
使用kubeadm的方式搭建k8s(1.18.2版本)高可用集群
kubernetes高可用部署参考:
https://kubernetes.io/docs/setup/independent/high-availability/
https://github.com/kubernetes-sigs/kubespray
https://github.com/wise2c-devops/breeze
https://github.com/cookeem/kubeadm-ha
一、拓扑选择
配置高可用(HA)Kubernetes集群,有以下两种可选的etcd拓扑:
- 集群master节点与etcd节点共存,etcd也运行在控制平面节点上
- 使用外部etcd节点,etcd节点与master在不同节点上运行
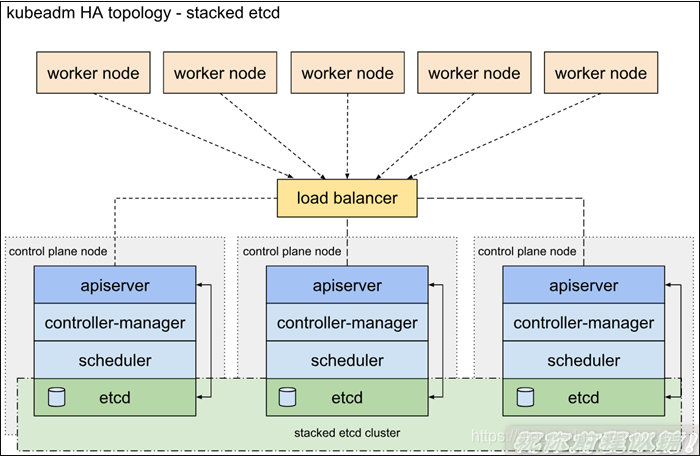
1.1 堆叠的etcd拓扑
堆叠HA集群是这样的拓扑,其中etcd提供的分布式数据存储集群与由kubeamd管理的运行master组件的集群节点堆叠部署。
每个master节点运行kube-apiserver,kube-scheduler和kube-controller-manager的一个实例。kube-apiserver使用负载平衡器暴露给工作节点。
每个master节点创建一个本地etcd成员,该etcd成员仅与本节点kube-apiserver通信。这同样适用于本地kube-controller-manager 和kube-scheduler实例。
该拓扑将master和etcd成员耦合在相同节点上。比设置具有外部etcd节点的集群更简单,并且更易于管理复制。
但是,堆叠集群存在耦合失败的风险。如果一个节点发生故障,则etcd成员和master实例都将丢失,并且冗余会受到影响。您可以通过添加更多master节点来降低此风险。
因此,您应该为HA群集运行至少三个堆叠的master节点。
这是kubeadm中的默认拓扑。使用kubeadm init和kubeadm join --experimental-control-plane命令时,在master节点上自动创建本地etcd成员。
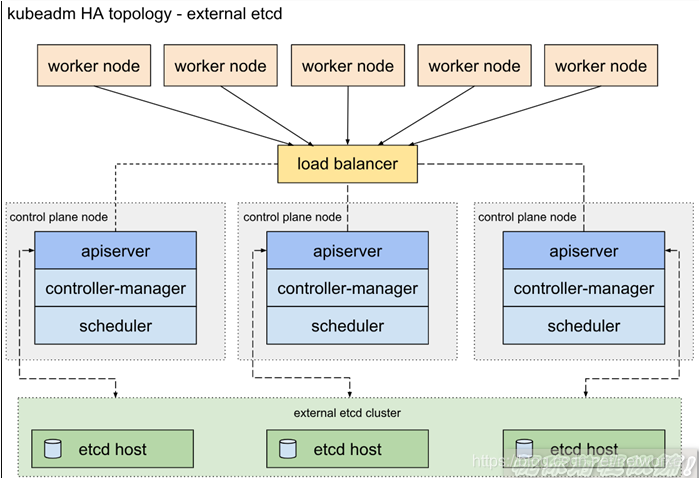
1.2 外部etcd拓扑
具有外部etcd的HA集群是这样的拓扑,其中由etcd提供的分布式数据存储集群部署在运行master组件的节点形成的集群外部。
像堆叠ETCD拓扑结构,在外部ETCD拓扑中的每个master节点运行一个kube-apiserver,kube-scheduler和kube-controller-manager实例。并且kube-apiserver使用负载平衡器暴露给工作节点。但是,etcd成员在不同的主机上运行,每个etcd主机与kube-apiserver每个master节点进行通信。
此拓扑将master节点和etcd成员分离。因此,它提供了HA设置,其中丢失master实例或etcd成员具有较小的影响并且不像堆叠的HA拓扑那样影响集群冗余。
但是,此拓扑需要两倍于堆叠HA拓扑的主机数。具有此拓扑的HA群集至少需要三个用于master节点的主机和三个用于etcd节点的主机。
二、部署要求
使用kubeadm部署高可用性Kubernetes集群的两种不同方法:
- 使用堆叠master节点。这种方法需要较少的基础设施,etcd成员和master节点位于同一位置。
- 使用外部etcd集群。这种方法需要更多的基础设施, master节点和etcd成员是分开的。
2.1 部署要求
- 至少3个master节点
- 至少3个worker节点
- 所有节点网络全部互通(公共或私有网络)
- 所有机器都有sudo权限
- 从一个设备到系统中所有节点的SSH访问
- 所有节点安装kubeadm和kubelet,kubectl是可选的。
- 针对外部etcd集群,你需要为etcd成员额外提供3个节点
三、基本配置
3.1 节点信息:
| 主机名 | IP地址 | 角色 | CPU/MEM | 磁盘 |
|---|---|---|---|---|
| k8s-master01 | 192.168.100.235 | master | 4C8G | 100G |
| k8s-master02 | 192.168.100.236 | master | 4C8G | 100G |
| k8s-master03 | 192.168.100.237 | master | 4C8G | 100G |
| k8s-node01 | 192.168.100.238 | node | 4C8G | 100G |
| K8S VIP | 192.168.100.201 | – | – | - |
3.2 初始化
#配置主机名
$ hostnamectl set-hostname k8s-master01
$ hostnamectl set-hostname k8s-master02
$ hostnamectl set-hostname k8s-master03
$ hostnamectl set-hostname k8s-node01
#修改/etc/hosts
$ cat >> /etc/hosts << EOF
192.168.100.235 k8s-master01
192.168.100.236 k8s-master02
192.168.100.237 k8s-master03
192.168.100.238 k8s-node01
192.168.100.201 k8s-slb
EOF
# 开启firewalld防火墙并允许所有流量
$ systemctl stop firewalld && systemctl disable firewalld
# 关闭selinux
$ sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config && setenforce 0
#关闭swap
$ swapoff -a
$ yes | cp /etc/fstab /etc/fstab_bak
$ cat /etc/fstab_bak | grep -v swap > /etc/fstab
3.3 配置时间同步
为了简单起见,就使用ntp进行时间同步了!
# 时间同步
$ yum install ntpdate -y
$ ntpdate ntp.aliyun.com
$ timedatectl set-timezone Asia/Shanghai
3.4 内核升级
参考博文:https://www.cnblogs.com/lvzhenjiang/p/14115440.html
升级完成后,内核版本:
$ uname -r
4.4.248-1.el7.elrepo.x86_64
3.5 加载IPVS模块
