
ElasticStack企业级实战篇
- 一、Elastic Stack在企业的常见架构
- 二、ElasticSearch和Solr的抉择
- 三、集群基础环境初始化
- 四、ElasticSearch单点部署
- 五、ElasticSearch分布式集群部署
- 六、部署kibana服务
- 七、filebeat部署及基础使用
- 八、EFK架构企业级实战案例
- 九、部署logstash环境及基础使用
- 十、logstash企业插件案例(ELK架构)
一、Elastic Stack在企业的常见架构
1.1 没有日志收集系统运维工作的日常“痛点”概述
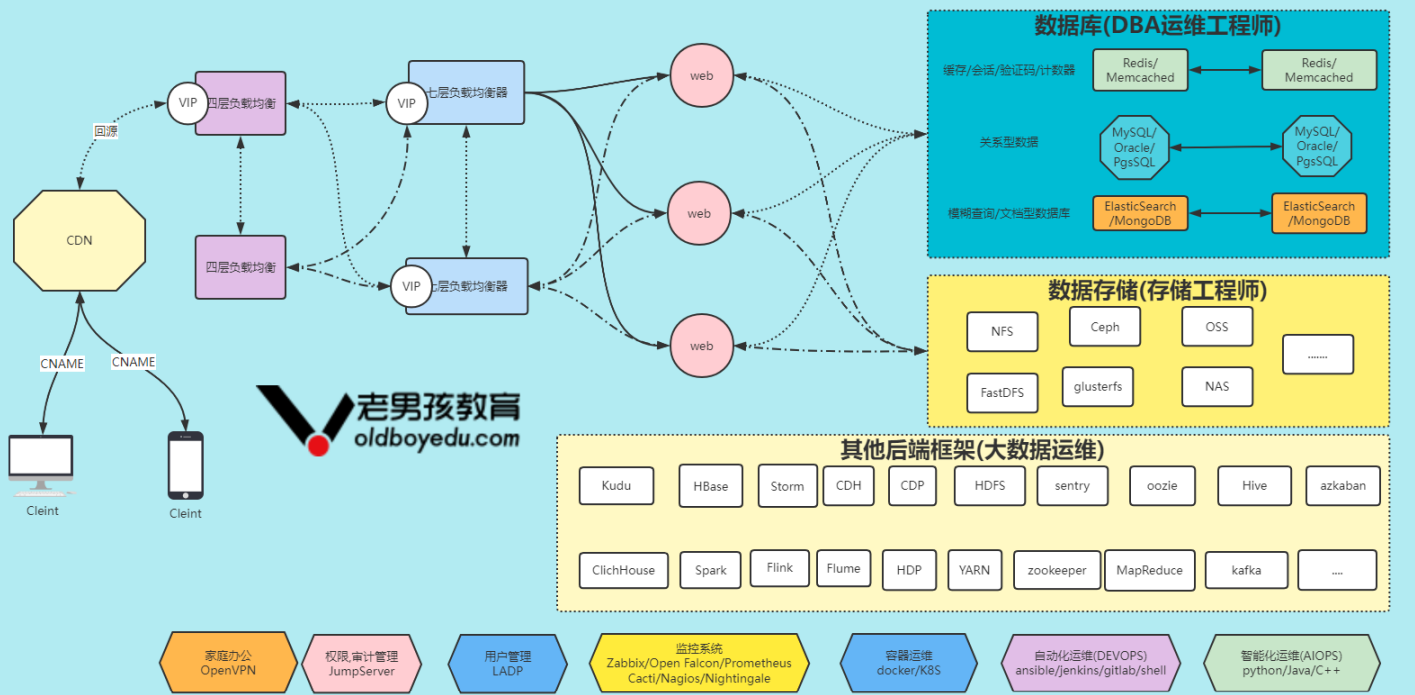
如上图所示,我简单画了一下互联网常见的一些技术栈相关架构图,请问如果让你对上图中的各组件日志进行收集,分析,存储,展示该如何做呢?
是否也会经常面临以下的运维痛点?
- 痛点1:生产出现故障后,运维需要不停的查看各种不同的日志进行分析?是不是毫无头绪?
- 痛点2:项目上线出现错误,如果快递定位问题?如果后端节点过多、日志分散怎么办?
- 痛点3:开发人员需要实时查看日志但又不想给服务器的登录权限,怎么办?难道每天都开发取日志?
- 痛点4:如果在海量的日志中快速的提取我们想要的数据?比如:PV、UV、TOP10的URL?如果分析的日志数量量过大,那么势必会导致查询速度慢、难度增大,最终会导致我们无法快速的获取想要的指标。
- 痛点5:CDN公司需要不停的分析日志,那么分析什么?主要分析命中率,为什么?因为们给用户承诺的是命中率是90%以上。如果没有达到90%,那么我们就要去分析数据为什么没有被命中、为什么没有被缓存下来。
- 痛点6:近期某影视公司周五下午频分出现被盗链的情况,导致异常流量突增2G有余,给公司带来了损失,那又该如何分析异常流量呢?
- 痛点7:上百台MYSQL实例的慢日志查询分析如何聚集?
- 痛点8:docker、K8s平台日志如何收集分析?
- 痛点N:......
如上所有的痛点都可以使用日志分析系统Elastic Stack解决,将运维所有的服务器日志,业务系统日志都收集到一个平台下,然后提取想要的内容,比如错误信息、警告信息等,当过滤到这种信息,就马上告警,告警后,运维人员就能马上定位是哪台机器、哪个业务系统出现了问题,出现了什么问题?
1.2 Elastic Stack分布式日志系统概述

The Elastic Stack,包括Elasticsearch、Kibana、Beats和Logstash(也称为ELK Stack)。
- ElasticSearch:简称ES,ES是一个开源的高扩展的分布式全文搜索引擎,是这个Elastic Stack技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台机器,处理PB级别的数据;
- Kibana:是一个免费且开放的用户界面,能够让您对ElasticSearch数据进行可视化,并让您在Elastic Stack中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
- Beats:是一个免费且开发的平台,集合了多种单一用途数据采集器。它们从成百上千机器和系统向Logstash和Elasticsearch发送数据;
- Logstash:是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的存储库中;
Elastic Stack的主要优点有如下几个:
1)处理方式灵活:elasticsearch是实时全文索引,具有强大的搜索功能;
2)配置相对简单:elasticsearch全部使用JSON接口,Logstash使用模板配置,kibana的配置文件部分更简单;
3)检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应;
4)集群线性扩展:elasticsearch和Logstash都可以灵活线性扩展;
5)前端操作绚丽:kibana的前端设计比较绚丽,而且操作简单;
使用Elastic stack能收集哪些日志:
- 容器管理工具:docker
- 容器编排工具:docker swarm、Kubernetes
- 负载均衡服务器:LVS、haproxy、nginx
- web服务器:httpd、nginx、tomcat
- 数据库: mysql,redis,MongoDB,Hbase,Kudu,ClickHouse,PostgreSQL
- 存储: nfs,gluterfs,fastdfs,HDFS,Ceph
- 系统: message,security
- 业务: 包括但不限于C,C++,Java,PHP,Go,Python,Shell等编程语言研发的App
1.3 Elastic Stack企业级“EFK”架构图解
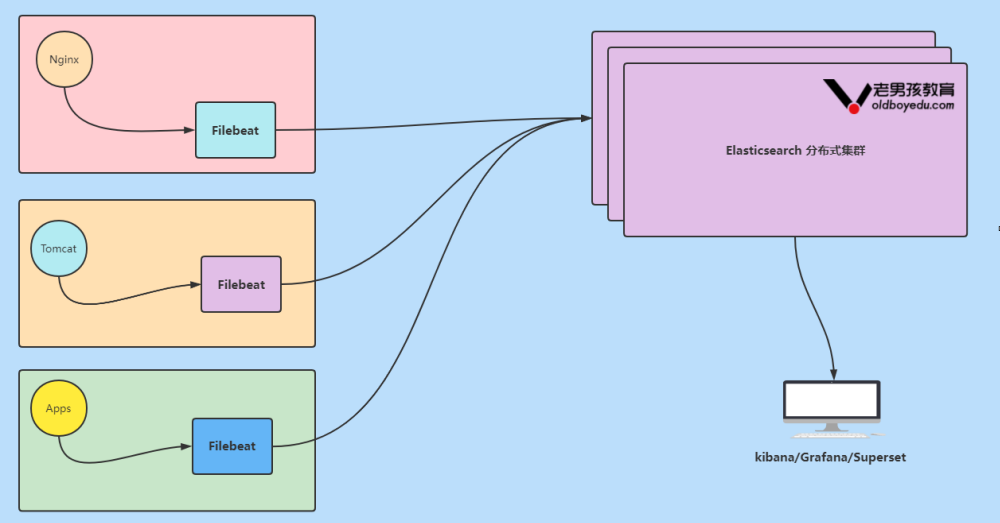
数据流走向: 源数据层(nginx,tomcat) ---> 数据采集层(filebeat) ---> 数据存储层 (ElasticSearch)。
1.4 Elastic Stack企业级“ELK”架构图解
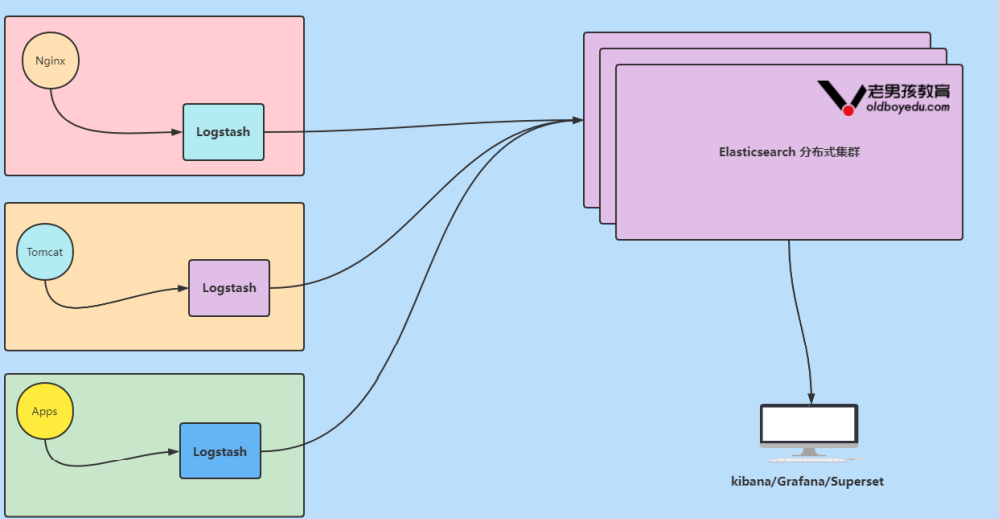
数据流走向: 源数据层(nginx,tomcat) ---> 数据采集/转换层(Logstash) ---> 数据存 储层(ElasticSearch)。
1.5 Elastic Stack企业级“ELFK”架构图解
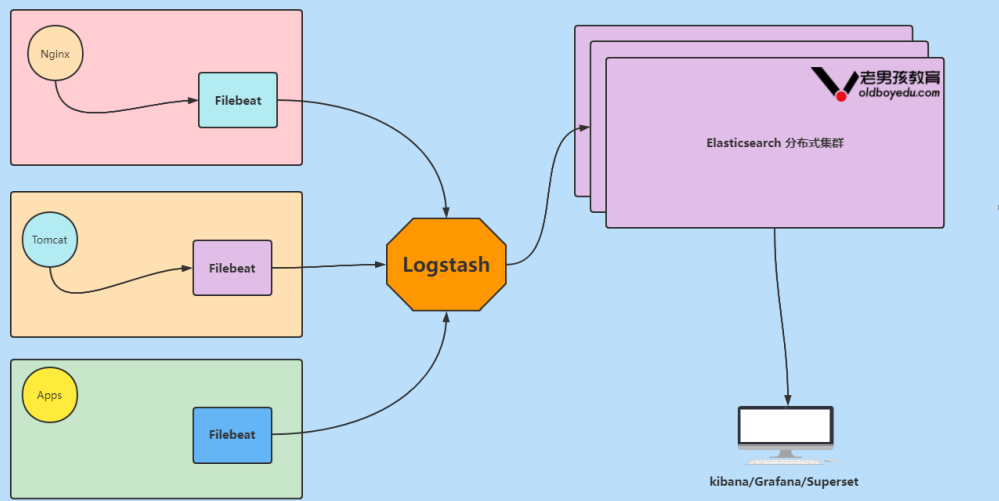
数据流走向: 源数据层(nginx,tomcat) ---> 数据采集(filebeat) ---> 转换层 (Logstash) ---> 数据存储层(ElasticSearch)。
1.6 Elastic Stack企业级“ELFK” + “kafka”架构图解
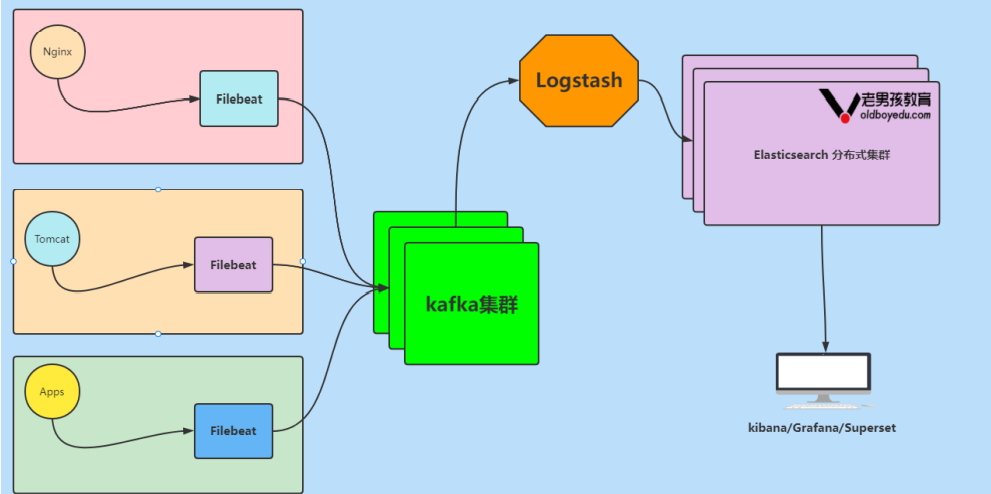
数据流走向: 源数据层(nginx,tomcat) ---> 数据采集(filebeat) ---> 数据缓存层 (kafka)---> 转换层(Logstash) ---> 数据存储层(ElasticSearch)。
1.7 Elastic Stack企业级“ELFK” + “kafka”架构演变
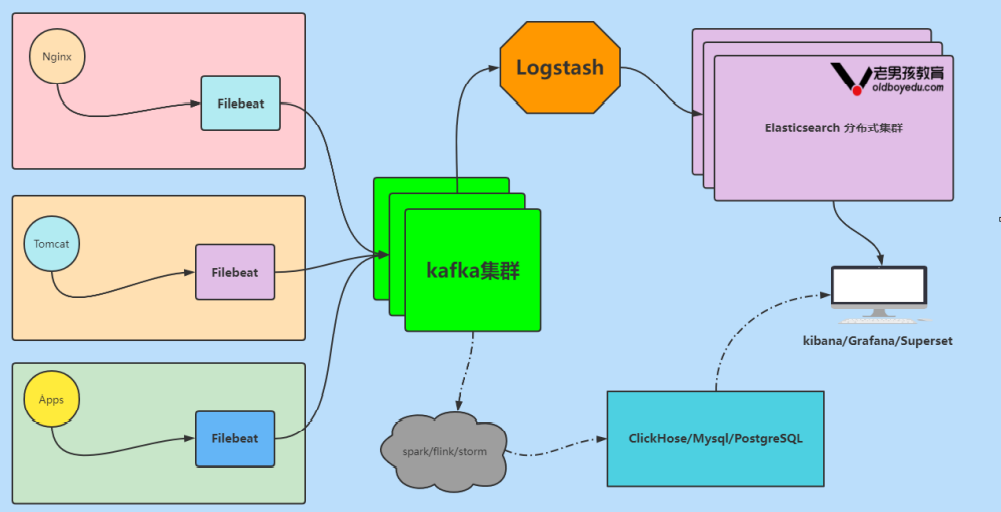
如上图所示,在实际工作中,如果有大数据部门的存在,也有可能kafka的数据要被多个公司使用哟。
二、ElasticSearch和Solr的抉择
2.1 ElasticSearch和Lucene的关系
Lucene的优缺点:
-
优点:可以被认为是迄今为至最先进,性能最好的,功能最全的搜索引擎库(框架);
-
缺点:
1)只能在Java项目中使用,并且要以jar包的方式直接集成在项目中;
