
聊聊GAN
聊聊GAN
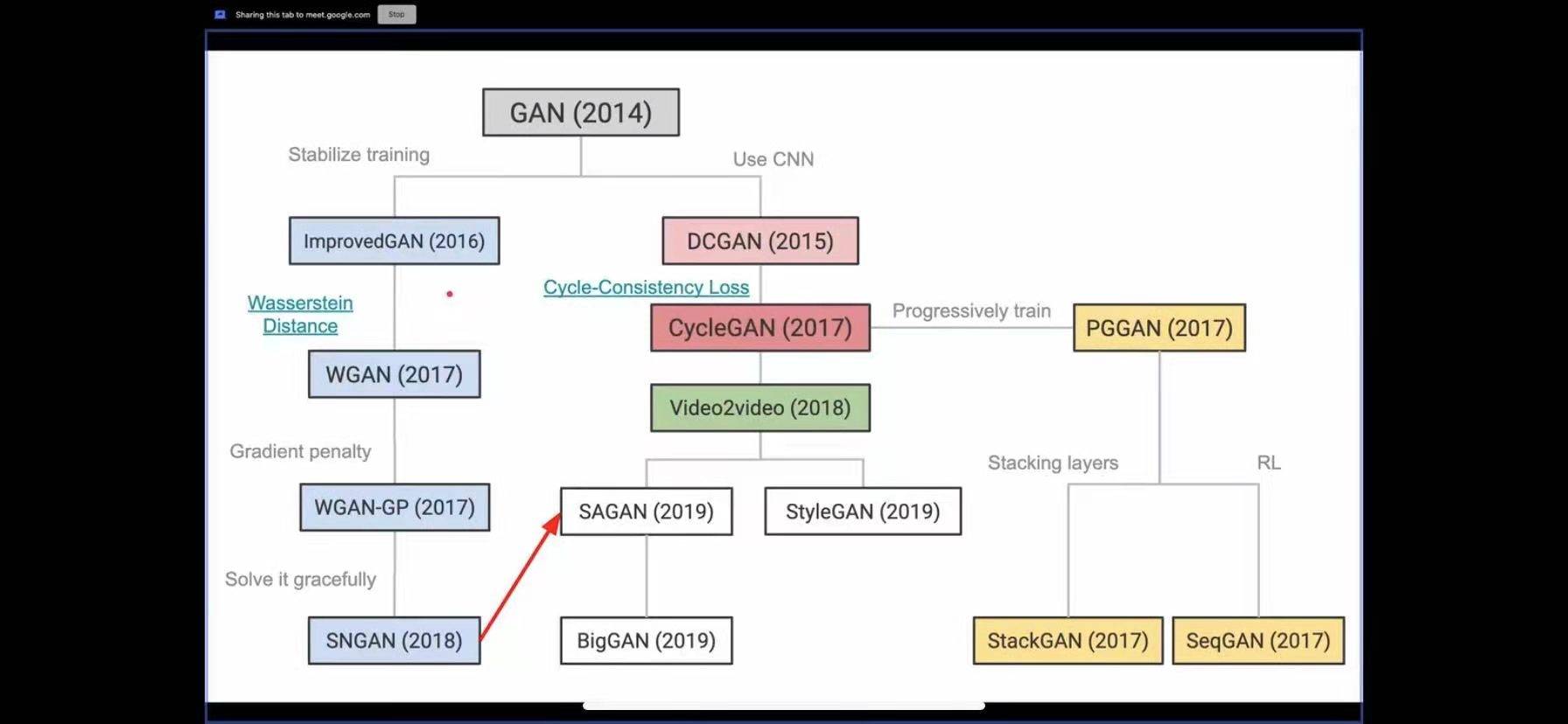
今天我们来说说GAN,这个被誉为新的深度学习的技术。由于内容非常多,我们会分上下两期。今天这一期是上,我们从以下几个方向来说。(1)生成式模型与判别式模型。(2)GAN的基本原理。(3)GAN的应用。同时也预告一下下期的内容,(1)GAN的优化目标,(2)GAN的模型发展(3)GAN的训练技巧。
生成式模型与判别式模型
正式说GAN之前我们先说一下判别式模型和生成式模型。
1.1 判别式模型
判别式模型,即Discriminative Model,又被称为条件概率模型,它估计的是条件概率分布(conditional distribution), p(class|context) 。
举个例子,我们给定(x,y)对,4个样本。(1,0), (1,0), (2,0), (2, 1),p(y|x)是事件x发生时y的条件概率,它的计算如下:
1.2 生成式模型
即Generative Model ,生成式模型 ,它估计的是联合概率分布(joint probability distribution),p(class, context)=p(class|context)*p(context) 。p(x,y),即事件x与事件y同时发生的概率。同样以上面的样本为例,它的计算如下:
1.3 常见模型
常见的判别式模型有Logistic Regression,Linear Regression,SVM,Traditional Neural Networks
Nearest Neighbor,CRF等。
常见的生成式模型有Naive Bayes,Mixtures of Gaussians, HMMs,Markov Random Fields等。
1.4 比较
判别式模型 ,优点是分类边界灵活 ,学习简单,性能较好 ;缺点是不能得到概率分布 。
生成式模型 ,优点是收敛速度快,可学习分布,可应对隐变量 ;缺点是学习复杂 ,分类性能较差。
上面是一个分类例子,可知判别式模型,有清晰的分界面,而生成式模型,有清晰的概率密度分布。生成式模型,可以转换为判别式模型,反之则不能。
1.5 酒后小故事
2014 年的一个晚上,Goodfellow 在酒吧给师兄庆祝博士毕业。一群工程师聚在一起不聊姑娘,而是开始了深入了学术探讨——如何让计算机自动生成照片。
当时研究人员已经在使用神经网络(松散地模仿人脑神经元网络的算法),作为“生成”模型来创建可信的新数据。但结果往往不是很好:计算机生成的人脸图像要么模糊到看不清人脸,要么会出现没有耳朵之类的错误。
针对这个问题,Goodfellow 的朋友们“煞费苦心”,提出了一个计划——对构成照片的元素进行统计分析,来帮助机器自己生成图像。
Goodfellow 一听就觉得这个想法根本行不通,马上给否决掉了。但他已经无心再party了,刚才的那个问题一直盘旋在他的脑海,他边喝酒边思考,突然灵光一现:如果让两个神经网络互相对抗呢?
但朋友们对这个不靠谱的脑洞深表怀疑。Goodfellow 转头回家,决定用事实说话。写代码写到凌晨,然后测试…
Ian Goodfellow:如果你有良好的相关编程基础,那么快速实现自己的想法将变得非常简单。几年来,我和我的同事一直在致力于软件库的开发,我曾用这些软件库来创建第一个 GAN、Theano 和 Pylearn2。第一个 GAN 几乎是复制-粘贴我们早先的一篇论文《Maxout Networks》中的 MNIST 分类器。即使是 Maxout 论文中的超参数对 GAN 也相当有效,所以我不需要做太多的新工作。而且,MNIST 模型训练非常快。我记得第一个 MNIST GAN 只花了我一个小时左右的时间。
GAN的基本原理
2.1基本原理
在GAN的原作中,作者将生成器比喻为印假钞票的犯罪分子,判别器则类比为警察。犯罪分子努力让钞票看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。那么类比于图像生成任务,生成器不断生成尽可能逼真的假图像。判别器则判断图像是否是真实的图像,还是生成的图像,二者不断博弈优化。最终生成器生成的图像使得判别器完全无法判别真假。