# 在所有的Kubernetes节点执行以下脚本(若内核大于4.19替换nf_conntrack_ipv4为nf_conntrack):
$ cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
#执行脚本
$ chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
#安装相关管理工具
$ yum install ipset ipvsadm -y
3.6 配置内核参数
$ cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_forward = 1
vm.swappiness=0
EOF
$ sysctl --system
四、负载均衡
部署集群前首选需要为kube-apiserver创建负载均衡器。
注意:负载平衡器有许多中配置方式。可以根据你的集群要求选择不同的配置方案。在云环境中,您应将master节点作为负载平衡器TCP转发的后端。此负载平衡器将流量分配到其目标列表中的所有健康master节点。apiserver的运行状况检查是对kube-apiserver侦听的端口的TCP检查(默认值:6443)。
负载均衡器必须能够与apiserver端口上的所有master节点通信。它还必须允许其侦听端口上的传入流量。另外确保负载均衡器的地址始终与kubeadm的ControlPlaneEndpoint地址匹配。
haproxy/nignx+keepalived是其中可选的负载均衡方案,针对公有云环境可以直接使用运营商提供的负载均衡产品。
部署时首先将第一个master节点添加到负载均衡器并使用以下命令测试连接:
$ nc -v LOAD_BALANCER_IP PORT
由于apiserver尚未运行,因此预计会出现连接拒绝错误。但是,超时意味着负载均衡器无法与master节点通信。如果发生超时,请重新配置负载平衡器以与master节点通信。将剩余的master节点添加到负载平衡器目标组。
4.1 安装负载均衡相关软件
$ yum install haproxy keepalived -y
4.2 配置haproxy
所有master节点的配置相同,如下:
注意:把apiserver地址改成自己节点规划的master地址
$ vim /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server k8s-master01 192.168.100.235:6443 check
server k8s-master02 192.168.100.236:6443 check
server k8s-master03 192.168.100.237:6443 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:9999
stats auth admin:P@ssW0rd
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
4.3 配置keepalived
k8s-master01
$ cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
# 定义脚本
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.100.201
}
}
EOF
k8s-master02
$ cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
# 定义脚本
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.100.201
}
}
EOF
k8s-master03
$ cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
# 定义脚本
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.100.201
}
}
EOF
4.4 编写健康监测脚本
$ vim /etc/keepalived/check-apiserver.sh
#!/bin/bash
function check_apiserver(){
for ((i=0;i<5;i++))
do
apiserver_job_id=${pgrep kube-apiserver}
if [[ ! -z ${apiserver_job_id} ]];then
return
else
sleep 2
fi
apiserver_job_id=0
done
}
# 1->running 0->stopped
check_apiserver
if [[ $apiserver_job_id -eq 0 ]];then
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
$ chmod 755 /etc/keepalived/check-apiserver.sh
4.5 启动haproxy和keepalived
$ systemctl enable --now keepalived
$ systemctl enable --now haproxy
五、安装docker
# 安装依赖软件包
$ yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加Docker repository,这里改为国内阿里云yum源
$ yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce
$ yum clean all && yum makecache && yum install -y docker-ce
## 创建 /etc/docker 目录
$ mkdir /etc/docker
# 配置镜像加速
$ echo "{\"registry-mirrors\": [\"https://registry.cn-hangzhou.aliyuncs.com\"]}" >> /etc/docker/daemon.json
# 重启docker服务
$ systemctl daemon-reload && systemctl restart docker && systemctl enable docker
六、安装kubeadm
#由于官方源国内无法访问,这里使用阿里云yum源进行替换:
$ cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
$ yum install -y kubelet-1.18.2 kubeadm-1.18.2 kubectl-1.18.2 --disableexcludes=kubernetes
$ systemctl enable kubelet && systemctl start kubelet
