rebroadcast),这类图像是指利用照片获取工具 (一般使用数码相机) 对需要却又很难得到的图像进行二次获取,得到新的数字图像。由于当今社会的科学技术越来越发达,数码相机的拍摄质量日益提高。经过二次获取的图像很容易骗过人们的眼睛,被不法分子用来做不正当的事情。
(8) 携密图像 (stego image), 是把需要传递或者需要隐藏的图像或文字隐藏在一幅载体图像当中,传输者或者目击者无法通过载体图像本身来判断其有没隐藏除图像本身以外其它的信息,从而达到安全传输秘密信息的目的。
3 数字图像取证技术介绍
数字图像篡改的取证技术主要是通过分析数字图像的特征来对图像进行真实性、完整性以及其来源进行鉴别。换句话说,数字图像篡改的取证技术主要是判断图像从成像设备产生之后,其内容是否真实,图像是否经过了篡改,是从哪种设备产生的等。
根据对已有的部分成果进行分析可知,数字图像篡改的取证技术主要分为主动取证技术和被动取证技术,具体分类如图 3-1 所示。
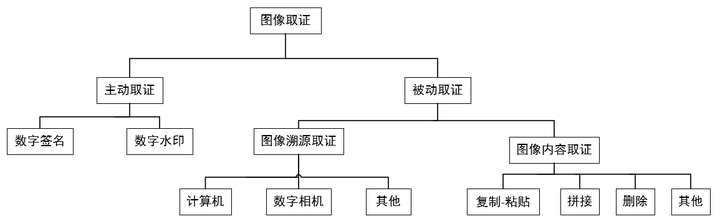 图3-1 图像取证技术分类
图3-1 图像取证技术分类
图像取证方法主要分为主动取证和被动取证。主动取证方法主要包含数字签名、数字水印等需要事先在图像中嵌入验证信息,然后再进行信息提取验证的相关技术手段。相对于主动取证,被动取证的应用范围更为广泛,可以直接通过图像去进行图像来源、完整性的判断。根据取证的目的不同,又可以分为图像溯源取证和图像内容取证。图像溯源取证即寻找图像的来源,图像内容取证则是需要判断图像的内容是否经过修改。接下来本文将对图像取证的分类和方式进行详细介绍。
3.1数字图像主动取证技术
图像主动取证的主要特点是需要事先在图像中嵌入秘密信息[2],接收者收到图像之后再提取水印或者数字签名,通过判断水印或签名的情况来判断图像是否已经被篡改过。
(1) 数字水印
1994年,Schyndel首次定义了“数字水印”的概念,并提出了在图像中嵌入人言不可见的加密信息技术。
这种方法需要事先向图像嵌入一些数字水印,或者使用可以添加水印的成像设备来产生带水印的图像。数字水印主要包含两个部分:水印嵌入模块、水印提取验证模块。如图3-2所示:
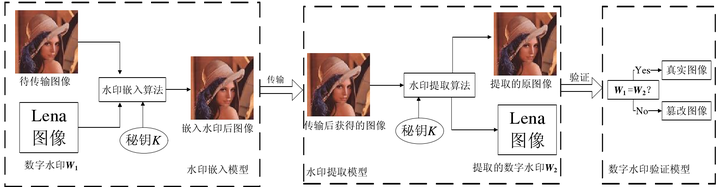 图3-2 数字水印主动取证算法流程[3]
图3-2 数字水印主动取证算法流程[3]
基于空间域的数字水印技术通过水印嵌入算法和密钥K直接将某数字水印W1嵌入到图像中,人眼往往无法直接观测到数字水印的存在。经过传输后,根据水印提取算法密钥K提取出完成的数字水印,通过验证水印的完整性从而判断图像的原始性。
(2) 数字签名
数字签名技术原理与数字水印技术类似,基于数字签名的图像主动取证技术将图像和其摘要加密形成的数字签名进行合并。当验证图像的真实性时,从图像中提取摘要,并生成数字签名,通过对比数字签名判断图像是否经过篡改。具体流程如图3-3所示:
 图3-3 数字签名主动取证算法流程[3]
图3-3 数字签名主动取证算法流程[3]
然而在实际应用中,由于各种原因有可能不能及时地对图像嵌入水印而影响图像的使用。另外,可以自动添加水印的成像设备价格昂贵,绝大多数生活中所使用的成像设备都不具备自动添加水印这一功能。这就使得数字图像主动取证技术的应用范围不够广阔。与之相对应的是数字图像被动取证技术,该技术只依赖于待取证图像本身的特征,不需要其它任何信息。这一特点使得被动取证技术的应用范围更加广阔,实用性更强。因此,数字图像篡改的被动取证技术成为了目前国内外极具研究价值的一个研究方向。
3.2 数字图像被动取证技术
数字水印和签名都有局限性,只有当图像中包含水印或者签名时,这些检测技术才有效。这给图像取证技术带来了限制,因为大多数情况都要求在没有水印或签名的情况下对图像进行检测。图像被动取证又称为数字图像被动取证(Blind Forensics),其中的“盲”就是指可以直接从没有事先嵌入数字水印或签名的图像进行取证,与主动取证相比,适用面更宽。被动取证技术主要包含图像溯源取证、图像内容取证(篡改鉴定)。
3.2.1图像来源被动取证
图像来源被动取证指的是识别未知图像的获取设备,不同的品牌和型号的设备具有特定的成像属性,即是设备的类型、品牌和型号完全相同,不同设备的个体差异也会导致不同图像具有不同的属性,主要方法分为以下几种:
(1)模式噪声估计算法
图像采集过程中,设备不可避免地要引入模式噪声,这是不同设备的特有属性,即使两个型号完全相同的设备,其模式噪声也会有所不同。模式噪声估计算法需要事先建立训练集,将已知相同型号的设备作为一类,利用去噪算法过滤出图像的“残余噪声”作为这一类图像的参考噪声。然后对比待检测图像的残余噪声和训练集中的各类参考噪声,从而确定设备的型号。Lukas[4]等人最早提出了模式噪声方法来识别图像的来源,文中对9种不同的设备进行了来源识别,识别率达到了100%
(2)CFA差值算法
彩色图像设备成像过程中,通常只采集RGB三色通道中的其中一种颜色信息,然后再利用CFA(color filter array)插值获取其他两种颜色。通过此种方法形成的图像,其RGB三色通道之间往往存在一定的相关性,不同的设备使用的插值算法和模型也不同,CFA插值算法就是利用了这个特性判断图像的来源。Swaminathan等人[5, 6]就是采用了这种方法,然后利用SVM对19种不同设备产生的图像进行分类,准确率可以达到85%
(3)光学镜头失真算法
设备在进行图像采集时,光学镜头的失真会最终引入到生成的图像中,给图像带来几何特性的变化。不同的设备带来的几何变化不同,光学镜头失真算法就是用了设备成像的这种特性进行图像来源分类。San Choi K [7]等人就是通过提取图像中的直线失真对图像的来源进行鉴别,通过对三种设备图像进行分类,准确率可以达到92%。但当图像中不存在参考直线时,这种方法会完全失效,存在一定的局限性。
(4)JPEG量化表算法
当前绝大多数图像都是JPEG格式,不同品牌的设备采用的JPEG量化表不同,可以通过量化表来对图像的来源进行鉴别,但该方法只能判断图像的大致范围,无法准确确定成像设备的具体型号。
(5)自然图像和计算机图形的鉴别
自然图像的成像过程非常复杂,但计算机生成的图像在图像的统计特性上会有很大的差异。当前人工智能生成图像(AI)大行其道,出色的图像生成算法使得伪造图像真假难辨,只有在图像的细小纹理、光照、直方图连续性等统计学数据上存在差异。当前的鉴别方法有:基于成像设备的方法[8, 9],基于几何特征的方法[10]和基于统计特征的方法[11, 12]。
3.2.2图像内容被动取证
图像篡改方法种类繁多,方法大致分类两类,一类是基于传统方法的图像被动取证,另一类是基于深度学习方法的图像被动取证。传统方法目前没有出现一种方法可以应对所有的图像篡改技术,大多只能针对一类图像篡改方法。当前,深度学习技术在计算机视觉领域有了很大的进展,近几年部分研究者试图通过深度学习方法进行图像的被动取证,在多种类篡改技术的识别方面取得了不错的效果,为通用图像被动取证方法带来了曙光。图像篡改被动取证的分类如图4所示。
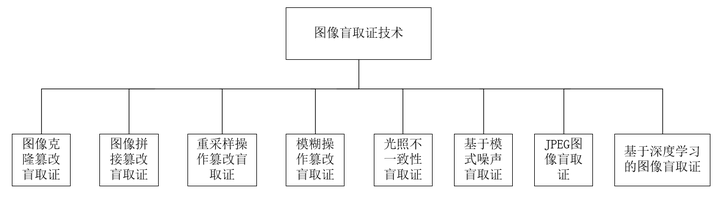 图3-4 图像被动取证技术分类
图3-4 图像被动取证技术分类
(1)图像克隆被动取证
这种方法针对的是同一张图像本身的复制粘贴篡改方法。由于图像采集的多样性,同一张图像中的噪声、纹理完全相同的区域几乎不可能出现,而图像克隆篡改方法将导致图像中出现了两个完全相同的区域,因此该类取证方法的关键在于寻找图像中两个完全相同的区域。
(2)图像拼接被动取证
这种方法针对的是不同图像的复制-粘贴篡改方法,该方法产生的篡改图像其统计特性会发生改变,并且边缘特征也会发生变化。通过滤波器对图像进行处理,凸显图像边缘特征,从而发现真实区域与篡改区域之间的边缘差异。
(3)重采样被动取证
一般对图像进行克隆或拼接等篡改操作以后,伪造者会对合成区域进行缩放、旋转,使其尺寸或者形态更符合视觉感受。对图像尺寸的缩放即重采样,通常采用插值算法来增加(上采样)或减少(下采样)图像像素,这就会改变图像原有的统计特性。目前关于重采样的被动取证可分为两类:一类是根据像素相关性进行检测,另一类方法是根据插值区域像素的二阶导数进行检测。
