程序员的自我修养
这本书能学到什么
- 本书基本信息:https://book.douban.com/subject/3652388/
- 介绍程序基本运行过程的一本书。一个应用程序在编译、链接和运行时刻所发生的各种事项,包括:代码指令是如何保存的,库文件如何与应用程序代码静态链接,应用程序如何被装载到内存中并开始运行,动态链接如何实现,C/C++运行库的工作原理,以及操作系统提供的系统服务是如何被调用的。
- 计算机技术是相通的,即使IT技术日新月异,核心思想稳定不变,人要系统的学习知识,做到触类旁通,提高认知效率
- 内核、装载、链接、库,对于系统的重要性是什么?能帮助在哪方面有更好的提高?提高哪些认识的能力?
第一章 温故而知新
- 多核处理器、smp
多核处理器从硬件角度,分为同构和异构两种架构
同构:核的架构相同,如使用的都为A73的核心
异构:核的架构不同,如使用A73和A57两个核心
从软件的角度来看,多核处理器的运行模式有三种:
SMP-对称多处理,symmetric multi-processing。
AMP-非对称多处理,asymmetric multi-processing
BMP-边界多处理,bound multi-processing
以下是三种模式的特点和优点:

soc(system on chip)片上系统是一个集成的概念,一个soc集成了多个处理器实现了多种功能,如应用处理器、图形处理器、基带处理器等
- 软件分层思想
- 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。“Any problem in computer science can be solvd by another layer of indirection.”
- 计算机系统软件按照严格的层次结构设计,从下到上分为硬件层、操作系统层、运行库、应用软件。体系里的每个组件比如操作系统、bsp驱动、硬件结构也都是有严格的层次结构和设计。
- 每层之间通过接口进行通信,每个中间层都是对它下面那层的包装和扩展。上层软件依赖下层软件提供的接口功能,在实际设计编码过程中,要遵循以下设计思想,上层可直接调用下层接口;下层不依赖上层,下层只能调用上层注册的回调函数。
- 操作系统基本概念
- 操作系统的一个主要功能是管理硬件资源,比如cpu、存储、IO设备
- 内存分段:把不同程序需要的内存空间映射到不同的地址空间,解决了程序地址空间隔离、程序运行地址不确定的问题。但是分段对内存区域的分配映射是以程序为单位的,如果内存不足需要交换整个程序。内存使用效率较低。
- 分页的基本方法是把地址空间分成固定大小的页,每一页的大小由硬件决定,或者硬件支持多种大小的页,由操作系统选择决定页的大小。物理内存中的页叫做物理页(physical page),虚拟空间的页叫做虚拟页(virtual page)。由MMU来实现页的映射管理。
- 线程,又称为轻量级进程,是程序执行的最小单元。一个标准的线程由线程ID、当前指令指针PC、寄存器集合、堆栈组成。一个进程由一个或多个线程组成,各个线程之间共享程序的内存空间:代码段、数据段、堆、进程级资源。线程的栈、局部变量、寄存器是各自私有的。
- 并发与并行。对于单处理器的多线程情况,并发是模拟出来的状态,对于一段时间来说看起来多个线程都执行了一些操作。并行是指同一时刻多个线程在不同核上在运行计算。
- 线程调度。线程至少有3种状态:运行(running)、就绪(ready)、等待(pending)。线程调度有不同的方案和算法,如优先级调度、轮转法。分时操作系统会让程序分别运行固定的时间片,优先运行高优先级任务,实时系统一般没有分时时间片机制。
- 频繁等待的线程称为IO密集型线程;进行大量计算的线程称为CPU密集型线程。
- 抢占式和不可抢占式线程。不可抢占线程是指,除非线程主动发起放弃执行的命令,否则其他线程无法得到调度,当今这种系统很少了。
- 线程安全:睡眠锁,获取失败放弃CPU,信号量、互斥锁;非睡眠锁,获取失败则忙等待,直到获取锁,自旋锁。
