
Linux三剑客那点事
一、正则表达式
1.1 正则表达式?
- 匹配有规律的东西:手机号、身份证号、匹配日志
- 正则表达式就出来了,regular expression(RE)
- 使用一些符号表达重复出现,大小写,开头/结尾含义
1.2 应用场景?
| 正则表达式 | Linux三剑客使用,开发语言(python、golang…………) |
| 应用场景 | 过滤有规律的内容,尤其是日志 |
1.3 正则注意事项
- 所有的符号(英文符号)
- 学习正则,通过grep命令歇息,grep加上单引号
- 给grep、egrep加上颜色
alias grep='grep --color=auto' alias egrep='egrep --color=auto' - 注意系统的字符集:
en_US、UTF-8(大部分情况90%,没问题),如果出现问题修改字符集为export LANG=C - 快速掌握正则:配合
grep -o参数学习
1.4 正则符号
| 分类 | 命令 | |
|---|---|---|
| 基础正则 | 、$、$、*、.*、[a-z]、[^abc] | grep、sed、awk |
| 扩展正则 | +、|、()、{}、? | egerp、sed -r、awk |
1.5 正则VS通配符
| 分类 | 诞生目标(用途) | 支持的命令 |
|---|---|---|
| 正则(re) | 三剑客,高级语言,进行过滤(匹配字符) | 三剑客:grep、sed、awk、find、rename(ubuntu)、expr |
| 通配符(pathname extension 或 glob) | 匹配文件(文件名) *.txt、*.log、 | Linux下面大部分命令都支持 |
1.6 基础正则
$ cat oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my qq is 49000448
not 49000000448.
my god,i am not oldbey,but OLDBOY!
1.6.1 ^ 以……开头的行
^oldboy:过滤以oldboy开头的行
$ grep '^oldboy' oldboy.txt
1.6.2 $ 以……结尾的行
448$:以448结尾的行
$ grep '448$' oldboy.txt
my qq is 49000448
$ grep '448' oldboy.txt
my qq is 49000448
not 49000000448.
- 找出以
m结尾的行
$ cat -A oldboy.txt
I am oldboy teacher!$
I teach linux.$
$
I like badminton ball,billiard ball and chinese chess!$
my blog is http://oldboy.blog.51cto.com $
our size is http://blog.oldboyedu.com $
my qq is 49000448$
$
not 49000000448.$
my god,i am not oldbey,but OLDBOY!$
$ grep 'm$' oldboy.txt
$ grep 'm $' oldboy.txt
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
1.6.3 ^$空行
- 空行这一行中没有任何内容(空格也是符合)
- 空格也是个字符
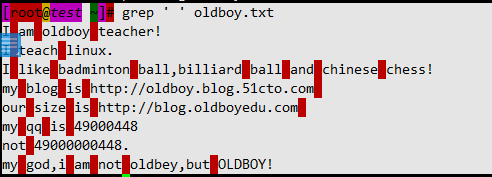
$ grep -n '^$' oldboy.txt
3:
8:
$ cat -n oldboy.txt
1 I am oldboy teacher!
2 I teach linux.
3
4 I like badminton ball,billiard ball and chinese chess!
5 my blog is http://oldboy.blog.51cto.com
6 our size is http://blog.oldboyedu.com
7 my qq is 49000448
8
9 not 49000000448.
10 my god,i am not oldbey,but OLDBOY
-
企业应用案例:
-
排除文件中的空行
$ grep -v '^$' oldboy.txt I am oldboy teacher! I teach linux. I like badminton ball,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com my qq is 49000448 not 49000000448. my god,i am not oldbey,but OLDBOY! $ grep -vn '^$' oldboy.txt 1:I am oldboy teacher! 2:I teach linux. 4:I like badminton ball,billiard ball and chinese chess! 5:my blog is http://oldboy.blog.51cto.com 6:our size is http://blog.oldboyedu.com 7:my qq is 49000448 9:not 49000000448. 10:my god,i am not oldbey,but OLDBOY!
-
1.6.4 . :表示任意一个字符
- 注意不能匹配空行
$ grep '.' oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my qq is 49000448
not 49000000448.
my god,i am not oldbey,but OLDBOY!
1.6.5 \:转义字符
- 匹配出文件中以
.结尾的行
$ grep '.$' oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my qq is 49000448
not 49000000448.
my god,i am not oldbey,but OLDBOY!
$ grep '\.$' oldboy.txt
I teach linux.
not 49000000448.
