关于输入图像Size不固定的讨论
关于输入图像Size不固定的讨论
【转】对于大小可变的输入,深度学习模型如何处理?
前几天在学习花书的时候,和小伙伴们讨论了“CNN如何处理可变大小的输入”这个问题。进一步引申到“对于大小可变的输入,深度学习模型如何处理?”这个更大的问题。因为这里面涉及到一些概念,我们经常搞混淆,比如RNN单元明明可以接受不同长度的输入,但我们却在实际训练时习惯于使用padding来补齐;再比如CNN无法直接处理大小不同的输入,但是去掉全连接层之后又可以。因此,这里我想总结一下这个问题:
- 究竟什么样的模型结构可以处理可变大小的输入?
- 若模型可处理,那该如何训练/预测?
- 若模型不可处理,那该如何训练/预测?
一、什么样的网络结构可以处理可变大小的输入?
直接上结论(我个人总结的,不一定对/全面,欢迎指正):
当某个网络(层或者单元)是以下三种情况之一时:
① 只处理局部的信息;
② 网络是无参数化的;
③ 参数矩阵跟输入大小无关,
这个网络就可以处理大小可变的输入。
下面我分别从几个经典的网络结构来回应上面的结论:
CNN
首先讲讲CNN。CNN中的卷积层通过若干个kernel来获取输入的特征,每个kernel只通过一个小窗口在整体的输入上滑动,所以不管输入大小怎么变化,对于卷积层来说都是一样的。那为什么CNN不能直接处理大小不同的图片呢?是因为一般的CNN里都会有Dense层,Dense层连接的是全部的输入,一张图片,经过卷积层、池化层的处理后,要把全部的单元都“压扁(flatten)”然后输入给Dense层,所以图片的大小,是影响到输入给Dense层的维数的,因此CNN不能直接处理。但是,有一种网络叫FCNN,即Fully Convolutional Neural Network,是一种没有Dense层的卷积网络,那么它就可以处理大小变化的输入了。
SSP
CNN处理大小可变的输入的另一种方案是使用特殊的池化层——SSP(Spatial Pyramid Pooling),即“空间金字塔池化”,最初由何恺明团队提出。这种池化层,不使用固定大小的窗口,而是有固定大小的输出。比方不管你输入的网格是多大,一个固定输出2×2的SSP池化,都将这个输入网络分成2×2的区域,然后执行average或者max的操作,得到2×2的输出。
SSP和FCNN在《花书》中都有展示:
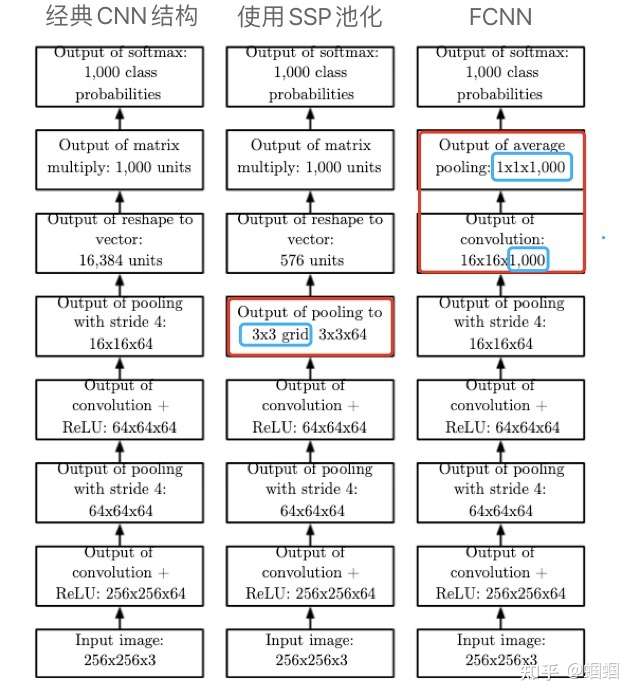
图中,SSP通过一个固定输出大小的pooling,拥有了处理可变大小输入的能力。
FCNN
而FCNN,则是去掉了Dense层,使用kernel的数量来对应类别的数量(如图中例子使用了1000个kernel来对应1000个类),最后使用一个全局池化——GAP(Global Average Pooling),出自Inception-V3,其将每个kernel对应的feature map都转化成一个值,就形成了一个1000维的向量,就可以直接使用softmax来分类了,不必使用Dense层了。通过这连个特殊的卷积层和池化层,FCNN也拥有了处理可变大小输入的能力。