- 函数可重入要具备以下特点:不使用静态或者全局的非const变量;不返回静态或者全局的非const变量;仅依赖调用方提供的参数;不依赖单个资源的锁;不调用任何不可重入的函数。
第二章 编译和链接
集成开发环境IDE通常将编译和链接过程整合到一起,称为构建build。隐藏了源代码到可执行文件的背后运行机制。源程序到可执行文件包括4步:预处理(prepressing、cp、.c文件->.i文件)、编译(compilation、gcc、.i文件->.s文件)、汇编(assembly、as、.s文件->.o文件)、链接(linking、ld、.o文件->可执行文件)。
- 预编译工作
预编译过程主要处理那些源代码中的以“#”开始的预编译命令,比如“#include”、“#define”等,主要处理规则如下:
- 将所有#dfine删除,并且展开所有的宏定义
- 处理所有条件预编译指令,比如#if、#ifdef、#elif、#else、#endif
- 处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。这个过程是递归进行的,被包含的文件可能还包含其他文件。
- 删除所有的注释“//”和“/* */”。
- 添加行号和文件名标识,比如 # “hello.c” 2,以便于编译时编译器产生调试用的行号信息,用于编译时产生编译错误或者告警时能够显示行号。
- 保留所有#progma编译器指令,因为编译器需要使用它们。
经过预编译后的.i文件不包含任何宏定义,因为所有宏已经被展开,并且包含的文件也已经插入到.i文件中,所以当我们无法判断宏定义是否正确,或者头文件是否正确包含时,可以查看预编译后的文件来确定问题。
- 编译工作
- 编译过程就是把预处理文件进行一系列的词法分析、语法分析、语义分析及优化后生成相应的汇编代码文件。
- 编译命令:gcc -S hello.c -o hello.s
- 汇编工作
- 汇编过程就是把汇编文件转换成机器可以执行的指令,每一条汇编语句几乎都对应一条机器指令。
- 汇编命令:gcc -c hello.c -o hello.o
- 链接
- 链接器通过指令参数把目标文件、库等进行进行链接生成一个可执行文件
- 编译的作用
- 词法分析:将源代码输入到扫描器,运用有限状态机的算法将源代码分割成一系列的记号(token),包括关键字、标识符、字面量、特殊符号。词法扫描器可以是一个独立的程序,每个编译器都可使用。
- 语法分析:语法分析器将记号进行语法分析产生语法树。结点通常为表达式,叶结点为符号和数字。语法分析会判断表达式是否合法,若各种括号不匹配,表达式缺少操作符,编译器就会报告语法分析阶段的错误。
- 语义分析:语法分析仅仅完成了表达式的语法层面的分析,并不了解这个语句是否有真正的含义。编译器所分析的语义是静态语义,是指在编译期可以确定的语义。动态语义是在运行期才能确定的语义。静态语义通常包括声明和类型的匹配,类型转换。动态语义一般指运行期出现的语义相关问题,如除0操作。经过语义分析后,语法树的表达式都标识了类型。
- 源代码级优化、代码生成器、目标代码优化器(乘法移位,删除多余指令)
- 链接
- 符号这个概念被汇编语言用来表示一个地址,可以是一段子程序的起始地址,也可以是一个变量的起始地址。模块间依靠符号进行通信。链接的主要内容是把各模块之间相互引用的部分处理好,使得各模块之间能正确地衔接。链接主要包括了地址和空间分配、符号决议、重定位等步骤。
- 库是一组目标文件的包,就是一些常用的代码编译成目标文件后打包存放。
目标文件
- 目标文件的格式
- 现在流行的可执行文件格式主要是Windows下的PE(portable executable)和Linux的ELF(executable linkable format),它们都是COFF(common file format)格式的变种。
- 目标文件从结构上讲,是编译后的可执行文件格式(.obj、.o),只是未经过链接的过程,它跟可执行文件的内容和格式很相似,所以一般跟可执行文件格式采用一种格式存储。