GAN,即Generative adversarial net,它同时包含判别式模型和生成式模型,一个经典的网络结构如下。
GAN的原理很简单,它包括两个网络,一个生成网络,不断生成数据分布。一个判别网络,判断生成的数据是否为真实数据。
2.2 优化目标与求解
下面是它的优化目标。
D是判别器,它的学习目标,是最大化上面的式子,而G是生成器,它的学习目标,是最小化上面的式子。上面问题的求解,通过迭代求解D和G来完成。
D的目标,是最大化损失函数V,对数函数log在底数大于1时,为单调递增函数,最大化V,就是最大化D(x) 和1-D(G(z))。那么对于任意的输入x,都有D(x)=1,对于任意的输入z,都有D(G(z)) = 0。
G的目标,是针对特定的D,去最小化损失函数V,就是最小化D(x) 和1-D(G(z)),它对于任意的输入z,都有D(G(z)) = 1。
在训练开始时,G性能较差,D(G(z))接近0,此时:log1-D(G(z)) 的梯度值较小。log(D(G(z)的梯度值较大,因此实践时可把G的目标改为最大化logD(G(z)),在早期学习中能提供更强的梯度。
要求解上面的式子,等价于求解下面的式子。
其中D(x)属于(0,1),上式是alog(y) + blog(1−y)的形式,取得最大值的条件是D(x)=a/(a+b),此时等价于下面式子。
如果用KL散度来描述,上面的式子等于下面的式子。
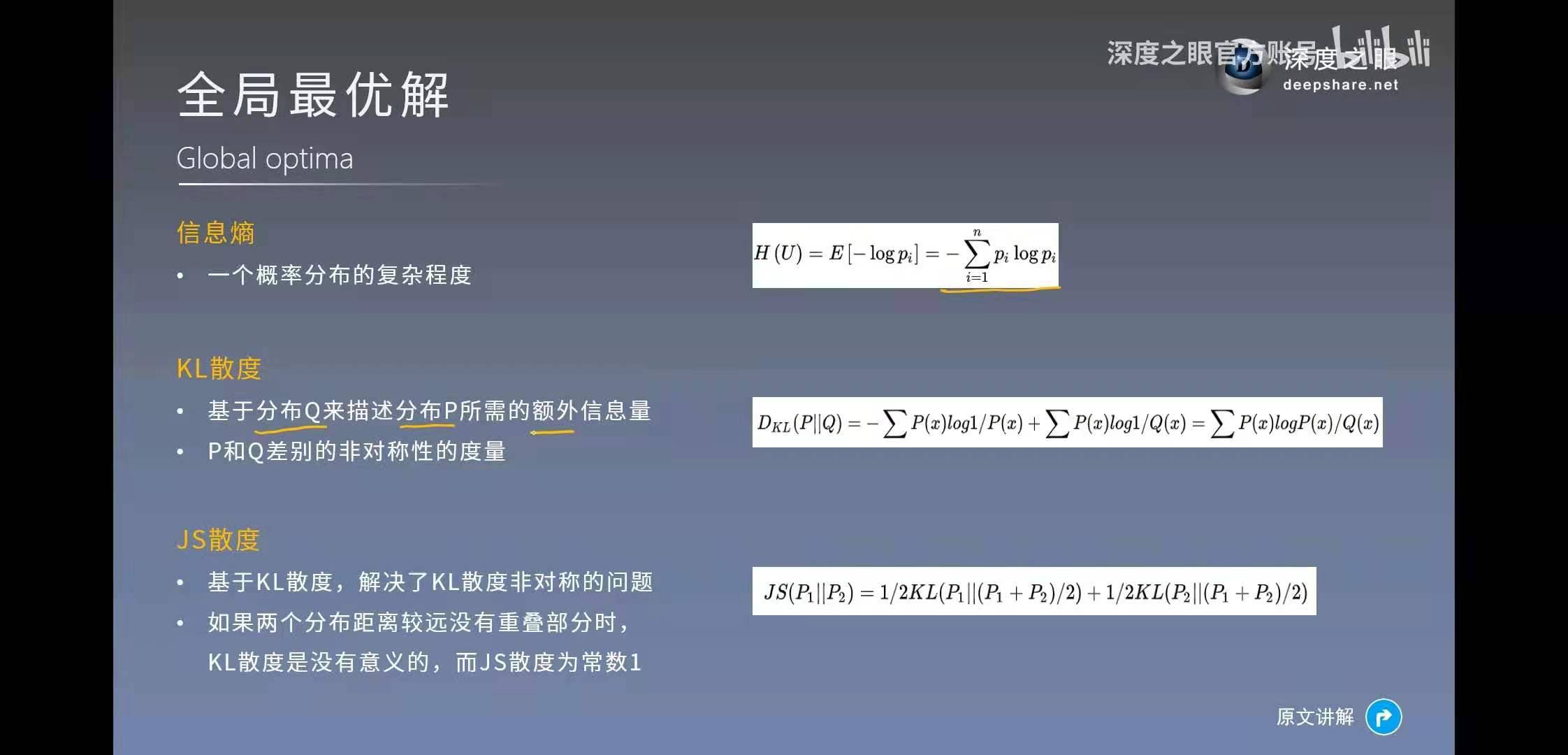
当且仅当pdata(x)=pg(x)时,取得极小值-log4,此时d=0.5,无法分辨真实样本和假样本。GAN从理论上,被证实存在全局最优解。至于KL散度,大家可以再去补充相关知识,篇幅有限不做赘述。
黑色:x_data的数据分布;
蓝色:判别器输出的值;
绿色: 生成器生成数据的分布;
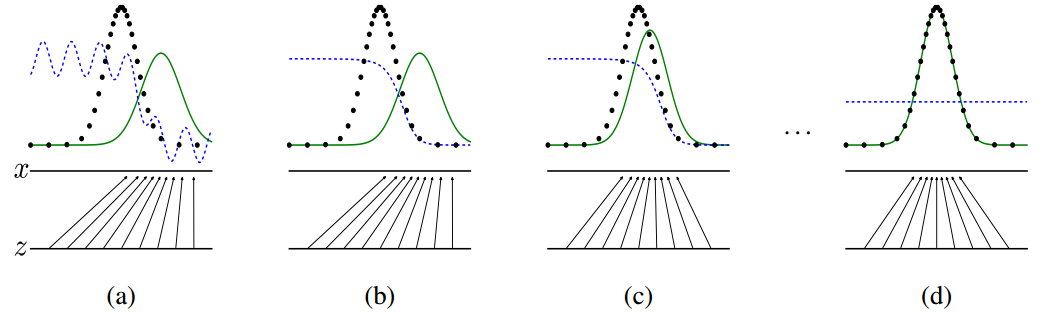

2.3 如何训练
import torch
import torch.nn as nn
from torchvision import transforms, datasets
from torch import optim as optim
import matplotlib
matplotlib.use('AGG')#或者PDF, SVG或PS
import matplotlib.pyplot as plt
import time
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
batch_size = 100
# MNIST dataset
dataset = datasets.MNIST(root='./data/', train=True, transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]), download=True)
# Data loader
dataloader = torch.utils.data.DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True)
print(f"Length of total dataset = {len(dataset)}, \nLength of dataloader with having batch_size of {batch_size} = {len(dataloader)}")
dataiter = iter(dataloader)
images,labels = dataiter.next()
print(torch.min(images),torch.max(images))
class GeneratorModel(nn.Module):
def __init__(self):
super(GeneratorModel, self).__init__()
input_dim = 100
output_dim = 784
