

RocketMQ介绍与实践
一、RocketMQ介绍
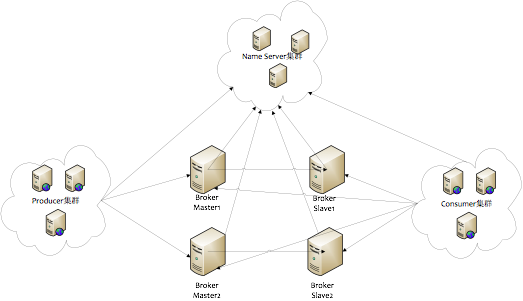

1、相关术语名词
1. NameSrv:是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
2. Broker:分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,BrokerId为0表示Master,Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与Name Server集群中的所有 节点建立长连接,定时注册Topic信息到所有Name Server。
3. Producer:向MQ发送消息,与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳,Producer完全无状态,可集群部署。
4. Consumer:从MQ消费消息,与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
5. Push Consumer :Consumer 的一种,应用通常向 Consumer 对象注册一个 Listener 接口,一旦收到消息,Consumer 对象立刻回调 Listener 接口方法。
6. Pull Consumer:Consumer 的一种,应用通常主动调用 Consumer 的拉消息方法从 Broker 拉消息,主动权由应用控制。
7. Producer Group:用来表示一个发送消息应用,一个Producer Group下包含多个Producer实例,可以是多台机器,也可以是一台机器的多个进程,或者一个进程的多个Producer对象。
8. Consumer Group:用来表示一个消费消息应用,一个Consumer Group下包含多个Consumer实例,可以是多台机器,也可以是多个进程,或者是一个进程的多个Consumer对象。一个Consumer Group下的多个Consumer以均摊方式消费消息,如果设置为广播方式,那么这个Consumer Group下的每个实例都消费全量数据。
2、上图是一个典型的消息中间件收发消息的模型,RocketMQ具有以下特点:
1. 是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式特点;
2. Producer、Consumer、队列都可以分布式。
3. Producer向一些队列轮流发送消息,队列集合称为Topic,Consumer如果做广播消费,则一个consumer实例消费这个Topic对应的所有队列,如果做集群消费,则多个Consumer实例平均消费这个topic对应的队列集合。
4. 实时的消息订阅机制。
5. 亿级消息堆积能力。
3、三款常用的消息中间件在性能及其它维度的简单对比
|
对比项
|
RabbitMQ
|
RocketMQ
|
Kafka
|
|---|---|---|---|
|
高可用模型/扩展性 |
集群+镜像队列 |
主从模式 |
动态集群+备份 |
|
性能 |
万级吞吐量 |
十万级吞吐量(批量消息) |
百万级吞吐量(批量消息) |
|
开发语言/维护难度 |
开发语言:Erlang |
开发语言:Java |
开发语言:Scala+Java
|
|
客户端支持 |
基本支持目前大部分语言 |
官方支持Java,社区有维护部分语言SDK
|
官方支持Java,开源维护很多语言的SDK |
|
消费模型 |
Push / Pull |
Push / Pull |
Pull |
|
优势 |
使用资料完善 |
消息类型丰富,方便定制化开发 |
大数据生态完善 |
|
劣势 |
不容易掌控 |
资料有待完善 |
多分区多Topic带来性能下降 |
二、RocketMQ特性介绍
1、消费模式(集群消费与广播消费)
1. 集群消费时,MQ认为Topic中任意一条消息只需要被消费者组内任意一个消费者处理即可,消息消费进度保存在broker端,如下图:

2. 广播消费时,MQ 会将Topic中每条消息推送给消费组内内所有注册过的消费者客户端,保证消息至少被每个消费者消费一次,客户端本地保存消费进度。

2、消费模型
1. Push模式(MQPushConsumer)
MQPushConsumer 即MQServer主动向消费端推送消息,consumer把轮询过程封装了,并注册MessageListener监听器,取到消息后,唤醒MessageListener的consumeMessage()来消费,对用户而言,感觉消息是被推送过来的。Push和Pull模式都是采用消费端主动拉取的方式,即consumer轮询从broker拉取消息。
代码示例:PushConsumer.java
2. Pull模式(MQPullConsumer)
MQPullConsumer 即消费端在需要时,主动到MQServer拉取,取消息的过程需要用户自己写,首先通过打算消费的Topic拿到MessageQueue的集合,遍历MessageQueue集合,然后针对每个MessageQueue批量取消息,一次取完后,记录该队列下一次要取的开始offset,直到取完了,再换另一个MessageQueue。
代码示例:PullConsumer.java
3、RocketMQ 数据存储结构
如图所示,RocketMQ采取了一种数据与索引分离的存储方法。有效降低文件资源、IO资源,内存资源的损耗。即便是阿里这种海量数据,高并发场景也能够有效降低端到端延迟,并具备较强的横向扩展能力。

4、刷盘策略
RocketMQ 的所有消息都是持久化的,先写入系统 PAGECACHE,然后刷盘,可以保证内存与磁盘都有一份数据,访问时,直接从内存读取。
1.异步刷盘

在有 RAID 卡,应用服务器三块SSD磁盘测试顺序写文件,速度可以达到 500M/S以上,万一由于此时系统压力过大,可能堆积消息,除了写入 IO,还有读取 IO,万一出现磁盘读取落后情况,
会不会导致系统内存溢出,答案是否定的,原因如下:
a) 写入消息到 PAGECACHE 时,如果内存不足,则尝试丢弃干净的 PAGE,腾出内存供新消息使用,策略
是 LRU 方式。
b) 如果干净页不足,此时写入PAGECACHE会被阻塞,系统尝试刷盘部分数据,大约每次尝试32个PAGE,来找出更多干净 PAGE。
2.同步刷盘

同步刷盘与异步刷盘的唯一区别是异步刷盘写完 PAGECACHE 直接返回,而同步刷盘需要等待刷盘完成才返回, 同步刷盘流程如下:
(1). 写入 PAGECACHE 后,线程等待,通知刷盘线程刷盘。
(2). 刷盘线程刷盘后,唤醒前端等待线程,可能是一批线程。
(3). 前端等待线程向用户返回成功。
5、存储目录结构

