
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
天气预报爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取各个城市的温度、风向、湿度等天气数据。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
思路:用requests库对页面的数据进行爬取,用BeautifulSoup4库进行清洗数据,然后将得到的数据进行持久化和可视化及分析处理。
难点:根据城市名查找到该城市的页面数据;将列表中的数据类型转为整型以作为可以使用在可视化图表的数据。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征

即https://www.tianqi.com/+城市名拼音/
2.Htmls页面解析
2.Htmls页面解析

城市名在这一页的citybox中

城市的各项天气数据
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
在html源文件中找到对应数据所在的标签,用find_all()f方法遍历。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
(必要时画出节点树结构)
在html源文件中找到对应数据所在的标签,用find_all()f方法遍历。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
#爬取天气网中的全国城市天气查询页面 def getHTML(url): try: hs = {'User-Agent': 'Mozilla/5.0 '} #爬取该网页,若响应时间超过60则超时 r = requests.get(url,headers=hs,timeout=60) #判断是否成功,状态码不等于200即失败 r.raise_for_status() #防止出现中文乱码 r.encoding = r.apparent_encoding #返回爬取的所有代码 return r.text except: return'无法爬取'
#创建存储数据的文件 def dataSave(): try: #创建文件夹 os.mkdir("C:\天气网数据") except: #若文件已存在,则不再重复进行创建操作 "" #爬取各个城市名称 def getCityName(html): #创建用来存放的表 OldList = [] CityNameList = [] #设置对象 soup = BeautifulSoup(html,"html.paser") #提取城市标签 tab = soup.find("div",attrs="citybox") #用find_all()方法遍历得到所有城市的标签 a = tab.find_all("span") for b in range(len(a)): for x in a[b].find_all("a"): if x is not None: OldList.append(x.get("name")) #将得到的城市名称放在一个表上 CityNameList.append(OldList) #清理OldList表 OldList = [] #返回城市名称表 return CityNameList #设置城市的链接 def getCityHref(html): #创建2个存放城市信息的空表 oldList = [] cityHrefList = [] #设置对象 soup = BeautifulSoup(html, "html.parser") #提取城市 tab = soup.find("div",attrs="citybox") #用find_all()方法遍历得到所有城市的标签 a = tab.find_all("span") for d in range(len(a)): for x in a[d].find_all("a"): if x is not None: oldList.append(x.get("href")) #把得到得省包装在一个表上 cityHrefList.append(oldList) #清空表 oldList = [] #返回一个包含所有省市的列表 return cityHrefList #爬取各个城市温度 def getTemperature(html): soup = BeautifulSoup(html,"html.parser") a = soup.find("p",attrs="now") return a.text #爬取各个城市湿度 def getHumidity(html): soup = BeautifulSoup(html,"html.parser") b = soup.find("dd",attrs="shidu") a1 = b.b.text return a1 #爬取各个城市空气质量 def getAir(html): soup = BeautifulSoup(html,"html.parser") c = soup.find("dd",attrs="kongqi") return c.h5.text #爬取各个城市风向 def getWind(html): soup = BeautifulSoup(html,"html.parser") d=soup.find('dd',class_="shidu") return d.find_all("b")[1].text #测试爬取是否正常 if __name__ == "__main__": html = getHTML("http://www.tianqi.com/quanzhou/") print(getTemperature(html)) print(getWind(html)) print(getAir(html)) print(getHumidity(html))
运行结果:
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
#创建两个空表 list1 = [] list2 = [] #正常显示中文标签 plt.rcParams['font.sans-serif'] = ['SimHei'] #正常显示负号 plt.rcParams['axes.unicode_minus'] = False for x in cityHref[0][0:6]: html = getHTML("http://www.tianqi.com{}".format(x)) list1.append(getHumidity(html)) for j in list1: j=list2.append(j[3:5]) print(list2) numbers = [int(x) for x in list2] s = pd.Series(numbers[0:6],['海淀','朝阳','顺义','怀柔','通州','昌平']) #设置图表标题 s.plot(kind='bar', title='北京省前6个城市的湿度对比') #输出图片 plt.show()
运行结果:

5.数据持久化
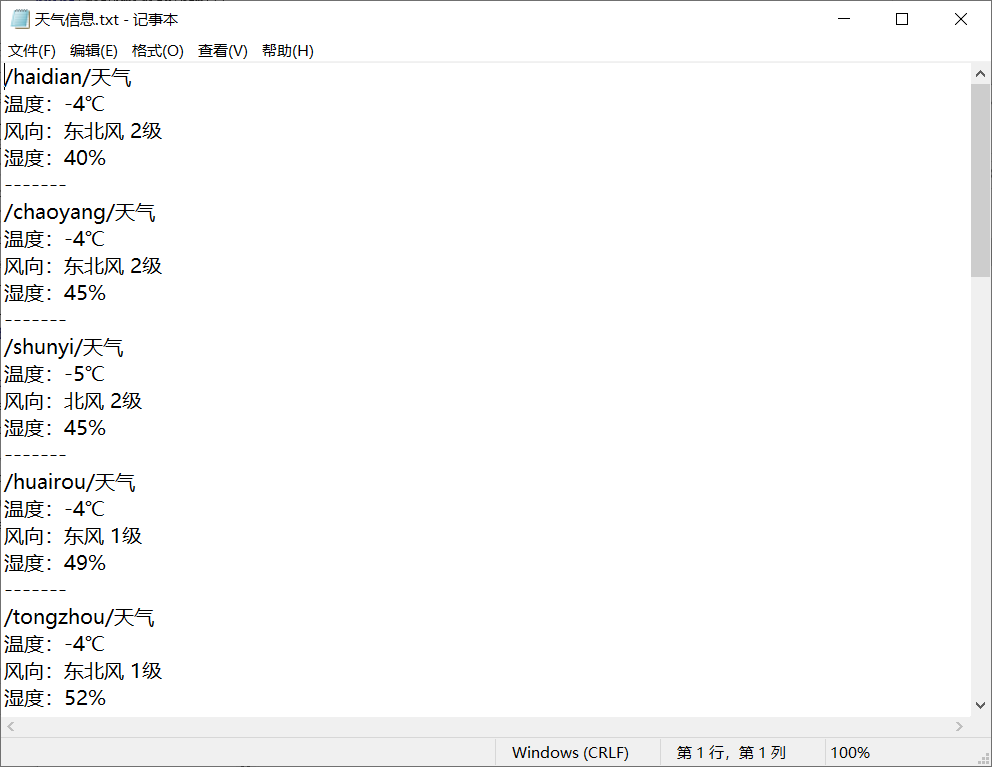
#数据存储 def saveCityWeather(cityHref): #数据保存 dataSave() try: #存储爬取到的数据 for x in range(len(cityHref)): for a in range(len(cityHref[x])): with open("C:\\天气网数据\\天气信息.txt", "a") as f: html = getHTML("http://www.tianqi.com{}".format(cityHref[x][a])) f.write("{}天气\n".format(cityHref[x][a])) f.write("温度:{}\n".format(getTemperature(html))) f.write("{}\n".format(getWind(html))) f.write("{}\n".format(getHumidity(html))) f.write("-------\n") print("存储成功") except: "存储失败"
运行结果:

6.附完整程序代码
#导入所需的库 import requests from bs4 import BeautifulSoup import matplotlib.pyplot as plt import os import pandas as pd #爬取天气网中的全国城市天气查询页面 def getHTML(url): try: hs = {'User-Agent': 'Mozilla/5.0 '} #爬取该网页,若响应时间超过60则超时 r = requests.get(url,headers=hs,timeout=60) #判断是否成功,状态码不等于200即失败 r.raise_for_status() #防止出现中文乱码 r.encoding = r.apparent_encoding #返回爬取的所有代码 return r.text except: return'无法爬取' #创建存储数据的文件 def dataSave(): try: #创建文件夹 os.mkdir("C:\天气网数据") except: #若文件已存在,则不再重复进行创建操作 "" #爬取各个城市名称 def getCityName(html): #创建用来存放的表 OldList = [] CityNameList = [] #设置对象 soup = BeautifulSoup(html,"html.paser") #提取城市标签 tab = soup.find("div",attrs="citybox") #用find_all()方法遍历得到所有城市的标签 a = tab.find_all("span") for b in range(len(a)): for x in a[b].find_all("a"): if x is not None: OldList.append(x.get("name")) #将得到的城市名称放在一个表上 CityNameList.append(OldList) #清理OldList表 OldList = [] #返回城市名称表 return CityNameList #设置城市的链接 def getCityHref(html): #创建2个存放城市信息的空表 oldList = [] cityHrefList = [] #设置对象 soup = BeautifulSoup(html, "html.parser") #提取城市 tab = soup.find("div",attrs="citybox") #用find_all()方法遍历得到所有城市的标签 a = tab.find_all("span") for d in range(len(a)): for x in a[d].find_all("a"): if x is not None: oldList.append(x.get("href")) #把得到得省包装在一个表上 cityHrefList.append(oldList) #清空表 oldList = [] #返回一个包含所有省市的列表 return cityHrefList #爬取各个城市温度 def getTemperature(html): soup = BeautifulSoup(html,"html.parser") a = soup.find("p",attrs="now") return a.text #爬取各个城市湿度 def getHumidity(html): soup = BeautifulSoup(html,"html.parser") b = soup.find("dd",attrs="shidu") a1 = b.b.text return a1 #爬取各个城市空气质量 def getAir(html): soup = BeautifulSoup(html,"html.parser") c = soup.find("dd",attrs="kongqi") return c.h5.text #爬取各个城市风向 def getWind(html): soup = BeautifulSoup(html,"html.parser") d=soup.find('dd',class_="shidu") return d.find_all("b")[1].text #测试爬取是否正常 if __name__ == "__main__": html = getHTML("http://www.tianqi.com/quanzhou/") print(getTemperature(html)) print(getWind(html)) print(getAir(html)) print(getHumidity(html)) #数据存储 def saveCityWeather(cityHref): #数据保存 dataSave() try: #存储爬取到的数据 for x in range(len(cityHref)): for a in range(len(cityHref[x])): with open("C:\\天气网数据\\天气信息.txt", "a") as f: html = getHTML("http://www.tianqi.com{}".format(cityHref[x][a])) f.write("{}天气\n".format(cityHref[x][a])) f.write("温度:{}\n".format(getTemperature(html))) f.write("{}\n".format(getWind(html))) f.write("{}\n".format(getHumidity(html))) f.write("-------\n") print("存储成功") except: "存储失败" #函数调用 if __name__ == "__main__": html = getHTML("http://www.tianqi.com/quanzhou/") html2 = getHTML("http://www.tianqi.com/chinacity.html") cityHref = getCityHref(html2) dataSave() saveCityWeather(cityHref) ##所有城市天气控制台输出 for x in range(len(cityHref)): for a in range(len(cityHref[x])): html = getHTML("http://www.tianqi.com{}".format(cityHref[x][a])) print(cityHref[x][a]+"天气") print(getWind(html)) print(getAir(html)) print(getHumidity(html)) print("-------\n") #保存数据 #数据分析与可视化 #创建两个空表 list1 = [] list2 = [] #正常显示中文标签 plt.rcParams['font.sans-serif'] = ['SimHei'] #正常显示负号 plt.rcParams['axes.unicode_minus'] = False for x in cityHref[0][0:6]: html = getHTML("http://www.tianqi.com{}".format(x)) list1.append(getHumidity(html)) for j in list1: j=list2.append(j[3:5]) print(list2) numbers = [int(x) for x in list2] s = pd.Series(numbers[0:6],['海淀','朝阳','顺义','怀柔','通州','昌平']) #设置图表标题 s.plot(kind='bar', title='北京省前6个城市的湿度对比') #输出图片 plt.show()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过北京省前6个城市的湿度对比图,可以清楚的得出结论:同一省份的6个城市中湿度最高的城市比湿度最低的城市高仅5%,即地理位置相近的城市同一天同一时刻的空气湿度差距不会过大。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过本次程序设计任务的进行,我发现了很多自己在理论学习中没有注意和发现到的问题,深刻意识到要如果想要学好Python这门语言,想写好爬虫,都需要在学习的同时更多的去实践,有时候虽然对知识都理解了,但操作起来又会遇到一些细节性的问题,而更多的实践,去亲手敲出自己的程序,才能从中发现问题,将问题找出并解决,才能让掌握的知识能真正的为自己所用。