(4)模糊被动取证
模糊是图像篡改中一种常见的润饰方式,能使篡改区域边缘更加自然,在视觉上不引起人注意。当前针对模糊操作的取证方式一般是根据图像模糊操作滤波器的特性来进行判断。不同模糊方法其像素值之间往往有迹可循,根据这些规律,可以判断出图像是否采用了模糊操作以及模糊操作的具体方法。
(5)光照不一致性被动取证
在同一地点的不同时间点,相机拍摄的物体所受光线的角度不同。基于光照不一致性的被动取证依据的是:随机选取的两张图像中物体所受光照不同,在进行合成时,篡改区域和背景区域很难达到光照一致的效果。目前关于光照不一致性被动取证一般分类两类:一类是通过分析图像中的光源位置,判定图像光源是否一致;另一类是寻找图像中的阴影,判断阴影几何形状是否满足图像中的几何特性。
(6)基于模式噪声被动取证
图像内容篡改中的基于模式噪声被动取证和图像来源被动取证中的方法不同,它的目的是检测同一幅图像中模式噪声不一致的区域。人们在篡改图像时,往往只关注图像的RGB域而忽略了图像的噪声域,不同图像的噪声域不同,根据这一点可以判断出图像是否经过篡改操作。
(7)面向JPEG图像篡改的被动取证
JPEG是当前主流的图像压缩标准,现在的数码相机大都支持输出JPEG图像,而网络上的图片多数也是JPEG格式,所以针对JPEG格式图像的取证非常有意义。但是JPEG压缩是有损的,图像的信息会丢失,给取证带来难度。针对篡改手段和检测依据的不同,目前方法大致分为两种:双JPEG压缩检测和块效应不一致性检测。
(8) 基于深度学习的图像被动取证
随着深度学习技术在各种计算机视觉和图像处理任务中的成功应用,最新的一些技术也采用了深度学习方法来进行图像修改识别。深度学习方法可以将图像被动取证看作目标检测问题、异常检测问题。早期的深度学习图像取证方法通过将传统滤波方法与深度学习模型结合,取得了不错的效果。近几年,更多学者希望能够利用深度学习方法的自适应性,使深度学习模型能够自动提取有效的特征,但受限于数据集太小以及篡改方法多样,这仍是深度学习方法在图像被动取证领域中的一大挑战。
当前的图像篡改大多都是对图像内容进行修改,如拼接、复制-粘贴、移除等,如JPEG压缩、模糊、图像增强等篡改方法往往被用来掩盖图像内容刚修改痕迹,本文接下来将对图像内容篡改取证技术进行详述,分为传统方法和基于深度学习方法两类。
4 传统图像被动取证
传统图像内容被动取证方法首先通过手工设计特征的方式进行特征提取,然后对该特征进行对比分析或者对图像统计特性进行分析,从而找出篡改区域,判定篡改技术种类。根据图像内容被动取证采用的不同类型特征,传统图像内容被动取证技术可以分为以下三类:基于篡改痕迹检测,基于成像设备固有属性一致性,基于图像内在统计特征[13]。
4.1 基于篡改痕迹检测的图像被动取证
图像篡改方式大致可以分为两类:拼接、复制-粘贴、删除三种操作是对图像内容进行修改,这类修改方式给人的误导性较大,也是最为常见的三种篡改方式;其余的修改方式如模糊、压缩、增强、放缩、滤波等操作没有对图像的内容进行修改,绝大多数是为了掩盖图像的篡改痕迹进行的后处理操作,危害性较小。基于篡改痕迹检测的图像内容被动取证则是期望通过某种方法检测出图像修改的某些蛛丝马迹,从而判断出图像修改的位置和修改种类。
Fridrich等人[14]在2003年提出了一种对图像进行块分割的方法来进行图像复制-粘贴被动取证,成为传统图像块检测的经典算法。他们首先将图像分割成16*16大小的重叠图像块,以图像块为单位提取特征。通过计算图像块之间的离散余弦变换(Discrete Cosine Transform)特征系数,组成特征向量,最后基于字典排序检测算法对所有特征向量进行排序,字典中位置相近的两个块就是复制-粘贴的源区域和篡改区域。之后产生的传统的基于图像块的图像克隆被动取证方法大多是对[14]改进,如AC.Popescu和H.Farid[15]在2004年提出使用主成分分析法(PCA)代替了DCT,获得了更小的特征系数,提升了图像块特征向量匹配的效率。基于图像块匹配技术的取证方法一般遵循以下流程,如图4-1所示。
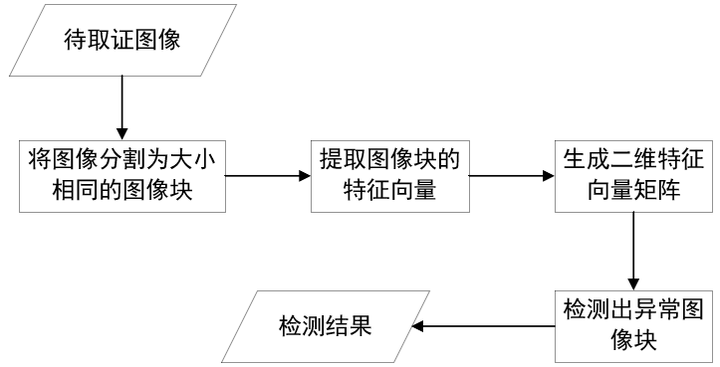 图4-1 基于图像块匹配的克隆图像被动取证技术流程图[13]
图4-1 基于图像块匹配的克隆图像被动取证技术流程图[13]
随着模式识别领域的快速发展,也有学者利用了图像的局部不变性技术进行图像取证,例如:尺度不变特征变换(Scale-Invariant Feature Transform)技术[16],加速鲁棒性特征(Speeded-Up Robust Features)技术[17]等等。这类技术有着强大的物体识别能力,即使物体进行了多种几何变形操作,也仍可以识别出相似物体。因此这类方法非常适合检测图像中被复制-粘贴的部分,取得了良好的效果。Amerini等人[18]和Pan等人[19]分别利用了SIFT特征进行图像复制-粘贴被动取证,在这类方法中,首先提取SIFT特征值,对SIFT特征进行匹配,当相似的SIFT特征值积累到达一定阈值时,判定该图像经过了篡改操作。在实验中,这类算法可以对加入噪声和经过压缩的图像进行鉴别,具有良好的鲁棒性。
篡改后的图像需要经过重新保存,若原图像为JPEG格式,经过修改后,图像再次保存为JPEG格式的话,图像本身会经过两次JPEG压缩过程。这是一种不可逆的双重有损压缩过程。经过双重压缩的图像在图像直方图的DCT变换系数中会呈现出一种周期性的规律,而重采样本身也会破坏一些图像的内在特性。Farid等人[20]提出了利用量化DCT系数直方图的判断图像是否经过重采样压缩,然后采用E/M(Expectation/Maximization)算法计算临近像素线性组合的概率,从而得到检测图像重采样的方法。该方法可以判断图像是否经过重采样操作,也可以定位篡改区域。但该方法只对图像部分篡改区域有效,对于全局篡改的方式不适用。J. Lukas[21]通过研究双重压缩检测的特性,从JPEG双重压缩图像中估计出原始量化表,通过量化表的对比来进行图像取证。AC. Popescu [22]则利用双重JPEG压缩为图像直方图带来的周期性规律来鉴别图像的真伪。
4.2 基于成像设备固有属性一致性被动取证
自然图像一般是由数字采集设备获取的,如数码相机、摄像机、手机等。不同的采集设备具有不同的特性,如使用的颜色滤波阵列CFA(Color Filter Array)不同,JPEG量化表不同,镜头光学畸变不同等。由相同的设备采集的图像通常在某些特性具有一致性,这种一致性可以反映出该设备的特性,可以用于图像被动取证。
Farid[23]使用了一个包含百万张图片的数据库,通过对其中图像分析,可以得出不同采集设备所使用的JPEG量化表几乎不同的结果,因此JPEG量化表通常用来鉴定图像的来源。
不同成像设备采取的颜色滤波阵列CFA往往存在差异,通过对比分析CFA插值的相关性判断图像真伪一直是图像取证的研究热点。AC.Popescu和H.Farid[24]对CFA插值带来的特殊相关系数进行量化,提出了一种能够自动在图像人一部分检测这种相关系数的方法,从而可以判断图像的篡改区域,鉴别图像的真伪。
相机在拍摄图像的过程中,通常会附加该相机特有的模式噪声,模式噪声包含固定模式噪声FPN(Fix Pattern Noise)和图像响应非一致PRNU噪声。根据噪声的特异性,诸多学者进行了广泛的研究。Lukas等人[25]首先利用去噪算法滤出整张图"残余噪声"作为参考模式噪声,然后比对图像块的残余噪声和参考模式噪声,篡改块会出现异常。Chen等人[26]中指出数码相机在拍摄过程中会给图像带来随机性的噪声点.而篡改区域可能来自不同图像,噪声分布不一致,以此来鉴别篡改区域。但是这些方法有缺陷:(1)参考模式噪声的估计通常需要一定数量的、来自于同一个相机的图片样本;(2)裁剪、缩放等图像处理操作也会破坏图像模式噪声的一致性,使算法的误检率增加:(3)算法不能判断模式噪声存在性低的区域,比如饱和区域。
4.3 基于图像内在统计特征被动取证