2)使用很复杂,你需要深入了解检索的相关知识来创建索引和搜索索引代码;
3)不支持集群环境,索引数据不同步(不支持大型项目);
4)扩展性差,索引库和应用所在同一个服务器,当索引数据过大时,效率逐渐降低;
值得注意的是,上述的Lucene框架中的缺点,Elasticsearch全部都能解决。
ElasticSearch是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据。
ES可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三者进行组合。 有哪些公司在使用ElasticSearch呢,全球几乎所有的大型互联网公司都在拥抱这个开源项目:https://www.elastic.co/cn/customers/success-stories
2.2 ElasticSearch和Solr如何抉择
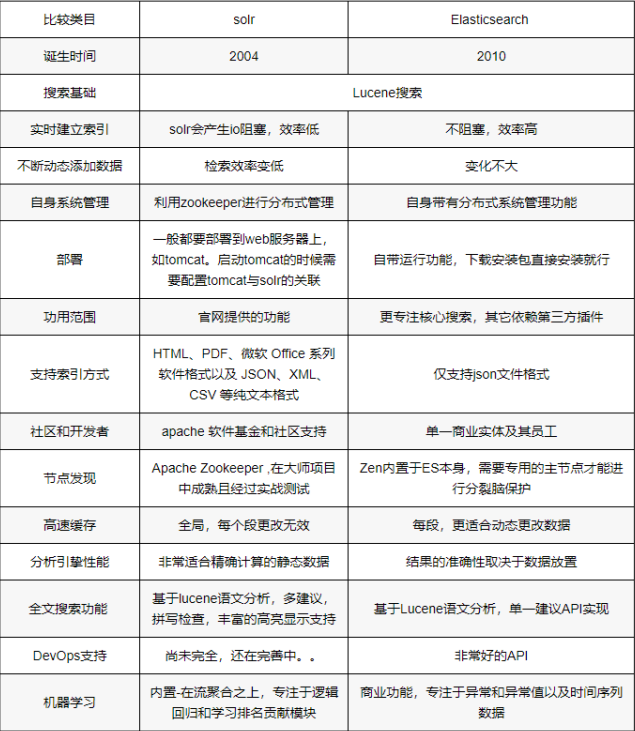
Solr是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。
Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr是最流行的企业级搜索引擎, Solr4 还增加了NoSQL支持。
Elasticsearch(下面简称"ES")与Solr的比较:
1)Solr利用Zookeeper进分分布式管理,而ES自身带有分布式协调管理功能;
2)Solr支持更多格式(JSON、XML、CSV)的数据,而ES仅支持JSON文件格式;
3)Solr官方提供的功能更多,而ES本身更注重于核心功能,高级功能多有第三方插件提供;
4)Solr在"传统搜索"(已有数据)中表现好于ES,但在处理"实时搜索"(实时建立索引)应用时效率明显低于ES;
5)Solr是传统搜索应用的有力解决方案,但Elasticsearch更适用于新兴的实时搜索应用;
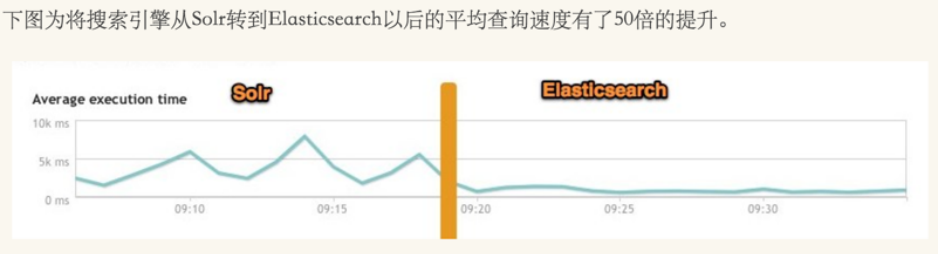
如下图所示,有网友在生产环境测试,将搜索引擎从Solr转到ElasticSearch以后的平均查询速度有了将近50倍的提升:
三、集群基础环境初始化
3.1 准备虚拟机
| IP地址 | 主机名 | CPU | 内存 | 磁盘 | 说明 |
|---|---|---|---|---|---|
| 192.168.99.11 | elasticsearch01 | 2 core | 4G | 20G+ | ES node |
| 192.168.99.12 | elasticsearch02 | 2 core | 4G | 20G+ | ES node |
| 192.168.99.13 | elasticsearch03 | 2 core | 4G | 20G+ | ES node |
3.2 修改数据源
$ sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org|baseurl=https://mirrors.tuna.tsinghua.edu.cn|g' \
-i.bak \
/etc/yum.repos.d/CentOS-*.repo
参考链接:https://mirrors.tuna.tsinghua.edu.cn/help/centos/
3.3 修改终端颜色
$ cat <<EOF >> ~/.bashrc
PS1='[\[\e[34;1m\]\u@\[\e[0m\]\[\e[32;1m\]\H\[\e[0m\]\[\e[31;1m\] \W\e[0m\]]# '
EOF
$ source ~/.bashrc
3.4 修改sshd服务优化
$ sed -ri 's@^#UseDNS yes@UseDNS no@g' /etc/ssh/sshd_config
$ sed -ri 's#^GSSAPIAuthentication yes#GSSAPIAuthentication no#g' /etc/ssh/sshd_config
$ grep ^UseDNS /etc/ssh/sshd_config
$ grep ^GSSAPIAuthentication /etc/ssh/sshd_config
3.5 关闭防火墙
$ systemctl disable --now firewalld && systemctl is-enabled firewalld
$ systemctl status firewalld
3.6 禁用selinux
$ sed -ri 's#(SELINUX=)enforcing#\1disabled#' /etc/selinux/config
$ grep ^SELINUX= /etc/selinux/config
$ setenforce 0
$ getenforce
3.7 配置集群免密登录及同步脚本
1)修改主机列表
$ cat >> /etc/hosts <<'EOF'
192.168.99.11 elasticsearch01
192.168.99.12 elasticsearch02
192.168.99.13 elasticsearch03
EOF
2)elasticsearch01节点上生成密钥对
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa -q
3)elasticsearch01配置所有集群节点的免密登录
$ for ((host_id=1;host_id<=3;host_id++));do ssh-copy-id elasticsearch0${host_id} ;done
4)连接测试
$ ssh elasticsearch01
$ ssh elasticsearch02
$ ssh elasticsearch03
5)所有节点安装rsync数据同步工具
$ yum -y install rsync
6)编写同步脚本
$ vim /usr/local/sbin/data_rsync.sh
# 将下面的内容拷贝到该文件即可
#!/bin/bash
if [ $# -ne 1 ];then
echo "Usage: $0 /path/to/file(绝对路径)"
exit
fi
# 判断文件是否存在
if [ ! -e $1 ];then
echo "[ $1 ] dir or file not find!"
exit
fi
# 获取父路径
fullpath=`dirname $1`
# 获取子路径
basename=`basename $1`
# 进入到父路径
cd $fullpath
for ((host_id=2;host_id<=3;host_id++))
do
# 使得终端输出变为绿色
tput setaf 2
echo ===== rsyncing elasticsearch0${host_id}: $basename =====
# 使得终端恢复原来的颜色
tput setaf 7