七、部署k8s master、node节点
初始化参考:
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/
https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta1
7.1 创建初始化配置文件
可以使用如下命令生成初始化配置文件:
$ kubeadm config print init-defaults > kubeadm-config.yaml
根据实际部署环境修改信息:
apiVersion: kubeadm.k8s.io/v1beta1
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.100.235
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "k8s-slb:16443"
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.14.1
networking:
dnsDomain: cluster.local
podSubnet: "10.244.0.0/16"
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
配置说明:
- controlPlaneEndpoint:为vip地址和haproxy监听端口16443
- imageRepository:由于国内无法访问google镜像仓库k8s.gcr.io,这里指定为阿里云镜像仓库registry.aliyuncs.com/google_containers
- podSubnet:指定的IP地址段与后续部署的网络插件相匹配,这里需要部署flannel插件,所以配置为10.244.0.0/16
- mode: ipvs:最后追加的配置为开启ipvs模式。
在集群搭建完成后可以使用如下命令查看生效的配置文件:
$ kubectl -n kube-system get cm kubeadm-config -oyaml
7.2 初始化master01节点
这里追加tee命令将初始化日志输出到kubeadm-init.log中以备用(可选)。
k8s v1.16 之前
$ kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log
k8s v1.16 之后
$ kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log
该命令指定了初始化时需要使用的配置文件,其中添加–experimental-upload-certs或--upload-certs参数可以在后续执行加入节点时自动分发证书文件。
kubeadm init主要执行了以下操作:
- [init]:指定版本进行初始化操作
- [preflight] :初始化前的检查和下载所需要的Docker镜像文件
- [kubelet-start]:生成kubelet的配置文件”/var/lib/kubelet/config.yaml”,没有这个文件kubelet无法启动,所以初始化之前的kubelet实际上启动失败。
- [certificates]:生成Kubernetes使用的证书,存放在/etc/kubernetes/pki目录中。
- [kubeconfig] :生成 KubeConfig 文件,存放在/etc/kubernetes目录中,组件之间通信需要使用对应文件。
- [control-plane]:使用/etc/kubernetes/manifest目录下的YAML文件,安装 Master 组件。
- [etcd]:使用/etc/kubernetes/manifest/etcd.yaml安装Etcd服务。
- [wait-control-plane]:等待control-plan部署的Master组件启动。
- [apiclient]:检查Master组件服务状态。
- [uploadconfig]:更新配置
- [kubelet]:使用configMap配置kubelet。
- [patchnode]:更新CNI信息到Node上,通过注释的方式记录。
- [mark-control-plane]:为当前节点打标签,打了角色Master,和不可调度标签,这样默认就不会使用Master节点来运行Pod。
- [bootstrap-token]:生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
- [addons]:安装附加组件CoreDNS和kube-proxy
说明:无论是初始化失败或者集群已经完全搭建成功,你都可以直接执行kubeadm reset命令清理集群或节点,然后重新执行kubeadm init或kubeadm join相关操作即可。
7.3 配置kubectl
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ yum -y install bash-completion
$ source /usr/share/bash-completion/bash_completion
$ source <(kubectl completion bash)
$ echo "source <(kubectl completion bash)" >> ~/.bashrc
7.4 查看当前状态
$ kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
7.5 安装网络插件
kubernetes支持多种网络方案,这里简单介绍常用的flannel和calico安装方法,选择其中一种方案进行部署即可。
以下操作在master01节点执行即可。
安装flannel网络插件:
由于kube-flannel.yml文件指定的镜像从coreos镜像仓库拉取,可能拉取失败,可以从dockerhub搜索相关镜像进行替换,另外可以看到yml文件中定义的网段地址段为10.244.0.0/16。
$ wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
$ cat kube-flannel.yml | grep image
$ cat kube-flannel.yml | grep 10.244
$ sed -i 's#quay.io/coreos/flannel:v0.11.0-amd64#willdockerhub/flannel:v0.11.0-amd64#g' kube-flannel.yml
$ kubectl apply -f kube-flannel.yml
安装calico网络插件(可选):
安装参考:https://docs.projectcalico.org/v3.6/getting-started/kubernetes/