未经篡改的真实图像通常在内在统计特征上具有连续性和完整性,而经过篡改的图像这些连续性则会被破坏。因此通过分析原始图像和篡改图像在这些统计性的内在特征(如像素平均值、RGB相关性、小波域统计特征等)上的区别,就可以对图像的真伪作出判断。这种方法一般都是通过手工设计某种统计特征,将提取的特征进行量化描述后,采用机器学习的相关方法(如SVM)进行分类训练,最后通过训练好的分类器进行判定。
Farid等人[27]采用多尺度小波分解的方法,对包含数码相片、扫描图像和计算机生成图像在内的图像进行高阶统计建模。通过得到的诸多统计特征,对分类机进行训练,完成了基于机器学习的图像取证过程。在实验中,他们测试了46000幅图像,在虚警率为0.8%的条件下,篡改检测的准确率仅为65%左右。
在图像内容的篡改过程中,往往会产生大量的非线性、不稳定的特性。Shi等人[28]提出图像的拼接过程会产生大量复杂异常的局部操作。他们通过多尺度离散余弦变换(MBDCT)和马尔科夫(Markov)模型来捕捉这些局部异常特征,然后将Markov模型的转移概率矩和MBDCT低阶矩输入SVM进行图像分类。
4.4 总结
图像篡改方法种类繁多,篡改技术进步也十分迅速,研究者将篡改技术分为合成、润饰、计算机生成、变种、增强、绘画、二次获取图像、泄密图像八个大类。[1]其中,合成、计算机生成、变种、绘画是对图像的内容进行篡改,而润饰、增强、二次获取图像则通常被用来掩盖图像的篡改痕迹。
面对数量庞大,流程复杂的篡改技术,图像的被动取证面临巨大的困难。如何对图像真伪进行判定,如何判定图像篡改技术种类和篡改区域是研究者一直思考的问题。通过分析,研究者们发现不同类型的篡改方式会产生独特的特征和篡改痕迹,根据不同类型的篡改特征,可以对某一种篡改方式进行鉴定,因此产生了大量的图像特征提取方法和图像被动取证方法。截至目前,根据提取的特征种类不同,这些方法可以大致分为三类:基于篡改痕迹检测,基于成像设备固有属性一致性,基于图像内在统计特征。[13]
基于篡改痕迹检测方法大多是在图像块级别进行篡改检测,具有很好的鲁棒性,可以对加入了噪声和经过压缩的图像进行判定。这类方法通过提取图像块的特征(如DCT、PCA、SVD),比较不同块之间的特征相似度判定图像的真实性和篡改区域。
基于成像设备固有属性一致性方法从成像设备入手,比对不同图像的固有属性(如CFA特性、JPEG量表等),当统一图像中出现两种不同的特性时判定图像为假。这类方法通常被用来进行图像溯源取证,在图像内容真实性方面,表现不如基于篡改痕迹检测方法。
基于图像内在统计特征的方法经常与机器学习方法结合,首先提取图像内在统计特性(如像素均值、RGB相关性等),将这些特征输入到SVM分类器中,分类器对这些特征进行分类,得到图像的判定结果。但由于手工设计的特征不具备代表性,分类器表现一般,因此准确率较低。
这三类方法不是相互独立的,可以相互交叉使用,比如基于篡改痕迹检测方法中大多采用图像块的方式,而基于成像设备固有属性一致性和基于图像内在统计特征也可以在图像块的级别上进行检测。
但传统的图像被动取证方式仍然存在缺陷,这些图像取证方法通常都是采用手工设计的方式提取特征,这种基于手工设计的特征大多存在局限性,缺乏代表性,无法根据这些特征同时对多种篡改方式进行判定,这也就导致了图像被动取证方法仅仅具有对一种篡改技术的鉴别能力。
5 深度学习图像内容被动取证
2012年AlexNet横空出世,Alex Krizhevsky等人首次将深度学习技术应用于图像分类领域[29],凭借84.6%的准确率一举拿下当年ILSVRC的冠军。随后,深度学习在计算机视觉方面不断取得突破,目标检测、语义分割、姿态识别、图像修复等领域不断涌现新的模型[30-33],识别精度也在不断提升。
随着深度学习在计算机视觉领域的成功应用,自2016年起,越来越多的研究人员试图将深度学习方法应用到图像取证领域中[34-36]。但与常规计算机视觉领域的任务相比又有很大区别:
1)识别目标不是语义内容区域,而且篡改区域
不管是目标检测还是语音分割,深度学习模型都是对图像中的语义内容进行识别,如人、动物、车辆等,而图像被动取证领域需要模型识别的是图像的篡改区域。这与语义内容有很大区别,篡改区域也许是图像的某个语义级别的目标,也有可能是一个不规则的区域,甚至是一个已经被移除的区域。
2)特征不同
常规计算机视觉任务关注的是图像的语义内容,无需关注图像的内容间细微变化,但图像被动取证任务与其恰恰相反。图像被动取证任务需要关注的是篡改边界细微的变化,根据边界伪影和统计特征的变化,从而判断出图像的真假。当前图像内容篡改方式主要有拼接、复制-粘贴、移除三种,但这三种篡改方式所具备的特征具有很大的差异。比如拼接图像真假区域具有不同图像的统计特征,但复制-粘贴与拼接不同,复制-粘贴是同一张图像的内部篡改操作,因此真实区域与篡改区域具备的统计特征十分相近,识别拼接区域的特征在这里无法使用。
3)图像后处理对识别精度的影响不同
常规计算机视觉任务关注的是图像的语义内容,正常的图像压缩不会对模型的精度产生较大的影响,但图像被动取证任务恰恰相反。由于图像被动取证需要关注的是边界处细微的特征变化,图像后处理技术,如模糊、压缩等操作对图像的篡改线索损害极大,经过处理之后的图像,其边界细微的变化会大大减少,甚至消失。因此,如何克服图像后处理操作对模型识别准确性的影响,也是需要研究的问题之一。
虽然深度学习方法在图像取证领域具有其特殊性,但这并不影响其应用前景。以上问题产生的根源在于篡改图像特征的提取,其关键是避免提取图像语义特征,为此研究者们提出了多种方法:
1)基于图像块的方法
为了避免提取图像语义特征,研究者们从传统图像取证方法中受到启发,采用图像块级别提取特征的方法[36]。在提取特征之前,首先将图像分割成大小相同的图像块,然后再逐一提取图像块的篡改特征(如手工设计特征、图像统计特征等)。通过将图像分割为图像块,避免了单一图像块中有完整的语义主体,同时对图像块的处理也提升了模型的效率。但随着人们对模型识别精度的要求不断提升,基于图像块的方法定位较为粗糙,倘若将图像分割为更小的图像块,又将会导致计算成本提升。为了解决这个问题,Bappy,等人[37]提出了一种基于像素级别概率映射的方法,建立了图像块级别与像素级别的映射关系。作者建立了CNN-LSTM图像被动取证模型,首先通过卷积操作提取重叠图像块的特征,然后采用LSTM网络捕捉不同图像块像素之间上下文依赖关系,计算像素级别的篡改概率映射,最终输出像素级别的修改区域掩码(mask)。
2)基于手工设计特征的方法
受到传统图像被动取证技术的启发,部分研究者抛弃了图像的RGB域语义特征,而是继续沿用传统图像取证方法的手工特征(如重采样特征、SIFT特征、CFA不一致特征等)。其中,空域隐富模型(Spatial Rich Model)[38]在隐写分析领域取得了良好的效果,由于隐写分析与图像内容被动取证有很强的相似性,因此SRM被广泛应用于图像被动取证。
隐写分析(Steg analysis) 是指在已知或未知嵌入算法的情况下,从观察到的数据检测判断其中是否存在秘密信息,分析数据量的大小和数据嵌入的位置,并最终破解嵌入内容的过程[38]。与图像内容被动取证方法相似,隐写分析也需要在屏蔽图像语义特征的条件下寻找图像边缘处隐藏的异常。2012年Fridrich[38]提出了空域隐富模型的方法对图像进行隐写分析。值得注意的是,Fridrich设计了丰富多样的空域高通滤波器,使用这些滤波器对图像滤波可以得到丰富多样的残差图像。这些残差图像屏蔽了原始图像RGB域语义特征,较好的保留了图像边缘特征,很适合用于图像内容被动取证[36, 39]。
基于手工设计特征的方法通常需要进行图像预处理,提取图像在其他域(如频域、噪声域等)的特征,达到屏蔽图像内容的效果。这类方法可以在整个图像级别进行特征提取,也可以在图像块级别进行特征提取,但手工设计的特征通常只能识别一种操作类型,识别的过程也大多基于前提假设来进行,因此在适用范围上存在一定局限。
3)基于约束卷积层的方法
基于图像块的方法和基于手工设计特征的方法往往都需要进行前提假设,根据已有假设再设计手工特征,但这种方式通常只能进行某一种篡改方式的识别。因此,如何提取是通用图像修改特征是图像被动取证的一个关键点。