# 将数据同步到其他两个节点
rsync -az $basename `whoami`@elasticsearch0${host_id}:$fullpath
if [ $? -eq 0 ];then
echo "命令执行成功!"
fi
done
7)给脚本授权
$ chmod +x /usr/local/sbin/data_rsync.sh
3.8 集群时间同步
1)安装常用的Linux工具,您可以自定义哈。
$ yum -y install vim net-tools
2)安装chrony服务
$ yum -y install ntpdate chrony
3)修改chrony服务配置文件
$ vim /etc/chrony.conf
...
# 注释官方的时间服务器,换成国内的时间服务器即可
server ntp.aliyun.com iburst
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
server ntp4.aliyun.com iburst
server ntp5.aliyun.com iburst
...
4)配置chronyd的开机自启动
$ systemctl enable --now chronyd
$ systemctl restart chronyd
5)查看服务
$ systemctl status chronyd
四、ElasticSearch单点部署
4.1 下载指定的ES版本
参考链接:https://www.elastic.co/cn/downloads/elasticsearch
4.2 单点部署elasticsearch
1)安装
$ yum -y localinstall elasticsearch-7.17.6-x86_64.rpm
2)修改配置文件
$ egrep -v '^$|^#' /etc/elasticsearch/elasticsearch.yml
cluster.name: lvzhenjiang-elk
node.name: elasticsearch01
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.seed_hosts: ["192.168.99.11"]
相关参数说明:
-
cluster.name: 集群名称,若不指定,则默认是"elasticsearch",日志文件的前缀也是集群名称。 -
node.name: 指定节点的名称,可以自定义,推荐使用当前的主机名,要求集群唯一。 -
path.data: 数据路径。 -
path.logs: 日志路径。 -
network.host: ES服务监听的IP地址。 -
discovery.seed_hosts: 服务发现的主机列表,对于单点部署而言,主机列表和network.host字段配置相同
即可。
3)启动服务
$ systemctl start elasticsearch.service
五、ElasticSearch分布式集群部署
5.1 elasticsearch01修改配置文件
$ egrep -v '^$|^#' /etc/elasticsearch/elasticsearch.yml
cluster.name: lvzhenjiang-elk
node.name: elasticsearch01
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.seed_hosts: ["192.168.99.11","192.168.99.12","192.168.99.13"]
cluster.initial_master_nodes: ["192.168.99.11","192.168.99.12","192.168.99.13"]
注意:
node.name:各个节点配置要区分清楚,建议写对应的主机名称!
5.2 同步配置文件到集群的其他节点
1)elasticsearch01同步配置文件到集群的其他节点
$ data_rsync.sh /etc/elasticsearch/elasticsearch.yml
2)elasticsearch02节点配置
......
node.name: elasticsearch02
3)elasticsearch03节点配置
......
node.name: elasticsearch03
5.3 所有节点删除之前的临时数据
$ pkill java
$ rm -rf /var/{lib,log}/elasticsearch/* /tmp/*
$ ll /var/{lib,log}/elasticsearch/ /tmp/
5.4 所有节点启动服务
1)所有节点启动服务
$ systemctl daemon-reload
$ systemctl start elasticsearch
2)启动过程中建议查看日志
$ tail -100f /var/log/elasticsearch/lvzhenjiang-elk.log
5.5 验证集群是否正常
$ curl elasticsearch01:9200/_cat/nodes?v

六、部署kibana服务
6.1 本地安装kibana
$ yum localinstall -y kibana-7.17.6-x86_64.rpm
6.2 修改kibana的配置文件
$ egrep -v '^$|^#' /etc/kibana/kibana.yml
server.host: "0.0.0.0"
server.name: "elasticsearch-kibana"
elasticsearch.hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
i18n.locale: "zh-CN"
6.3 启动kibana服务
$ systemctl enable --now kibana
$ systemctl status kibana
6.4 访问kibana的webUI
浏览器访问:http://{kibana IP}:5601
七、filebeat部署及基础使用
7.1 部署filebeat环境
$ yum localinstall -y filebeat-7.17.6-x86_64.rpm
7.2 修改filebeat的配置文件
1)编写测试的配置文件
$ mkdir ~/config
$ cat > ~/config/01-stdin-to-console.yml << 'EOF'
# 指定输入类型
filebeat.inputs:
# 指定输入的类型为 stdin ,表示标准输入
- type: stdin
# 指定输出类型
output.console:
# 打印漂亮的格式
pretty: true
EOF
2)运行filebeat实例
$ filebeat -e -c ~/config/01-stdin-to-console.yml
3)测试
启动filebeat实例,见打印的日志即可!
