Python中堆是一种基于二叉树存储的数据结构。
主要应用场景:
对一个序列数据的操作基于排序的操作场景,例如序列数据基于最大值最小值进行的操作。
堆的数据结构:
Python 中堆是一颗平衡二叉树(关于二叉树参考数据结构相关知识),且基于小堆进行存储。
何为小堆,简单的说就是根节点永远不大于子节点的一种存储树,如下所示:
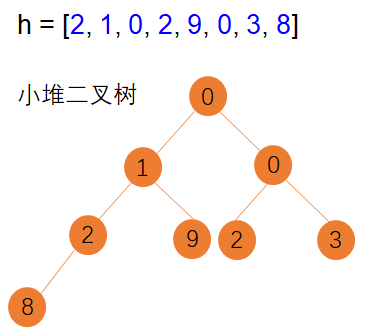
为何会形成图示的二叉树,这跟二叉树的存储及翻转规则有关,比较复杂,如果感兴趣,可查阅数据结构相关知识。
特性:
(1)堆的数据要基于链表(List)进行操作(堆中的数据是基于链表进行操作)。
(2)堆直接基于链表操作,不再开辟新的存储空间。
(3)堆头永远都是最小的值。
(4)堆的检索是根据中序遍历方式:根节点 --> 左节点 -->右节点
常用方法:
1 import heapq 2 3 # (1)创建一个空堆,并加入数据 4 heap = [] 5 for item in [2, 3, 1, 4]: 6 heapq.heappush(heap, item) 7 print heap # 输出 [1, 3, 2, 4] 8 9 # (2)根据链表构建一个堆 --> heapify 10 l = [2, 3, 1, 4] 11 heapq.heapify(l) 12 print l # 输出 [1, 3, 2, 4] 13 14 # (2)向堆中追加元素 -->heappush 15 heapq.heappush(l, -10) 16 print l # 输出 [-10, 1, 2, 4, 3] 17 18 # (3) 弹出堆头(返回堆头之后堆再进行翻转,堆头保持最小值) -->heappop 19 print heapq.heappop(l) # 输出 -10 20 print l # 输出 [1, 3, 2, 4] 21 print heapq.heappop(l) # 输出 1 22 print l # 输出 [2, 3, 4] 23 24 # (4) 替换第一个元素,并构建堆 --> heapreplace 25 l = [2, 3, 1, 4] 26 print heapq.heapreplace(l, 100) # 输出 2 27 print l # 输出 [1, 3, 100, 4] 28 29 # (5)合并多个链表 --> merge 30 l = [1, 3, 2] 31 l2 = [5, 2, 3] 32 l3 = [9, 2, 3, 1] 33 print list(heapq.merge(l, l2, l3)) # 输出 [1, 3, 2, 5, 2, 3, 9, 2, 3, 1] 34 35 # (6)多路归并 --> merge 36 # 对每一个链表进行排序,再对排序后的列表进行合并 37 print list(heapq.merge(sorted(l), sorted(l2), sorted(l3))) 38 39 # (7)返回最大的元素 --> nlargest 40 l = [2, 3, 1, 4] 41 print heapq.nlargest(2, l) # 输出 [4, 3] 42 43 # (8)返回最小的元素 --> nsmallest 44 l = [2, 3, 1, 4] 45 print heapq.nsmallest(2, l) # 输出 [1, 2] 46 47 # (9)向堆中追加一个数据,再弹出堆头(弹出后堆不会发生翻转) --> heappushpop 48 l = [2, 3, 1, 4] 49 print heapq.heappushpop(l, -10) # 输出 -10 50 print l # 输出 [2, 3, 1, 4]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号