Transformer
Transformer也可以处理长度可变的输入,这个问题在知乎上有讨论,可惜我都没太看明白。比如邱锡鹏老师讲的,是因为“self-attention的权重是是动态生成的”,我不懂权重怎么个动态法?再例如许同学讲“Transformer是通过计算长度相关的self-attention得分矩阵来处理可变长数据”,这个直接从字面上也不太好理解。
在我看来,这跟self-attention压根没关系。Transformer中的self-attention是无参数化的,从attention层输入,到输出加权后的向量表示,不需要任何的参数/权重,因此self-attention自然可以处理长度变化的输入。Transformer中的参数都来源于Dense层,包括一些纯线性映射层(projection layer)和position-wise FFN(feed-forward layer)。搞清楚这些Dense层的操作,才能理解为何Transformer可以处理变长输入。
我们先看看Transformer的结构:
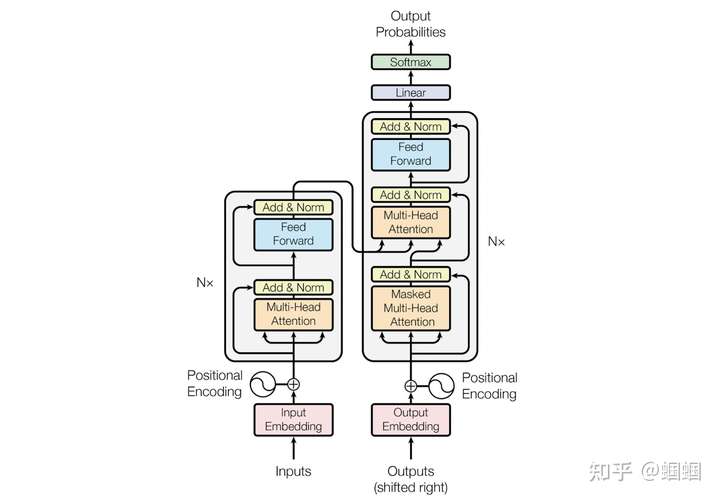
这里我们重点关注encoder部分,即左半部分。但是看这个图,并不能很好的理解为什么可以处理长度变化的输入。为此,我花了一个简陋的草图(省略了多头,省略了Add&Norm,简化了论文中的FFN),来更细致地查看encoder部分:
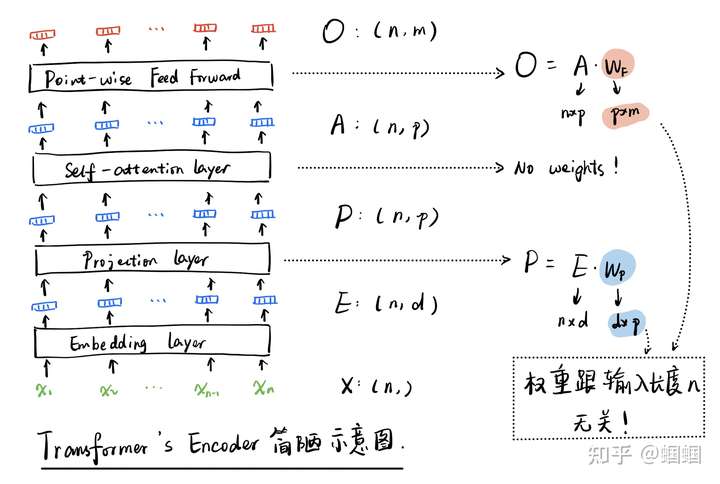
我们不必展开看self-attention的部分,因为它就是让所有的向量,两两之间都计算attention权重然后再分别加权求和得到新的一组向量,中间没有任何的参数,向量的维度、数量都没有任何的变化。
整个encoder,涉及到可学习参数的只有projection layer和point-wise feed-forward layer,其中前者只是为了把每个输入token的向量的维度改变一下(图中,从d变为p),后者则是对每一个token,都使用同一个Dense层进行处理,把每个向量的p维转化为m维。所以,所有的参数,都跟序列的长度n没有任何关系,只要模型参数学好了,我们改变序列长度n也照样可以跑通。
这里唯一值得展开看看的,就是这里的point-wise feed-forward layer,这其实就是普普通通的Dense层,但是处理输入的方式是point-wise的,即对于序列的每个step,都执行相同的操作:
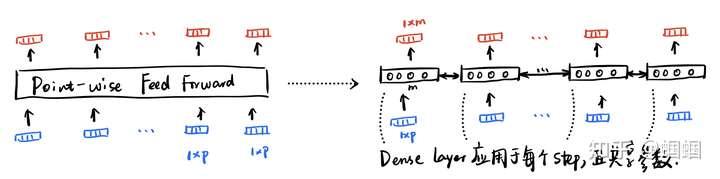
一开始我不理解,为什么明明有一个Dense层接在attention层后面还能处理可变长的输入。后来发现这不是普通的Dense,而是point-wise的,相当于一个recurrent的Dense层,所以自然可以处理变化的长度。
二、若模型可处理大小变化的输入,那如何训练和预测?
