
进程管理
进程管理
进程概述
什么是进程:
执行中的程序称作进程。当程序可以执行文件存放在存储中,并且运行的时候,每个进程会被动态得分配系统资源、内存、安全属性和与之相关的状态。可以有多个进程关联到同一个程序,并同时执行不会互相干扰。操作系统会有效地管理和追踪所有运行着的进程。
- 当程序运行为进程后,系统会为该进程分配内容,以及运行的身份和权限
- 在进程运行的过程中,服务器上会有各种状态表现当前进程的指标信息
进程与程序的区别:
- 程序是数据和指令的集合,是一个动态的概念。比如/bin下面的命令,可以长期存在系统中。
- 进程是一个程序的运行过程,是一个动态概念,进程是存在生命周期概念的,也就是说进程会随着程序的终止而销毁,不会永远在系统中存在
进程的生命周期:
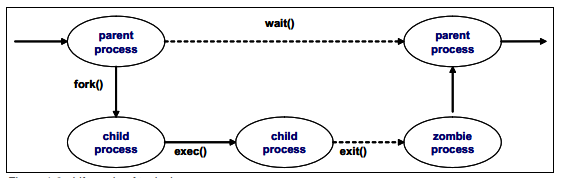
-
正常结束任务:
- 父进程接收任务>>通过fork派生子进程处理(继承父进程的属性)>>子进程在处理任务代码时父进程进入等待状态中>>子进程在处理任务代码后会执行退出,唤醒父进程来回收子进程的资源.
-
非正常结束任务时
-
僵尸进程:子进程退出,而父进程并没有调用 wait 或 waitpid 获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵死进程。
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。孤儿进程将被 init 进程(进程号为1)所收养,并由 init 进程对它们完成状态收集工作。
-
每个进程都会有自己的PID号.
监控进程的状态
进程状态管理命令-ps
ps是Linux 中最基础的浏览系统中的进程的命令。能列出系统中运行的进程,包括进程号、命令、CPU使用量、内存使用量等
ps [选项][参数]
用法:
[root@localhost ~]# ps -ef
[root@localhost ~]# ps aux
a:查看所有与终端相关的进程,由终端发起的进程
u:显示进程的管理用户
x:查看所有与终端无关的进程
[root@localhost ~]# ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME
root 1 3.0 0.6 127892 6508 ? Ss 17:00 0:02
COMMAND
/usr/lib/systemd/systemd --switched-root --system --deserialize 22
USER: //启动程序的用户
PID: //进程ID
%CPU: //占用CPU的百分比
%MEM: //占用内存的百分比
VSZ: //虚拟内存集(进程占用虚拟内存的空间)
RSS: //物理内存集(进程占用物理内存的空间)
TYY: //运行的终端
?: #内核运行的终端
tty1: #机器运行的终端
pts/0:#远程连接的终端
STAT: //进程状态
D: #无法中断的休眠状态(通IO的进程)
R: #正常运行的状态
S: #处于休眠的状态
T: #暂停或被追踪的状态
W: #进入内存交换(从内核2.6开始无效)
X: #死掉的进程(少见)
Z: #僵尸进程
<: #优先级较高的进程
N: #优先级较低的进程
L: #有些页被锁进内存
S: #父进程(在它之下有子进程开启着)
l: #以线程的方式运行
|: #多进程的
+: #该进程运行在前台
START: //该进程被触发开启的时间
TIME: //该进程实际使用CPU运行时间
COMMAND: //命令的名称和参数
[]: #内核态的进程
没[]: #用户态的进程
案例:PS命令查看前台进程转换到停止
#在终端上运行vim
[root@localhost ~]# vim 1.txt
#查看vim运行的状态,S:睡眠状态 +:在前台运行
[root@localhost ~]# ps aux|grep [v]im
root 1306 0.0 0.2 151664 5180 pts/0 S+ 13:00 0:00 vim 1.txt
#执行ctrl + z,将进程放置后台
[1]+ 已停止 vim 1.txt
#进程状态变成了T,暂停或被追踪的状态
[root@zls ~]# ps aux|grep [v]im
root 1306 0.0 0.2 151664 5180 pts/0 T 13:00 0:00 vim 1.txt
## 查看所有被暂停的进程
[root@web01 ~]# jobs
[1]- Stopped vim1.txt
[2]+ Stopped ping baidu.com
bg:让暂停的进程运行起来,后面加数字,就可以运行第几个被暂停的进程(默认是最后一个)
fg:是把后台暂停的进程,调到前台运行,后面加数字,可以将第N个进程调到前台运行(默认是最后一个)
ps aux | grep '[n]ginx 命令中 [] 的作用
1.通常情况下,我们总是会结合使用 ps 和 grep 的方式来筛选出只包含某个进程名的那些行,比如: ps aux | grep nginx.