- 转义字符序列
- \n:回车换行
- \t:tab键
1.6.6 *:前一个字符连续出现0次或0次以上
-
连续出现
$ grep '0*' oldboy.txt I am oldboy teacher! I teach linux. I like badminton ball,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com my qq is 49000448 not 49000000448. my god,i am not oldbey,but OLDBOY!
1.6.7 .*:任意内容
- 整体记忆:
*表示所有即可! - 了解:
.任意一个字符;+前一个字符连续出现0次或0次以上!
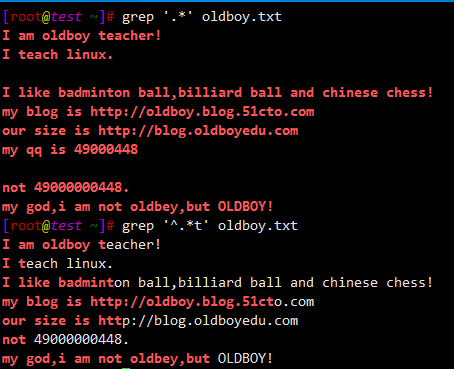
$ grep '^.*t' oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
not 49000000448.
my god,i am not oldbey,but OLDBOY!
- 正则特色:正则表达式的贪婪性
$ cat oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my qq is 49000448
not 49000000448.
my god,i am not oldbey,but OLDBOY!
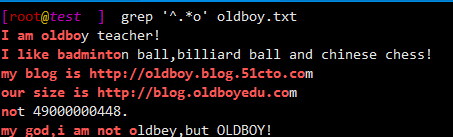
$ grep '^.*o' oldboy.txt
I am oldboy teacher!
I like badminton ball,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
not 49000000448.
my god,i am not oldbey,but OLDBOY!
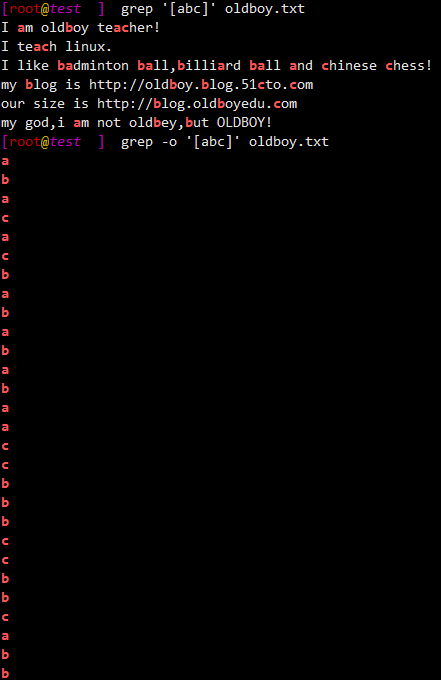
1.6.8 []、[abc]:1次匹配1个字符,匹配任意一个字符(a或b或c)
$ grep '[abc]' oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my god,i am not oldbey,but OLDBOY!
# 显示匹配过程
$ grep -o '[abc]' oldboy.txt
a
b
a
c
a
c
b
a
b
a
b
a
b
a
a
c
c
b
b
b
c
c
b
b
c
a
b
b
[a-z]:所有小写字符[A-Z]:所有大写字符[0-9]:所有数字[a-zA-Z0-9]、[a-Z0-9]:所有字母、数字
$ grep '[a-z]' oldboy.txt
$ grep '[A-Z]' oldboy.txt
$ grep '[0-9]' oldboy.txt
$ grep '[a-zA-Z0-9]' oldboy.txt
$ grep '[a-Z0-9]' oldboy.txt
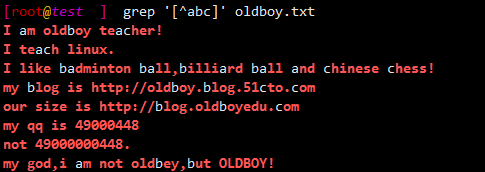
1.6.9 [^]、[^abc]:取反,排除a或b或c
$ grep '[^abc]' oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my qq is 49000448
not 49000000448.
my god,i am not oldbey,but OLDBOY!