2017年Bayar等人[40] 发现CNN可用于执行通用图像操作检测和相机模型识别,但图像取证与目标识别相比是根本不同的问题,要使用CNN学习图像取证功能,我们首先需要抑制图像的内容,否则,它将导致识别与训练图像相关联的对象和场景的分类。
2018年Bayar等人[41]在之前研究的基础上提出了一种约束卷积层的方式,可以抑制图像内容对篡改痕迹的影响,自适应提取图像的篡改特征。作者对约束卷积层的卷积核做出了限定:卷积核中心权值被设置为1,其余权值之和限定为-1,其公式表示如下:
这种限定使网络自适应学习到一个类似高通滤波器的卷积核。该模型对中值滤波、高斯滤波、重采样、高斯白噪声等检测效果比较好,不过没有考虑抗压缩等鲁棒性问题。
总的来说,基于深度学习的图像内容被动取证主要有以下两个任务:
1)篡改技术识别
需要对图像内容的篡改方式进行识别,主要包含拼接、复制-粘贴、移除三种篡改技术。
2)篡改区域定位
需要对虚假图像中的篡改区域进行定位,输出内容有两种方式,一种是以bounding box的方式输出,另一种是以篡改区域二进制掩码(mask)的方式输出。
2006年至今出现了很多基于深度学习的图像被动取证方法,由于不同篡改手段所具备的特征具有很大差异,大多数模型只能对一种篡改方式进行识别,少数模型可以实现多种篡改方式的识别。本文接下来将按照拼接检测、复制-粘贴检测、计算机生成检测、多种操作检测四类进行详述。
5.1 图像拼接检测
5.1.1 单一篡改图像检测
图像拼接操作是指将供体图像中的某部分拼接到源图像中,生成新的篡改图像。这种篡改方式对修改了图像的内容,是当前比较常见的篡改方式。图像拼接检测相对于其他图像内容篡改方式检测较为简单,因为不同图像具有不同的特征信息,拼接区域与真实区域之间通常对比较为明显,能够利用的特征也相对较多。因此这也是深度学习技术在图像被动取证领域解决的第一个问题。
2016年Ying Zhang等人[42]首次将深度学习技术应用于图像被动取证,提出了一种图像块级别的基于Daubechies小波特征的深度学习图像取证方法,成功完成图像拼接检测。作者首先将图像转换至YCrCb颜色空间,因为相对于RGB颜色空间,YCrCb颜色空间对篡改伪像更敏感。 然后,作者将图像分割成32*32个图像块,逐块进行Daubechies小波特征提取。最终将生成的图像块特征输入一个五层的神经网络进行图像真假二分类,完成了图像块的判定。该方法首次将深度学习技术应用于图像内容篡改检测,但由于模型仅仅在patch级别进行了真假判定,因此篡改区域定位比较粗糙,识别精度较低。
J Long等人[43]在2015年提出了全卷积网络用于语义分割任务,实现了像素级别的分类。受此启发,2017年Salloum等人[44]对J Long等人[43]提出的网络结构稍作修改,提出了一种基于边缘强化的多任务图像被动取证框架(MFCN),用于像素级别的篡改区域分割。文章中,作者直接将原始图像输入到网络中,通过VGG-16[45]提取图像篡改特征,随后全卷积部分,模型分为两个分支,一支用来预测图像篡改区域,另一支用来预测篡改区域边缘,最后利用篡改区域边缘掩码来对篡改区域掩码进行进一步修正。该模型进行了端到端训练,强迫VGG-16网络识别拼接图像中的篡改痕迹,实现了图像篡改特征的自适应提取,框架结构如5-1所示。实验表明,该框架在CASIA v1.0、Columbia、NIST 2016、Carvalho数据集上均超越了传统拼接检测方法。同时,该方法还具有良好的鲁棒性,在分别进行JPEG压缩、高斯白噪声、模糊等数据集加强操作后,在没有大幅损失精度的情况下,仍可以对图像篡改区域进行检测。
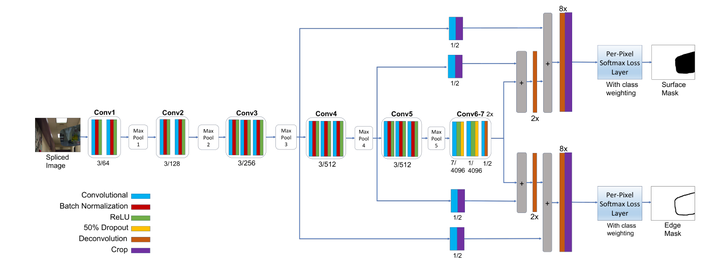 图5-1 MFCN框架结构[44]
图5-1 MFCN框架结构[44]
由于FCN框架中存在平滑操作,导致框架常常会忽略一些细小物体,这个问题在MFCN中同样存在。因此Chen等人[46]创新性地融入了Faster R-CNN[30]中的区域推荐网络(RPN)结构。同时,为了在篡改区域边缘获得更精细的结果,作者引入了不同大小的上采样率,以获得互补的篡改区域掩码。实验表明,引入RPN部件可以提升模型在细小物体上的识别率。同时,由于RPN本身也是一个全卷积网络,因此整个模型仍可以端到端进行训练。
由于篡改区域大小各不相同,大部分框架通常只能对有限大小的篡改区域进行定位。为了解决这个问题,2018年 Yaqi Liu等人[47]提出了一种基于多尺度方法进行篡改区域定位的框架。该模型创新性地引入了多尺度的思想,设计不同尺度的图像滑动窗口,提取多尺度图像块特征。模型首先经过SRM高通滤波器进行预处理,然后不同尺度的图像滑动窗口从预处理后的图像提取特征进行预测,生成与图像大小相同的多个篡改区域掩码(mask)。由于采用多尺度特征提取方法,不同掩码图像所关注的图像范围不同,将这些多尺度掩码图像合并为一张图像,生成最终的掩码。
Bo Liu 等人[48]提出了一种多种基础网络融合的方法,利用不同种类的基础网络互补,用来提升模型的鲁棒性,从而提升模型的识别准确率。该模型主要包含多个基础网络和分类器两部分。不同的基础网络在不同的数据集上单独进行训练。文章中,作者选择了两种不同的篡改特征:源图像与供体图像噪声不同,源图像与供体图像JPEG压缩量表不同。两种基础网络在对图像块进行分类,产生多种分类结果,最终统一输入到全连接层中进行融合分类。虽然该模型相对于传统方法取得了不错的效果,但是模型的鲁棒性源于多种基础网络的堆积,是以提升模型复杂度为代价的,局限性较强。
数据集数量太小一直是图像内容被动取证领域的一个难题。Minyoung Huh等人[49]创新性地将自监督方法应用于图像内容被动取证问题中,这种基于我监督方法的图像篡改取证有希望达到监督学习无法实现的检测效果。该模型以JPEG中的EXIF元数据为特征,迫使深度学习模型学习不同图像块(来自不同的源图像)EXIF元数据之间的差异,根据不同图像块之间的相似性预测,归纳出基于83种像素级别的特征相似性概率映射,最后采用Mean shift方法对概率映射map进行合并,输出最终的篡改区域掩码,该模型骨干网络如图5-2所示。作者在文章最后提到,虽然该方法在多个数据集上取得了最好的效果,但与传统方法相比,这种基于自监督学习方法的模型缺乏可解释性,尤其是我们无法确定解决该问题的具体视觉线索,同时基于对抗机器学习工作表明,在循环中使用自学习篡改技术将使伪造检测问题更难以解决,并且需要新的技术进步。
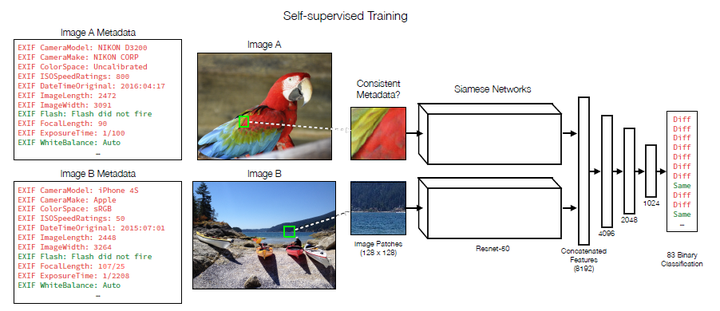 图 5-2 基于自监督方法的骨干网络[49]
图 5-2 基于自监督方法的骨干网络[49]
为了解决Minyoung Huh等人提出的基于GAN框架的篡改技术识别问题,Peng zhou等人[50]提出了一种基于GAN[33]结构的拼接检测模型(GSR-Net)。该方法分为生成器和鉴别器,生成器将供体图像的某部分拼接到源图像中,再经过深度卷积网络努力生成真假难辨的篡改图像;鉴别器分为分割阶段和替换阶段,两个阶段共享网络参数,分割阶段负责识别篡改图像中的篡改边界,再经过替换阶段将篡改别见替换为真实区域,生成新的篡改边界,模型结构如图5-3所示。这种设计可以引导鉴别器进一步识别图像篡改边界的特征。最终,采用鉴别器对篡改图像进行识别。由于鉴别器是别的是拼接边缘的伪影,所以在实验中,该方法在拼接、复制粘贴等多个任务都达到了当前最好的效果。
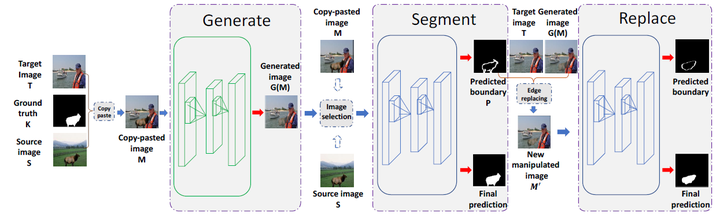 图 5-3 GSR-Net网络结构[50]
图 5-3 GSR-Net网络结构[50]
5.1.2 约束图像拼接检测
由于当前篡改技术复杂多样,很难从一幅图像中提取到有效的通用特征进行学习,因此Yue Wu等人[51]将拼接检测任务进行了扩展:将原有单一篡改图像检测任务扩展为源图像和供体图像相似性匹配任务,称为约束图像拼接检测任务(CISD)。