2.最后结果会最后一行会显示
root 29249 0.0 0.1 11744 920 pts/0 S+ 23:15 0:00 grep --color=auto nginx
就是我们的 grep 命令本身的命令行。 因为它的命令行中也包含了被筛选的内容(nginx),所以自然也会被包含进来。
3.所以怎么去掉?先说答案,像下面这样即可: ps aux | grep '[n]ginx'
4.grep(全局正则表达式打印,Global Regular Expression Print),是一种正则表达式模式匹配工具:用于搜索/匹配内容,并打印出匹配的内容。[n] 这个模式在正则表达式中的含义是:中括号中的字符 n 必须出现一次。那么 grep '[n]ginx' 的含义是:在结果中搜索匹配 nginx 这个字符串。 因此就含义本身而言,grep '[n]ginx' 整体的含义等价于 grep nginx。
5.为什么要加单引号?
单引号可以避免 bash 做路径名展开
ps命令的使用方法:
#对进程的CPU进行排序展示
[root@localhost ~]# ps aux --sort %cpu |less
#对进程的占用物理内存排序
[rootlocalhost ~]# ps aux --sort rss |less
#排序,是在记不住,那就自己排序
[root@localhost ~]# ps aux|sort -k3 -n
#自定义显示字段
[root@localhost ~]# ps axo user,pid,ppid,%mem,command |grep sshd
root 869 1 0.2 /usr/sbin/sshd -D
root 1194 869 0.2 sshd: root@pts/0
root 1307 869 0.2 sshd: root@pts/1
root 1574 869 0.2 sshd: root@pts/2
#显示进程的子进程
[rootlocalhost ~]# yum install nginx -y
[rootlocalhost ~]# systemctl start nginx
[root@localhost ~]# ps auxf|grep [n]ginx
root 2033 0.0 0.1 125096 2112 ? Ss 13:29 0:00 nginx: master process /usr/sbin/nginx
nginx 2034 0.0 0.1 125484 3148 ? S 13:29 0:00 \_ nginx: worker process
#查看指定进程PID
[root@localhost ~]# ps aux|grep sshd
root 1157 0.0 0.1 105996 3604 ? Ss Feb27 0:00 /usr/sbin/sshd -D
[root@localhost ~]# cat /run/sshd.pid
1157
pgrep的意思是"进程号全局正则匹配输出"。该命令扫描当前运行进程,然后按照命令匹配条件列出匹配结果到标准输出。对于通过名字检索进程号是很有用。
#pgrep常用参数, -l -a
-l:显示该进程的启动命令
-a:显示该进程的完整描述信息
[root@localhost ~]# pgrep sshd
869
1194
1307
1574
[root@localhost ~]# pgrep -l sshd
869 sshd
1194 sshd
1307 sshd
1574 sshd
[root@localhost ~]# pgrep -l -a sshd
869 /usr/sbin/sshd -D
1194 sshd: root@pts/0