通过了第一部分的讨论,我们知道了,什么网络结构可以处理大小变化的输入。
训练
但是我们在训练时,为了加速训练,往往会将一批数据同时输入到模型中进行计算、求导。那同一批数据,要喂给网络,我们必须把它组织成矩阵的形式,那矩阵的每一行/列自然维度需要相同。所以我们必须让同一个batch中的各个样本长度/大小一致。
最常用的方法,就是padding,我们通过padding补零,把同一个batch中的所有样本都变成同一个长度,这样就可以方便我们进行批量计算了。对于那些padded values,也就是补的零,我们可以使用masking机制来避免模型对这些值进行训练。
实际上,有研究指出,我们可以对一批样本(以NLP为例),做一个长度的排序,然后分组,每一组使用不同的max length超参数,这样可以节省padding的使用次数,从而提高训练效率(论文我不知道是哪个,听别人说的,知道的同学可以告诉我),文后的连接里,我找到了一个keras的示例代码,可供参考。
当然,如果我们设置batch size=1,那就不需要padding了,就可以开心的把各种不同长度的数据都丢进去训练了。
预测
在预测时,如果我们想进行批量预测,那也是必须通过padding来补齐,而如果是单条的预测,我们则可以使用各种长度。
三、若模型不可处理大小变化的输入,那如何训练与预测?
训练
不可接受,那我们就只能老老实实地把所有输入都规范成同一大小,比如经典的CNN网络,我们会吧所有的图片都进行resize,或者padding。
这里需要提一下transfer learning的场景,我们经常需要直接拿来别人在ImageNet上训练好的牛逼网络来进行finetune,那问题来了,比人训练CNN的时候,肯定有自己固定好的输入大小,跟我们要用的场景往往不一致,那怎么办?只要做过CNN的transfer learning的同学应该都有经验:我们需要把别人的网络的最后面的Dense层都去掉!因为前面分析过了,Dense层才是让CNN无法处理可变大小输入的罪魁祸首,Dense一拿掉,剩下的卷积层啊池化层啊都可以快乐地迁移到各种不同大小的输入上了。
其他的办法,就是改造模型结构了,例如SSP,FCNN都是对经典CNN的改造。
预测
预测时,在这种情况下,我们也只能使用统一的输入大小,不管是单条还是批量预测。
参考链接:
- 知乎上关于Transformer为何可以处理不同长度数据的讨论: https://www.zhihu.com/question/445895638
- keras中如何实现point-wise FFN的一些讨论:
- https://ai.stackexchange.com/questions/15524/why-would-you-implement-the-position-wise-feed-forward-network-of-the-transforme
- https://stackoverflow.com/questions/44611006/timedistributeddense-vs-dense-in-keras-same-number-of-parameters/44616780#44616780
- keras中如何使用masking来处理padding后的数据:https://www.tensorflow.org/guide/keras/masking_and_padding