Yue Wu等人提出了一种名为深度匹配验证网络(DMVN)[51]的结构,该网络采用源图像和供体图像同时作为输入,采用卷积操作,提取密集重叠图像块的特征,然后将获取的篡改特征输入到特征提取框架(如VGG-16、ResNet等)进行深度特征提取,通过图像块之间的相似性比对,获取像素级别的置信图,再经过反卷积操作获得两幅图像的掩码。值得一提的是,作者在框架最后引入了Attention思想,根据获得的掩码,再次提取篡改区域特征进行视觉一致性验证,进一步提高了区域分割精度。
受到Yue Wu等人深度匹配验证网络(DMVN)[51]的启发,Yaqi Liu等人[52]在2019年提出了一种基于空洞卷积的深度匹配模型(DAMC),同样采用篡改图像和供体图像作为输入。该模型基于GAN[33]框架,分为DMAC网络,类别检测网络和区域定位网络,模型结构如图5-4 所示。其中DMAC网络为生成器部分,特征提取骨干网络为VGG-16,但网络的最后三层卷积被替换为空洞卷积层,随后将提取的特征图输入到基于空洞卷积的关联层计算不同尺度的关联度映射,再采用基于空洞网络的空间金字塔池化结构计算出篡改图像和供体图像的掩码。鉴别器由类别检测网络和区域定位网络构成。类别检测网络负责鉴别生成器确定区域的真假分类,区域定位网络负责对比篡改区域和供体区域是否一致。该模型相对于DMVN进一步提升了识别精度。
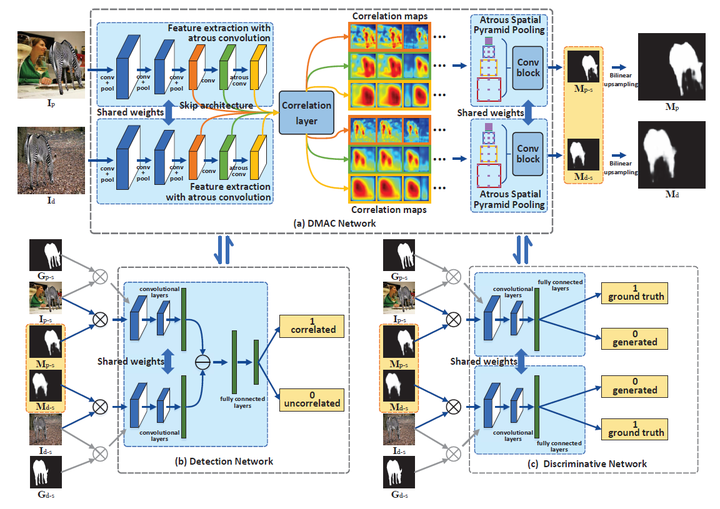 图5-4 DMAC网络结构
图5-4 DMAC网络结构
5.1.3 总结
图像拼接检测领域当前可以分为两个任务,一是仅对篡改图像进行分类,二是将拼接检测任务转换为篡改区域与供体图像的相似性检测任务(CISD)。
第一类任务是目前图像被动取证研究的热点问题,从2016年至今取得了长足的发展,2016年Ying Zhang等人[42]首次将深度学习方法用于手工特征的学习,完成了图像块级别的粗略定位。2017年Salloum等人[44]将全卷积神经网络应用于图像拼接被动取证任务,提出了MFCN框架,首次实现了像素级别细粒度地分割。随后Chen等人[46]对MFCN进一步改进,提升了细小区域的识别精度。2018年基于深度学习的图像拼接被动取证任务涌现了大量创新性的网络结构。Yaqi Liu等人[47]提出了一种基于多尺度卷积的方法,提取不同尺度图像块特征,解决了拼接区域识别领域中篡改区域大小限制的问题。Bo Liu等人[48]为了提升模型对于图像后处理操作的鲁棒性,设计了基于基础网络的模型结构。Minyoung Huh等人[49]创新性的将自学习方法融入图像拼接检测中,该模型避免了当前图像篡改数据集数据量不足的问题,为基于深度学习的图像内容被动取证指出了新的方向。不久后,Peng zhou等人试图解决 Minyoung Huh在文中提出的基于GAN框架图像篡改识别问题,开创性地提出了基于GAN框架的GSR-Net[50],引导深度学习模型提取图像边缘伪影特征进行篡改区域检测。
与第一类任务相比,CISD任务处于刚刚发展的阶段,目前存在的方法较少,仅有DMVN和DMVC两种网络结构。2017年Yue Wu等人[51] 将拼接检测任务进行了扩展:将原有单一篡改图像检测任务扩展为源图像和供体图像相似性匹配任务,称为约束图像拼接检测任务(CISD),同时提出了一种解决该问题的方法—DMVN模型。2019年Yaqi Liu等人受到Yue Wu的启发,提出了一种基于空洞卷积的深度匹配模型(DAMC)[52],进一步提升了识别精度。
图像拼接检测是图像内容被动取证中相对简单的一个任务,相对于复制-粘贴和移除,采用拼接方式篡改的图像在图像边缘伪影、图像统计特征、图像成像特征等方面都有大量可以利用的线索。但截至目前,绝大多数拼接检测深度学习框架都无法应用于复制-粘贴检测和移除检测。接下来我们将详细描述深度学习方法在复制-粘贴检测任务中的成果。
5.2 图像复制-粘贴检测
图像复制-粘贴操作是指复制图像中某一区域并粘贴到同一图像中。通常,复制-粘贴操作用来掩盖图像中某一区域,达到真假难辨的效果。这种篡改方式与拼接相同,都篡改了图像的内容,但检测难度比拼接技术检测要高很多。因为复制-粘贴操作是同一图像内部操作,真实区域与篡改区域在统计属性上极为相似,因此成像设备固有属性和大部分图像统计特征都无法使用。目前,图像复制-粘贴检测技术可以分为两大类:1)基于区域边界伪影,2)基于区域相似性。
5.2.1 基于区域边界伪影
经过复制-粘贴操作的图像,其篡改区域与真实区域边界之间通常存在边界伪影,这与真实图像有很大区别。基于边界伪影的探测方式就是利用卷积网络提取图像边界信息,再经过机器学习分类器进行分类。
2016年 Rao等人[36]首次将深度学习方法应用于复制-粘贴操作检测任务中。为了更好地抑制图像语义信息,提取边缘特征,作者首先采用SRM高通滤波器提取图像高频信息,然后采用滑动窗口的方法将预处理后的图像输入到深度卷积神经网络中,最终实现图像真假分类,模型结构如图5-5所示。实验表明,该方法能有有效学习边界伪影特征,捕捉边界异常信息,达到了较高的分类精度。
2017年Ouyang等人[53]提出了一种基于卷积神经网络的复制-粘贴检测方法。 由于复制-粘贴数据集数据量太小,因此该模型首先在ImageNet上进行预训练,然后再使用较小的复制-粘贴训练样本对网络参数进行微调,最终模型实现图像真假分类。
基于区域边界伪影的方法虽然更符合人类视觉习惯,但对于深度学习网络来说,提取如此细小的边界伪影信息十分困难。因此采用这种方法进行识别的模型仅仅能够完成图像真假分类,不能实现像素级别的区域分割。
5.2.2 基于区域相似性
复制-拼接操作的本质是复制图像中某一区域并粘贴到同一图像中。这种篡改方式产生的图像中必定包含两个完全相同的区域,因此研究者们提出了基于区域相似性的检测方法,这与拼接探测问题中约束图像拼接检测任务(CISD)十分相似。
2018年Wu等人[54]提出了一种图像复制-粘贴篡改检测框架。该模型采用端到端的设计,整体分为特征提取、自相关计算、逐点特征提取、掩码生成四个阶段。首先采用整张图像输入到模型中,经由特征提取器提取图像高级特征,然后计算特征图中每一对像素之间的相关性,然后根据相关性大小选取相似区域,再进一步提取相似区域高级特征,最后进行解码,输出图像篡改区域掩码,模型整体结构如图 5-6所示。该方法首次实现了像素级别的复制-粘贴任务检测,识别精度超过了传统检测方法。
 图5-6 Wu等人复制-粘贴检测框架[54]
图5-6 Wu等人复制-粘贴检测框架[54]
不久Wu等人[55]进一步扩展了该框架,融合基于边界伪影方法和区域相似性方法的长处,提出了可以检测源目标和篡改目标的BusterNet。如图5-7所示,模型分为Mani-Det分支和Simi-Det分支。Mani分支主要负责定位篡改区域,通过提取篡改区域边界伪影信息,实现像素级别预测,输出篡改区域掩码。Simi-Det分支负责自相关检测,检测出图像中两个相似的区域,并输出相似性区域掩码。值得注意的是,模型将Mani-Det分支和Simi-Det分支的特征进行融合,然后对两个相似区域进行像素级别地分类,准确预测出源目标和篡改目标。实验表明,该方法具有较好的鲁棒性,在多个数据集上实现了最佳的效果。
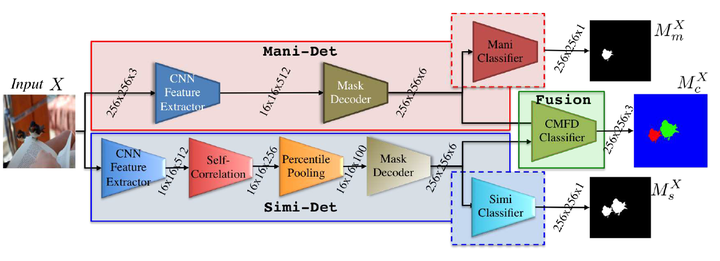 图5-7 BusterNet网络结构[55]
图5-7 BusterNet网络结构[55]
5.2.3 总结
深度学习图像复制-粘贴检测任务,当前可以大致分为基于图像边界伪影和基于区域相似性两大类。
基于图像边界伪影检测方法是从人类识别图像真假过程入手,提取篡改区域与真实区域之间的不一致特征,经由深度学习模型进行预测分类。这类方法一般会进行图像预处理过程,如2016年Rao等人[36]提出的基于深度学习的图像复制-粘贴检测框架就使用了SRM高通滤波器,预处理过程的目的是屏蔽图像内容特征,提取图像高频信息,突出边缘特征。2017年Ouyang等人[53]提出使用迁移学习的方法解决篡改图像数据集过小的问题。该方法首先在ImageNet上进行预训练,然后再采用数量较小的复制-粘贴数据集进行微调,在图像真假分类上实现了较高的精度。