# <----------D和G的非输出层激活函数都是LeakyReLU()函数--------->
self.hidden_layer1 = nn.Sequential(
nn.Linear(input_dim, 256),
nn.LeakyReLU(0.2)
)
self.hidden_layer2 = nn.Sequential(
nn.Linear(256, 512),
nn.LeakyReLU(0.2)
)
self.hidden_layer3 = nn.Sequential(
nn.Linear(512, 1024),
nn.LeakyReLU(0.2)
)
# <----------G的最后一层激活函数是Tanh()函数--------->
self.hidden_layer4 = nn.Sequential(
nn.Linear(1024, output_dim),
nn.Tanh()
)
def forward(self, x):
output = self.hidden_layer1(x)
output = self.hidden_layer2(output)
output = self.hidden_layer3(output)
output = self.hidden_layer4(output)
return output.to(device)
class DiscriminatorModel(nn.Module):
def __init__(self):
super(DiscriminatorModel, self).__init__()
input_dim = 784
output_dim = 1
self.hidden_layer1 = nn.Sequential(
nn.Linear(input_dim, 1024),
nn.LeakyReLU(0.2),
nn.Dropout(0.3)
)
self.hidden_layer2 = nn.Sequential(
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Dropout(0.3)
)
self.hidden_layer3 = nn.Sequential(
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Dropout(0.3)
)
# <----------D的最后一层激活函数是Sigmoid()函数--------->
self.hidden_layer4 = nn.Sequential(
nn.Linear(256, output_dim),
nn.Sigmoid()
)
def forward(self, x):
output = self.hidden_layer1(x)
output = self.hidden_layer2(output)
output = self.hidden_layer3(output)
output = self.hidden_layer4(output)
return output.to(device)
discriminator = DiscriminatorModel()
generator = GeneratorModel()
discriminator.to(device)
generator.to(device)
print(generator,"\n\n\n",discriminator)
# <----------交叉熵损失函数---------->
criterion = nn.BCELoss()
# <----------Adam优化器---------->
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0002)
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0002)
num_epochs = 100
batch = 100
outputs=[]
# Losses & scores
losses_g = []
losses_d = []