1307 sshd: root@pts/1
1574 sshd: root@pts/2
#查看进程的pid
[root@localhost ~]# pidof sshd
1574 1307 1194 869
#查看进程树
[rootlocalhost ~]# pstree
进程管理命令-top
top五行内容解析
[root@localhost ~]# top
#第一行:系统相关
top - 14:46:00
#当前系统时间
up 12:14,
#该服务器运行的时间
3 users
#当前登录的用户数量
load average: 0.00, 0.01, 0.05
#系统的平均负载 0.00:1分钟 0.01:5分钟 0.05:15分钟
#第二行:进程状态
Tasks: 97 total
#当前系统中所有的进程数量
1 running
#处于R状态 正在运行状态的进程数量
96 sleeping
#处于S状态 sleep状态的进程数量
0 stopped
#处于T状态 后台挂起暂停状态的进程数量
0 zombie
#处于Z状态 僵尸进程的进程数量
#第三行:cpu百分比
%Cpu(s):
0.3 us
#用户进程占用cpu的百分比(用户态)
0.3 sy
#系统进程占用cpu的百分比(内核态)
0.0 ni
#优先级较高的进程占用cpu的百分比
99.3 id
#cpu的空闲程度
0.0 wa
#等待状态的进程占用cpu的百分比
0.0 hi
#硬中断占用cpu的百分比
0.0 si
#软中断占用cpu的百分比
0.0 st
#虚拟化技术占用cpu的百分比
#第四行:物理内存
KiB Mem :
995896 total
#总内存数
401620 free
#空闲内存数
139704 used
#已使用的内存数
454572 buff/cache
#缓冲区/缓存区
#第五行:Swap虚拟内存
KiB Swap:
999420 total
#总虚拟内存数
998396 free
#空闲的虚拟内存数
1024 used
#已使用的虚拟内存数
640076 avail Mem
#可用的虚拟内存数
Linux中断(interrupt)机制
什么是中断:
中断是系统用来影响硬件设备请求的一种机制,它会打断进程的正常调度和执行,然后调用内核中的中断处理程序来影响设备的请求。
Linux 内核需要对连接到计算机上的所有硬件设备进行管理,毫无疑问这是它的份内事。如果要管理这些设备,首先得和它们互相通信才行,一般有两种方案可实现这种功能:
轮询(polling) 让内核定期对设备的状态进行查询,然后做出相应的处理;
中断(interrupt) 让硬件在需要的时候向内核发出信号(变内核主动为硬件主动)。
第一种方案会让内核做不少的无用功,因为轮询总会周期性的重复执行,大量地耗用 CPU 时间,因此效率及其低下,所以一般都是采用第二种中断的方案。
简单的来说,中断是为了快速响应硬件的事件,打断进程的正常调度和执行,转而调用中断处理程序的一种方法。
服务完毕后再返回去继续运行被暂时中断的程序。
linux中把中断处理过程粉尘了两个阶段,也就是上半部和下半部。
上半部用来快速处理中断 ,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行
言简意赅:
第一阶段:直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行。
第二阶段:由内核触发该请求,也就是我们常说的软中断,特点是延迟执行。
Linux中的软中断包括:网络收发,定时,调度等各种类型,可以通过/proc/softirqs来观察中断的运行情况
在企业中,会经常听说一个问题,就是大量的网络小包会导致性能问题,为啥呢?