基于区域相似性检测方法将复制-粘贴区域定位问题转换为相似性匹配问题。这类方法通常以整个图像作为输入,提取图像中大量重叠的图像块进行相似性计算,从而找到相似性最高的区域。2018年Wu等人[54]便是基于这种思想设计完成了基于区域相似性匹配的图像复制-粘贴检测框架。不久后,Wu等人[55]对该方法再次进行了拓展,融合了基于边界伪影检测和区域相似性检测方法,提出了一种双流检测框架BusterNet。值得一提的是,该框架不仅可以同时定位两个相似区域,而且还可以区分源区域与篡改区域。
5.3 计算机生成检测
近几年,深度学习技术快速发展,采用生成对抗网络(GAN)[33]生成图像的方法取得了极好的效果,生成的图像真假难辨。当前,图像篡改领域也出现了采用生成对抗方法修复图像移除部分的网络结构[56]。面对深度学习生成这一新兴的图像篡改方式,如何对其进行有效检测是图像内容被动取证领域的新任务,存在以下难点:
1)特征变化较大
GAN框架生成图像的原理是通过建立缺失区域与真实区域之间的联系,从而通过当前区域特征分布预测缺失区域。这种方法产生的篡改图像与常规篡改方式产生的图像有很大区别,篡改区域与真实区域往往在统计特征、边缘伪影等方面极为相似。因此,如何提取有效特征将会是检测的难点之一。
2)视觉效果十分逼真
GAN框架由生成器和鉴别器构成,二者都是深度学习网络。生成器负责生成真假难辨的图像,鉴别器负责对图像进行鉴别,当鉴别器无法鉴别出生成图像的时候,图像被输出。采用这种方式产生的图像通常是常规深度学习网络无法检测出具体类别的,生成方法对于深度学习鉴别方法鲁棒性很强。因此如何设计有效的网络结构去学习人眼无法发现的篡改线索也是检测的难点之一。
面对复杂的深度学习篡改图像,研究者们从2017年起开始了逐步探索。2017年Nicolas Rahmouni等人[57]首次尝试对计算机生成的篡改图像进行鉴别。该模型首先将图像分割为重叠的大小相同的图像块,然后采用深度卷积网络提取图像特征,最后采用机器学习分类器对图像块真假进行分类。该方法是对计算机生成图像检测的一次尝试,展现出了较高的分类精度。
2018年Huy H等人[58]提出了一种模块化的计算机生成图像检测器。该模型主要分为三个模块:特征提取模块、特征转换模块、分类模块。图像首先被分割为大小相同的不重叠的图像块,然后输入到网络中进行预测。特征提取模块负责提取图像块的深层语义信息,然后输入到特征转换模块,为了避免深层卷积网络提取图像的深层语义信息,特征转换模块仅用了两层卷积,用来捕获图像篡改特征,接下来输入到分类器进行真假分类。该方法加入了特征转换模块,尝试捕获图像篡改信息,在图像块级别产生了较高的分类精度。
由于篡改图像可以由GAN框架生成器产生,那么自然可以通过鉴别器来进行分辨。Francesco Marra等人[59] 将GAN框架中的鉴别器替换为当前多种鉴别网络结构,对比他们在计算机伪造图像上的检测效果。实验发现InceptionNet v3和XceptionNet在未压缩图像中精度最高,其中XceptionNet具有很好的鲁棒性,在图像进行压缩后仍有较高的准确率。
深度学习促进了计算机图像生成的发展,但发展背后带来的多媒体信息安全问题值得研究者们深思,如何对这些信息的真假进行鉴别是一个新兴的问题。
5.4 多种篡改方式检测
以上三类检测方法大都建立在对图像篡改类型的假设上,但这在实际使用中是不可能实现的,面对为止图像,我们无法直接判断图像的判断类型。因此,如何才能实现通用图像检测,一直是研究者们努力的方向。当前存在以下多种篡改方式检测模型,主要分为基于手工设计特征和自适应提取特征两种方式。
5.4.1手工设计特征方法
受到传统检测方式的启发,手工设计特征(如重采样特征、JPEG压缩特征等)结合深度学习方法有时会产生意想不到的效果。
2017年Bappy等人[60]首次利用重采样特征结合深度学习方法对多种篡改方式进行检测。作者提出了两种基于重采样特征和深度学习相结合的图像操作检测和定位方法。在第一种方法中,对重叠图像块计算重采样特征的Radon变换。然后使用深度学习分类器和高斯条件随机场模型来创建热图。利用随机Walker分割方法定位篡改区域。第二种方法是通过基于长短时记忆(LSTM)的网络对重叠图像块计算的重采样特征进行分类和定位,作者训练了一个六分类器,探测六种不同的重采样,如图5-8所示。其中基于LSTM的网络在拼接、复制-粘贴、移除三种篡改方式的数据集上实现了0.9以上的准确率。
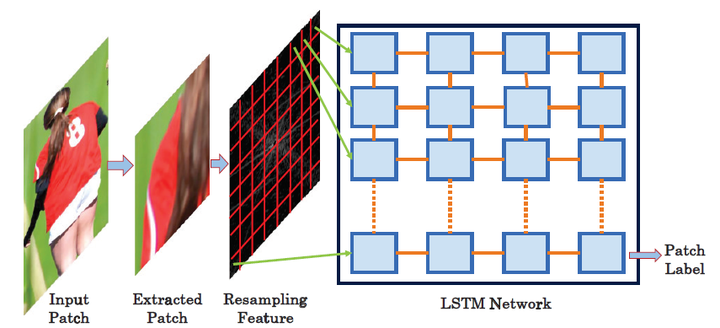 图5-8 基于LSTM的图像块分类框架[60]
图5-8 基于LSTM的图像块分类框架[60]
2018年Park等人[61]提出了一种利用双JPEG压缩特征进行篡改区域定位的框架。如图5-9所示,图像首先被分割为大小相同的多个图像块,然后将图像块转换至YCbCr颜色空间计算DCT系数,然后根据多个图像块的DCT系数得出图像的直方图特征,将该特征输入至深度卷积网络提取深层特征,最后结合图像量化表中附加信息预测图像是否包含双JPEG压缩,从而判断出图像篡改区域。值得注意的是,该模型可以检测具有混合JPEG质量因子的各种操作。为此,作者将原始图像数据集中的图像分割为大小相同的图像块,然后采用随机JPEG量表进行压缩,构建了一个随机JPEG压缩数据集。
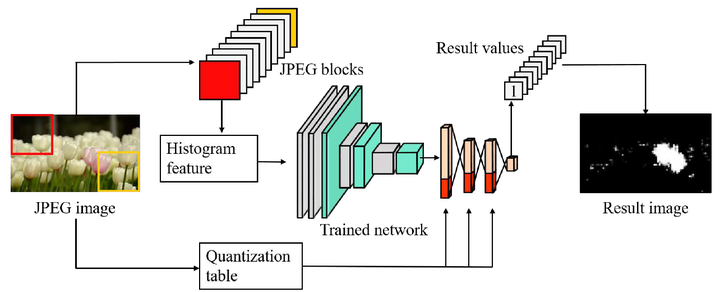 图5-9 基于JPEG特征的篡改区域定位框架[61]
图5-9 基于JPEG特征的篡改区域定位框架[61]
2019年Bappy等人[34]提出了一种基于重采样特征,LSTM网络和编码器 - 解码器架构的统一架构,解决被篡改图像区域的像素级定位问题。如图5-10所示,模型存在LSTM和编码器两个分支。首先在LSTM分支中将一个给定的图像分成多个图像块,然后从每个块中提取重采样特征。利用LSTM网络来学习频域中的篡改区域和真实区域之间的相关性。然后在编码器分支中利用编码器 - 解码器网络来捕获空间信息。每个编码器生成不同大小和数量的特征映射。来自LSTM网络的特征映射和来自编码器的编码特征映射在通过解码器之前被融合。
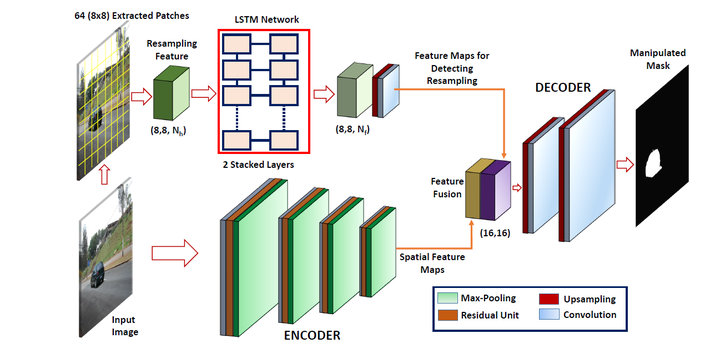 图5-10 Bappy等人提出的网络结构[34]
图5-10 Bappy等人提出的网络结构[34]
由于手工设计的特征在传统方法上发展相对成熟,因此基于手工设计特征的方法在深度学习中也取得了不错的效果,但手工设计特征有其自身的局限性,随着篡改技术的发展,手工设计特征很容易被有针对性的屏蔽,因此如何自适应提取图像篡改特征仍是解决通用检测任务的关键。
5.4.2 自适应提取特征方法
任何篡改方式都会在细微处留下篡改痕迹。自适应提取特征方法通常是将图像输入后,不进行预处理操作,由神经网络自行学习图像中的篡改特征,这些特征一般是图像边界异常特征、图像内在统计特征等。
2017年Bappy等人[37]设计并实现了一个混合的CNN - LSTM模型来捕捉修改区域和非修改区域边界的异常特征,学习边界差异,即利用LSTM和卷积层的结合,得到修改区和非修改区之间的空间结构,通过学习修改区域和非修改区域边界之间异常的空间结构判定图像篡改区域,如图5-11所示。该模型在拼接、复制-粘贴、删除等篡改技术上取得了不错的效果。
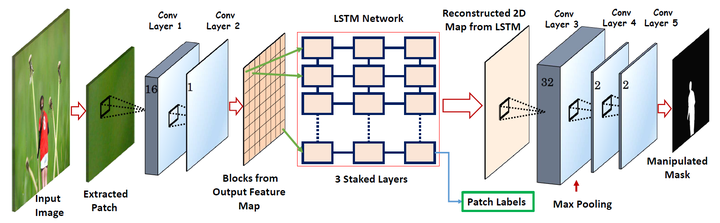 图5-11 CNN-LSTM网络结构[37]
图5-11 CNN-LSTM网络结构[37]
随后,Bappy等人再次对CNN-LSTM模型进行拓展[62]。由于复制-粘贴操作是一张图像内的篡改过程,因此很多特征在复制-粘贴操作检测中都失效了。因此作者在原有模型之前加入了单独的复制-粘贴检测模块,作为整个模型的“预判断”步骤。该模块基于图像块匹配模型,计算图像块之间相似度,从而判定图像是否经过复制-粘贴判定并确定篡改区域位置。与原有模型相比,新框架识别AUC分数从0.66提升至0.74 。