real_scores = []
fake_scores = []
for epoch_idx in range(num_epochs):
start_time = time.time()
for batch_idx, data_input in enumerate(dataloader):
real = data_input[0].view(batch, 784).to(device) # batch_size X 784
batch_size = data_input[1] # batch_size
noise = torch.randn(batch,100).to(device)
fake = generator(noise) # batch_size X 784
disc_real = discriminator(real).view(-1)
lossD_real = criterion(disc_real, torch.ones_like(disc_real))
disc_fake = discriminator(fake).view(-1)
lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake))
# <----------D_loss是lossD_real+lossD_fake的和---------->
lossD = (lossD_real + lossD_fake) / 2
real_score = torch.mean(disc_real).item()
fake_score = torch.mean(disc_fake).item()
d_optimizer.zero_grad()
lossD.backward(retain_graph=True)
d_optimizer.step()
gen_fake = discriminator(fake).view(-1)
# <----------G_loss是使向D输入fake_img,输出的值向1靠近--------->
lossG = criterion(gen_fake, torch.ones_like(gen_fake))
g_optimizer.zero_grad()
lossG.backward()
g_optimizer.step()
print('Epochs [{}/{}] & Batch [{}/{}]: loss_d: {:.4f}, loss_g: {:.4f}, real_score: {:.4f}, fake_score: {:.4f}, took time: {:.0f}s'.format(
(epoch_idx+1), num_epochs, batch_idx+1, len(dataloader),lossD,lossG,real_score,fake_score,time.time()-start_time))


2.4 训练技巧
1. Normalize the inputs
- normalize the images between -1 and 1
- Tanh as the last layer of the generator output
2. A modified G's loss function
- In GAN papers, the loss function to optimize G is
min (log 1-D), but in practice folks practically usemax log D,because the first formulation has vanishing gradients early on.
3. Use a spherical Z
- Don't sample from a Uniform distribution. Sample from a gaussian distribution.
4. BatchNorm
5. Avoid Sparse Gradients: ReLU, MaxPool
- LeakyReLU = good (in both G and D).