因为大量的网络小包会导致频繁的硬中断和软中断,所以大量的网络小包传输速度很慢,但如果将所有的网络小包"打包","压缩"一次性传输,是不是会快很多。
top命令的使用
top
-d:指定更新的时间(默认是3s更新一次)
[root@localhost ~]# top -d 1
-p:只查看指定pid的进程
[root@localhost ~]# top -d 1 -p 10126
-u:指定相关用户
[root@localhost ~]# top -d 1 -u root
-b:将top内容保存到文件中
[root@localhost ~]# top -d 1 -b -n 2 > top.txt
-n:指定保存到文件中的次数
top常见指令
h 查看帮出
z 高亮显示
1 显示所有CPU的负载
s 设置刷新时间
b 高亮现实处于R状态的进程
M 按内存使用百分比排序输出
P 按CPU使用百分比排序输出
R 对排序进行反转
f 自定义显示字段
k kill掉指定PID进程
W 保存top环境设置 ~/.toprc
q 退出
#进程ID
PID
#用户
USER
#优先级,正常为20
PR
#nice值,正常为0,负值表示高优先级,正值表示低优先级
NI
#虚拟内存占用空间
VIRT
#真实内存占用空间
RES
#共享内存占用空间
SHR
#进程的状态
S
#CPU占用百分比
%CPU
#内存占用百分比
%MEM
#运行时间
TIME+
#进程的运行命令
COMMAND
进程的信号管理
当程序运行为进程后,如果希望强行停止就可以使用kill命令对进程发送关闭信号,除了kill还有pkill、killall
定义守护进程的角色
结束用户会话和进程
kill,killall,pgrep,pkil
[root@localhost ~]# kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
[root@zls ~]# kill -l //列出所有支持的信号
//常见信号列表:
数字信号 信号别名 作用
1 HUP 挂起信号,往往可以让进程重新配置
2 INT 中断信号,起到结束进程的作用,和ctrl + c 的作用一样
3 QUIT 让进程退出,结果是进程退出
9 KILL 直接结束进程,不能被进程捕获
15 TERM 进程终止,这是默认信号
18 CONT 被暂停的进程将继续恢复运行
19 STOP 暂停进程
20 TSTP 用户停止请求,作用类似于ctrl + z 把进程放到后台并暂停
kill命令发送信号
// 给 vsftpd 进程发送信号 1,15
[root@localhost ~]# yum -y install vsftpd
[root@localhost ~]# systemctl start vsftpd
//发送重启信号,例如 vsftpd 的配置文件发生改变,希望重新加载
[root@localhost ~]# kill -1 9160
//发送停止信号,vsftpd 服务有停止的脚本 systemctl stop vsftpd
[root@localhost ~]# kill 9160
// 给vim进程发送信号 9,15
[root@localhost ~]# touch file1 file2
//使用远程终端1打开file1
[root@localhost ~]# tty
/dev/pts/1
[root@localhost ~]# vim file1
//使用远程终端2打开file2
[root@localhost ~]# tty
/dev/pts/2
[root@localhost ~]# vim file2
//查看当前进程pid
[root@localhost ~]# ps aux |grep vim
root 4362 0.0 0.2 11104 2888 pts/1 S+ 23:02 0:00 vim file1
root 4363 0.1 0.2 11068 2948 pts/2 S+ 23:02 0:00 vim file2
//发送15信号
[root@localhost ~]# kill -15 4362
//发送9信号
[root@localhost ~]# kill -9 4363
//还可以同时给所有vim进程发送信号, 模糊匹配,同时给多个进程发送信号
[root@localhost ~]# killall vim
//使用pkill踢出从远程登录到本机的用户, pkill 类似killall
[root@localhost ~]# w