- 动态链接库(DLL,dynamic linking library,Windows .dll 、linux .so)及静态链接库(static linking library,Windows .lib、Linux .a)文件都可按照可执行文件格式存储。
- 静态链接库把很多目标文件捆绑在一起形成一个文件,再加上一些索引,形成一个文件包。
- 目标文件与可执行文件格式跟操作系统和编译器密切相关,不同的平台和编译器有不同的格式,但是大同小异。
- 目标文件的主要概念是段的机制,不同的目标文件有不同数量及类型的段。
- file命令:查看相应的文件格式。
| ELF文件类型 | 说明 | 实例 |
| 可重定位文件(relocatable file) | 这类文件包含代码和数据,可以被用来连接成可执行文件或共享目标文件,静态链接库也可归为这一类 |
Linux的.o Windows的.obj |
| 可执行文件(executable file) | 这类文件包含了可以直接执行的程序,它的代表就是ELF可执行文件,它们一般都没有扩展名 |
比如/bin/bash文化 Windows的.exe |
| 共享目标文件(shared object file) | 这种文件包含代码和数据,有两种情况下使用,1、链接器把它与其他可重定位文件和共享目标文件产生新的目标文件。2、动态链接器可以将它与可执行文件结合,作为进程影响的一部分来运行 |
linux的.so如/lib/glibc-2.5.so. windows的DLL |
| 核心转储文件(core dump file) | 当进程意外终止时,系统可以将该进程的地址空间的内容及终止时的一些其他信息转储到核心转储文件 | linux的core dump |
- 段的概念
目标文件包括了链接时所需要的一些信息,比如符号表、调试信息、字符串等。
- 文件头:描述了整个文件的文件属性,包括文件是否可执行,是静态链接,动态链接及入口地址,目标硬件,目标操作系统等信息,还包括段表,描述了文件中各个段在文件中的偏移位置及段属性。
- 代码段:机器指令,常见的名字有“.code”、“.text”。
- 数据段:全局变量、局部静态变量,“data”。
- BSS段(Block started by symbol):用于定义符号并且为符号预留给定数量的未初始化空间。未初始化的全局变量和局部静态变量,因为都是0,所以为它们在.data段分配空间并存储0是没有必要的。BSS段存储了所有未初始化的全局变量和局部静态变量的大小总和。
- 程序源代码被编译以后主要分成两段:程序指令和程序数据。
- 当程序被装载后,数据和指令分别被映射到两个虚存区域,数据区域被设置为读写,指令区域被设置为只读,可以防止程序的指令被有意或者无意的改写。
- 指令区域与数据区域分离有利于提高程序的局部性。现代CPU一般都设计成数据缓存和指令缓存分离,所以程序的指令和数据被分开存放对CPU的缓存命中率提高有好处。
- 指令区域共享。当运行着多个程序的副本时,它们的指令是一样的,内存中只须保存一份该程序的指令。每个副本程序的数据区域是私有的。
- 显示段的基本信息:objdum -h
参数-h会打印ELF或者目标文件的各个段的基本信息。除了基本的代码段、数据段、BSS段,显示的段比我们想象的要多。还包括只读数据段、注释信息段、堆栈提示段。段的基本属性,包括段的长度(Size)、段所在的偏移(file offset)、每个段的第2行“CONTENTS”、“ALLOC”等表示段的各种属性,“CONTENTS”表示该段在文件中存在。BSS段没有“CONTENTS”,表示它实际在ELF文件不存在。
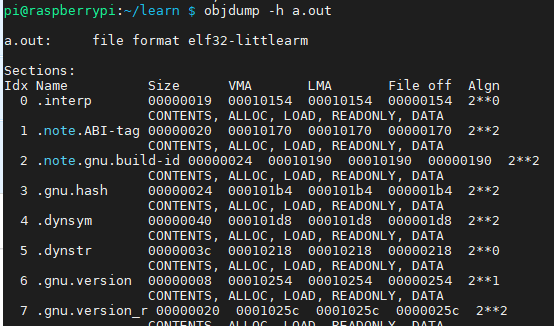
- 显示各段的长度:size命令
dec(十进制)和hex(16进制)分别表示3代码段、数据段、BSS段的总长度。

- 将包含的指令段进行反汇编:objdump -d
- 常用的段名。由“.”作为前缀的名字表示系统保留名,应用程序可以使用非系统保留名作为段名