7.3 input的log类型
filebeat.inputs:
- type: log
paths:
- /tmp/test.log
output.console:
pretty: true
7.4 input的通配符案例
filebeat.inputs:
- type: log
paths:
- /tmp/test.log
- /tmp/*.txt
output.console:
pretty: true
7.5 input的通用字段案例
filebeat.inputs:
- type: log
# 是否启动当前的输入类型,默认值为true
enabled: true
# 指定数据路径
paths:
- /tmp/test.log
- /tmp/*.txt
# 给当前的输入类型打上标签,支持中文
tags: ["lvzhenjiang-linux80","吕振江"]
# 自定义字段
fields:
address: "北京房山"
# 将自定义键值对放到顶级字段,默认值为false,会将数据放到一个 “fields” 子段的下面
fields_under_root: true
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["lvzhenjiang-python"]
fields:
address: "北京"
output.console:
pretty: true
7.6 日志过滤案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/test/*.log
# 注意,黑白名单均支持通配符,生产环节中不建议同时使用,
# 指定黑名单,包含指定的内容才会采集,且区分大小写!
include_lines: ['^ERR', '^WARN','oldboyedu']
# 指定白名单,排除指定的内容
exclude_lines: ['^DBG',"linux","oldboyedu"]
output.console:
pretty: true
7.7 将数据写入es案例
filebeat.inputs:
- type: log
# 是否启动当前的输入类型,默认值为true
enabled: true
# 指定数据路径
paths:
- /tmp/test.log
- /tmp/*.txt
# 给当前的输入类型打上标签,支持中文
tags: ["lvzhenjiang-linux80","吕振江"]
# 自定义字段
fields:
address: "北京房山"
# 将自定义键值对放到顶级字段,默认值为false,会将数据放到一个 “fields” 子段的下面
fields_under_root: true
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["lvzhenjiang-python"]
fields:
address: "北京"
output.elasticsearch:
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
7.8 自定义es索引名称
filebeat.inputs:
- type: log
# 是否启动当前的输入类型,默认值为true
enabled: true
# 指定数据路径
paths:
- /tmp/test.log
- /tmp/*.txt
# 给当前的输入类型打上标签,支持中文
tags: ["lvzhenjiang-linux80","吕振江"]
# 自定义字段
fields:
address: "北京房山"
# 将自定义键值对放到顶级字段,默认值为false,会将数据放到一个 “fields” 子段的下面
fields_under_root: true
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["lvzhenjiang-python"]
fields:
address: "北京"
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-elk-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
7.9 多个索引写入案例
filebeat.inputs:
- type: log
# 是否启动当前的输入类型,默认值为true
enabled: true
# 指定数据路径
paths:
- /tmp/test.log
- /tmp/*.txt
# 给当前的输入类型打上标签,支持中文
tags: ["lvzhenjiang-linux80","吕振江"]
# 自定义字段
fields:
address: "北京房山"
# 将自定义键值对放到顶级字段,默认值为false,会将数据放到一个 “fields” 子段的下面
fields_under_root: true
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["lvzhenjiang-python"]
fields:
address: "北京"
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
# index: "lvzhenjiang-linux-elk-%{+yyyy.MM.dd}"
indices:
- index: "lvzhenjiang-linux-elk-%{+yyyy.MM.dd}"
# 匹配字段包含的内容
when.contains:
tags: "lvzhenjiang-linux80"
- index: "lvzhenjiang-linux-python-%{+yyyy.MM.dd}"
when.contains:
tags: "lvzhenjiang-python"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
7.10 自定义分片和副本案例
filebeat.inputs:
- type: log
# 是否启动当前的输入类型,默认值为true
enabled: true
# 指定数据路径
paths:
- /tmp/test.log
- /tmp/*.txt
# 给当前的输入类型打上标签,支持中文
tags: ["lvzhenjiang-linux80","吕振江"]
# 自定义字段
fields:
address: "北京房山"
# 将自定义键值对放到顶级字段,默认值为false,会将数据放到一个 “fields” 子段的下面
fields_under_root: true
- type: log
enabled: true
paths:
- /tmp/test/*/*.log
tags: ["lvzhenjiang-python"]
fields:
address: "北京"
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
# index: "lvzhenjiang-linux-elk-%{+yyyy.MM.dd}"
indices:
- index: "lvzhenjiang-linux-elk-%{+yyyy.MM.dd}"
# 匹配字段包含的内容
when.contains:
tags: "lvzhenjiang-linux80"
- index: "lvzhenjiang-linux-python-%{+yyyy.MM.dd}"
when.contains:
tags: "lvzhenjiang-python"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板
setup.template.overwrite: false
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 2
7.11 filebeat实现日志聚合到本地
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.file:
path: "/tmp/filebeat"
filename: lvzhenjiang-linux80
# 指定文件的滚动大小,默认值为20MB
rotate_every_kb: 102400
# 指定保存的文件个数,默认是7个,有效值为2-1024个
number_of_files: 300
# 指定文件的权限,默认权限是0600
permissions: 0600
7.12 filebeat实现日志聚合到ES集群
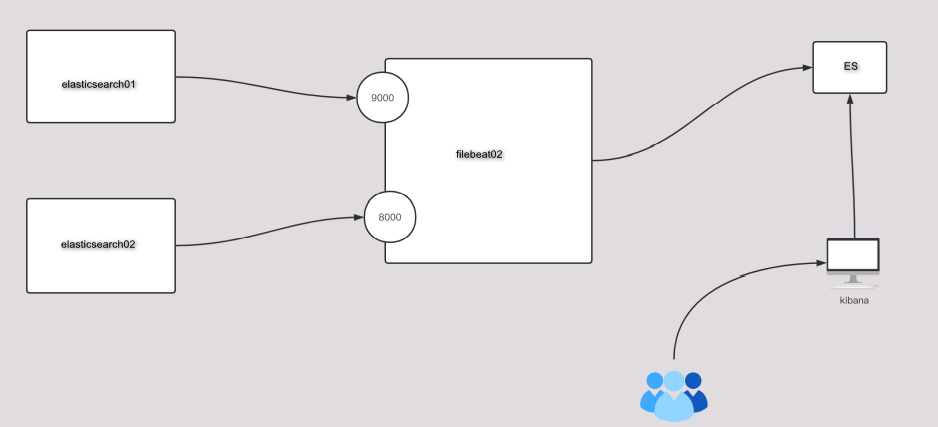
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
tags: ["aaa"]
- type: tcp
host: "0.0.0.0:8000"
tags: ["bbb"]
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
indices:
- index: "lvzhenjiang-linux80-elk-aaa-%{+yyyy.MM.dd}"
when.contains:
tags: "aaa"
- index: "lvzhenjiang-linux80-elk-bbb-%{+yyyy.MM.dd}"
when.contains:
tags: "bbb"
setup.ilm.enabled: false
setup.template.name: "lvzhenjiang-linux80-elk"
setup.template.pattern: "lvzhenjiang-linux80-elk*"
setup.template.overwrite: true
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 0
八、EFK架构企业级实战案例
8.1 部署nginx服务
1)配置nginx的软件源
$ cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
[nginx-mainline]
name=nginx mainline repo
baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
EOF
2)安装nginx服务
$ yum install nginx -y
3)启动nginx服务
$ systemctl start nginx
8.2 基于log类型收集nginx原生日志
filebeat.inputs:
- type: log
# 是否启动当前的输入类型,默认值为true
enabled: true
# 指定数据路径
paths:
- /var/log/nginx/access.log*
# 给当前的输入类型打上标签,支持中文
tags: ["access"]
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-nginx-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.3 基于log类型收集nginx的json日志
1)修改nginx的源日志格式
$ vim /etc/nginx/nginx.conf
......
