SQL Server 索引基本概念与优化
数据页和区
- 页
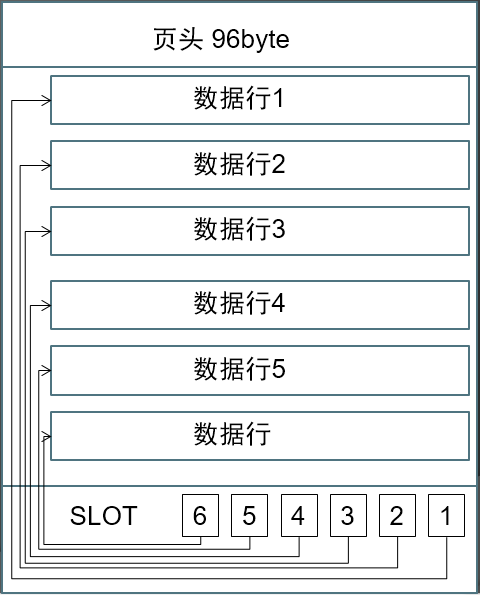
SQL Server 中的数据以“页”(Page)的形式保存数据,页是SQL Server 的IO单位,读/写一次至少是一页。一页为8K(8192byte).
页由三部分组成,页头,数据和偏移量。页头大小是96byte,记录页号,所属对象和页类型(IAM,DataPage,IndexPage),数据部分是8060byte,用来存放实际数据。偏移量36byte,也叫“slot”,用来标记每一行数据的位置
- 区
一个区=8个连续的页。
B树和索引键
B树(Balanced-Tree) 平衡多路查找树结构
- 含有一个跟节点(root node)
- 若干非页叶节点(none-leaf node)
- 最后一层为叶节点(leaf node),一个索引仅有一层(最后一层)叶子节点
- 根节点和非叶节点存放按顺序排列的键值(建索引的行)。对于聚集索引,叶子节点存放实际的数据行(所以只有一个聚集索引),而对于非聚集索引,叶子节点存放键值和书签(RID,记录文件号,页号和slot号)

索引碎片和填充因子
- 分页:当发生插入或者更新操作时,如果数据页已经不够空间容纳新数据,就会发生分页,即新建一页来存放新数据。
- 正向记录(forwarded records): 发生在堆表(即没有索引的表)中,在旧页中放一个指针指向新页,在新页中放置新数据和一个指向旧页的指针。
- 页拆分(Page Split): 发生在索引(聚集索引和非聚集索引的数据页中),当插入或更新数据时,如果数据页已经没有空间放置新数据,就会新建一页,将旧页中一半的数据移动到新页中,同时在旧页中放置新数据,如果还不够空间,则继续拆分。
- 索引碎片:当发生分页情况时,新页有可能和旧页不是连续的,例如隔开了N个页或者N个区,这样就形成了碎片。碎片增加了磁盘IO数量,原来读100条数据只需读10页,但有碎片情况下有可能需要读20页或更多(虽然一次IO最小是一个页,但一般一次都不止一个页)

(上图为Careyson的原创图片)
- 如何减少分页
- 使用自增ID。自增ID具有连续性,插入的新数据页通常位于索引数据页尾部。而使用类似newid()产生的GUID因为字母具有随机性,容易在索引叶子页的中间段插入,导致页不连续而产生碎片。
- 重新生成或重新组织索引。重生生成索引会删除原来的索引并且重新建立新索引。重组索引会对叶子页进行物理排序,使其连续。
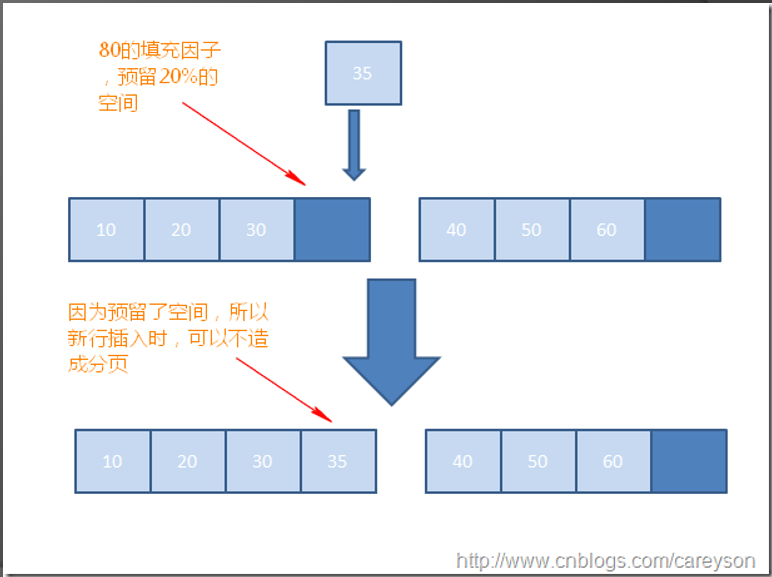
- 填充因子。 提供填充因子选项是为了优化索引数据存储和性能。当创建或重新生成索引时,填充因子的值可确定每个叶级页上要填充数据的空间百分比,以便在每一页上保留一些剩余空间作为以后扩展索引的可用空间。例如,指定填充因子的值为 80 表示每个叶级页上将有 20% 的空间保留为空,以便随着向基础表中添加数据而为扩展索引提供空间。在索引行之间保留可用空间,而不是在索引的末尾保留。

(上图为Careyson的原创图片)
(上图为Careyson的原创图片)
索引监控统计信息
一般是使用动态管理对象(DMO)
- 索引统计信息:记录索引使用情况和索引碎片情况
sys.dm_db_index_usage_stats 用于统计索引使用情况,例如索引查找/索引扫描/索引更新次数

sys.dm_db_index_physical_stats
用于统计索引的物理信息,最主要是检查索引碎片

sys.dm_db_index_operational_stats 统计索引操作统计信息,例如叶级页插入/删除/更新次数,加锁与等待累计时间

- 索引缺失:SQL SERVER在执行查询中会记录没有使用最佳索引的查询信息,通常用来分析并生成最佳索引
sys.dm_db_missing_index_group_stats 返回有关缺失索引组的摘要信息,例如,通过实现特定的缺失索引组所获取的性能改善。 sys.dm_db_missing_index_groups 返回有关特定缺失索引组的信息,例如组标识符和该组包含的所有缺失索引的标识符。 sys.dm_db_missing_index_details 返回有关缺失索引的详细信息,例如,返回缺失索引的表的名称和标识符,以及应组成缺失索引的列和列类型。 sys.dm_db_missing_index_columns (Transact-SQL) 返回有关缺失索引的数据库表列的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号