存储特点:
(1)RocketMQ消息主体以及元数据都存储在CommitLog当中 ,消息的存储是由consume queue和 commitLog 配合完成的;
(2)Consume Queue定长的结构,每1条记录固定的20个字节,相当于kafka中的partition,是一个逻辑队列,存储了这个Queue在CommiLog中的起始offset,log大小和MessageTag的hashCode;
(3)Consumer消费消息的时候,先读取consumerQueue,然后再通过consumerQueue去commitLog中拿到消息主体。
1. CommitLog文件(物理队列)
CommitLog是用于存储真实的物理消息的结构,保存消息元数据,所有消息到达Broker后都会保存到commitLog文件,这里需要强调的是所有topic的消息都会统一保存在commitLog中。
1)commitlog文件的存储地址:$HOME\store\commitlog\${fileName}
2)一个消息存储单元长度是不定的,顺序写但是随机读
3)每个commitLog文件的默认大小为 1G =1024*1024*1024,满1G之后会自动新建CommitLog文件做保存数据用
4)commitlog的文件名fileName,名字长度为20位,左边补零,剩余为起始偏移量;比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当这个文件满了,
第二个文件名字为00000000001073741824,起始偏移量为1073741824,以此类推,第三个文件名字为00000000002147483648,起始偏移量为2147483648消息存储的时候会顺序写入文件,当文件满了,写入下一个文件。
5)CommitLog的清理机制:
按时间清理,rocketmq默认会清理3天前的commitLog文件;
按磁盘水位清理:当磁盘使用量到达磁盘容量75%,开始清理最老的commitLog文件。
2.ConsumeQueue文件组织:
ConsumerQueue相当于CommitLog的索引文件,消费者消费时会先从ConsumerQueue中查找消息的在commitLog中的offset,再去CommitLog中找元数据。如果某个消息只在CommitLog中有数据,没在ConsumerQueue中, 则消费者无法消费,Consumequeue类对应的是每个topic和queuId下面的所有文件,相当于字典的目录用来指定消息在消息的真正的物理文件commitLog上的位置,每条数据的结构如下图所示:消息的起始物理偏移量physical offset(long 8字节)+消息大小size(int 4字节)+tagsCode(long 8字节)。
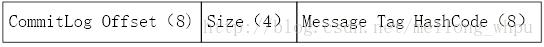
1)每个topic下的每个queue都有一个对应的consumequeue文件;
2)每个文件由30W条数据组成,每条数据的大小为20个字节,从而每个文件的默认大小为600万个字节(consume queue中存储单元是一个20字节定长的数据)是顺序写顺序读;
3)commitLogOffset是指这条消息在commitLog文件实际偏移量,size就是指消息大小,消息tag的哈希值;
三、RocketMQ实践
1、消息保留时长
fileReservedTime=72 消息留盘时常,默认72小时,取决于broker所在机器磁盘容量大小和业务场景要求,可以通过命令行动态修改,如下:
sh mqadmin updateBrokerConfig -n 'namesrv_adress' -c DefaultCluster -k fileReservedTime -v 24 -n 表示修改集群中master节点上消息保留时常为24小时
sh mqadmin updateBrokerConfig -b 'broker_adress' -c DefaultCluster -k fileReservedTime -v 24 -b 表示修改集群中指定broker节点上消息保留时常为24小时
2、消息主从同步及刷盘策略,默认主从同步,消息异步刷盘
brokerRole=SYNC_MASTER 主从同步
flushDiskType=ASYNC_FLUSH 异步刷盘
|
方式 |
同步双写 |
异步复制 |
|
同步刷盘 |
金融级,吞吐量低 |
吞吐量低 |
|
异步刷盘 |
默认配置,吞吐量适中 |
吞吐量最高,单节点宕机会丢失消息 |
3、生产端实践
1. 局部顺序消息考虑单分片全挂的极端情况,可能存在短时间乱序;
2. 事物消息考虑部署多个slave节点,slave挂掉影响消息发送;
3. 发送使用同步方式并打印发送结果,方便问题排查;
4. 消息发送失败的处理逻辑;
5. 有消息优先级的需求,通过将不同优先级的消息发送到不同队列来实现;
6. 手动创建Topic,避免单点问题,创建步骤

集群名默认,broker_name选集群中所有节点,主题名(Topic)手动输入,默认每个broker上16个队列(MessageQueue),
图中3个broker节点共48个队列,队列数的大小与消费者数量有关,最好是等于消费者数量,这样消费效率最高,
如果业务场景上需要严格的顺序消息,那么读写队列数量为1。

4、消费端实践
1. 同一个消费者组只能订阅相同的Topic
2. 同一个消费者组TAG使用出错导致部分消息未消费,合理使用TAG
3. Topic中数据量比较大,新消费者组加入建议使用LAST_OFFSET
4. 消息去重,RocketMQ只保证消费最少消费一次
5. 消费考虑均衡,避免消费者消费不均匀
5、消息堆积问题解决办法
|
|
考虑项
|
堆积性能指标
|
|---|---|---|
| 消息的堆积容量 | 依赖磁盘大小 | |
| 发消息的吞吐量大小受影响程度 | 无 SLAVE 情况,会受一定影响 有 SLAVE 情况,不受影响 |
|
| 正常消费的 Consumer 是否会受影响 | 无 SLAVE 情况,会受一定影响 有 SLAVE 情况,不受影响 |
|
| 访问堆积在磁盘的消息时,吞吐量有多大 | 与访问的并发有关,最慢会降到 5000 左右 |