1.6.10 总结
| 基础正则 | 含义 |
|---|---|
| ^ | 以……开头的行 |
| $ | 以……结尾的行 |
| ^$ | 空行 |
| . | 任意一个字符 |
| * | 前一个字符连续出现(重复)0次或0次以上 |
| .* | 所有内容 |
| \ | 转移字符,\n、\t |
| [] | 一个整体,匹配任意一个字符[abc],a或b或c |
| [^] | 取反、排除[^abc] |
| 正则贪婪性 | 熟悉特点就OK,.*或连续出现 |
1.7 扩展正则
1.7.1 +:前一个字符出现1次或1次以上
$ grep '0+' oldboy.txt
$ egrep '0+' oldboy.txt
my qq is 49000448
not 49000000448.
$ grep -E '0+' oldboy.txt
my qq is 49000448
not 49000000448.
# 了解
$ grep '0\+' oldboy.txt
my qq is 49000448
not 49000000448.
- 匹配出文件中连续的数字
$ egrep '[0-9]+' oldboy.txt
my blog is http://oldboy.blog.51cto.com
my qq is 49000448
not 49000000448.
1.7.2 |:或者
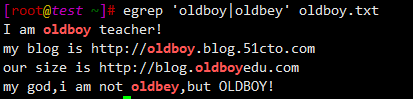
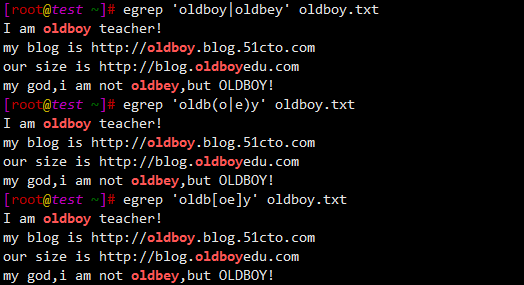
$ egrep 'oldboy|oldbey' oldboy.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my god,i am not oldbey,but OLDBOY!
1.7.3 []或|区别
| 符号 | 含义 |
|---|---|
| [] | 1次匹配1个字符 |
| | | 匹配1个字符或多个 |
1.7.4 ():表示被括起来的内容,表示一个整体(一个字符),后向引用(反向引用,sed)
- 被括起来的内容,表示一个整体(一个字符)
- 后向引用(反向引用,sed)
$ egrep 'oldboy|oldbey' oldboy.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my god,i am not oldbey,but OLDBOY!
$ egrep 'oldb(o|e)y' oldboy.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my god,i am not oldbey,but OLDBOY!
$ egrep 'oldb[oe]y' oldboy.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my god,i am not oldbey,but OLDBOY!
1.7.5 {}:连续出现
| 符号 | 含义 | |
|---|---|---|
| o | 前一个字母o,至少连续出现n次,最多连续出现m次 | >=n <=m |
| o | 前一个字母o,连续出现n次 | ==n |
| o | 前一个字母o,至少连续出现n次 | >=n |
| o | 前一个字母o,最多连续出现n次 | <=m |
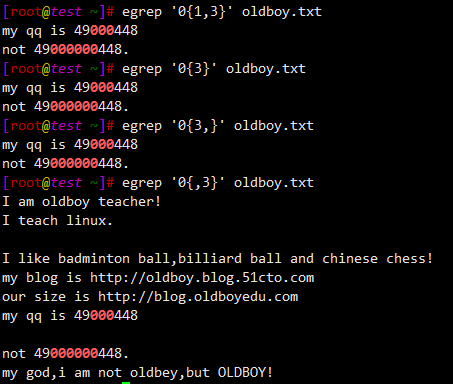
$ egrep '0{1,3}' oldboy.txt
my qq is 49000448
not 49000000448.
$ egrep '0{3}' oldboy.txt
my qq is 49000448
not 49000000448.
$ egrep '0{3,}' oldboy.txt
my qq is 49000448
not 49000000448.
$ egrep '0{,3}' oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our size is http://blog.oldboyedu.com
my qq is 49000448
not 49000000448.
my god,i am not oldbey,but OLDBOY!
