6、使用Flask-SQLAlchemy管理数据库和数据库的迁移
使用Flask-SQLAlchemy管理数据库
在视图函数中操作数据库
使用Flask-Migrate实现数据库的迁移
1、安装Flask-SQLAlchemy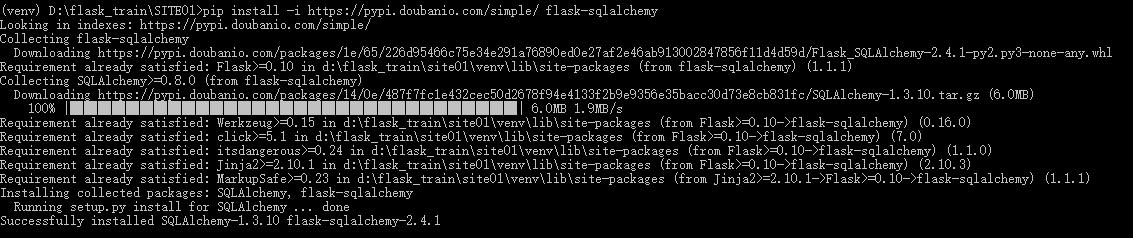
2、hello.py配置数据库
from flask_script import Manager
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
manager = Manager(app)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///data.sqlite'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
db = SQLAlchemy(app)
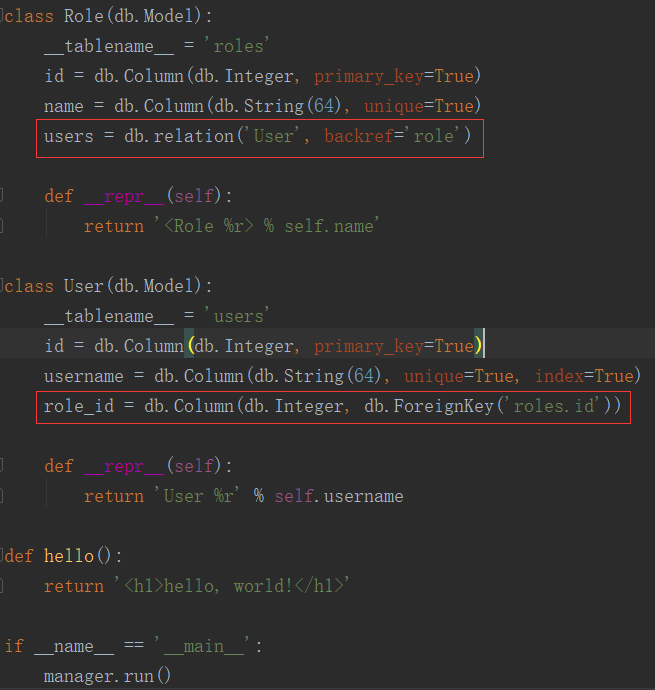
3、hello.py 定义Role和User模型
类变量__tablename__定义在数据库中使用的表名。如果没有定义,Flask-SQLAlchemy会使用一个默认的名字,但默认的表名没有遵守使用复数形式进行命名的约定,最好由我们自己指定表名。其余变量都是该模型的属性,被定义为db.Cloumn类的实例
#定义数据库模型 class Role(db.Model): __tablename__ = 'roles' id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String(64), unique=True) def __repr__(self): return '<Role %r>' %self.name class User(db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64), unique=True, index=True) def __repr__(self): return 'User %r' %self.username
4、关系
users = db.relation('User', backref='role')
添加到Role模型中的users属性代表这个关系的面向对象视角。对于一个Role类的实例,其users属性将返回与角色相关联的用户组成的列表。
db.relationship()第一个参数表明这个关系的另一端是哪个模型(类)。如果模型类尚未定义,可使用字符串形式指定。
db.relationship()第二个参数backref,将向User类中添加一个role属性,从而定义反向关系。这一属性可替代role_id访问Role模型,此时获取的是模型对象,而不是外键的值。
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
这句话是说,User类中添加了一个role_id变量,数据类型db.Integer,第二个参数指定外键是哪个表中哪个id
当表之间的关系是一对一的关系时,可添加userlist参数
db.Relationship('User',backref='role',uselist=False)
5、在shell中创建数据库
在shell中激活虚拟环境,运行python hello.py shell
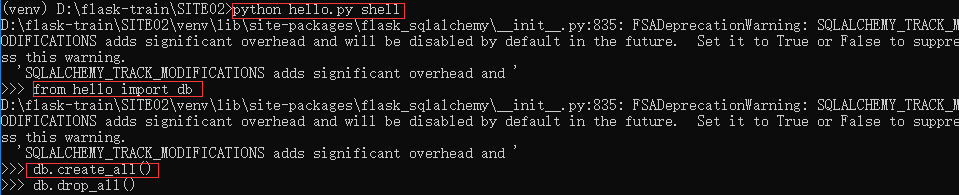
