cache的基本原理
为什么需要cache
我们应该知道程序是运行在 RAM之中,RAM 就是我们常说的DDR(例如: DDR3、DDR4等)。我们称之为main memory(主存)。当我们需要运行一个进程的时候,首先会从磁盘设备(例如,eMMC、UFS、SSD等)中将可执行程序load到主存中,然后开始执行。在CPU内部存在一堆的通用寄存器(register)。如果CPU需要将一个变量(假设地址是A)加1,一般分为以下3个步骤:
- CPU 从主存中读取地址A的数据到内部通用寄存器 x0(ARM64架构的通用寄存器之一)。
- 通用寄存器 x0 加1。
- CPU 将通用寄存器 x0 的值写入主存。
我们将这个过程可以表示如下:

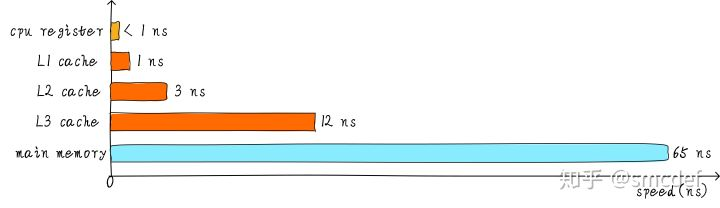
其实现实中,CPU通用寄存器的速度和主存之间存在着太大的差异。两者之间的速度大致如下关系:

CPU register的速度一般小于1ns,主存的速度一般是65ns左右。速度差异近百倍。因此,上面举例的3个步骤中,步骤1和步骤3实际上速度很慢。当CPU试图从主存中load/store 操作时,由于主存的速度限制,CPU不得不等待这漫长的65ns时间。如果我们可以提升主存的速度,那么系统将会获得很大的性能提升。如今的DDR存储设备,动不动就是几个GB,容量很大。如果我们采用更快材料制作更快速度的主存,并且拥有几乎差不多的容量。其成本将会大幅度上升。我们试图提升主存的速度和容量,又期望其成本很低,这就有点难为人了。因此,我们有一种折中的方法,那就是制作一块速度极快但是容量极小的存储设备。那么其成本也不会太高。这块存储设备我们称之为cache memory。在硬件上,我们将cache放置在CPU和主存之间,作为主存数据的缓存。 当CPU试图从主存中load/store数据的时候, CPU会首先从cache中查找对应地址的数据是否缓存在cache 中。如果其数据缓存在cache中,直接从cache中拿到数据并返回给CPU。程序局部性:时间局部性:如果一个信息项正在被访问,那么在近期它很可能还会被访问;空间局部性:如果最近将要访问的信息很可能与正在使用的信息在空间地址上是邻近的。使用cache很好的利用这两类程序局部性。当存在cache的时候,以上程序如何运行的例子的流程将会变成如下:
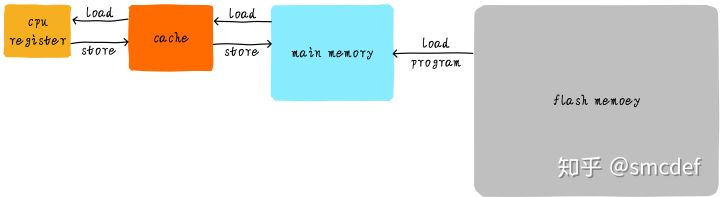
CPU和主存之间直接数据传输的方式转变成CPU和cache之间直接数据传输。cache负责和主存之间数据传输。
多级cache存储结构
cahe的速度在一定程度上同样影响着系统的性能。一般情况cache的速度可以达到1ns,几乎可以和CPU寄存器速度媲美。但是,这就满足人们对性能的追求了吗?并没有。当cache中没有缓存我们想要的数据的时候,依然需要漫长的等待从主存中load数据。为了进一步提升性能,引入多级cache。前面提到的cache,称之为L1 cache(第一级cache)。我们在L1 cache 后面连接L2 cache,在L2 cache 和主存之间连接L3 cache。等级越高,速度越慢,容量越大。但是速度相比较主存而言,依然很快。不同等级cache速度之间关系如下:
经过3级cache的缓冲,各级cache和主存之间的速度最萌差也逐级减小。在一个真实的系统上,各级cache之间硬件上是如何关联的呢?我们看下Cortex-A53架构上各级cache之间的硬件抽象框图如下:

在Cortex-A53架构上,L1 cache分为单独的instruction cache(ICache)和data cache(DCache)。L1 cache是CPU私有的,每个CPU都有一个L1 cache。一个cluster 内的所有CPU共享一个L2 cache,L2 cache不区分指令和数据,都可以缓存。所有cluster之间共享L3 cache。L3 cache通过总线和主存相连。
多级cache之间的配合工作
首先引入两个名词概念,命中和缺失。 CPU要访问的数据在cache中有缓存,称为“命中” (hit),反之则称为“缺失” (miss)。多级cache之间是如何配合工作的呢?我们假设现在考虑的系统只有两级cache。
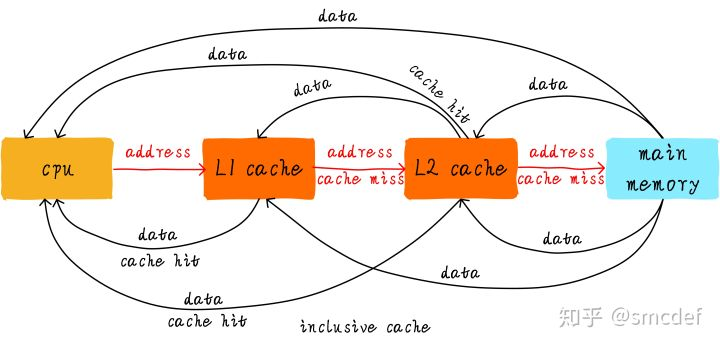
当CPU试图从某地址load数据时,首先从L1 cache中查询是否命中,如果命中则把数据返回给CPU。如果L1 cache缺失,则继续从L2 cache中查找。当L2 cache命中时,数据会返回给L1 cache以及CPU。如果L2 cache也缺失,很不幸,我们需要从主存中load数据,将数据返回给L2 cache、L1 cache及CPU。这种多级cache的工作方式称之为inclusive cache。某一地址的数据可能存在多级缓存中。与inclusive cache对应的是exclusive cache,这种cache保证某一地址的数据缓存只会存在于多级cache其中一级。也就是说,任意地址的数据不可能同时在L1和L2 cache中缓存。
cache的基本原理
cache是比主存小得多的高速SRAM,成本较高。cache的所有功能都是硬件来实现的,对于应用程序员和系统程序员来说是透明的,他们感觉不到cache的存在,也无法操作cahce,但是在系统初始化时,需要嵌入式程序员对cache进行配置和使能。
cahce line是cache与主存之间进行数据交换的基本单位。CPU在读取指令或者数据时会同时将其相邻的指令和数据保存到一个cache line中。当CPU再次访问这个数据或者其相邻数据时会大大的提高速度,对系统性能由较大的改进,这利用了程序的局部性规律。