1.7.6 ?:连续出现,前一个字符出现0次或1次
$ cat wen.txt
gooood
goood
good
god
gd
$ egrep 'god|gd' wen.txt
god
gd
$ egrep 'go?d' wen.txt
god
gd
1.7.7 总结
| 符号 | 含义 |
|---|---|
| + | 前一个字符连续出现1次或1次以上 |
| | | 或者 |
| () | 一个整体,sed反向引用 |
| {} | o{n,m}:前一个字母o,至少连续出现n次,最多连续出现m次 |
| ? | 前一个字符连续出现0次或1次 |
二、三剑客
2.1 三剑客特点及应用场景
| 命令 | 特点 | 场景 |
|---|---|---|
| grep | 过滤 | grep命令过滤速度是最快的 |
| sed | 替换,修改文件内容,取行 | 如果进行替换/修改文件 取出某个范围的内容 |
| awk | 取列,统计计算 | 取列 对比,比较 统计,计算(awk数组) |
2.2 三剑客——grep
| 选项 | 含义 |
|---|---|
| -E | egrep 支持扩展正则 |
| -A | after -A5:匹配你要的内容显示接下面的5行 |
| -B | before -B5:匹配你要的内容显示接上面的5行 |
| -C | context -C5:匹配你要的内容显示接上下5行 |
| -c | 统计出现了多少次,类似于wc -l |
| -v | 取反,排除(行) |
| -n | 显示行号 |
| -i | 忽略大小写 |
| -w | 精确匹配 |
# -A
$ seq 10 | grep -A3 5
5
6
7
8
# -B
$ seq 10 | grep -B3 5
2
3
4
5
# -C
$ seq 10 | grep -C3 5
2
3
4
5
6
7
8
# -c
$ ps -ef | grep sshd | wc -l
4
$ ps -ef | grep -c sshd
4
# -v
$ ps -ef | grep crond | grep -v grep
# 可以使用下面这种简单的方法
$ ps -ef | grep '[c]rond'
# -w
$ ss -lnt | grep -w 22
2.3 三剑客——sed
2.3.1 特点及格式
- sed:stream editor 流编辑器
- sed格式
| 命令 | 选项 | sed命令功能 | 参数(文件) |
|---|---|---|---|
| sed | -r | 's#oldboy#oldgirl#g' | oldboy.txt |
- sed命令核心功能
| 功能 | |
|---|---|
| s | 替换 |
| p | 打印 |
| d | 删除 |
| c/a/i | 增加c/a/i |
2.3.2 sed核心应用
1)sed——查找p
| 查看格式 | |
|---|---|
| '1p' '2p' | 指定行号进行查找 |
| '1,5p' | 指定行号范围进行查找 |
| '/lidao/p' | 类似于grep过滤,//里面可以写正则 |
| '/10:00/,/11:00/p' | 表示范围的过滤 |
- 指定行号查找文件内容
$ cat oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
# 指定行号
$ sed -n '2p' oldboy.txt
102,zhangyao,CTO
# 指定行号范围
$ sed -n '2,5p' oldboy.txt
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
# 从第2行到最后一行
$ sed -n '2,$p' oldboy.txt
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
- 过滤
$ sed -n '/oldboy/p' oldboy.txt
101,oldboy,CEO
$ sed -n '/10/p' oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
# 过滤包含4或者5的行
$ sed -n '/[45]/p' oldboy.txt
104,yy,CFO
105,feixue,CIO
$ sed -n '/[0-9]/p' oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
# 正则
$ sed -nr '/[0-9]+/p' oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
$ sed -nr '/[0-9]{3}/p' oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
# 范围过滤
$ sed -n '/102/,/105/p' oldboy.txt
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
2)sed——删除
- d
| 查看格式 | |
|---|---|
| '1d' '2d' | 指定行号进行查找 |
| '1,5d' | 指定行号范围进行查找 |
| '/lidao/d' | 类似于grep过滤,//里面可以写正则 |
| '/10:00/,/11:00/d' | 表示范围的过滤 |
$ sed '1d' oldboy.txt
$ sed '1,5d' oldboy.txt
$ sed '/lidao/d' oldboy.txt
- 删除文件中的空行和包含
#号的行
$ sed -r '/^$|#/d' /etc/ssh/sshd_config
$ egrep -v '^$|#' /etc/ssh/sshd_config
# !的妙用
$ sed -nr '/^$|#/!p' /etc/ssh/sshd_config
3)sed——增加c、a、i
| 命令 | ||
|---|---|---|
| c | replace:替代这行的内容 | |
| a | append:追加,向指定的行或每一行追加内容(行后面) | |
| i | insert:插入,向指定的行或每一行插入内容(行前面) |
$ cat oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
$ sed '3a 996,lidao996,UFO' oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