$ wget https://kuboard.cn/install-script/calico/calico-3.9.2.yaml
$ cat calico-3.9.2.yaml | grep 10.244
$ kubectl apply -f calico-3.9.2.yaml
注意该yaml文件中默认CIDR为192.168.0.0/16,需要与初始化时kube-config.yaml中的配置一致,如果不同请下载该yaml修改后运行。
7.6 添加master节点
从初始化输出或kubeadm-init.log中获取命令:
$ kubeadm join k8s-slb:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:36c5f93203130cea88d162f28d54cd47f07f887c470e8a2f1b11d0ee48ef5b28 \
--control-plane --certificate-key afe2d59c138e7f0c16344c58fe4981069e21570f848f5ba50531f8f698f75302
执行以上命令,依次将k8s-master02和k8s-master03加入到集群中!
7.7 添加node节点
$ kubeadm join k8s-slb:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:36c5f93203130cea88d162f28d54cd47f07f887c470e8a2f1b11d0ee48ef5b28
八、集群验证
8.1 查看node节点运行情况
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready master 2m30s v1.18.2
k8s-master02 Ready master 2m34s v1.18.2
k8s-master03 Ready master 2m37s v1.18.2
k8s-node01 Ready <none> 2m49s v1.18.2
8.2 查看pod运行情况
$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-7d94cd8f86-b8vzs 1/1 Running 0 8m6s 10.224.32.130 k8s-master01 <none> <none>
calico-node-4rqj8 1/1 Running 0 3m47s 192.168.100.236 k8s-master02 <none> <none>
calico-node-94sw6 1/1 Running 0 5m20s 192.168.100.238 k8s-node01 <none> <none>
calico-node-gk7hg 1/1 Running 0 8m7s 192.168.100.235 k8s-master01 <none> <none>
calico-node-vpll4 1/1 Running 0 5m8s 192.168.100.237 k8s-master03 <none> <none>
coredns-7ff77c879f-97tjw 1/1 Running 0 11m 10.224.32.131 k8s-master01 <none> <none>
coredns-7ff77c879f-mp98g 1/1 Running 0 11m 10.224.32.129 k8s-master01 <none> <none>
etcd-k8s-master01 1/1 Running 0 11m 192.168.100.235 k8s-master01 <none> <none>
etcd-k8s-master02 1/1 Running 0 3m45s 192.168.100.236 k8s-master02 <none> <none>
etcd-k8s-master03 1/1 Running 0 4m41s 192.168.100.237 k8s-master03 <none> <none>
kube-apiserver-k8s-master01 1/1 Running 0 11m 192.168.100.235 k8s-master01 <none> <none>
kube-apiserver-k8s-master02 1/1 Running 1 3m47s 192.168.100.236 k8s-master02 <none> <none>
kube-apiserver-k8s-master03 1/1 Running 0 5m7s 192.168.100.237 k8s-master03 <none> <none>
kube-controller-manager-k8s-master01 1/1 Running 1 11m 192.168.100.235 k8s-master01 <none> <none>
kube-controller-manager-k8s-master02 1/1 Running 0 3m47s 192.168.100.236 k8s-master02 <none> <none>
kube-controller-manager-k8s-master03 1/1 Running 0 5m7s 192.168.100.237 k8s-master03 <none> <none>
kube-proxy-66ntf 1/1 Running 0 5m8s 192.168.100.237 k8s-master03 <none> <none>
kube-proxy-7n7nw 1/1 Running 0 11m 192.168.100.235 k8s-master01 <none> <none>
kube-proxy-8qknh 1/1 Running 0 5m20s 192.168.100.238 k8s-node01 <none> <none>
kube-proxy-rhqf4 1/1 Running 0 3m47s 192.168.100.236 k8s-master02 <none> <none>
kube-scheduler-k8s-master01 1/1 Running 1 11m 192.168.100.235 k8s-master01 <none> <none>
kube-scheduler-k8s-master02 1/1 Running 0 3m46s 192.168.100.236 k8s-master02 <none> <none>
kube-scheduler-k8s-master03 1/1 Running 0 5m8s 192.168.100.237 k8s-master03 <none> <none>
8.3 验证IPVS
查看kube-proxy日志,输出信息包含Using ipvs Proxier.