20:50:17 up 95 days, 9:30, 1 user, load average: 0.00, 0.00, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
xuliangw pts/0 115.175.115.39 20:22 0.00s 0.01s 0.00s sshd: root [priv]
//终止 pts/0上所有进程, 除了bash本身
[root@localhost ~]# pkill -t pts/0
//终止pts/0上所有进程, 并且bash也结束(用户被强制退出)
[root@localhost ~]# pkill -9 -t pts/0
//列出root用户的所有进程,-l输出pid
[root@localhost ~]# pgrep -l -u root
32206 sshd
32207 bash
进程的优先级
为什么要有优先级
优先级高的进程有优先执行的权利。此外,优先级还影响分配给进程的时间片长短。 重要的进程,应该分配多一些cpu时间片,好让其尽快完成任务。所有的进程都会有机会运行,但优先级高的进程会获取更多的cpu执行时间。配置进程优先级对多任务环境的Linux很有用,可以改善系统性能。简单来说,优先级高的进程,可以优先享用系统的资源。系统资源包括cpu、文件描述符、磁盘空间等等
如何查看或给进程配置优先级
在启动进程时,为不同的进程使用不同的调度策略。
nice值越高:表示优先级越低,例如19,该进程容易将CPU使用量让给其他进程。
nice值越低:表示优先级越高,例如-20,该进程更不倾向于让出CPU
1)使用top或ps命令查看进程的优先级
#使用top看优先级
[root@localhost ~]# top
#使用ps查看优先级
[root@localhost ~]# ps axo command,nice |grep [s]shd
2)使用nice命令指定进程优先级
指定进程优先级:
[root@localhost ~]# nice -n -5 vim 1.txt
使用renice调整已运行程序的优先级
#先查看sshd的优先级
[root@localhost ~]# ps axo pid,command,nice|grep [s]shd
869 /usr/sbin/sshd -D 0
1194 sshd: root@pts/0 0
1307 sshd: root@pts/1 0
1574 sshd: root@pts/2 0
#设置sshd的优先级为-20
[root@localhost ~]# renice -n -20 869
869 (进程 ID) 旧优先级为 0,新优先级为 -20
#再次查看sshd的优先级
[root@localhost ~]# ps axo pid,command,nice|grep [s]shd
869 /usr/sbin/sshd -D -20
1194 sshd: root@pts/0 0
1307 sshd: root@pts/1 0
1574 sshd: root@pts/2 0
Linux 假死现象
什么是Linux假死现象
所谓假死现象,是指 Linux 内核 Alive,但是其上的某个或所有操作的响应变得很慢的现象。
具体比较常见的现象有如下几种:
能 Ping 通访问的服务器。
系统负载非常的高。
SSH 不能登陆或者登陆比较慢。
服务器上提供的服务都不能正常响应,比如:不能访问系统上部署的 Web 服务器所提供的页面。
在系统上做任何其它操作都没有反应或者反应较慢。
为什么假死很难出现
作为一个多任务操作系统,要把系统忙死,忙到ssh都连不上去,也不是那么容易的。尤其是现在还有fd保护、进程数保护、最大内存保护之类的机制
内存多到一定程度 Linux 的 OOM 机制的 Killer 进程就会杀掉你的进程,来保证其它服务能正常工作。
如何实现假死
主进程分配固定内存,然后不停的 Fork,并且在子进程里面 Sleep(100)。
也就是说,当主进程不停 Fork 的时候,很快会把系统的物理内存用完。当物理内存不足时候,系统会开始使用 Swap。那么当 Swap 不足时会触发 OOM 机制的 Killer 进程来杀掉多余进程。
当 OOM 机制的 Killer 进程杀掉了子进程,主进程会立刻 Fork 新的子进程,并再次导致内存用完并再次触发 OOM 机制的 Killer 进程杀掉子进程,于是就进入死循环。而且 OOM Killer 进程是系统底层优先级很高的内核线程,此时也参与到这个死循环中,长此以往系统资源就会被消耗殆尽。
系统出现假死现象后,为何还能 Ping 通但又无法建立新的网络连接