深度学习促进计算机视觉领域快速发展,其中最为突出的便是目标检测任务,基于Two-Stage结构的Faster R-CNN[30],基于One-Stage的YOLO[32]等框架都在目标检测任务中取得了很好的效果。由于图像内容篡改通常是对图中某个区域进行修改,因此也可以将篡改区域看作一种“目标”。因此2018年Peng zhou等人[39]将图像内容被动取证任务转换为目标检测任务,提出了RGB-N框架。如图5-12所示,该模型整体基于Faster R-CNN框架,模型分为RGB流和噪声流两部分。其中RGB域更容易检测出图像的边界异常,Noise空间中可以发现RGB空间无法发现的篡改线索,更有利于篡改技术分类。值得注意的是,作者巧妙地将区域推荐网络(RPN)应用到篡改区域定位任务中,通过RPN模块寻找潜在篡改区域,分别在RGB特征和Noise特征中截取篡改区域部分进行细粒度的双线性池化[63]操作,最终完成篡改分类。同时,作者为了解决数据集不足的问题,从现有的目标检测数据集中提取原始图像创建了大小为42K的合成数据集用于图像预训练。实验结果证明,该方法具有较强的鲁棒性,在拼接、复制-粘贴、移除等操作中取得了很好的效果。
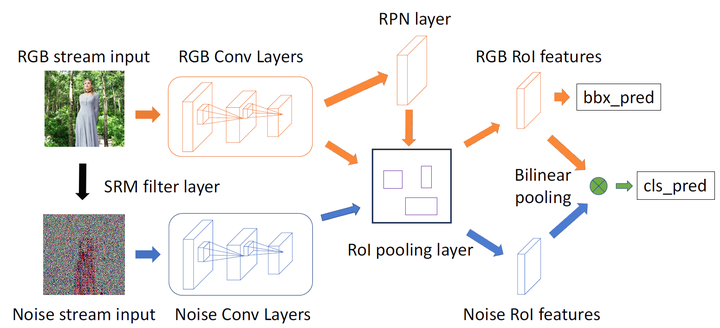 图5-12 RGB-N框架结构[39]
图5-12 RGB-N框架结构[39]
5.4.3 总结
多种篡改方式检测任务按照特征提取大致可以分为两类:1)基于手工设计特征的方法,2)自适应特征提取方法。
基于手工设计特征的方法传承自传统图像被动取证,深度学习被广泛应用之前发展就相对成熟。2016年Bappy等人[60] 首次利用重采样特征结合深度学习方法对多种篡改方式进行检测,在拼接、复制-粘贴、移除三种篡改方式的数据集上实现了0.9以上的准确率。2018年Park等人[61]提出了一种利用双JPEG压缩特征进行篡改区域定位的框架,该模型可以检测具有混合JPEG质量因子的各种操作。2019年Bappy等人[34]提出了一种基于重采样特征,LSTM网络和编码器 - 解码器架构的统一架构,解决被篡改图像区域的像素级定位问题。但基于手工设计特征的方法无法适应不断发展的篡改技术,很容易被新的篡改手段有针对性地屏蔽。
自适应特征提取方法是最适合深度学习思想的一种特征提取方法,通常是将图像输入后,不进行预处理操作,由神经网络自行学习图像中的篡改特征。2017年Bappy等人[37]设计并实现了一个混合的CNN - LSTM模型,该模型在拼接、复制-粘贴、删除等篡改技术上取得了不错的效果,不久后,Bappy等人再次对CNN-LSTM模型进行拓展[62],针对CNN-LSTM模型在复制-粘贴检测上的短板,在模型前加入了复制-粘贴检测模块,进一步提升了模型精度。2018年Peng zhou等人[39]将图像内容被动取证任务转换为目标检测任务,提出了RGB-N框架,巧妙地将区域推荐网络(RPN)应用到篡改区域定位任务中,在拼接、复制-粘贴、移除等操作中取得了很好的效果。
6 展望
相对于计算机视觉领域,深度学习图像内容被动取证是一个新兴的研究方向。通过借鉴目标检测、语义分割、图像修复等方向的研究方法,自2016年首次出现至今,图像内容被动取证发展迅速,出现了很多出色的深度学习框架。但这与实现通用被动取证框架的目标还相距甚远。总体而言,基于深度学习的图像内容被动取证领域还存在以下问题:
1)图像篡改特征提取
基于手工设计的特征当前在精度上可以达到不错的效果,但由于篡改技术发展日新月异,随着篡改手段越来越先进,越来越复杂,基于手工设计的特征很容易受到攻击,被某一种或者几种篡改技术屏蔽。当前自适应提取图像篡改特征的方法发展仍不成熟,仅仅依赖区域边缘异常和图像内在统计特征很容易很难取得鲁棒性好的结果,边缘异常和统计特征都很容易被图像后处理过程破坏。约束卷积层是通用特征提取的一个好的方向,但当前实现的约束卷积层可以看作是一个通用高通滤波器,其在图像增强、放缩等操作中效果较好,但在图像内容被动取证中与手工设计的SRM高通滤波器效果相当,没有取得更佳的效果。
2)数据集不足
虽然当前篡改图像数据集越来越多,但这与复杂多样的篡改技术相比仍远远不足。当前大多深度学习框架都依赖于数据驱动,当深度学习模型面对一个从来没有学习过的篡改技术时很难进行有效判定。自学习和自一致性检测是解决这个问题的有效方法。通过图像内部自一致性判断,可以检测出图像中异常的区域。这种方法可以解决篡改图像数据集不足的问题,以大量不同源图像块对进行一致性训练,让模型学习图像之间的差异。但该方法仅仅适用于拼接检测,还不能解决其他篡改方式检测的问题。
3)深度学习图像修复与取证的“矛与盾”
深度学习可以用来进行图像内容被动取证,自然也可以进行图像修复和图像伪造。就目前研究进展而言,基于生成对抗网络的图像修复发展极为迅速,所生成的图像让人真假难辨。与图像修复和篡改的“矛”相比,图像内容被动取证的“盾”发展情况要落后很多。面对深度学习网络基于真实区域与缺失区域相关性预测出的“虚假”图像,如何进行检测,当前还没有效果很好的方法。
4)模型复杂度
现有比较有效的模型大多极为复杂,由于图像篡改特征十分微小和脆弱,因此深度学习模型需要细密捕获图像特征,这就会导致模型参数量很大,有时甚至需要在多GPU上连续运行数周时间,这是人们远远不能接受的。如何精简模型参数并削弱无效特征的提取是一个亟待解决的问题。
5)可解释性弱
手工设计特征鲁棒性差,自适应特征提取方法通常采用端到端的训练方式,这种方法避免了人工调整参数,但也造成了人们无法解释模型究竟提取的是什么特征。
参考文献
[1] 周琳娜. 数字图像盲取证技术研究 [D]; 北京邮电大学, 2007.
[2] WARBHE A D, DHARASKAR R V, THAKARE V M. Computationally Efficient Digital Image Forensic Method for Image Authentication ☆ [J]. Procedia Computer Science, 2016, 78(464-70.
[3] 朱叶. 数字图像复制—粘贴篡改盲取证关键技术研究 [D]; 吉林大学, 2017.
[4] LUKAS J, FRIDRICH J, GOLJAN M. Digital camera identification from sensor noise [J]. IEEE Transactions on Information Forensics & Security, 2006, 1(2): 205-14.
[5] SWAMINATHAN A, MIN W, LIU K J R. Nonintrusive component forensics of visual sensors using output images [M]. 2007.
[6] SWAMINATHAN A, WU M, LIU K J R. Component Forensics of Digital Cameras: A Non-Intrusive Approach; proceedings of the Conference on Information Sciences & Systems, F, 2007 [C].
[7] LAM E Y, KAI S C, WONG K K Y. Automatic source camera identification using the intrinsic lens radial distortion [J]. Optics Express, 2006, 14(24): 11551-65.
[8] GALLAGHER A C, CHEN T. Image authentication by detecting traces of demosaicing; proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition Workshops, F, 2008 [C].
[9] DIRIK A E, BAYRAM S, SENCAR H T, et al. New Features to Identify Computer Generated Images; proceedings of the IEEE International Conference on Image Processing, F, 2007 [C].