996,lidao996,UFO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
$ sed '3i 996,lidao996,UFO' oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
996,lidao996,UFO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
$ sed '3c 996,lidao996,UFO' oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
996,lidao996,UFO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
- 向文件中追加多行内容
# 向config中追加内容
UseDNS no
GSSAPIAUTCATION no
PermitRootLogin no
# 方法1:
$ cat >> config <<'EOF'
UseDNS no
GSSAPIAUTCATION no
PermitRootLogin no
EOF
# 方法2:
$ sed '$a UseDNS no\nGSSAPIAUTCATION no\nPermitRootLogin no' config
4)sed——替换s
- s ---> sub substitute 替换
- g ---> global 全局替换,sed替换每行所有匹配的内容,sed默认只替换每行第一个匹配的内容
| 替换 |
|---|
| s###g |
| s///g |
| s@@@g |
$ sed 's#[0-9]##' oldboy.txt
01,oldboy,CEO
02,zhangyao,CTO
03,李导996,COO
04,yy,CFO
05,feixue,CIO
10,lidao,COCO
$ sed 's#[0-9]##g' oldboy.txt
,oldboy,CEO
,zhangyao,CTO
,李导,COO
,yy,CFO
,feixue,CIO
,lidao,COCO
- 后向引用,反向引用
$ echo 123456 | sed -r 's#(.*)#<\1>#g'
<123456>
$ echo lvzhenjiang_linux | sed -r 's#(^.*)_(.*$)#\2_\1#g'
linux_lvzhenjiang
$ ip a s ens33 | sed -n '/inet/p' | sed -r 's#(^.* )(.*)(/.*$)#\2#g'
192.168.99.181
四、三剑客——awk
4.1 awk内置变量
| 内置变量 | |
|---|---|
| NR | 记录行,行号 |
| NF | 每行有多少个字段(列),$NF表示最后一列 |
| FS | -F:指定字段分隔符 |
| OFS | -vOFS:指定输出字段分隔符 |
4.2 行与列
| 名词 | awk中的叫法 | 一些说明 |
|---|---|---|
| 行 | 记录record | 每一行默认通过回车分隔的 |
| 列 | 字段,域field | 每一行默认通过空格分隔的 |
| awk中行和列结束标记都是可以修改的 |
1)取行
| awk | ||
|---|---|---|
| NR==1 | 取出某一行 | |
| NR>=1 && NR<=5 | 取出1到5行 范围 | |
| /oldboy/ | ||
| /101/,/105/ | ||
| 符号 | >、<、>=、<=、==、!= |
$ cat oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
$ awk 'NR==1' oldboy.txt
101,oldboy,CEO
$ awk 'NR>=1 && NR <=5' oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
$ awk '/oldboy/' oldboy.txt
101,oldboy,CEO
$ awk '/101/,/105/' oldboy.txt
101,oldboy,CEO
102,zhangyao,CTO
103,李导996,COO
104,yy,CFO
105,feixue,CIO
2)取列
-F:指定分隔符,指定每一列结束标记(默认是空格、连续的空格、tab键)$数字:取出某一列,注意:在awk中$内容一个意思,表示取出某一列$0:取出整行的内容$NF:表示最后一列
$ ls -l /tmp/ | awk '{print $5,$9}'
28766 kk-node01.root.history
17 systemd-private-24f3a640f6c64ab78797fb775b60002f-chronyd.service-VxcyPj
6 vmware-root_9016-2866351041
6 vmware-root_9024-3134929799
6 vmware-root_9085-4121797114
# column -t 格式化输出
$ ls -l /tmp/ | awk '{print $5,$9}' | column -t
28907 kk-node01.root.history
17 systemd-private-24f3a640f6c64ab78797fb775b60002f-chronyd.service-VxcyPj
6 vmware-root_9016-2866351041
6 vmware-root_9024-3134929799
6 vmware-root_9085-4121797114
$ ls -l /tmp/ | awk '{print $5,$NF}' | column -t
28907 kk-node01.root.history
17 systemd-private-24f3a640f6c64ab78797fb775b60002f-chronyd.service-VxcyPj
6 vmware-root_9016-2866351041
6 vmware-root_9024-3134929799
6 vmware-root_9085-4121797114
$ awk -F':' '{print $1,$NF}' /etc/passwd | column -t | head -3
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