我们要让 Flask-SQLAlchemy 根据模型类创建数据库。方法是使用 db.create_all()函数,执行完后,目录下会多一个data.sqlite的文件
6、生成data.sqlite文件后,在pycharm中需下载相应包进行支持,否则数据库不能用
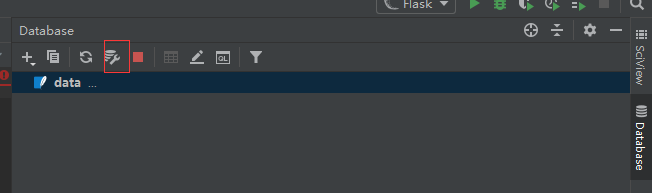
如果没有下载相应文件,红框处会有下载提示,点击下载即可
6、插入行
创建一些角色和用户
from hello import Role, User admin_role = Role(name='Admin') mod_role = Role(name='Moderator') user_role = Role(name='User') user_john = User(username='john', role=admin_role) user_susan = User(username='susan', role=user_role) user_david = User(username='david', role=user_role)
此时新建对象的id属性并没有明确设定,因为主键是由 Flask-SQLAlchemy 管理的,现在这些对象只存在于python中,还未写入数据库,因此id未赋值
在 Flask-SQLAlchemy 中,会话由 db.session表示。准备把对象写入数据库之前,先要将其添加到会话中
db.session.add(admin_role)
db.session.add(mod_role)
db.session.add(user_role)
db.session.add(user_john)
db.session.add(user_susan)
db.session.add(user_david)
也可简写为:
db.session.add_all([admin_role, mod_role, user_role,... user_john, user_susan, user_david])
提交到会话
db.session.commit()
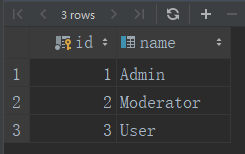
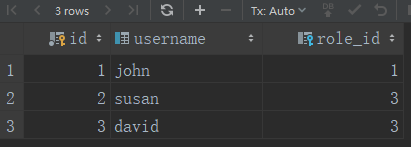
roles表 users表
SELECT * FROM roles SELECT * FROM users
说明:
users表中的用户拥有唯一的角色,在users表中定义role_id并设置属性为外键,在roles表中给users表添加role属性,该属性可以替代users表中的role_id访问roles模型
user_john = User(username='john', role=admin_role) 可以看到可以通过role属性,访问了roles表中的id,并通过设置的关系,自动关联users表中role_id 和roles表中的id列
7、修改行
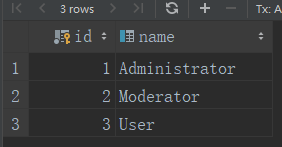
admin_role.name = 'Administrator' db.session.add(admin_role) db.session.commit()
roles表状态
8、删除行
db.session.delete(mod_role)
db.session.commit()
roles表状态
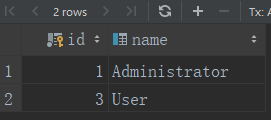
9、查询行
Flask-SQLAlchemy为每个模型类都提供了query对象,最基本的模型查询对象是取回对应表中的所有记录:

使用过滤器可以配置query对象进行更精确的数据库查询,下面是查找角色为“User”的所有用户

若要查看SQLAlchemy为查询生成的原生SQL查询语句,只需把query对象转换成字符串:

退出shell后,重新打开一个shell会话,就要从数据库中读取行,再重新创建python对象,下面是发起一个查询,加载名为“User”的用户角色

filter_by()等过滤器在query对象上调用,返回一个更精确的query对象。多个过滤器可以一起调用,知道获取结果
在视图函数中操作数据库
1、修改hello.py中的index方法
@app.route('/', methods=['GET', 'POST'])
def index():
form = NameForm()
if form.validate_on_submit():
user = User.query.filter_by(username=form.name.data).first()
if user is None:
user = User(username = form.name.data)
db.session.add(user)
session['known'] = False
else:
session['known'] = True
session['name'] = form.name.data
form.name.data = ''
return redirect(url_for('index'))
return render_template('index.html', form = form, name = session.get('name'), known = session.get('known', False))
提交表单后,程序会使用filter_by()查询过滤器在数据库中查找提交的名字。变量known被写入用户会话中,因此重定向后,可以把数据传给模板,用来显示自定义的欢迎消息。
2、修改templates/index.html
{% extends "base.html" %} {% import "bootstrap/wtf.html" as wtf%} {% block title %}Flasky{% endblock %} {% block page_content %} <div class="page-header"> <h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}</h1> {% if not known %} <p>Pleased to meet you!</p> {% else %} <p>Happy to see you again!</p> {% endif %} </div> {{ wtf.quick_form(form)}} {% endblock %}
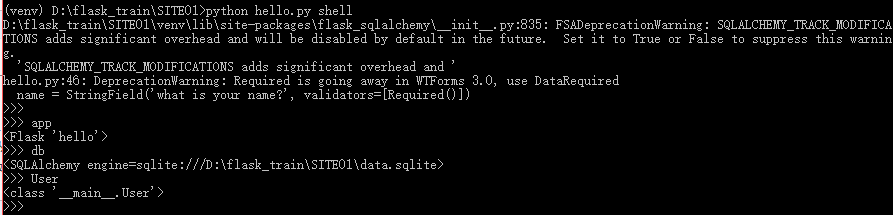
3、集成python shell
每次启动shell都要导入数据库实例和模型,为避免重复,下面命令可让Flask-Script的shell命令自动导入特点的对象
from flask_script import Manager,Shell #为shell命令添加一个上下文 def make_shell_context(): return dict(app=app, db=db, User=User, Role=Role) manager.add_command("shell", Shell(make_context=make_shell_context))
在次启动时,自动导入了模型
使用Flask-Migrate实现数据库的迁移
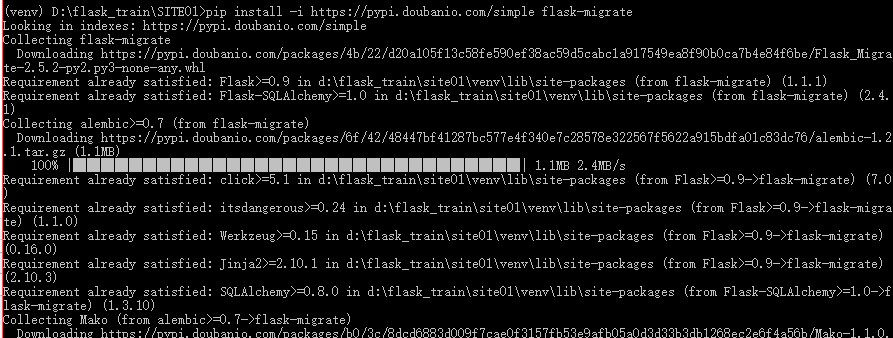
1、安装Flask-Migrate
2、在hello.py中配置Flask-Migrate
from flask_migrate import Migrate, MigrateCommand app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///data.sqlite' app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True app.config["SECRET_KEY"] = "123456" bootstrap = Bootstrap(app) db = SQLAlchemy(app) migrate = Migrate(app, db) manager = Manager(app) manager.add_command('db', MigrateCommand)
3、在迁移前,使用init子命令创建迁移仓库
python hello.py db init
该命令会创建migrations文件夹,所有迁移脚本都会存放其中

执行完之后的目录结构

4、创建迁移脚本
在Alembic中,数据库迁移用迁移脚本表示,有两个函数:
upgrade() 把迁移中的改动应用到数据库中
downgrad() 将改动删除
数据库可以重设到修改历史的任意一点
迁移操作分为:
手动迁移,只是一个骨架,uograde()和downgrade()函数都是空的,开发者要使用Alembic提供的Operations对象指令实现具体操作
自动迁移,会根据模型定义和数据库当前状态之间的差异生成upgrade()和downgrade()函数的内容
migrate子命令用来自动创建迁移脚本:
python hello.py db migrate -m "initial migration"

5、更新数据库
检查并修正好迁移脚本后,可以使用 db upgrade 命令将迁移应用到数据库中:
python hello.py db uograde

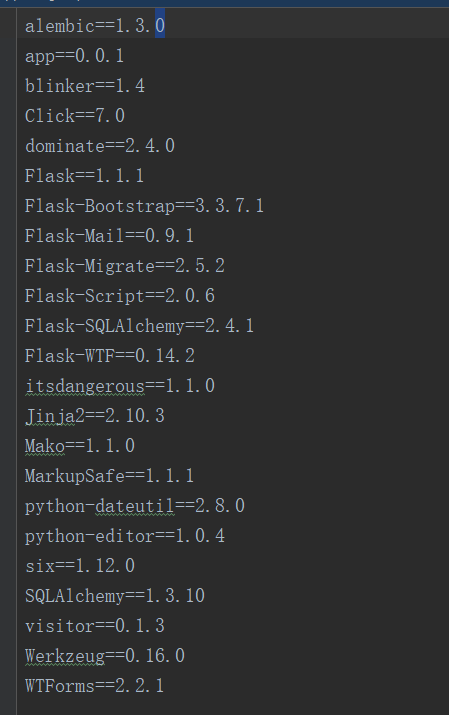
生成需求文件
pip freeze >requirements.txt

在新的虚拟环境中创建完整副本
pip install -r requirements.txt