log_format json '{"@timestamp": "$time_iso8601", '
'"time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"AWS_ALB_ip": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"upstream_response_time": "$upstream_response_time", '
'"status": "$status", '
'"host": "$host", '
'"request": "$request", '
'"request_method": "$request_method", '
'"uri": "$uri", '
'"http_referrer": "$http_referer", '
'"size": "$body_bytes_sent", '
'"user_ip": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" '
'}';
access_log /var/log/nginx/access.log json;
2)检查nginx的配置文件语法并重启nginx服务
$ nginx -t
$ systemctl restart nginx
3)定义配置文件
filebeat.inputs:
- type: log
# 是否启动当前的输入类型,默认值为true
enabled: true
# 指定数据路径
paths:
- /var/log/nginx/access.log*
# 给当前的输入类型打上标签,支持中文
tags: ["access"]
# 以JSON格式解析message字段的内容
json.keys_under_root: true
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-nginx-access-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.4 基于modules采集nginx日志文件
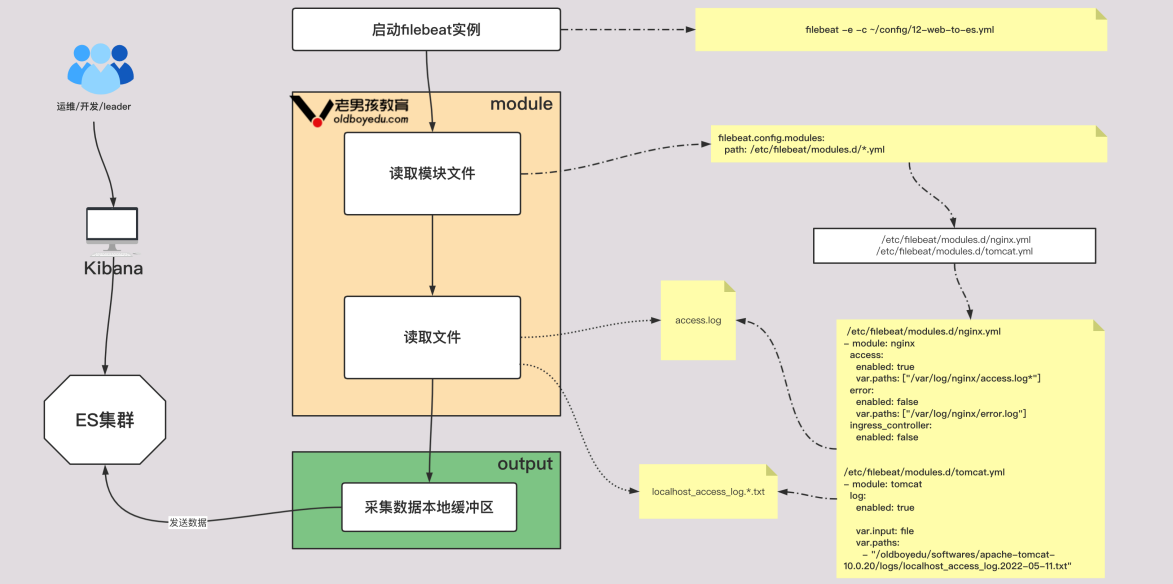
1)模块的基本使用
# 查看模块
filebeat modules list
# 启动模块
filebeat modules enable nginx tomcat
# 禁用模块
filebeat modules disable nginx tomcat
2)filebeat配置文件(需要启动nginx模块)
filebeat.config.modules:
# 指定模块的配置文件路径,如果是yum方式安装,在7.17.3版本两种不能使用如下默认值
# path: ${path.config}/modules.d/*.yml
# 经过实际测试,推荐使用如下的配置,此处写绝对路径即可!而对于二进制部署无需做此操作
path: /etc/filebeat/modules.d/*.yml
# 是否开启热加载
reload.enabled: true
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-nginx-access-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
3)/etc/filebeat/modules.d/nginx.yml文件内容
- module: nginx
access:
enabled: true
var.paths: ["/var/log/nginx/access.log*"]
error:
enabled: false
var.paths: ["/var/log/nginx/error.log"]
ingress_controller:
enabled: false
8.5 基于modules采集tomcat日志文件
1)部署tomcat服务
-
解压tomcat软件包
$ tar zvxf apache-tomcat-10.0.20.tar.gz -C /lvzhenjiang/software/ -
创建符号链接
$ ln -sv /lvzhenjiang/software/apache-tomcat-10.0.20 /lvzhenjiang/software/tomcat -
配置环境变量
$ vim /etc/profile.d/elk.sh #!/bin/bash export JAVA_HOME=/usr/share/elasticsearch/jdk export TOMCAT_HOME=/lvzhenjiang/software/apache-tomcat-10.0.20 export PATH=$PATH:$TOMCAT_HOME/bin:$JAVA_HOME/bin -
使得环境变量生效
$ source /etc/profile.d/elk.sh -
启动tomcat服务
$ catalina.sh start
2)启用tomcat模块管理
$ filebeat -c ~/config/11-nginx-to-es.yml modules disable ngix
$ filebeat -c ~/config/11-nginx-to-es.yml modules enable tomcat
$ filebeat -c ~/config/11-nginx-to-es.yml modules list
3)filebeat配置文件
filebeat.config.modules:
# 指定模块的配置文件路径,如果是yum方式安装,在7.17.3版本两种不能使用如下默认值
# path: ${path.config}/modules.d/*.yml
# 经过实际测试,推荐使用如下的配置,此处写绝对路径即可!而对于二进制部署无需做此操作
path: /etc/filebeat/modules.d/*.yml
# 是否开启热加载
reload.enabled: true
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-tomcat-access-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
3)/etc/filebeat/modules.d/tomcat.yml文件内容
- module: tomcat
log:
enabled: true
var.input: file
var.paths:
- /lvzhenjiang/software/apache-tomcat-10.0.20/logs/*.txt
8.6 基于log类型收集tomcat的原生日志
filebeat.inputs:
- type: log
paths:
- /lvzhenjiang/software/apache-tomcat-10.0.20/logs/*.txt
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-tomcat-access-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.7 基于log类型收集tomcat的json日志
1)自定义tomcat的日志格式
$ cp /lvzhenjiang/software/apache-tomcat-10.0.20/conf/server.xml{,.`date +%F`}
$ vim /lvzhenjiang/software/apache-tomcat-10.0.20/conf/server.xml
......(切换到行尾修改,大概在133-149之间)
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="{"client":"%h", "client user":"%l", "authenticated":"%u", "access time":"%t", "method":"%r", "status":"%s", "send bytes":"%b", "Query?string":"%q", "partner":"%{Referer}i", "Agent version":"%{User-Agent}i"}"/>
</Host>
2)修改filebeat的配置文件
filebeat.inputs:
- type: log
paths:
- /lvzhenjiang/software/apache-tomcat-10.0.20/logs/*.txt
# 解析message字段的json格式,并放在顶级字段中
json.key_under_root: true
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-tomcat-access-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.8 多行匹配——收集tomcat的错误日志
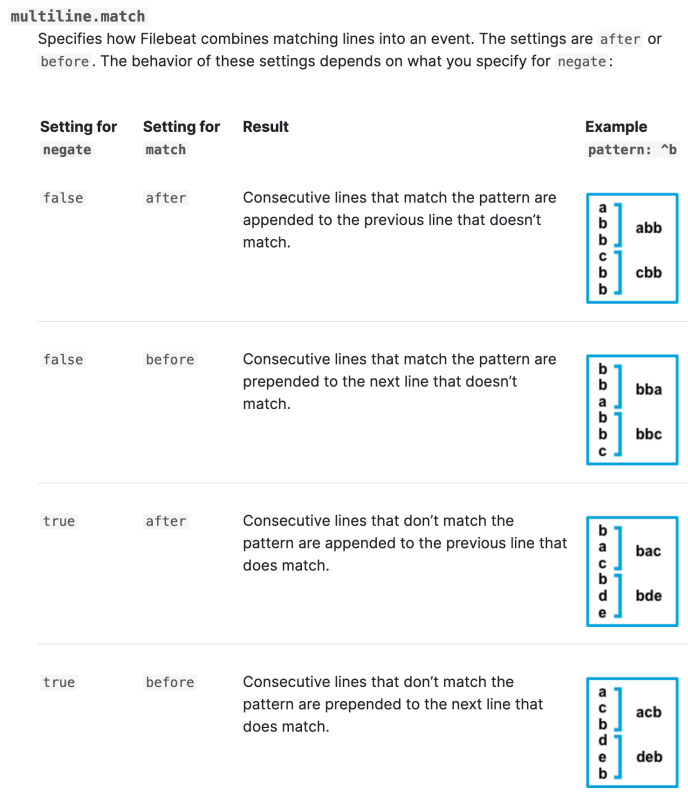
filebeat.inputs:
- type: log
paths:
- /lvzhenjiang/software/tomcat/logs/*.out
# 指定多行匹配的类型,可选值为“pattern”,“count”
multiline.type: pattern
# 指定匹配模式
multiline.pattern: '^\d{2}'
multiline.negate: true
multiline.match: after
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-tomcat-error-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.9 多行匹配——收集elasticsearch的错误日志
filebeat.inputs:
- type: log
paths:
- /var/log/elasticsearch/lvzhenjiang-elk-2022-09-03-1.log
# 指定多行匹配的类型,可选值为“pattern”,“count”
multiline.type: pattern
# 指定匹配模式
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-es-error-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.10 nginx错误日志过滤
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["access"]
# 以JSON格式解析message字段的内容
json.keys_under_root: true
- type: log
enabled: true
paths:
- /var/log/nginx/error.log*
tags: ["error"]
include_lines: ['\[error\]']
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
indices:
- index: "lvzhenjiang-linux-web-access-%{+yyyy.MM.dd}"
# 匹配字段包含的内容
when.contains:
tags: "access"
- index: "lvzhenjiang-linux-web-error-%{+yyyy.MM.dd}"
when.contains:
tags: "error"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.11 nginx和tomcat同时采集案例
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["nginx-access"]
json.keys_under_root: true
- type: log
enabled: true
paths:
- /var/log/nginx/error.log*
tags: ["nginx-error"]
include_lines: ['\[error\]']
- type: log
paths:
- /lvzhenjiang/software/apache-tomcat-10.0.20/logs/*.txt
json.key_under_root: true
tags: ["tomcat-access"]
- type: log
paths:
- /lvzhenjiang/software/tomcat/logs/*.out
multiline.type: pattern
multiline.pattern: '^\d{2}'
multiline.negate: true
multiline.match: after
tags: ["tomcat-error"]
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
indices:
- index: "lvzhenjiang-linux-web-nginx-access-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-access"
- index: "lvzhenjiang-linux-web-nginx-error-%{+yyyy.MM.dd}"
when.contains:
tags: "nginx-error"
- index: "lvzhenjiang-linux-web-tomcat-access-%{+yyyy.MM.dd}"
when.contains:
tags: "tomcat-access"
- index: "lvzhenjiang-linux-web-tomcat-error-%{+yyyy.MM.dd}"
when.contains:
tags: "tomcat-error"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.12 log类型切换filestream类型注意事项
8.12.1 filestream类型json解析配置
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["access"]
# 对于filestream类型而言,不能直接配置json解析,而是需要借助解析器实现
# json.keys_under_root: true
# 综上所述,我们就需要使用以下的写法实现
parsers:
- ndjson:
keys_under_root: true
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
index: "lvzhenjiang-linux-nginx-access-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.12.2 filestream类型多行匹配
filebeat.inputs:
- type: filestream
paths:
- /lvzhenjiang/software/apache-tomcat-10.0.20/logs/*.txt
tags: ["tomcat-access"]
parsers:
- ndjson:
keys_under_root: true
- type: filestream
paths:
- /lvzhenjiang/software/tomcat/logs/*.out
tags: ["tomcat-error"]
parsers:
- multiline:
type: pattern
pattern: '^\d{2}'
negate: true
match: after
output.elasticsearch:
enabled: true
hosts: ["http://192.168.99.11:9200","http://192.168.99.12:9200","http://192.168.99.13:9200"]
indices:
- index: "lvzhenjiang-linux-tomcat-access-%{+yyyy.MM.dd}"
# 匹配字段包含的内容
when.contains:
tags: "tomcat-access"
- index: "lvzhenjiang-linux-tomcat-error-%{+yyyy.MM.dd}"
when.contains:
tags: "tomcat-error"
# 禁用索引生命周期管理
setup.ilm.enabled: false
# 设置索引模板的名称
setup.template.name: "lvzhenjiang-linux"
# 设置索引模板的匹配模式
setup.template.pattern: "lvzhenjiang-linux*"
# 配置已有的索引模板,如果为true,则会覆盖现有的索引模板,如果为false则不覆盖现有的索引模板
setup.template.overwrite: true
# 配置索引模板
setup.template.settings:
# 设置分片数量
index.number_of_shards: 3
# 设置副本数量(要求小于集群数量)
index.number_of_replicas: 0
8.13 收集日志到redis服务
8.13.1 部署redis
$ yum install epel-release -y
$ yum install redis -y
8.13.2 修改配置文件
$ vim /etc/redis.conf
......