系统出现假死现象后,服务器还可以 Ping 通,但是无法建立新的网络连接。比如:SSH 无法连上去。这是由于 Ping 是在 Linux 系统底层 ( Kernel )处理的,并没有参与进程调度。而 SSHD 是要参与进程调度,但是优先级没 OOM 机制的 Killer 进程高。这样就会一直得不到系统调度,从而始终无法正确的提供服务来与 SSH 客户端建立新的连接
出现假死现象怎么办
为什么要费那么大的力气把机器搞死?我们知道假死是怎么产生的即可,这样可以针对假死的原因进行预防。 (其实假死的情况很少发生,只有当代码写的bug很多的情况下会出现。)
其实建议使用nice将sshd的进程优先级调高。这样当系统内存吃紧,还能勉强登陆sshd,进入调试。然后分析故障
后台进程管理
什么是后台进程
通常进程都会在终端前台运行,但是一旦关闭终端,进程也会随着结束,那么此时我们就希望进程能在后台运行,就是将在前台运行的进程放到后台运行,这样即使我们关闭了终端也不影响进程的正常运行。
为什么要把进程放到后台运行
企业中多时候会有一些需求:
- 传输大文件,由于网络问题需要传输很久
- 我们之前的国外业务,国内到国外,网速很慢,我们需要选择节点做跳板机,那么就必须知道,哪个节点到其他地区网速最快,丢包率最低。
- 有些服务没有启动脚本,那么我们就需要手动运行,并把他们放到后台
使用什么工具可以把进程放到后台
早期的时候,大家都选择使用&,将进程放到后台运行,然后再使用jobs、bg、fg等方式查看进程状态,太麻烦了,也不只管,所以我们推荐使用screen和nohup
作业控制是一个命令行功能,允许一个 shell 实例来运行和管理多个命令。
如果没有作业控制,父进程 fork()一个子进程后,将 sleeping,直到子进程退出。
使用作业控制,可以选择性暂停,恢复,以及异步运行命令,让 shell 可以在子进程运行期间返回接受其 他命令。
前台进程,后台进程jobs,bg,fg
ctrl + Z , ctrl +c , ctrl + B
&
# 在执行的命令后面加 & 会直接将该命令放在后台执行
&
[root@localhost ~]# ping baidu.com &
[root@localhost ~]# jobs //查看后台作业
[root@localhost ~]# bg 1 //让作业 1 在后台运行
[root@localhost ~]# fg 1 //将作业 1 调回到前台
nohup
# 将执行的命令放入后台执行,并且将输出结果保存到 nohup.out文件中
nohup
[root@localhost ~]# nohup ping baidu.com &
[1] 27067
[root@localhost ~]# nohup: ignoring input and appending output to ‘nohup.
screen
# 将进程放入后台(开启一个子shell)
#安装screen命令
[root@localhost ~]# yum install -y screen
[root@localhost ~]# screen ping baidu.com
-ls:查看所有screen的后台进程
-r:指定后台进程号,进入该后台进程
-S:指定后台进程的名字
Ctrl + a + d:放在后台执行
#Ctrl+c 查看丢包率
--- baidu.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
系统平均负载
什么是平均负载
平均负载是指,单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。平均负载与CPU使用率并没有直接关系。
可运行和不可中断状态是什么
- 可运行状态进程,是指正在使用CPU或者正在等待CPU的进程,也就是我们用PS命令看的处于R状态的进程
- 不可中断进程,系统中最常见的是等待硬件设备的IO响应,也就是我们PS命令中看到的D状态(也成为Disk Sleep)的进程
例如:一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,他是不能被其他进程或者中断程序打断的,这个是后续的进程就处于不可中断的状态。不可中断状态实际上是系统对进程和硬件设备的一种保护机制
平均负载多少时合理?
最理想的状态是每个CPU上都刚还运行着一个进程,这样每个CPU都得到了充分利用。所以在评判负载时,首先你要知道系统有几个CPU,这可以通过top命令获取或者/proc/cpuinfo
假设现在在4,2,1核的CPU上,如果平均负载为2时,意味着什么呢?