- For Downsampling, use: Average Pooling, Conv2d + stride
- For Upsampling, use: PixelShuffle, ConvTranspose2d + stride PixelShuffle介绍
6. Use the ADAM Optimizer
- Use SGD for discriminator and ADAM for generator
- optim.Adam rules. See Radford et. al. 2015
7. Track failures early
- D loss goes to 0: failure mode
- when things are working, D loss has low variance and goes down over time Vs having huge variance and spiking
- if loss of generator steadily decreases, then it's fooling D with garbage (says martin)
-
-
-
8.Dont balance loss via statistics (unless you have a good reason to)
- Don‘t try to find a (number of G / number of D) schedule to uncollapse training
- It's hard and we've all tried it.
- If you do try it, have a principled approach to it, rather than intuition
while lossD > A:
train D
while lossG > B:
train G
9. Use the ADAM Optimizer
- Add some artificial noise to inputs to D
- adding gaussian noise to every layer of generator
10. Use Dropouts in G in both train and test phase
- Apply on several layers of our generator at both training and test time
2.5 GAN的主要问题
GAN从本质上来说,有与CNN不同的特点,因为GAN的训练是依次迭代D和G,如果判别器D学的不好,生成器G得不到正确反馈,就无法稳定学习。如果判别器D学的太好,整个loss迅速下降,G就无法继续学习。
GAN的优化需要生成器和判别器达到纳什均衡,但是因为判别器D和生成器G是分别训练的,纳什平衡并不一定能达到,这是早期GAN难以训练的主要原因。另外,最初的损失函数也不是最优的。
https://hub.fastgit.org/soumith/ganhacks)
GAN的模型发展
2.1 CGAN
2.1.1 CGAN-条件GAN 论文链接
条件GAN,网络结构如下:
它将标签信息encode为一个向量,串接到了D和G的输入进行训练,优化目标发生了改变。Loss设计和原始GAN基本一致,只不过生成器,判别器的输入数据是一个条件分布。在具体编程实现时只需要对随机噪声采样z和输入条件y做一个级联即可。
关于CGAN,可以重看一下这篇知乎专栏 生成对抗网络GAN(二):Conditional Generation 条件生成网络的理解与算法流程
Conditional GAN, 除了输入这个sample出来的向量, 还有一个c(条件标签)。
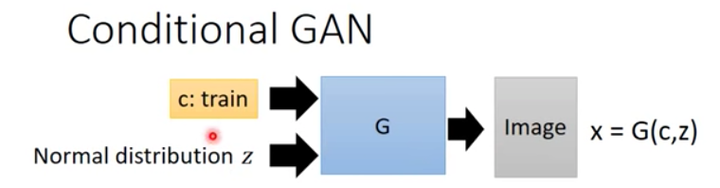
而Discriminator也需要做一些改进,之前的传统的Discriminator,它的任务是检查照片是否真实就可以了,不用去关注图片的内容。因此在conditional GAN里面, discriminator也多了一个输入"c", 代表的是图片的内容。这个时候的discriminator不仅仅要检查图片是否真实,还需要检查c和输入的图片x是不是匹配的。

从网络结构图可以看到,对于生成器Generator,其输入不仅仅是随机噪声的采样z,还有欲生成图像的标签信息。比如对于mnist数据生成,就是一个one-hot向量,某一维度为1则表示生成某个数字的图片。同样地,判别器的输入也包括样本的标签。这样就使得判别器和生成器可以学习到样本和标签之间的联系。
2.1.2 Conditional GAN算法流程
discriminator部分:
-
从数据集中sample出m个正例
-
从一个分布中sample出m个噪声点
-
通过
生成数据
-
再从数据集里面sample出m个样本点
-
更新discriminator的参数