bind 0.0.0.0
requirepass lvzhenjiang
8.13.3 启动redis服务
$ systemctl start redis
8.13.4 其他节点连接测试redis环境
$ redis-cli -a lvzhenjiang -h 192.168.99.11 -p 6379 --raw -n 5
8.13.5 将filebeat数据写入到Redis环境
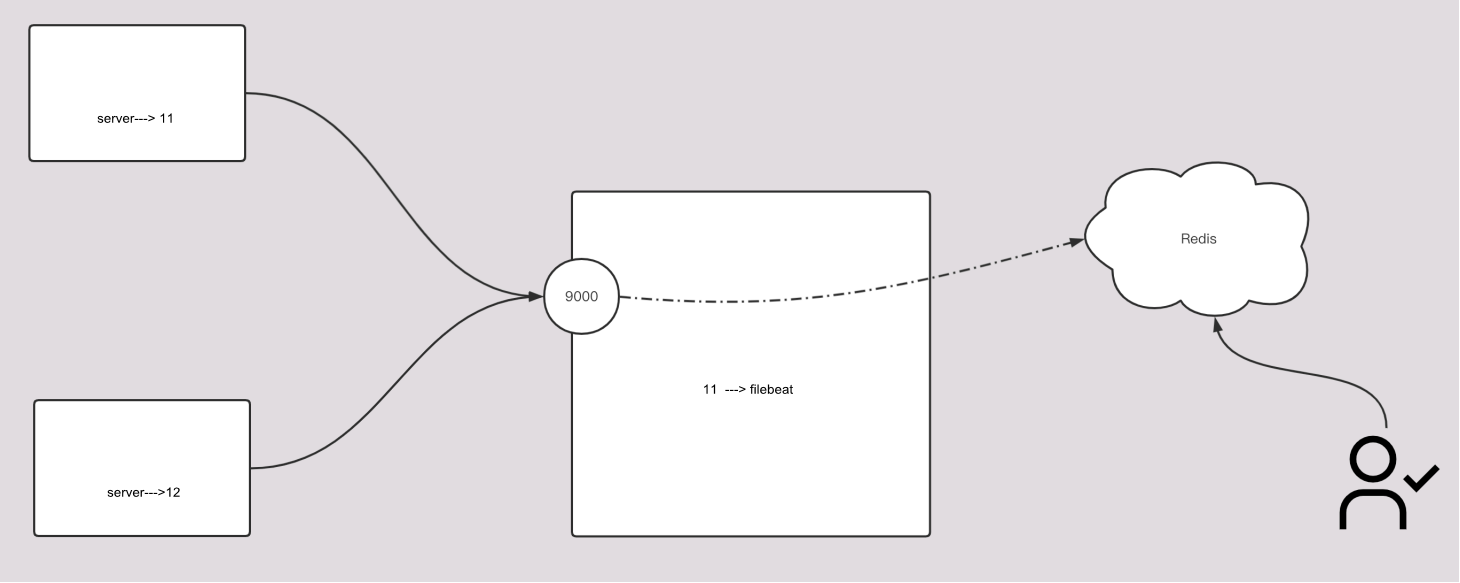
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.redis:
# 写入redis的主机地址
hosts: ["192.168.99.11:6379"]
# 指定redis的认证口令
password: "lvzhenjiang"
# 指定连接数据库的编号
db: 5
# 指定的key值
key: "lvzhejiang-filebeat"
# 规定超时时间
timeout: 3
8.13.6 测试写入数据
# 写入数据
$ echo 333333333333 | nc 192.168.99.11 9000
# 查看数据
$ redis-cli -a lvzhenjiang -h 192.168.99.11 -p 6379 --raw -n 5
192.168.99.11:6379[5]> :LRANGE lvzhenjiang-filebeat 0 -1
九、部署logstash环境及基础使用
9.1 部署logstash环境
$ yum localinstall logstash-7.17.6-x86_64.rpm -y
$ ln -sv /usr/share/logstash/bin/logstash /usr/local/bin/
9.2 修改logstash的配置文件
# 1)编写配置文件
$ cat > 01-stdin-to-stdout.conf << 'EOF'
input {
stdin {}
}
output {
stdout {}
}
EOF
# 2)检查配置文件语法
$ logstash -tf 01-stdin-to-stdout.conf
# 3)启动logstash实例
$ logstash -f 01-stdin-to-stdout.conf
9.3 input插件基于file案例
input {
file {
# 指定收集的路径
path => ["/tmp/test/*.txt"]
# 指定文件的读取位置,仅在“.sincedb*”文件中没有记录的情况下生效
start_position => "beginning"
# start_position => "end"
# start_position默认值是end
}
}
output {
stdout {}
}
9.4 input插件基于tcp案例
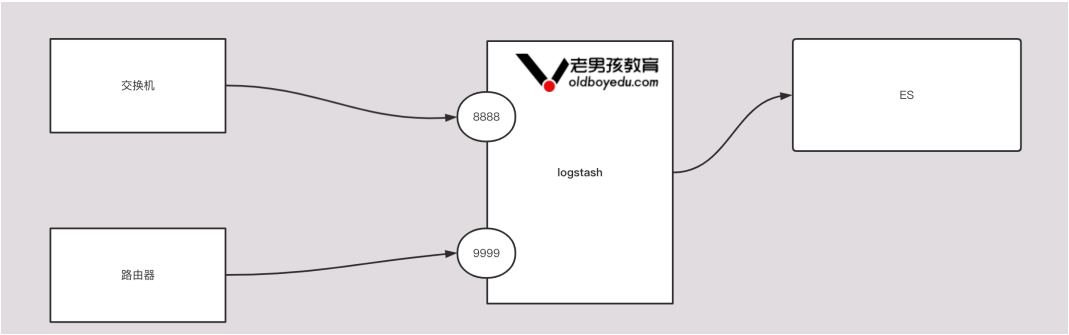
input {
tcp {
port => 8888
}
tcp {
port => 9999
}
}
output {
stdout {}
}
9.5 input插件基于http案例
input {
http {
port => 8888
}
http {
port => 9999
}
}
output {
stdout {}
}
9.6 input插件基于redis案例
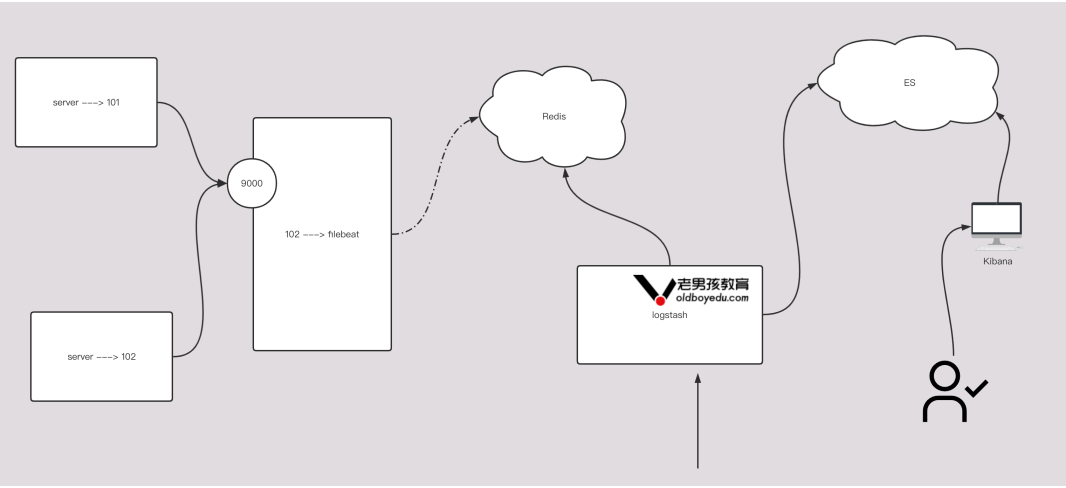
filebeat的配置:
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.redis:
# 写入redis的主机地址
hosts: ["192.168.99.11:6379"]
# 指定redis的认证口令
password: "lvzhenjiang"
# 指定连接数据库的编号
db: 5
# 指定的key值
key: "lvzhejiang-filebeat"
# 规定超时时间
timeout: 3
logstash的配置:
input {
redis {
# 指定的是REDIS的键(key)的类型
data_type => 'list'
# 指定数据库的编号,默认值是0号数据库
db => 5
# 指定数据库的IP地址,默认值是localhost
host => "192.168.99.11"
# 指定数据库的端口,默认值是6379
port => 6379
# 指定redis的认证密码
password => "lvzhenjiang"
# 指定从redis的哪个key取数据
key => "lvzhejiang-filebeat"
}
}
output {
stdout {}
}
9.7 input插件基于beats案例
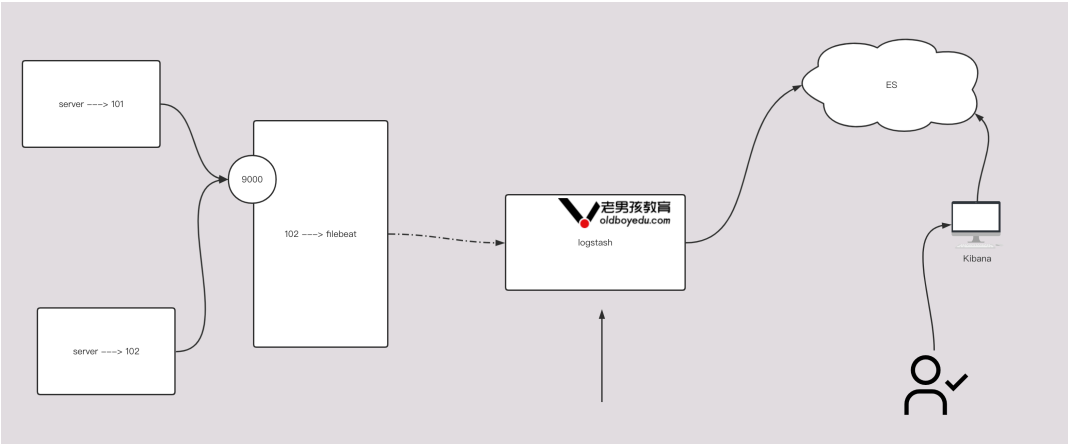
filebeat配置:
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.logstash:
hosts: ["192.168.99.12:5044"]
logstash配置:
input {
beats {
port => 5044
}
}
output {
stdout {}
}
9.8 output插件基于redis案例
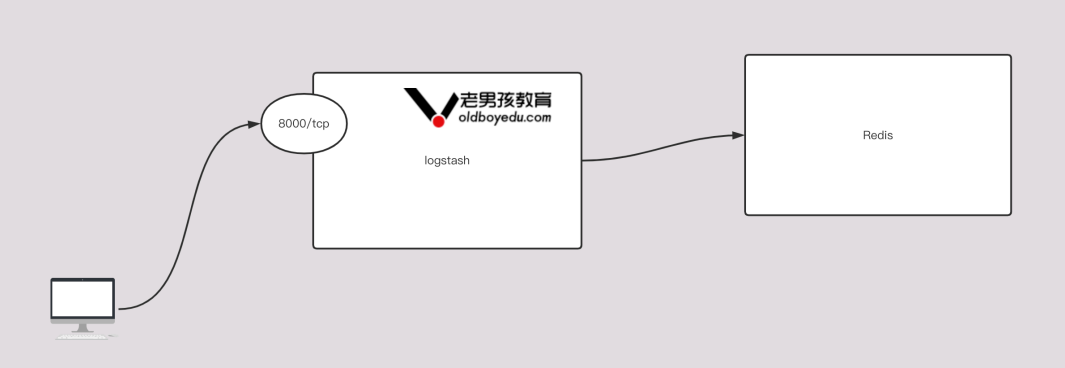
input {
tcp {
port => 9999
}
}
output {
stdout {}
redis {
# 指定redis的主机地址
host => "192.168.99.11"
# 指定redis的端口号
port => "6379"
# 指定redis数据库编号
db => 10
# 指定redis的密码
password => "lvzhenjiang"
# 指定写入数据的key类型
data_type => "list"
# 指定写入的key名称
key => "lvzhejiang-logstash"
}
}
9.9 output插件基于file案例
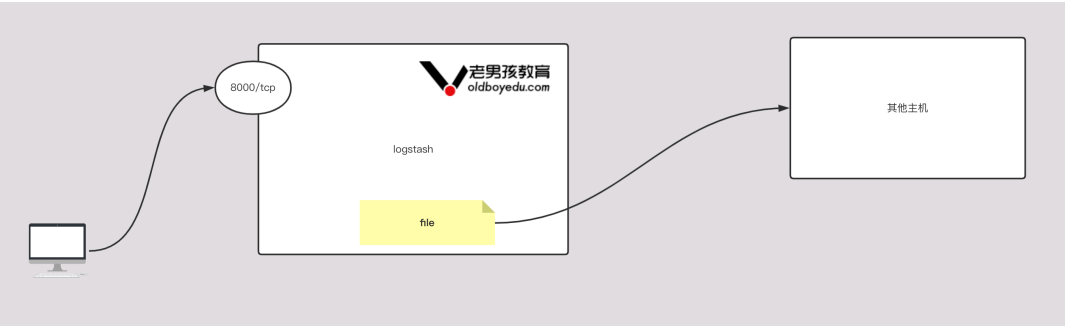
input {
tcp {
port => 9999
}
}
output {
stdout {}
file {
# 指定磁盘的落地位置
path => "/tmp/test/lvzhenjiang-logstash.log"
}
}
9.10 logstsh综合案例
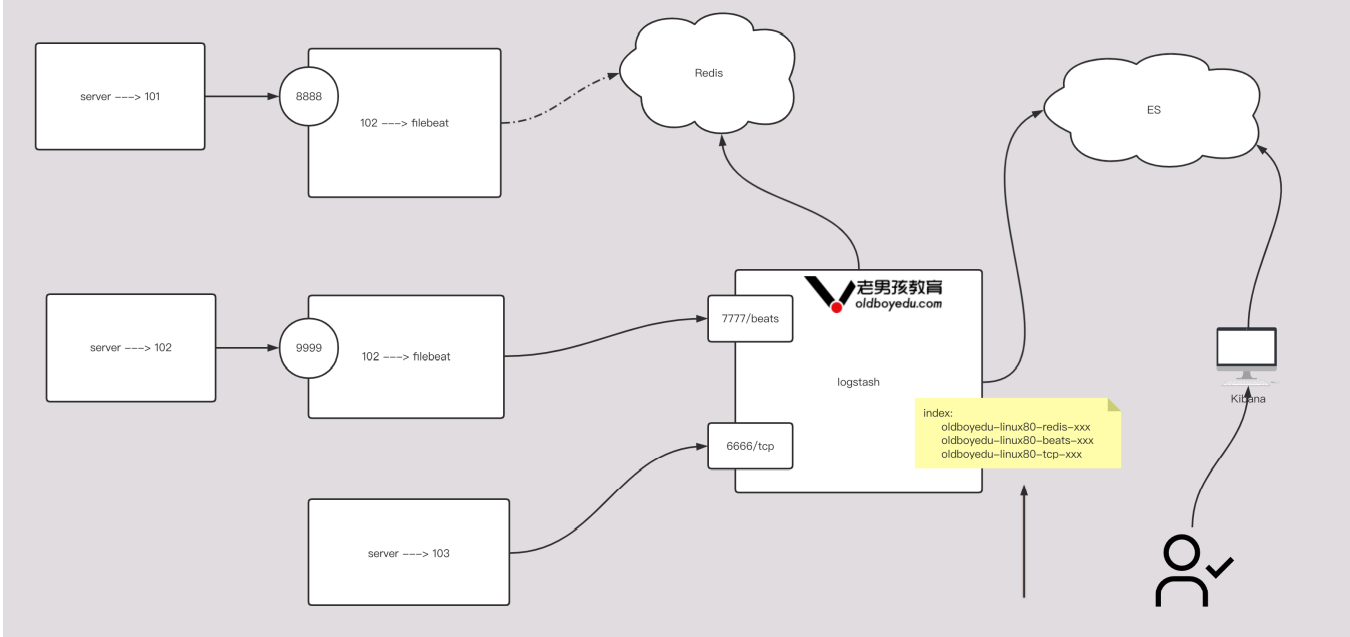
1)filebeat-to-redis参考笔记
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
output.redis:
# 写入redis的主机地址
hosts: ["192.168.99.11:6379"]
# 指定redis的认证口令
password: "lvzhenjiang"
# 指定连接数据库的编号
db: 5
# 指定的key值
key: "lvzhejiang-filebeat"
# 规定超时时间
timeout: 3
2)filebeat-to-logstash参考笔记
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9999"
output.logstash:
hosts: ["192.168.99.12:7777"]
3)logstash配置文件
input {
tcp {
type => "lvzhenjiang-tcp"
port => 6666
}
beats {
type => "lvzhenjiang-beat"
port => 7777
}
redis {
type => "lvzhenjiang-redis"
data_type => "list"
db => 5
host => "192.168.99.13"
port => "6379"
password => "lvzhenjiang"
key => "lvzhenjiang-linux-filebeat"
}
}
output {
stdout {}
if [type] == "lvzhenjiang-tcp" {
elasticsearch {
hosts => ["192.168.99.11:9200","192.168.99.12:9200","192.168.99.13:9200"]
index => "lvhzhenjiang-linux-tcp-%{+YYYY.MM.dd}"
}
} else if [type] == "lvzhenjiang-beat" {
elasticsearch {
hosts => ["192.168.99.11:9200","192.168.99.12:9200","192.168.99.13:9200"]
index => "lvhzhenjiang-linux-beat-%{+YYYY.MM.dd}"
}
} else if [type] == "lvzhenjiang-redis" {
elasticsearch {
hosts => ["192.168.99.11:9200","192.168.99.12:9200","192.168.99.13:9200"]
index => "lvhzhenjiang-linux-redis-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => ["192.168.99.11:9200","192.168.99.12:9200","192.168.99.13:9200"]
index => "lvhzhenjiang-linux-others-%{+YYYY.MM.dd}"
}
}
}
十、logstash企业插件案例(ELK架构)
10.1 常见的插件概述