一般,主存有多大2n个字组成,这些字可以被寻址并且每个字有唯一的n位地址。为实现主存到cache的映射,主存被看成由许多定长的行组成,每行K个字,共有M=2n/K个行。对应的cache由C个行组成,每行也有K个字。cache中行的数量远小于主存中行的数量,cache的行仅是主存中若干行的副本,每个cache line都有一个标签tag寄存器,用于存放该行与主存中行的映射关系和一些控制信息。
cahce按结构可分为两种,普林斯顿(Princeton):单一式,指令和数据统一存放到一个cache中;哈佛(Harvard)结构:分离式,指令和数据分开存放到两个cache中。Harvard结构的优点是CPU能同时访问指令cache和数据cache,使得取指令和存取数据并行操作,在流水线处理器中确实存在某条指令处于取值阶段,而另一条指令处于存储器访问阶段;其次哈佛结构可以独立配置指令cache和数据cache的容量。不足之处也在于,当不同的程序对指令和数据有不同需求时,不能灵活调整。在现在超标量CPU的设计中,第一级都采用分离式cache架构,而第二级乃至第三级都采用单一的cache架构。分离式cache在基于指令流水线的设计中效率较高,因为它消除了一条指令取值和另一条指令访存的结构冒险。
cache的映射方式
直接映射(Direct mapped cache)
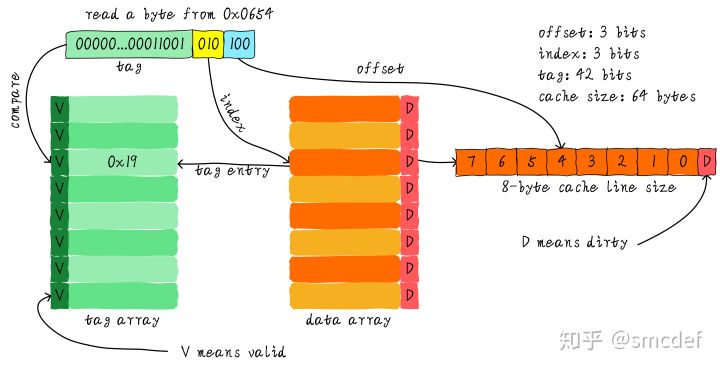
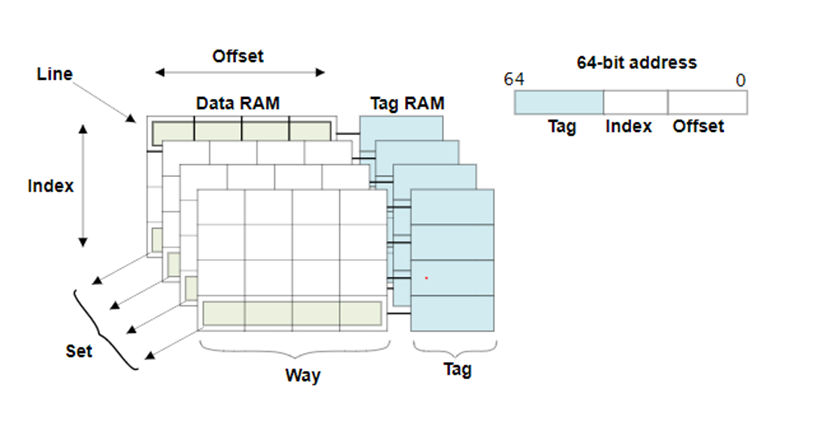
直接映射是最简单的映射方式。每个固定的cache line只能映射有共同特征的主存行,例如采用取模方式的映射方式。如下图所示,大小为64 byte的cache,cache line大小为8 byte。对于32位内存地址来说,最低3 bit是offset,代表一个byte在cache line的行内偏移,然后3 bit是索引地址,代表cache line的行号,剩余bit代表Tag地址。当CPU发出访存地址时,cache控制器首先利用3 bit索引找到对应的cache line的tag,并与其比较,如果相同则cache命中。虽然直接映射技术实现比较简单,但是当程序经常访问映射到同一cache line的主存来说,会导致cahce的颠簸,效率大大降低。
全关联映射(Full associative cache)
全关联映射允许cahce line存储主存任意行。cahce控制器把内存地址简单分为tag和offset两部分。由于当CPU发出访存地址时,cache需要比较cahce中的每个tag,效率较低,功耗大,

组关联映射(v-way set associative cache)
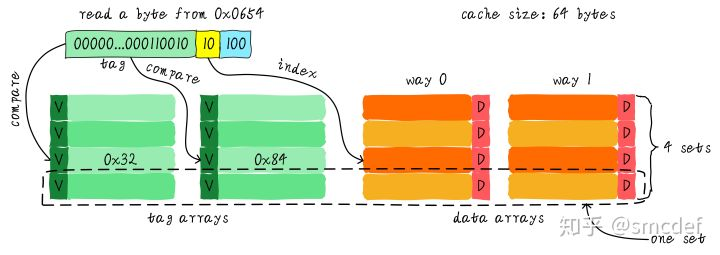
组关联映射是直接映射和全关联映射的一种折中办法。在组关联映射中,cahce分为v个路,每路有k个行,称为v路组关联映射。对于v路组关联映射,主存行可映射到某一特定组中的v个cache行的任意一行(共k组,内存行所映射的组号与其地址中索引段决定)。组关联映射具有较强的灵活性,而且每次命中判断时CPU发出的地址只需与所映射组的k个tag相比较,因此功耗较低。如下图,当CPU发出访存时,首先通过索引地址找到对应的组,每个组有两个cache行,对组内的tag进行依次比较,如果相同则命中cahce。