来最大化
:
这个优化过程跟之前的传统GAN的求解过程的差别在于, 多了一项 , 这个
我们前面提到了也是从数据集里面取出来的图片。其实就是说,这个
,不但要求图片真实,而且图片真实的条件下还得和输入文字匹配才能给高分,否则都给低分。
2.2 WGAN
WGAN - Martin Arjovsky, arXiv:1701.07875v1
WGAN: 在初期一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
为啥难训练? 令人拍案叫绝的Wasserstein GAN 中做了如下解释 : 原始GAN不稳定的原因就彻底清楚了:判别器训练得太好,生成器梯度消失,生成器loss降不下去;判别器训练得不好,生成器梯度不准,四处乱跑。只有判别器训练得不好不坏才行,但是这个火候又很难把握,甚至在同一轮训练的前后不同阶段这个火候都可能不一样,所以GAN才那么难训练。
WGAN 针对loss改进,在代码实现上来说.只改了4点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
2.3 ACGAN
Auxiliary Classifier GAN (CGAN) 分类加生成


上面第一张是 CGAN 的训练模式,第二张是 ACGAN 的模式,他们的不同点具体体现在 Discriminator 上:
- CGAN 的 Discriminator 需要同时接收标签和图片信息,输出是否真实的结论
- ACGAN 的 Discriminator 只需要接收图片的输入,这点和经典GAN一样,但是需要输出图片的类别和是否真实两个任务。
- 分类 - 是否是真实图片
- 分类 - 这张图属于哪一个类别
这样做的好处,除了可以用预训练模型,还有一点。是给判别器更多的标签数据,让判别器可以做更好的监督学习。在单独看类别信息的话, 实际上这种类别信息会先被生成器给压缩一遍,然后再被判别器解压出来,一来一回, 就像是一个 AutoEncoder 的非监督学习。

ACGAN 通过类似于 AutoEncoder 的非监督模式,将标签信息融入到了 压缩 - 解压 的过程, 让模型学习到标签类别的内在含义。
2.4 DCGAN
Deep Convolution Generative Adversarial Networks(深度卷积生成对抗网络)
前面我们聊的GAN都是基于简单的神经网络构建的。可是对于视觉问题,如果使用原始的基于DNN的GAN,则会出现许多问题。如果输入GAN的随机噪声为100维的随机噪声,输出图像为256x256大小。也就是说,要将100维的信息映射为65536维。整个模型参数会非常巨大,而且学习难度很大(低维度映射到高维度需要添加许多信息)。因此,DCGAN就出现了。
Alec Radford & Luke Metz提出使用 CNN 结构来稳定 GAN 的训练,并使用了以下一些 trick:
- 将pooling层convolutions替代,其中,在discriminator上用strided convolutions替代,在generator上用fractional-strided convolutions替代。
- 在generator和discriminator上都使用Batch Normalization。
- 移除全连接层,global pooling增加了模型的稳定性,但伤害了收敛速度。
- 在generator的除了输出层外的所有层使用ReLU,输出层采用tanh。
- 在discriminator的所有层上使用LeakyReLU。
上面这些 trick 对于稳定 GAN 的训练有许多帮助。
这是CNN在unsupervised learning领域的一次重要尝试,这个架构能极大地稳定GAN的训练,以至于它在相当长的一段时间内都成为了GAN的标准架构,给后面的探索开启了重要的篇章。

2.5 BigGAN
BigGAN — Brock et al. (2019) Large Scale GAN Training for High Fidelity Natural Image Synthesis”
BigGAN模型是基于ImageNet生成图像质量最高的模型之一。BigGAN作为GAN发展史上的重要里程碑,将精度作出了跨越式提升。在ImageNet (128x128分辨率)训练下,将IS从52.52提升到166.3,FID从18.65降到9.6。 该模型很难在本地机器上实现,而且BigGAN有许多组件,如Self-Attention、 Spectral Normalization和带有投影鉴别器的cGAN,这些组件在各自的论文中都有更好的解释。不过,这篇论文对构成当前最先进技术水平的基础论文的思想提供了很好的概述,论文贡献包括,大batchsize,大channel数,截断技巧,训练平稳性控制等。(暴力出奇迹)
这篇文章提供了 128、256、512 的自然场景图片的生成结果。 自然场景图片的生成可是比 CelebA 的人脸生成要难上很多。
