

ES介绍与实践
一、ES介绍
1、基础概念介绍
1. 索引:Elasticsearch中的“索引”有点像关系数据库中的数据库。 它是存储/索引数据的地方;
2.分片 shard
“分片”是Lucene的一个索引。 它本身就是一个功能齐全的搜索引擎。
“索引”可以由单个分片组成,但通常由多个分片组成,一部分主分片、一部分副本分片。
3.分段 segment
每个分片包含多个“分段”,其中分段是倒排索引,分段内的doc数量上限是2的31次方,默认每秒都会生成一个segment文件,通过GET /test/_segments查看
4.倒排索引:是一种将词项映射到文档ID的数据结构
5.translog日志文件:为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中。
6.refresh操作:相比于Lucene的提交操作,ES的refresh是相对轻量级的操作,先将index-buffer中文档(document)生成的segment写到文件系统之中,默认1s钟刷新一次,所以说ES是近实时的搜索引擎,不是准实时。
7.flush操作:新创建的document数据会先进入到index buffer之后,与此同时会将操作记录在translog之中,当发生refresh时ranslog中的操作记录并不会被清除,而是当数据从filesystem cache中被写入磁盘之后才会将translog中清空。
8.Mapping: 是对索引库中索引的字段名称及其数据类型进行定义,类似于mysql中的表结构信息。不过es的mapping比数据库灵活很多,它可以动态识别字段。一般不需要指定mapping都可以,因为es会自动根据数据格式识别它的类型,
如果你需要对某些字段添加特殊属性(如:定义使用其它分词器、是否分词、是否存储等),就必须手动添加mapping。
2、ES写过程拆解
1.写入集群
步骤1:首先客户端根据配置的连接节点,通过轮询方式连接到一个coordinate节点。
步骤2:coodinate节点通过hash算法计算出数据在shard1上shard = hash(document_id) % (num_of_primary_shards),然后根据节点上维护的shard信息,将请求发送到node1上。
步骤3:node1 对索引数据进行校验,然后写入到shard中。
步骤4:主节点数据写入成功后,将数据并行发送到副本集节点Node2,Node3。
步骤5:Node2,Node3写入数据成功后,发送ack信号给shard1主节点Node1。
步骤6:Node1发送ack给coordinate node;
步骤7:coordinate node发送ack给客户端。
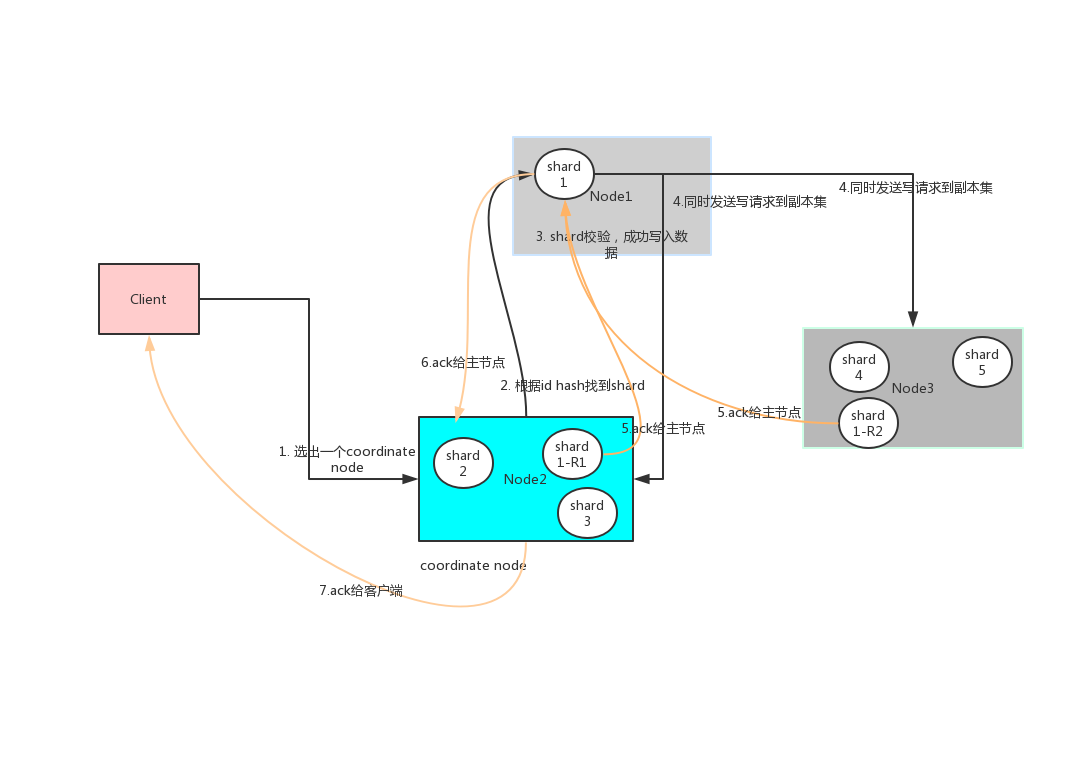
2.写入shard
步骤1:新document首先写入index Buffer缓存中,同时写入到数据到translog buffer;
步骤2:每隔1s数据从buffer中refresh到FileSystemCache中,生成segment文件,一旦生成segment文件,就能通过索引查询到了。
步骤3:refresh完,memory buffer就清空了。
步骤4:每隔5s中,translog 从buffer flush到磁盘中。
步骤5:flush完,translog就被清空了。
3、ES搜索数据过程
步骤1:客户端发送请求到一个coordinate node
步骤2:协调节点将搜索请求转发到所有的shard对应的primary shard或replica shard也可以
步骤3:query phase:每个shard将自己的搜索结果(其实就是一些doc id),返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果
步骤4:fetch phase:接着由协调节点,根据doc id去各个节点上拉取实际的document数据,最终返回给客户端
4、集群规模与容量规划
http://doc.oppoer.me/pages/viewpage.action?pageId=165283623
5、集群冷热部署(hot-warm)
"hotwarm_type":"hot" – >"hotwarm_type":"warm"