| 常用段名 | 说明 |
| .rodata1 | read only data,存放只读数据,比如字符串、全局const变量,跟“.rodata”一样 |
| .comment | 存放编译器版本信息,比如字符串“GCC:(GNU)(4.2.0)” |
| .debug | 调试信息 |
| .dynamic | 动态链接信息 |
| .hash | 符号哈希表 |
| .line | 调试时行号表,即源代码行号与编译后指令的对应表 |
| .note | 额外的编译器信息。比如程序的公司名、发布版本号 |
|
.plt .got |
动态链接的跳转表和全局入口表 |
|
.init .fini |
程序初始化与终结代码段 |
| .strtab | 存放elf用到的各种字符串 |
- 自定义段
正常情况下GCC编译出来的目标文件中,代码会被放到“.text”段,全局变量和静态变量放到“.data”和“.bss“段。但有时候希望变量或者某些代码段能够放到指定的段中去,以实现某些指定的功能。比如为了满足某些硬件的内存或者IO地址布局。GCC提供了一个扩展机制,使得程序员可以指定变量所处的段:__attribute__((section("FOO"))) int gloabal = 42;
- ELF文件结构描述
| ELF Header | 文件头:整个文件基本信息 |
| .text | |
| .data | |
| .bss | |
| ... ohter sectrions | |
| sections header table | 段表:各个段基本信息 |
| string tables | 字符串表 |
| symbol tables | 符号表 |
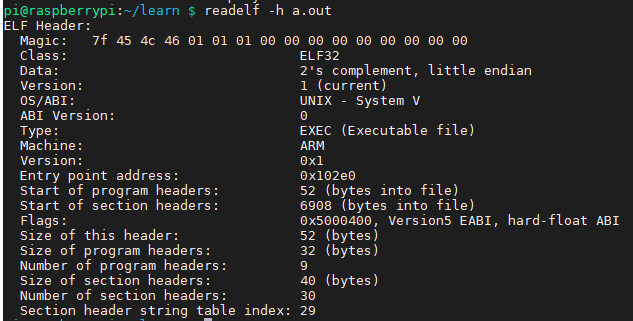
- 文件头:readelf -h file
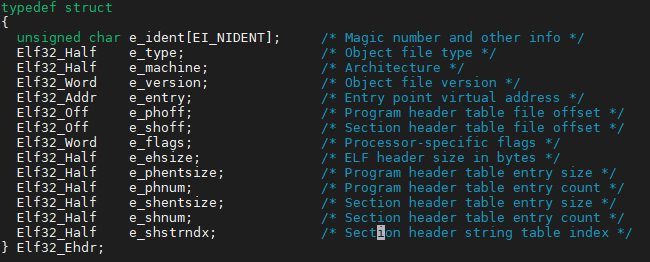
- ELF头文件中定义了ELF魔数、文件机器字节长度、数据存储方式、版本、运行平台、ABI版本、ELF重定位类型、硬件平台、硬件平台版本、入口地址、程序头入口和长度、段表的位置和长度与段的数量;
- ELF文件头结构及相关常数定义在“、usr/include/elf.h”,include/upai/linux/elf.h;
- 可执行文件的最开始几个字节都是魔数,用于确认文件类型,操作系统在加载可执行文件时会确认魔数是否正确;
a.out的文件头信息:
文件头定义:
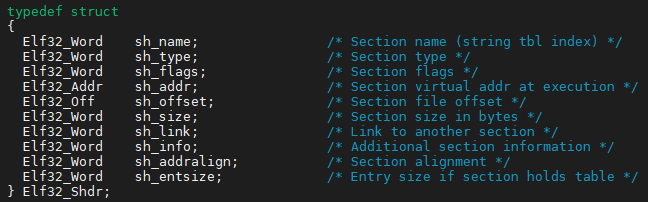
- 段表:readelf -S file
- 段表描述了各个段的基本信息,包括的段名、段长度、段偏移、读写权限等属性;
- 编译器、链接器、装载器根据段表来定位和访问各个段的属性的
- 段表的起始地址可以在文件头的“start of section headers”信息查到;
a.out的段表信息:

段描述符的定义,段描述符的大小为40字节:
- 字符串表
- 字符串表保存了很多字符串,比如段名、变量名。常用作用做法是把字符串集中放到一个表,使用偏移来表示字符串的起始位置,空字符代表结尾,不用关注长度。
- 字符串表常用名字有“.strtab”(字符串表,string table)或“.shstrtab”(段表字符串表)。字符串表用来保存普通的字符串比如符号名字,代码中的字符串常量;段表字符串名用来保存段表中用到的字符串。
- 文件头“Section header string table index: 29”代表段表字符串在段表数组的下标。
- 使用二进制工具,查看a.out找到“.strtab”和“.shstrtab”可看到对应的字符串。如方法1:hexdump -C file;方法2:hexedit file;方法3:使用ultra edit或者beyond compare等工具。
- 符号表
- 每个目标文件都有相应的符号表,每个定义的符号都有对应的值,称为符号值,地址;