[10] NG T T, CHANG S F, HSU J, et al. Physics-motivated features for distinguishing photographic images and computer graphics; proceedings of the Acm International Conference on Multimedia, F, 2005 [C].
[11] YING W, MOULIN P. On Discrimination between Photorealistic and Photographic Images; proceedings of the IEEE International Conference on Acoustics, F, 2006 [C].
[12] WEN C, SHI Y Q, XUAN G. Identifying Computer Graphics using HSV Color Model and Statistical Moments of Characteristic Functions; proceedings of the IEEE International Conference on Multimedia & Expo, F, 2007 [C].
[13] 杨滨. 图像克隆拼接篡改盲取证技术研究 [D]; 湖南大学, 2014.
[14] FRIDRICH A J, SOUKAL B D, LUK Š A J. Detection of copy-move forgery in digital images; proceedings of the in Proceedings of Digital Forensic Research Workshop, F, 2003 [C]. Citeseer.
[15] POPESCU A C, FARID H. Exposing digital forgeries by detecting duplicated image regions [J]. Dept Comput Sci, Dartmouth College, Tech Rep TR2004-515, 2004, 1-11.
[16] LOWE D G. Distinctive Image Features from Scale-Invariant Keypoints [J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
[17] BAY H, ESS A, TUYTELAARS T, et al. Speeded-Up Robust Features (SURF) [J]. Computer Vision & Image Understanding, 2008, 110(3): 346-59.
[18] AMERINI I, BALLAN L, CALDELLI R, et al. A SIFT-Based Forensic Method for Copy–Move Attack Detection and Transformation Recovery [J]. IEEE Transactions on Information Forensics & Security, 2011, 6(3): 1099-110.
[19] PAN X, LYU S. Region Duplication Detection Using Image Feature Matching [J]. IEEE Transactions on Information Forensics & Security, 2010, 5(4): 857-67.
[20] POPESCU A C, FARID H. Exposing digital forgeries by detecting traces of resampling [J]. IEEE Transactions on Signal Processing, 2005, 53(2): 758-67.
[21] LUK Š J, FRIDRICH J. Estimation of primary quantization matrix in double compressed JPEG images; proceedings of the Proc Digital forensic research workshop, F, 2003 [C].
[22] POPESCU A C, FARID H. Statistical tools for digital forensics; proceedings of the International Workshop on Information Hiding, F, 2004 [C]. Springer.
[23] FARID H. Digital image ballistics from JPEG quantization: A followup study [J]. Department of Computer Science, Dartmouth College, Tech Rep TR2008-638, 2008, 7(1-28.
[24] POPESCU A C, FARID H. Exposing Digital Forgeries in Color Filter Array Interpolated Images [J]. IEEE Transactions on Signal Processing, 2005, 53(10): 3948-59.
[25] LUK Š J, FRIDRICH J, GOLJAN M. Detecting digital image forgeries using sensor pattern noise [J]. Proceedings of SPIE - The International Society for Optical Engineering, 2006, 6072(362-72.
[26] CHEN M, FRIDRICH J, GOLJAN M, et al. Determining Image Origin and Integrity Using Sensor Noise [J]. IEEE Transactions on Information Forensics & Security, 2008, 3(1): 74-90.
[27] FARID H, LYU S. Higher-order Wavelet Statistics and their Applicationto Digital Forensics; proceedings of the Conference on Computer Vision & Pattern Recognition Workshop, F, 2003 [C].
[28] SHI Y Q, CHEN C, WEN C. A Natural Image Model Approach to Splicing Detection; proceedings of the Workshop on Multimedia & Security, F, 2007 [C].
[29] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks; proceedings of the Advances in neural information processing systems, F, 2012 [C].
[30] REN S, HE K, GIRSHICK R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks; proceedings of the Advances in neural information processing systems, F, 2015 [C].
[31] HE K, GKIOXARI G, DOLL R P, et al. Mask r-cnn; proceedings of the Proceedings of the IEEE international conference on computer vision, F, 2017 [C].
[32] REDMON J, FARHADI A. Yolov3: An incremental improvement [J]. arXiv preprint arXiv:180402767, 2018,
[33] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets; proceedings of the Advances in neural information processing systems, F, 2014 [C].
[34] BAPPY J H, SIMONS C, NATARAJ L, et al. Hybrid LSTM and Encoder-Decoder Architecture for Detection of Image Forgeries [J]. IEEE Transactions on Image Processing, 2019,
[35] HUANG N, HE J, ZHU N. A Novel Method for Detecting Image Forgery Based on Convolutional Neural Network; proceedings of the 2018 17th IEEE International Conference On Trust, Security And Privacy In Computing And Communications/12th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE), F, 2018 [C]. IEEE.
[36] RAO Y, NI J. A deep learning approach to detection of splicing and copy-move forgeries in images; proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), F, 2016 [C]. IEEE.
[37] BAPPY M J H, ROY-CHOWDHURY A K, BUNK J, et al. Exploiting Spatial Structure for Localizing Manipulated Image Regions; proceedings of the IEEE International Conference on Computer Vision, F, 2017 [C].
[38] FRIDRICH J, KODOVSKY J. Rich models for steganalysis of digital images [J]. IEEE Transactions on Information Forensics and Security, 2012, 7(3): 868-82.
[39] ZHOU P, HAN X, MORARIU V I, et al. Learning rich features for image manipulation detection; proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, F, 2018 [C].
[40] BAYAR B, STAMM M C. Design principles of convolutional neural networks for multimedia forensics [J]. Electronic Imaging, 2017, 2017(7): 77-86.
[41] BAYAR B, STAMM M C. Constrained convolutional neural networks: A new approach towards general purpose image manipulation detection [J]. IEEE Transactions on Information Forensics and Security, 2018, 13(11): 2691-706.
[42] ZHANG Y, GOH J, WIN L L, et al. Image Region Forgery Detection: A Deep Learning Approach; proceedings of the SG-CRC, F, 2016 [C].
[43] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation; proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, F, 2015 [C].
[44] SALLOUM R, REN Y, KUO C C J. Image Splicing Localization using a Multi-task Fully Convolutional Network (MFCN) ☆ [J]. Journal of Visual Communication & Image Representation, 2017, 51(201-9.
[45] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J]. arXiv preprint arXiv:14091556, 2014,
[46] CHEN B, QI X, WANG Y, et al. An Improved Splicing Localization Method by Fully Convolutional Networks [J]. IEEE Access, 2018, 6(69472-80.
[47] LIU Y, GUAN Q, ZHAO X, et al. Image forgery localization based on multi-scale convolutional neural networks; proceedings of the Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security, F, 2018 [C]. ACM.
[48] LIU B, PUN C-M. Deep fusion network for splicing forgery localization; proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), F, 2018 [C].
[49] HUH M, LIU A, OWENS A, et al. Fighting fake news: Image splice detection via learned self-consistency; proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), F, 2018 [C].
[50] ZHOU P, CHEN B-C, HAN X, et al. Generate, Segment and Replace: Towards Generic Manipulation Segmentation [J]. arXiv preprint arXiv:181109729, 2018,
[51] WU Y, ABD-ALMAGEED W, NATARAJAN P. Deep matching and validation network: An end-to-end solution to constrained image splicing localization and detection; proceedings of the Proceedings of the 25th ACM international conference on Multimedia, F, 2017 [C]. ACM.
[52] LIU Y, ZHU X, ZHAO X, et al. Adversarial Learning for Constrained Image Splicing Detection and Localization based on Atrous Convolution [J]. IEEE Transactions on Information Forensics and Security, 2019,
[53] OUYANG J, LIU Y, LIAO M. Copy-move forgery detection based on deep learning; proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), F, 2017 [C]. IEEE.
[54] WU Y, ABD-ALMAGEED W, NATARAJAN P. Image Copy-Move Forgery Detection via an End-to-End Deep Neural Network; proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), F, 2018 [C]. IEEE.
[55] WU Y, ABD-ALMAGEED W, NATARAJAN P. BusterNet: Detecting copy-move image forgery with source/target localization; proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), F, 2018 [C].
[56] YU J, LIN Z, YANG J, et al. Generative image inpainting with contextual attention; proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, F, 2018 [C].
[57] RAHMOUNI N, NOZICK V, YAMAGISHI J, et al. Distinguishing computer graphics from natural images using convolution neural networks; proceedings of the 2017 IEEE Workshop on Information Forensics and Security (WIFS), F, 2017 [C]. IEEE.
[58] NGUYEN H H, TIEU T, NGUYEN-SON H-Q, et al. Modular convolutional neural network for discriminating between computer-generated images and photographic images; proceedings of the Proceedings of the 13th International Conference on Availability, Reliability and Security, F, 2018 [C]. ACM.
[59] MARRA F, GRAGNANIELLO D, COZZOLINO D, et al. Detection of GAN-generated fake images over social networks; proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), F, 2018 [C]. IEEE.
[60] BUNK J, BAPPY J H, MOHAMMED T M, et al. Detection and Localization of Image Forgeries Using Resampling Features and Deep Learning [J]. 2017, 1881-9.
[61] PARK J, CHO D, AHN W, et al. Double jpeg detection in mixed jpeg quality factors using deep convolutional neural network; proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), F, 2018 [C].
[62] MOHAMMED T M, BUNK J, NATARAJ L, et al. Boosting Image Forgery Detection using Resampling Features and Copy-move Analysis [J]. Electronic Imaging, 2018, 2018(7): 1-7.
[63] GAO Y, BEIJBOM O, ZHANG N, et al. Compact bilinear pooling; proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, F, 2016 [C].

 浙公网安备 33010602011771号
浙公网安备 33010602011771号