$ kubectl logs -f kube-proxy-8qknh -n kube-system
W1221 10:19:43.092405 1 feature_gate.go:235] Setting GA feature gate SupportIPVSProxyMode=true. It will be removed in a future release.
W1221 10:19:43.092936 1 feature_gate.go:235] Setting GA feature gate SupportIPVSProxyMode=true. It will be removed in a future release.
I1221 10:19:43.590876 1 node.go:136] Successfully retrieved node IP: 192.168.100.238
I1221 10:19:43.590973 1 server_others.go:259] Using ipvs Proxier.
W1221 10:19:43.591887 1 proxier.go:429] IPVS scheduler not specified, use rr by default
I1221 10:19:43.592412 1 server.go:583] Version: v1.18.2
I1221 10:19:43.593666 1 conntrack.go:100] Set sysctl 'net/netfilter/nf_conntrack_max' to 131072
I1221 10:19:43.593763 1 conntrack.go:52] Setting nf_conntrack_max to 131072
I1221 10:19:43.593944 1 conntrack.go:100] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_established' to 86400
I1221 10:19:43.594082 1 conntrack.go:100] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_close_wait' to 3600
I1221 10:19:43.594668 1 config.go:133] Starting endpoints config controller
I1221 10:19:43.594728 1 shared_informer.go:223] Waiting for caches to sync for endpoints config
I1221 10:19:43.594789 1 config.go:315] Starting service config controller
I1221 10:19:43.594808 1 shared_informer.go:223] Waiting for caches to sync for service config
I1221 10:19:43.695036 1 shared_informer.go:230] Caches are synced for service config
I1221 10:19:43.695053 1 shared_informer.go:230] Caches are synced for endpoints config
8.4 etcd集群验证
$ kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl --endpoints=https://192.168.100.235:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key member list -wtable
+------------------+---------+--------------+------------------------------+------------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------------+------------------------------+------------------------------+------------+
| b22d109a6211c55 | started | k8s-master02 | https://192.168.100.236:2380 | https://192.168.100.236:2379 | false |
| c07cc16c40f2638 | started | k8s-master01 | https://192.168.100.235:2380 | https://192.168.100.235:2379 | false |
| f122e0cdce559ffc | started | k8s-master03 | https://192.168.100.237:2380 | https://192.168.100.237:2379 | false |
+------------------+---------+--------------+------------------------------+------------------------------+------------+
$ kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl --endpoints=https://192.168.100.235:2379,https://192.168.100.236:2379,https://192.168.100.237:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key endpoint status
https://192.168.100.235:2379, c07cc16c40f2638, 3.4.3, 3.8 MB, true, false, 15, 6776, 6776,
https://192.168.100.236:2379, b22d109a6211c55, 3.4.3, 3.7 MB, false, false, 15, 6776, 6776,
https://192.168.100.237:2379, f122e0cdce559ffc, 3.4.3, 3.7 MB, false, false, 15, 6776, 6776,
8.5 验证HA
在master01上执行关机操作,建议提前在其他节点配置kubectl命令支持。
$ shutdown -h now
在任意运行节点验证集群状态,master01节点NotReady,集群可正常访问:
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady master 33m v1.18.2
k8s-master02 Ready master 26m v1.18.2
k8s-master03 Ready master 27m v1.18.2
k8s-node01 Ready <none> 27m v1.18.2
查看网卡,vip自动漂移到master02节点
$ ip a | grep 192.168
inet 192.168.100.236/24 brd 192.168.100.255 scope global eth0
inet 192.168.100.201/32 scope global eth0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号