GAN应用
3.1 图像翻译 (Image Translation)
图像翻译,指从一副(源域)输入的图像到另一副(目标域)对应的输出图像的转换。它代表了图像处理的很多问题,比如灰度图、梯度图、彩色图之间的转换等。可以类比机器翻译,一种语言转换为另一种语言。翻译过程中会保持源域图像内容不变,但是风格或者一些其他属性变成目标域。
| Title | Co-authors | Publication | Links |
|---|---|---|---|
| Pix2Pix | Zhu & Park & et al. | CVPR 2017 | demo code paper |
| Pix2Pix HD | NVIDIA UC Berkeley | CVPR 2018 | paper code |
| SPADE | Nvidia | 2019 | paper code |
| CoupledGan | 2016 | paper code | |
| DTN | 2017 | paper code | |
| CycleGan | 2017 | code paper | |
| DiscoGan | 2017 | paper | |
| DualGan | 2017 | paper | |
| UNIT | 2017 | ||
| XGAN | 2018 | ||
| OST | 2018 | ||
| FUNIT | ICCV 2019 | paper code demo |
3.2 Pix2Pix
针对pix2pix,这篇文章讲得挺透彻的。链接
3.2.1 缺点
- 没有用户控制(user control)能力 在传统的GAN里,输入一个随机噪声,就会输出一幅随机图像。但用户是有想法滴,我们想输出的图像是我们想要的那种图像,和我们的输入是对应的、有关联的。比如输入一只猫的草图,输出同一形态的猫的真实图片(这里对形态的要求就是一种用户控制)。
- 低分辨率(Low resolution)和低质量(Low quality)问题 尽管生成的图片看起来很不错,但如果你放大看,就会发现细节相当模糊。
3.2.2 算法思想
- Pix2Pix对传统的CGAN做了个小改动,它不再输入随机噪声,而是输入用户给的图片:
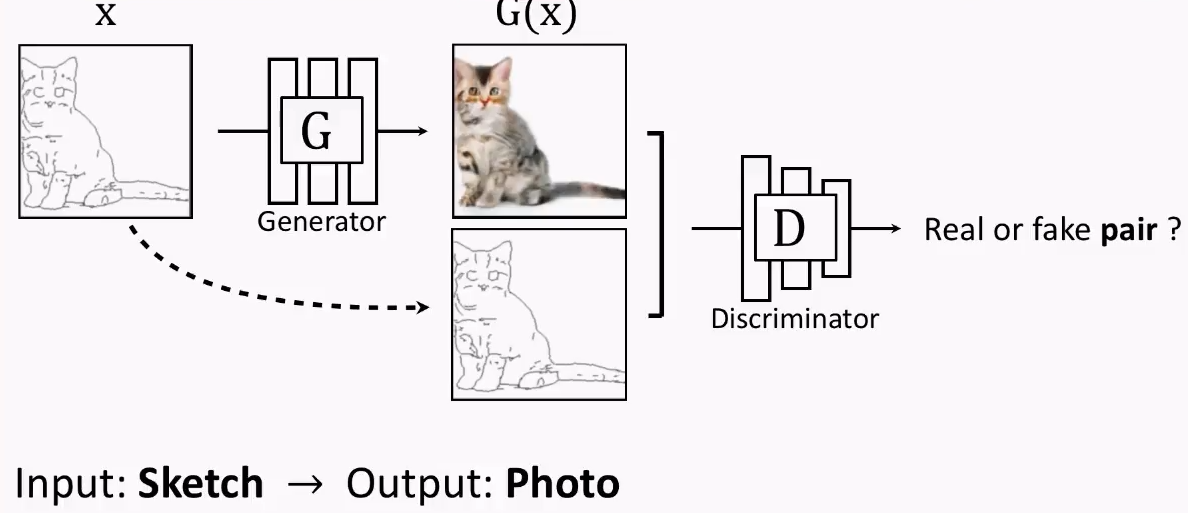 \img\ch7\pix2pix模型示意图.png)
\img\ch7\pix2pix模型示意图.png)
上图模型和CGAN有所不同,但它是一个CGAN,只不过输入只有一个,这个输入就是条件信息。原始的CGAN需要输入随机噪声,以及条件。这里之所有没有输入噪声信息,是因为在实际实验中,如果输入噪声和条件,噪声往往被淹没在条件C当中,所以这里直接省去了。
- 提出基于"U-Net + PatchGAN"的框架来良好地完成多种图像翻译任务。
3.2.3 损失函数
生成器的Loss除了上文cGAN中包含的损失之外, 还外加了L1-Loss,这样生成器的目标不单单是迷惑判别器, 同时还要保证输出图片在一定程度上接近grond-truth.
为什么要用patchGAN呢? patchGAN最先提出是2016年在 MGANs中( Markovian Generative Adversarial Net-works), 实际上就是Markovian discriminator。生成器中已经用到了L1重建损失, 那么判别器是不是只需要像普通的做法一样对整张图片做真/伪的二分类就好了呢? 首先, L1、L2损失只能够保证低频上的准确性, 而对于高频就不行了。为什么呢? 因为通常的L1、L2损失是对整张图片来做的, 它的粒度就是整个图片, 导致它的效果就是"生成的图片和目标图片整体上接近就好啦"。作者决定在判别器上下功夫: 既然你L1损失已经负责了生成图像在低频上的真实性, 那么我只需要让判别器负责高频部分就好啦。
其次, 如何通过判别器保证生成图片在高频真实性? 简单! 让判别器粒度更细就好了! 这就是patchGAN的核心思想。 实现上也很简单, 就是把输入图片分成多个NxN的小patch (N可以远小于原始图像尺寸) , 然后对每一个patch进行判别器的真伪判断, 当然不同patch是可以通过channel来并行的。这样的操作实际上是蕴含了一个假设: 超过一个patch之间的像素点是独立的。 是不是很熟悉? 这就是马尔科夫性, 这样做就相当于判别器对切分得到的小图片块按照Markov random field来建模! 考虑到patchGAN的高频/局部性, 它可以理解为一种对于纹理/细致风格(texture/style) 上的损失。 同时作者也提到如果对高频要求不高, 传统的L1损失其实也可以达到一个ok 的效果。
最后, patchGAN除了达到细粒度的目的外, 它还有一个很大的优点: 参数量大大减少同时速度提升, 并且可以处理任意大小的图像输入!