一般,在cache行大小和容量相同的前提下,组关联数越高命中率越高,但每次访问都需要比较所有的tag,造成单次访问延时大,功耗高;而关联数较低,容易引起cache的冲突,性能下降。
cache替换策略
由于cache的行数远小于主存的函数,因此必定会发生行的替换,为了提高访问速度,替换算法由硬件完成。
- 随机替换算法
用伪随机来产生要替换的行。在实际测试中有不错的表现,对于硬件实现也比较简单。
- 最近最少用替换策略LRU
该替换策略选择那些最近最少使用的行,意味着需要为每行设计相应的计数器,并且在替换时选择最少使用的行,硬件设计较为负载。
- 伪LRU替换策略
每个cahce行设置1 bit控制位。初始状态所有行都为0,如果访问过该行,则置为1,替换时总是选择状态为0的行,如果有多个0则随机选择一行,如果都为1,那么把其他行置为0,随机选择一行。
cache分配策略
- 读操作分配策略(read-allocate)
对于读操作分配策略,在指令或者数据缺失时为主存分配cache行,将主存读入cache行之后,再把目标数据返回给CPU;在写数据缺失时并不分配cache行,只把数据写入主存。
- 写操作分配策略(write-allocate)
写缺失时,主存读入cache后才进行写操作
- read-write-allocate
无论写缺失还是读缺失都会分配相应的cache行给主存。
cache写策略
- 写穿write through策略
如果写命中,即cache已经缓存地址段,那么写数据写入cache的同时写入主存;写缺失,则只将写数据写入主存,而不在cache进行备份。CPU需要等待缓慢的主存操作。
- 带write buffer的写穿策略
如果写命中,则将写数据写入cache的同时写入write buffer;写缺失时只写入write buffer。写缓冲是一块片上存储器,CPU发起的写操作可以立即保存到写缓冲,不用等待片外存储器。由于写缓冲可能有有效数据,因此CPU每次读操作时需要先判断数据是否在写缓冲区中
- 写回write back策略
写回策略是指CPU在写操作时,如果命中,只更新cache内容,而不立刻写入主存,这时cache和主存数据不同。仅当cache line被替换是才更新脏块到主存中。写回策略需要1 bit控制位,表示dirty状态。
可以从以下方面对写回和写穿进行比较:可靠性、与主存的通信量、控制复杂性。
- 写穿比写回可靠性强,因为能保证cache和主存数据一致
- 写穿与主存的通信量要高于写回
- 写回比写穿控制逻辑复杂,因为写回需要dirty位
参考:https://zhuanlan.zhihu.com/p/102293437

 浙公网安备 33010602011771号
浙公网安备 33010602011771号