1.在4个CPU的系统上,意味着CPU有50%空闲。
2.在2个CPU的系统上,以为这所有的CPU都刚好完全被占用。
3.在1个CPU的系统上,则意味着有一半的进程竞争不到CPU
平均负债有三个数值我们应该综合来看
- 如果1分钟,5分钟,15分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
- 如果1分钟的值远小于15分钟的值,就说明系统像最近1分钟的负载在减少,而过去15分钟内却有很大的负载。
- 反过来,如果1分钟的大于15分钟,就说明最近1分钟的负载在增加,这种增加有可能只是临时的,也有可能还会持续上升...所以要持续观察。
- 一旦1分钟的平均负载接近或超过了CPU的个数,就意味着,系统正在发生过载的问题,这时候就得分析问题了,并且要想办法优化。```
假设我们在有2个CPU系统上看到平均负载为2.73,6.90,12.98那么说明在过去1分钟内,系统有136%的超载(2.73/2*100%=136%)
5分钟:(6.90/2*100%=345%)
15分钟:(12.98/2*100%=649%)
但整体趋势来看,系统负载是在逐步降低
平均负载与CPU的使用率有什么关系
在十几工作中,我们经常容易把平均负载和CPU使用率混淆,所以在这里,我也做一个区分,可能你会感觉到疑惑,既然平均负载代表的是活跃进程数,那平均负载搞了,不就意味着CPU使用率高嘛?
我们还是要回到平均负载的含义上来,平均负载指的是每单位时间内,处于可运行状态和不可中断状态的进程数,所以,它不仅包括了正在使用CPU的进程数,还包括等待CPU和等待IO的进程数。
而CPU的使用率是单位时间内,CPU繁忙情况的统计,跟平均浮现在并不一定完全对应。
比如:
CPU密集型进程,使用大量的CPU会导致平均负载升高,此时这两者是一致的。
IO密集型进程,等待IO也会导致平均负载升高,但CPU使用率不一定很高。
大量等待CPU的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高。
但是CPU的种类也分两种:
CPU密集型:计算类相关服务
IO密集型:数据库相关服务
例如MySQL服务器,就需要尽量选择使用IO密集型CPU
平均负载案例分析实战
下面我们以三个示例分别来看这三中情况,并用:stress、mpstat、pidstat等工具找出平均负载升高的根源
stress是Linux系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
mpstat是多核CPU性能分析工具,用来实时检查每个CPU的性能指标,以及所有CPU的平均指标。
pidstat是一个常用的进程性能分析工具,用来实时查看进程的CPU,内存,IO,以及上下文切换等性能指标
#安装stress命令
[root@localhost ~]# yum install -y stress
案例一:CPU密集型 我们在第一个中断运行stress命令,模拟一个CPU使用率100%的场景
#启动了4个cpu密集型的进程,4个占用CPU的进程
[root@localhost ~]# stress --cpu 4 --timeout 600
#高亮显示变化区域
[root@localhost ~]# watch -d uptime
## 查看所有的CPU,5s显示一次数据
[root@zls ~]# mpstat -P ALL 5
下面可以看出,是用户态的进程导致CPU过高
Linux 3.10.0-862.el7.x86_64 ( localhost.localdomain) 05/06/2022 _x86_64_(4 CPU)
22时08分51秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
22时08分56秒 all 99.20 0.00 0.80 0.00 0.00 0.00 0.00 0.00 0.00 0.00
22时08分56秒 0 99.20 0.00 0.80 0.00 0.00 0.00 0.00 0.00 0.00 0.00
22时08分56秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
22时09分01秒 all 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00
22时09分01秒 0 99.60 0.00 0.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00
## -u指定5s输出一次数据 2 ,总共输出2组数据
[root@localhost ~]# pidstat -u 5 2
#模拟其他三种情况:
IO:磁盘IO导致负载升高
[root@localhost ~]# stress --io 100 --timeout 600
CPU:CPU会用率会导致负载升高
[root@localhost ~]# stress --cpu 100 --timeout 600
启动大量进程:导致负载升高
[root@localhost ~]# stress -c 100 --timeout 6
总结分析流程
- 使用uptime或者top命令查看,系统负载
- 看1分钟,5分钟,15分钟的负载趋势
- 是什么情况导致负载上升mpstat -P ALL 5是用户态,还是内核态,导致负载上升
- 用户态:cpu使用率,大量进程
- 内核态:磁盘IO,压缩文件,网络存储挂载,下载文件
- 使用pidstat查看到底是哪个程序,引起用户态或者内核态的负载上升

 浙公网安备 33010602011771号
浙公网安备 33010602011771号