论文里只说了用了L2损失比L1损失生成的图片更加模糊,没有给出原因。这里猜测可能的原因是L1损失函数稳健性强更强一些。面对误差较大的观测,L1损失函数不容易受到它的影响。这是因为:L1损失函数增加的只是一个误差,而L2损失函数增加的是误差的平方。当误差较大时,使用L2损失函数,我们需要更大程度的调整模型以适应这个观测,所以L2损失函数没有L1损失函数那么稳定。
3.3 CycleGAN
对于无成对训练数据的图像翻译问题,一个典型的例子是 CycleGAN。CycleGAN 使用两对 GAN,将源域数据通过一个 GAN 网络转换到目标域之后,再使用另一个 GAN 网络将目标域数据转换回源域,转换回来的数据和源域数据正好是成对的,构成监督信息。
CycleGan是让两个domain的图片互相转化。传统的GAN是单向生成,而CycleGAN是互相生成,一个A→B单向GAN加上一个B→A单向GAN,网络是个环形,所以命名为Cycle。理念就是,如果从A生成的B是对的,那么从B再生成A也应该是对的。CycleGAN输入的两张图片可以是任意的两张图片,也就是unpaired。
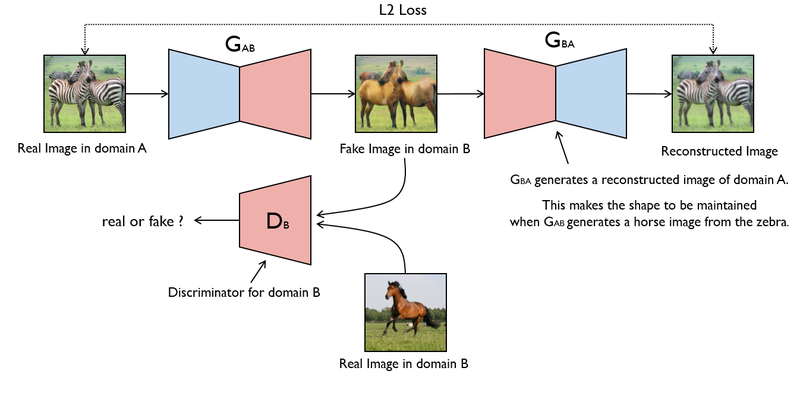
CycleGAN的生成器采用U-Net,判别器采用LS-GAN。
Loss设计
总的Loss就是X域和Y域的GAN Loss,以及Cycle consistency loss:
整个过程End to end训练,效果非常惊艳,利用这一框架可以完成非常多有趣的任务。
大佬们的实验
Avinash Hindupur建了一个GAN Zoo,他的“动物园”里目前已经收集了近500种有名有姓的GAN。 主要是2014-2018年之间的GAN。 the-gan-zoo
那么问题来了:这么多变体,有什么区别?哪个好用?
于是,Google Brain的几位研究员对各种进行了loss,参数,权重修改的GAN做一次“中立、多方面、大规模的”评测。 在此项研究中,Google此项研究中使用了minimax损失函数和用non-saturating损失函数的GAN,分别简称为MM GAN和NS GAN,对比了WGAN、WGAN GP、LS GAN、DRAGAN、BEGAN,另外还对比的有VAE(变分自编码器)。为了很好的说明问题,研究者们两个指标来对比了实验结果,分别是FID和精度(precision)、召回率(recall)以及两者的平均数F1。
其中FID(Fréchet distance(弗雷歇距离) )是法国数学家Maurice René Fréchet在1906年提出的一种路径空间相似形描述,直观来说是狗绳距离:主人走路径A,狗走路径B,各自走完这两条路径过程中所需要的最短狗绳长度,所以说,FID与生成图像的质量呈负相关。
为了更容易说明对比的结果,研究者们自制了一个类似mnist的数据集,数据集中都是灰度图,图像中的目标是不同形状的三角形。
最后,他们得出了一个有点丧的结论:
No evidence that any of the tested algorithms consistently outperforms the original one. :
都差不多……都跟原版差不多……
《Are GANs Created Equal? A Large-Scale Study》论文PDF
这些改进是否一无是处呢?当然不是,之前的GAN 训练很难, 而他们的优点,主要就是让训练变得更简单了。
那对于GAN这种无监督学习的算法,不同的模型结构改进,和不同的应用领域,才是GAN大放异彩的地方。
此外,谷歌大脑发布了一篇全面梳理 GAN 的论文,该研究从损失函数、对抗架构、正则化、归一化和度量方法等几大方向整理生成对抗网络的特性与变体。 作者们复现了当前最佳的模型并公平地对比与探索 GAN 的整个研究图景,此外研究者在 TensorFlow Hub 和 GitHub 也分别提供了预训练模型与对比结果。 论文链接
原名:The GAN Landscape: Losses, Architectures, Regularization, and Normalization
现名:A Large-Scale Study on Regularization and Normalization in GANs
Github:http://www.github.com/google/compare_gan
TensorFlow Hub:http://www.tensorflow.org/hub
翻译参见 https://www.tongtianta.site/paper/32758
GAN的很多研究,都是对Generative modeling生成模型的一种研究,主要有两种重要的工作
1 Density Estimation 对原有数据进行密度估计,建模,然后使用模型进行估计
2 Sampling 取样,用对数据分布建模,并进行取样,生成符合原有数据分布的新数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号