1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
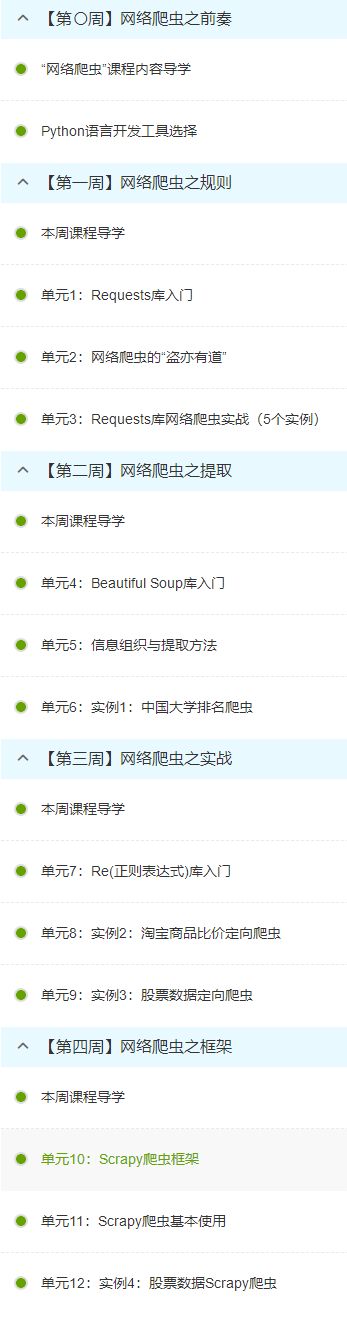

4.提供图片或网站显示的学习进度,证明学习的过程。
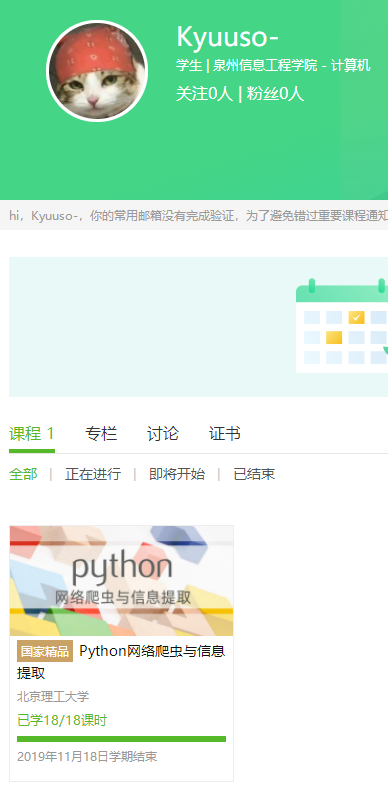
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
这次在中国大学MOOC(慕课)网站上参与了Python网络爬虫与信息提取的课程学习,认真完成了课程第0到第4周的总计18课时的全部内容,初步认识了定向网络数据爬取和网页解析的基本方法,同时理解了网络爬虫的基本概念:网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,它可以自动化浏览网络中的信息,浏览信息的时候会按照我们编写的逻辑进行处理,这些逻辑我们就称之为网络爬虫算法。
使用Python可以很方便地编写出爬虫程序,进行网络信息的自动化检索。当我们研究爬虫的时候,不仅要了解爬虫如何实现,还需要掌握一些常见爬虫的算法,如果有必要,我们要有能力自己去制定相应的算法。
在本课程中,我们学习了Requests库提供了基本的网络爬虫功能,并了解了如何进一步通过它来构建一个网络爬虫系统,掌握了Requests库的七个库使用方法,这七个方法如下:requests.get():该方法获取HTML网页的主要方法,对应HTTP的GET;requests.head():获取HTML网页头信息的方法,对应于HTTP的HEAD:通过对网络头部的处理能伪装成用户浏览便于后续网络爬虫的使用。requests.post():向HTML网页提交post请求的方法,对应于HTTP的POST;requests.put():向HTML网页提交PUT请求的方法,对应于HTTP的PUT;requests.patch():向HTML网页提交局部修改请求,对应于HTTP的PATCH;requests.delete() : 向HTML页面提交删除请求,对应于HTTP的DELETE。通过本课程的学习我清楚了Requests库是同步请求,也就是从请求到收到响应这一系列过程都是同步进行的。课程同时也向我们介绍并解释了一些有用的专业名词,URL是Internet上描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。HTTP协议的URL示例是使用超级文本传输协议HTTP,提供超级文本信息服务的资源。文件的URL用URL表示文件时,file表示,后面要有主机IP地址、文件的存取路 径(即目录)和文件名等信息。有时可以省略目录和文件名,但“/”符号不能省略。BeautifulSoup的导入时用服务器方式用 from bs4 import BeautifulSoup代码进入,常用BeautifulSoup有四个,但是每一个解释器的使用条件不同,BeautifulSoup类的基本元素有五个。常见的信息标记提取直接搜素<>.find_all() <>.find等方法,在这门课中教授还给我们运用实例代码讲了同时存在的扩展方法。crapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。这些知识都为我们能够自己尝试建立网络爬虫系统提供了基础。
学会Python网络爬虫与信息提取这一门网络课程的知识对我帮助很大,让我得以学习网络爬虫这个现在的热门技术,更好的提升了个人能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号