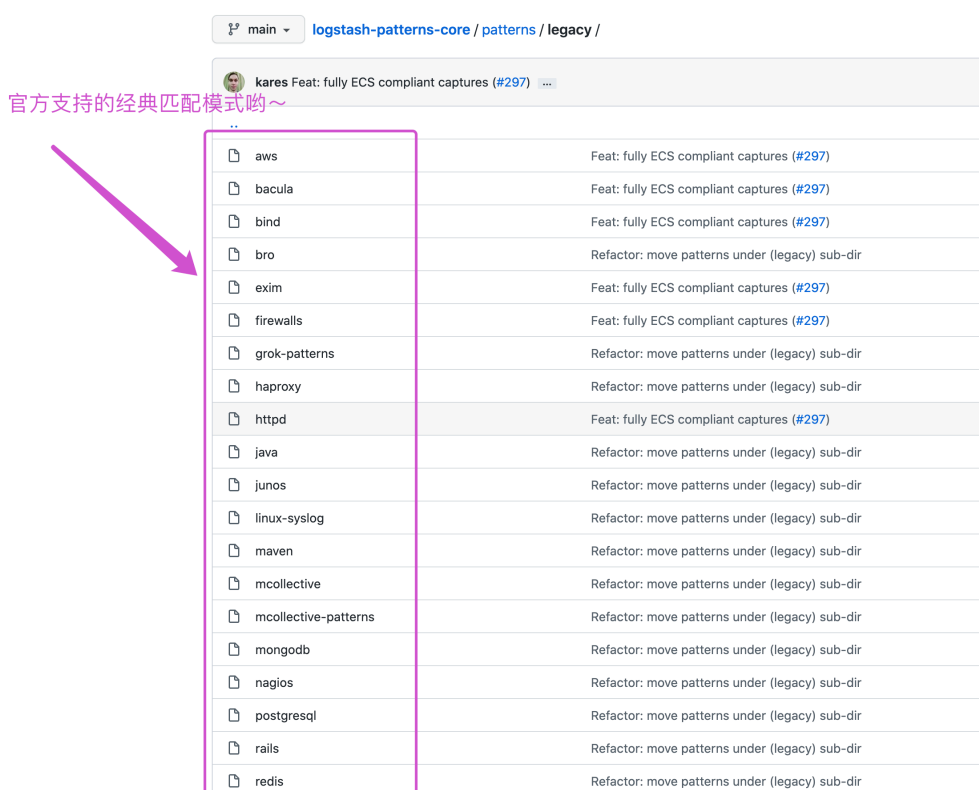
gork插件:grok是将非结构化日志数据解析为结构化和可查询的好方法。底层原理是基于正则匹配任意文本格式;该工具非常使用syslog日志、apache日志和其他网络服务器日志、mysql日志,以及通常为人类而非计算机消耗而编写的任何日志格式。内置120中匹配模式,当然也可以自定义匹配:https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/
10.2 使用grok内置的正则案例1
input {
beats {
port => 8888
}
}
filter {
grok {
match => {
# "message" => "%{COMBINEDAPACHELOG}"
# 上面的变量github官方已经废弃,建议使用下面的匹配模式:https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/legacy/httpd
"message" => "%{HTTPD_COMMONLOG}"
}
}
}
output {
stdout {}
elasticsearch {
hosts => ["192.168.99.11:9200","192.168.99.12:9200","192.168.99.13:9200"]
index => "lvzhenjiang-linux-logstash-%{+YYYY.MM.dd}"
}
}
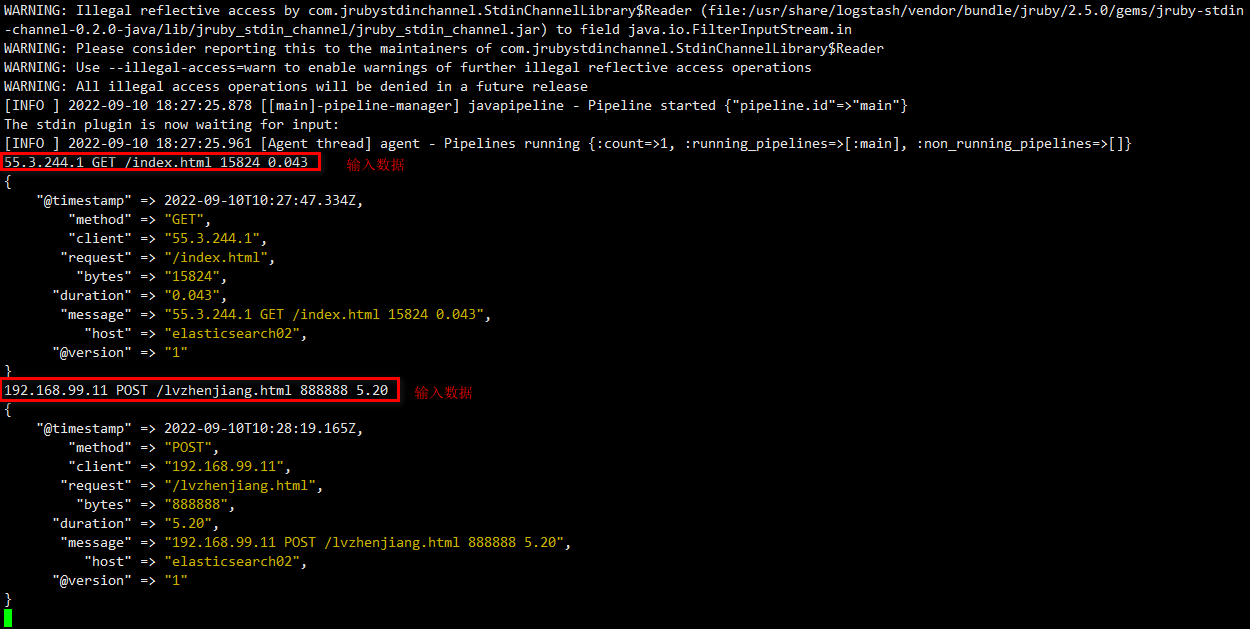
10.3 使用grok内置的正则案例2
input {
stdin {}
}
filter {
grok {
match => {
"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
}
}
}
output {
stdout {}
}
温馨提示:(如图所示,按照要求输入数据)
55.3.244.1 GET /index.html 15824 0.043
192.168.99.11 POST /lvzhenjiang.html 888888 5.20
参考地址:https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/legacy
10.4 使用grok自定义的正则案例
input {
stdin {}
}
filter {
grok {
# 指定匹配模式的目录,可以使用绝对路径
# 在./patterns目录下随便创建一个文件,并吸入以下匹配模式
# POSTFIX_QUEUEID [0-9A-F]{10,11}
# LVZHENJIANG_LINUX [\d]{3}
patterns_dir => ["./patterns"]
# 匹配模式
# 测试数据:Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>
# match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
# 测试数据为:ABCDE12345678910 ---> 666
match => { "message" => "%{POSTFIX_QUEUEID:lvzhenjiang_queue_id} ---> %{LVZHENJIANG_LINUX:lvzhenjiang_linux_elk}" }
}
}
output {
stdout {}
}
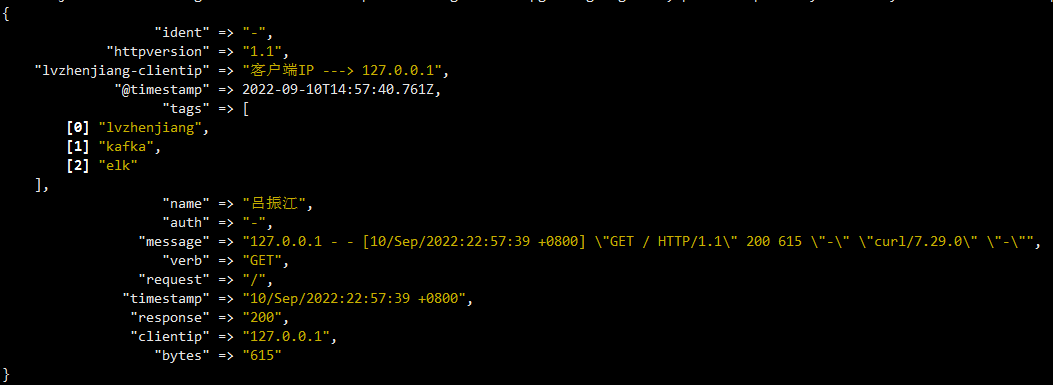
10.5 filter插件通用字段案例
input {
beats {
port => 8888
}
}
filter {
grok {
match => {
"message" => "%{HTTPD_COMMONLOG}"
}
# 移除指定的字段
remove_field => [ "host", "ecs", "tag", "@version", "agent", "input", "log" ]
# 添加指定的字段
add_field => {
"name" => "吕振江"
"lvzhenjiang-clientip" => "客户端IP ---> %{clientip}"
}
# 添加tag
add_tag => [ "lvzhenjiang", "kafka", "elk" ]
# 移除tag
remove_tag => [ "beats_input_codec_plain_applied" ]
# 创建插件的唯一ID,如果不创建则系统默认生成
id => "lvzhenjiang-logstash-elk"
}
}
output {
stdout {}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号