- 在训练中,给不同的batch设置不同的sequence_length: https://datascience.stackexchange.com/questions/26366/training-an-rnn-with-examples-of-different-lengths-in-keras
全卷积FCN
全卷积的目的就是为了能够接受任意尺寸的输入
全连接层要求固定的输入维度。而不同大小的图像,卷积模块(卷积+非线性激活+池化)输出的特征映射维度是不一样的。而你提到的FCN、U-Net、SegNet,都是全卷积神经网络(fully convolutional neural network)。实际上,FCN的全称就是Full Convolutional Networks(全卷积网络)。这些网络用卷积层替换掉了全连接层,这就支持了任意大小的输入图像。
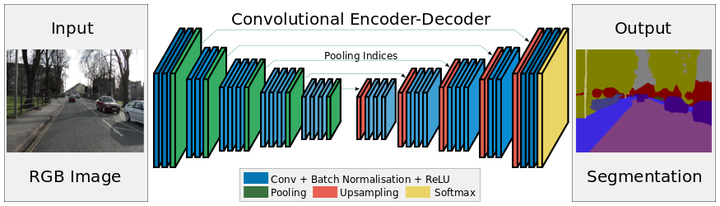
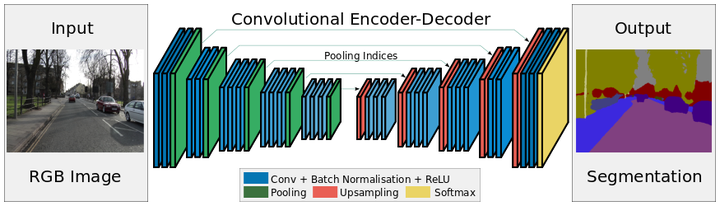 SegNet架构
SegNet架构
比如,上图为SegNet架构,可以看到,其中有卷积层、池化层、上采样层、Softmax层,就是没有FC(全连接)层。
顺便提下,要支持任意尺寸输入图像,全卷积神经网络不是唯一的选择。比如,可以用全局平均池化(Global Average Pooling)层替换全连接层(Inception-V3),或者在卷积模块和全连接层之间加一个空间金字塔池化(Spatial Pyramid Pooling)层,整理一下卷积模块的输出,再传给全连接层。
训练阶段,代码作者都将图片的输入尺寸固定了
这个并不是模型架构本身的限制,而是工程上的一些因素(比如,为了训练效率,同一mini-batch中的图像大小必须一样),或者说,是实现上的简单性。
通常情况下,你并不需要操心这个问题,因为这只是训练阶段。很多图像数据集中的图像都是统一的,即便不统一,你在传给网络前预处理一下也不是什么难事。这些模型架构确实具有支持任意尺寸图像的能力,但在训练阶段你不一定要利用这个能力。可以到测试阶段再发挥它支持任意尺寸图像的优势。
还有就是把batch大小改到1,也就是每次训练一张图像。比如,MXNet上的FCN实现FCN-xs就是这么干的,训练阶段的batch_size = 1。PyTorch上的FCN实现pytorch-fcn 和TensorFlow上的FCN实现tensor_fcn都可以将batch_size设为1,从而支持使用不同大小的图像进行训练。
理论上说,既然只是限制同一mini-batch大小都是一样,那么可以根据训练图像的不同大小进行分组,将相同大小的图像分到同一个mini-batch中进行训练。但是这比较复杂,因为据我所知主流框架的数据加载默认不支持这样的功能,可能需要自行实现(当然前提是defined-by-run框架,defined-and-run框架因为设计限制无法实现这样的功能)。
为何pytorch预训练的resnet模型对输入图片的大小无要求?
AdaptiveAvgPool2d
答:实际上就是当前的resnet实现已经使用了一个自适应池化层。

- Pytorch实现:torch.nn.AdaptiveAvgPool2d
CNN中如果图片的长宽差异太大会有什么影响呢?如果有怎么解决呢?