- 符号分类:内部定义全局符号、外部引用符号、段名、局部符号、行号信息;链接器只关注第一类和第二类;
- 符号表的名字是“.symtab”。显示符号表内容命令:readelf -s file;nm file
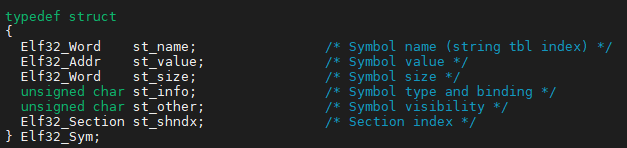
符号表定义:
- 特殊符号
链接器在链接过程中会使用一些程序中未定义的符号,其实这些符号被定义在链接脚本中,你可以在程序中引用它们。例如引用
extern char __executable_start[]; //程序起始地址
extern char __etext[]; //代码段结束地址
- 符号修饰和函数签名
- 为了解决链接过程中的符号冲突问题
- 修饰符号:函数签名,以一定规则,表示符号名、参数类型、它所在类、名称空间和其他信息。
- 不同编译器厂商的名称修饰方法不同;
- C++为了与C兼容,在符号管理上,C++有一个用来声明或者定义一个C符号的关键字“extern “C””;
- 被“extern ”C”“修饰的符号均为修饰后符号,可以被C++代码直接引用;
- 由于C语言不支持“extern “C””,因此要使用C++的宏“__cpluscplus”来控制“extern “C“”,_ifdef _cplusplus extern "C" { #endif;
- 强符号与弱符号
- 不允许强符号被多次定义,即不允许目标文件中有相同的强符号,如果有多个强符号,则链接器报符号重复定义错误;
- 如果一个符号在某个文件中是强符号,在其他文件中是弱符号,则选择强符号;__attribute__ ((weakref)) void foo();
- 如果一个符号在所有目标文件中都是弱符号,那么选择其中占用空间最大的一个。
- 强引用和弱引用
- 链接是如果没有找到符号定义,则报符号未定义。这种符号是强引用;如果未报错,这种符号称为弱引用。
- 对用弱引用,链接器默认其值为0,所以虽然可以链接成功,但是会发生运行错误。__attribute__ ((weak)) void foo();
- 弱符号,弱引用对于库来说非常有用,方便用户进行自定义功能实现,可以对功能进行裁剪和组合。
静态链接
- 相似片段合并
- 第一步:空间与地址分配。扫描所有输入目标文件,计算出输出文件中各个段合并后的长度与位置。
- 第二步:符号解析与重定位。对输入目标文件中的段的数据和重定位信息,进行符号解析与重定位、调整代码中的地址。
- VMA(virtual memory address),LMA(load memory address)。
- 重定位
- 编译器把代码中引用的外部符号先用临时地址代替
- 链接器根据重定位表对符号调整
- 对于每个要被重定位的ELF段都有一个对应的重定位表,而每一个重定位表往往是ELF中的一个段,例如“.text”对应有“.rel.text”;“.data”对应有“.rel.data”
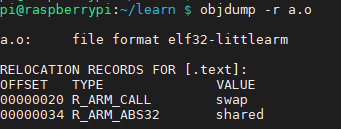
- 命令:objdump -r a.o,查看目标文件引用到外部符号地址,每个重定位地址叫一个重定位入口
- offset表示符号在被重定位段中的偏移
- 符号解析
- 链接目标文件最重要的工作是查找未定义类型的引用,如果找不到就会报未定义错误
- 指令修正:绝对寻址修改正后符号为实际地址;相对寻址修正后的地址为符号距离被修正位置的地址差
- COMMON块,解决弱符号与强符号的原则
- 参考Fortran,当不同的目标文件需要的COMMON块空间大小不一致时,以最大的那块为准
- 当两个或两个以上的弱符号类型不一致是,以占用空间最大的那个为准
- 最本质的原因是由于链接器不支持符号类型,区分符号类型,所以只能选择一个类型的符号定义
- gcc的编译选项“-fno-common”可以把所有未初始化的全局变量不以COMMOM看的形式处理,或者使用__attribute__((nocommon))扩展

 浙公网安备 33010602011771号
浙公网安备 33010602011771号