$ awk -F':' '{print $1"@@"$NF}' /etc/passwd | column -t | head -3
root@@/bin/bash
bin@@/sbin/nologin
daemon@@/sbin/nologin
$ awk -F':' -vOFS=':' '{print $NF,$2,$3,$4,$5,$6,$1}' /etc/passwd | head -3
/bin/bash:x:0:0:root:/root:root
/sbin/nologin:x:1:1:bin:/bin:bin
/sbin/nologin:x:2:2:daemon:/sbin:daemon
4.3 awk模式匹配
$ ip a s ens33 | awk 'NR==3' | awk -F"[ /]+" '{print $3}'
192.168.99.181
- 比较符号:>、<、>=、<=、==、!=
- 正则:
- 范围表达式:
- 特殊条件:BEGIN和END
1)比较表达式——参考取行部分
2)正则:
- // 支持扩展正则
- awk可以精确到某一列,某一列中包含/不包含...内容
- ~:包含
- !~:不包含
| 正则 | awk正则 |
|---|---|
| ^表示以……开头的行 | 某一列的开头 $3~/^oldbly/ |
| $表示以……结尾的行 | 某一列的结尾 $3~/oldboy$/ |
| ^$ 表示空行 | 某一列的是空的 $3~/^$/ |
# 找出/etc/passwd/文件中第三列以1开头的行
$ awk -F':' '$3~/^1/' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
# 找出/etc/passwd文件中第三列以2开头,并显示第一列、第三列、最后一列
$ awk -F':' '$3~/^2/{print $1,$3,$NF}' /etc/passwd
daemon 2 /sbin/nologin
rpcuser 29 /sbin/nologin
# 找出/etc/passwd文件中第三列以1或者以2开头,并显示第一列、第三列、最后一列
$ awk -F':' '$3~/^[12]/{print $1,$3,$NF}' /etc/passwd
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
systemd-network 192 /sbin/nologin
rpcuser 29 /sbin/nologin
$ awk -F':' '$3~/^(1|2)/{print $1,$3,$NF}' /etc/passwd
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
systemd-network 192 /sbin/nologin
rpcuser 29 /sbin/nologin
3)表示范围
- /哪里开始/,/哪里结束/
- NR1,NR5 从第1行开始到第5行结束,类似于
sed -n '1,5p'
# 显示指定时间内范围内的IP地址
$ awk '/11:02:00/,/11:02:30/{print $1}' access.log
4)特殊模式BEGIN{}和END{}
| 模式 | 含义 | 应用场景 |
|---|---|---|
| BEGIN{} | 里面的内容会在awk读取文件之前执行 | 1)进行简单的统计,计算,不涉及读取文件(常见) 2)用来处理文件之前,添加个表头(了解) 3)用来定义awk变量(很少用) |
| END{} | 里面的内容会在awk读取文件之后执行 | 1)awk进行统计,一般过程:先进行计算,最后END输出结果(常见) 2)awk使用数组,用来输出数组结果(常见) |
$ awk '/^$/{i++}END{print i}' /etc/services
17
$ seq 100 | awk '{sum=sum+$1}END{print sum}'
5050
4.4 awk数组
| shell 数组 | awk 数组 | ||
|---|---|---|---|
| 形式 | array[0]=oldboy array[1]=lidao | array[0]=oldboy array[1]=lidao | |
| 使用 | echo ${array[0]} $ | print array[0] array[1] | |
| 批量输出数组内容 | for i in ${array[*]} do echo $i done |
for (i in array) print array[i] |
awk数组专用循环,变量获取到的是数组下标,如果想要数组的内容:数组[下标] |
# awk字母 会被识别为变量,如果只是想使用字符串需要使用双引号引起来
$ awk 'BEGIN{a[0]="oldboy"; a[1]="lidao"; print a[0],a[1]}'
oldboy lidao
$ awk 'BEGIN{a[0]="oldboy"; a[1]="lidao"; for(i in a) print i,a[i]}'
0 oldboy
1 lidao
4.5 for 循环
| shell编程C语言for循环 | awk for循环 | |
|---|---|---|
| for((i=1,i<=10,i++)) do echo $i done |
for(i=1,i<=10,i++) print i |
awk for循环用来循环每个字段 |
$ awk 'BEGIN{for(i=1;i<=100;i++)sum+=i;print sum}'
5050
4.6 if判断
| shell if判断 | awk if判断 | |
|---|---|---|
| if [ 条件 ];then echo "OK" fi |
if(条件) print "OK" |
常用 |
| if [ 条件 ];then echo "OK" else echo "not OK" fi |
if(条件) print "OK" else print "not OK" |
# 统计磁盘空间使用率,如果大于70%,则提示磁盘空间不足,并显示磁盘分区,磁盘使用率,磁盘挂载点
$ df -h | awk -F"[ %]+" 'NR>1{if($5>=75)print "disk not enough", $1,$5,$NF}'
*************** 当你发现自己的才华撑不起野心时,就请安静下来学习吧!***************

 浙公网安备 33010602011771号
浙公网安备 33010602011771号