5、性能优化实践
1.分片大小Elasticsearch官方建议一个分片的大小应该在20到40 GB左右,
如果您计算出索引将存储300 GB的数据,则可以为该索引分配9到15个主分片。
根据集群大小,假设群集中有10个节点,您可以选择为此索引分配10个主分片,以便在集群节点之间均匀分配分片。
2.设置历史索引为只读,并进行段合并操作。
3.禁止swap,一台物理机部署一个ES进程,分配一半的物理内存给JVM,剩余的一半给lucene segment缓存;
4.增加刷新间隔 refresh_interval,适当减少flush操作频率
默认刷新间隔为1秒。这迫使Elasticsearch每秒创建一个分段。实际业务中,应该根据使用情况增加刷新间隔,举例:增加到30秒。
这样之后,30s产生一个大的段,较每秒刷新大大减少未来的段合并压力。最终会提升写入性能并使搜索查询更加稳定
"refresh_interval": "90s",
"number_of_shards": "20",
"translog": {
"flush_threshold_size": "500mb",
"sync_interval": "60s",
"durability": "async"
},
5.较少不必要的字段映射(mapping)
二、ES监控
第一部分:监控指标获取(三个维度)
1、集群监控指标:
1.Cluster Health – Nodes and Shards
通过GET _cluster/health监视群集时,可以查询集群的状态、节点数和活动分片计数的信息。还可以查看重新定位分片,初始化分片和未分配分片的计数。
1) Status:状态群集的状态。红色:部分主分片未分配。黄色:部分副本分片未分配。绿色:所有分片分配ok。
2) Nodes:节点。包括群集中的节点总数,并包括成功和失败节点的计数。 Count of Active
3) Shards:活动分片计数。集群中活动分片的数量。 Relocating Shards:重定位分片。由于节点丢失而移动的分片计数。
4) Initializing Shards:初始化分片。由于添加索引而初始化的分片计数。 Unassigned
5) Shards。未分配的分片。尚未创建或分配副本的分片计数。
2.Search – Request Latency and Request Rate
GET /_nodes/stats
请求过程本身分为两个阶段:
第一阶段是查询阶段(query phase),集群将请求分发到索引中的每个分片(主分片或副本分片);
第二阶段是获取阶段(fetch phrase),查询结果被收集,处理并返回给用户。
1) query_current:当前正在进行的查询数。集群当前正在处理的查询计数。
2) fetch_current:当前正在进行的fetch次数。集群中正在进行的fetch计数。
3) query_total:查询总数。集群处理的所有查询的聚合数。
4) query_time_in_millis:查询总耗时。所有查询消耗的总时间(以毫秒为单位)。
5) fetch_total:提取总数。集群处理的所有fetch的聚合数。
6) fetch_time_in_millis:fetch所花费的总时间。所有fetch消耗的总时间(以毫秒为单位)。
3.Indexing – Refresh Times and Merge Times
监视文档的索引速率( indexing rate )和合并时间(merge time)有助于在开始影响集群性能之前提前识别异常和相关问题。将这些指标与每个节点的运行状况并行考虑,这些指标为系统内的潜问题提供重要线索,为性能优化提供重要参考。
2、主机监控指标
GET /_cat/nodes?v&h=id,disk.total,disk.used,disk.avail,disk.used_percent,ram.current,ram.percent,ram.max,cpu
1.Node – Memory Usage
2.Node – Disk I/O
3.Node – CPU
实际业务场景中推荐使用:Elastic-HQ, cerebro监控。
3、JVM监控指标
GET /_nodes/stats
1.jvm heap usage
2.gc
3.threads
第二部分:生产环境的监控
1、cerebro(集群状态、索引分片、主机层基础监控)http://cere-bjsm.oppoer.me


2、Kibana http://kb-bjht.ops.oppoer.me elastic qeYM6NAuVNIxfEtedlRb


3、Promethues+Grafna http://progra-bjsm.ops.oppoer.me/?orgId=1
参考:https://shenshengkun.github.io/posts/550bdf86.html


三、常用工具清单
1、集群监控工具 cerebro https://github.com/lmenezes/cerebro
2、索引自动管理工具 curator https://github.com/elastic/curator
3、管理elasticsearch集群以及通过web界面来进行查询操作ES-HQ https://github.com/royrusso/elasticsearch-HQ
4、集群间数据迁移工具 Elasticsearch-migration https://github.com/medcl/elasticsearch-migration