-
answer1:
仅就代码而言,没什么问题,总是能跑的。
不要padding ,差距50倍,padding 完了等于就是一个大黑方块中间一条细线,除了浪费算力什么也得不到。
这种情况最大的问题在于感受野会非常受限,一般图片通过多次下采样来增大感受野,一般是下采样三到四次。这样的话窄边的信息可能直接就采没了,经不起几次下采样。
但同时长边那么长,感受野只能覆盖一小截,太局限了,上下文信息不足,最终效果也不会好。要增大长边的感受野就得疯狂下采样,来个五六层比如,但窄边又不允许……所以确实是一个很尴尬的局面。
稍微联想一下,你这个问题和车道线检测其实非常类似,都是长长的带状分布,所以可以直接使用车道线检测的思路解决,也就是scnn:
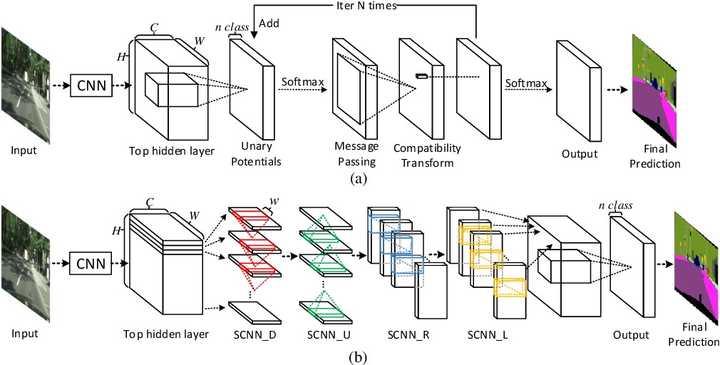
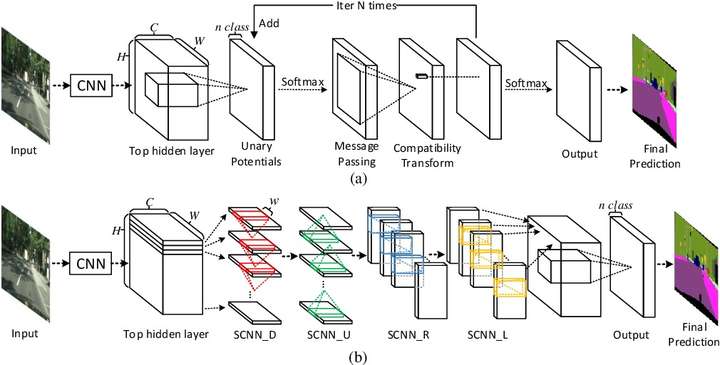
这篇文章解决的就是你这个问题,大概思路是从各个方向把信息融合在一起,充分的感受上下文信息,文章如下:
Spatial As Deep: Spatial CNN for Traffic Scene Understanding
Transformer是如何处理可变长度数据的?
占个坑吧,Transformer的知识点还是有点模糊不清。
在目标检测中如何解决小目标的问题?
在深度学习目标检测中,特别是人脸检测中,由于分辨率低、图像模糊、信息少、噪声多,小目标和小人脸的检测一直是一个实用和常见的难点问题。然而,在过去几年的发展中,也出现了一些提高小目标检测性能的解决方案。本文将对这些方法进行分析、整理和总结。
解决方案一:图像金字塔和多尺度滑动窗口检测
一开始,在深学习方法成为流行之前,对于不同尺度的目标,通常是从原始图像开始,使用不同的分辨率构建图像金字塔,然后使用分类器对金字塔的每一层进行滑动窗口的目标检测。
在著名的人脸检测器MTCNN中,使用图像金字塔法检测不同分辨率的人脸目标。然而,这种方法通常是缓慢的,虽然构建图像金字塔可以使用卷积核分离加速或简单粗暴地缩放,但仍需要做多个特征提取,后来有人借其想法想出一个特征金字塔网络FPN,在不同层融合特征,只需要一次正向计算,不需要缩放图片。
解决方案二:简单,粗暴和可靠的数据增强
通过增加训练集中小目标样本的种类和数量,也可以提高小目标检测的性能。有两种简单而粗糙的方法:
- 针对COCO数据集中含有小目标的图片数量较少的问题,使用过采样策略,即Oversampling;
- 针对同一张图片中小目标数量少的问题,使用分割mask切出小目标图像,然后使用复制和粘贴方法(当然,再加一些旋转和缩放)。
在Anchor策略方法中,如果同一幅图中有更多的小目标,则会匹配更多的正样本。与ground truth物体相匹配的不同尺度anchor示意图,小的目标匹配到更少的anchor。为了克服这一问题,我们提出通过复制粘贴小目标来人工增强图像,使训练过程中有更多的anchor与小目标匹配。
解决方案三:特征融合FPN
不同阶段的特征图对应不同的感受野,其所表达的信息抽象程度也不同。
浅层特征图感受野小,更适合检测小目标,深层特征图较大,更适合检测大目标。因此,有人提出将不同阶段的特征映射整合在一起来提高目标检测性能,称之为特征金字塔网络FPN。
- (a) 利用图像金字塔建立特征金字塔。特征的计算是在每个图像的尺度上独立进行的,这是很缓慢的。
- (b) 最近的检测系统选择只使用单一尺度的特征以更快地检测。
- (c) 另一种选择是重用由ConvNet计算出的金字塔特征层次结构,就好像它是一个特征图金字塔。
- (d)特征金字塔网络(FPN)如图所示,特征图用蓝色轮廓线表示,较粗的轮廓线表示语义上较强的特征。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号