
组件版本关系
| Spring Cloud Alibaba Version | Sentinel Version | Nacos Version | RocketMQ Version | Dubbo Version | Seata Version |
|---|---|---|---|---|---|
|
2.2.1.RELEASE or 2.1.2.RELEASE or 2.0.2.RELEASE |
1.7.1 |
1.2.1 |
4.4.0 |
2.7.6 |
1.2.0 |
|
2.2.0.RELEASE |
1.7.1 |
1.1.4 |
4.4.0 |
2.7.4.1 |
1.0.0 |
|
2.1.1.RELEASE or 2.0.1.RELEASE or 1.5.1.RELEASE |
1.7.0 |
1.1.4 |
4.4.0 |
2.7.3 |
0.9.0 |
|
2.1.0.RELEASE or 2.0.0.RELEASE or 1.5.0.RELEASE |
1.6.3 |
1.1.1 |
4.4.0 |
2.7.3 |
0.7.1 |
毕业版本依赖关系(推荐使用)
| Spring Cloud Version | Spring Cloud Alibaba Version | Spring Boot Version |
|---|---|---|
|
Spring Cloud Hoxton.SR3 |
2.2.1.RELEASE |
2.2.5.RELEASE |
|
Spring Cloud Hoxton.RELEASE |
2.2.0.RELEASE |
2.2.X.RELEASE |
|
Spring Cloud Greenwich |
2.1.2.RELEASE |
2.1.X.RELEASE |
|
Spring Cloud Finchley |
2.0.2.RELEASE |
2.0.X.RELEASE |
|
Spring Cloud Edgware |
1.5.1.RELEASE(停止维护,建议升级) |
1.5.X.RELEASE |
依赖管理
Spring Cloud Alibaba BOM 包含了它所使用的所有依赖的版本。
RELEASE 版本
Spring Cloud Hoxton
如果需要使用 Spring Cloud Hoxton 版本,请在 dependencyManagement 中添加如下内容
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.1.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency> Spring Cloud Greenwich
如果需要使用 Spring Cloud Greenwich 版本,请在 dependencyManagement 中添加如下内容
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency> Spring Cloud Finchley
如果需要使用 Spring Cloud Finchley 版本,请在 dependencyManagement 中添加如下内容
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.0.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency> Spring Cloud Edgware
如果需要使用 Spring Cloud Edgware 版本,请在 dependencyManagement 中添加如下内容
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>1.5.1.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>服务注册与发现nacos
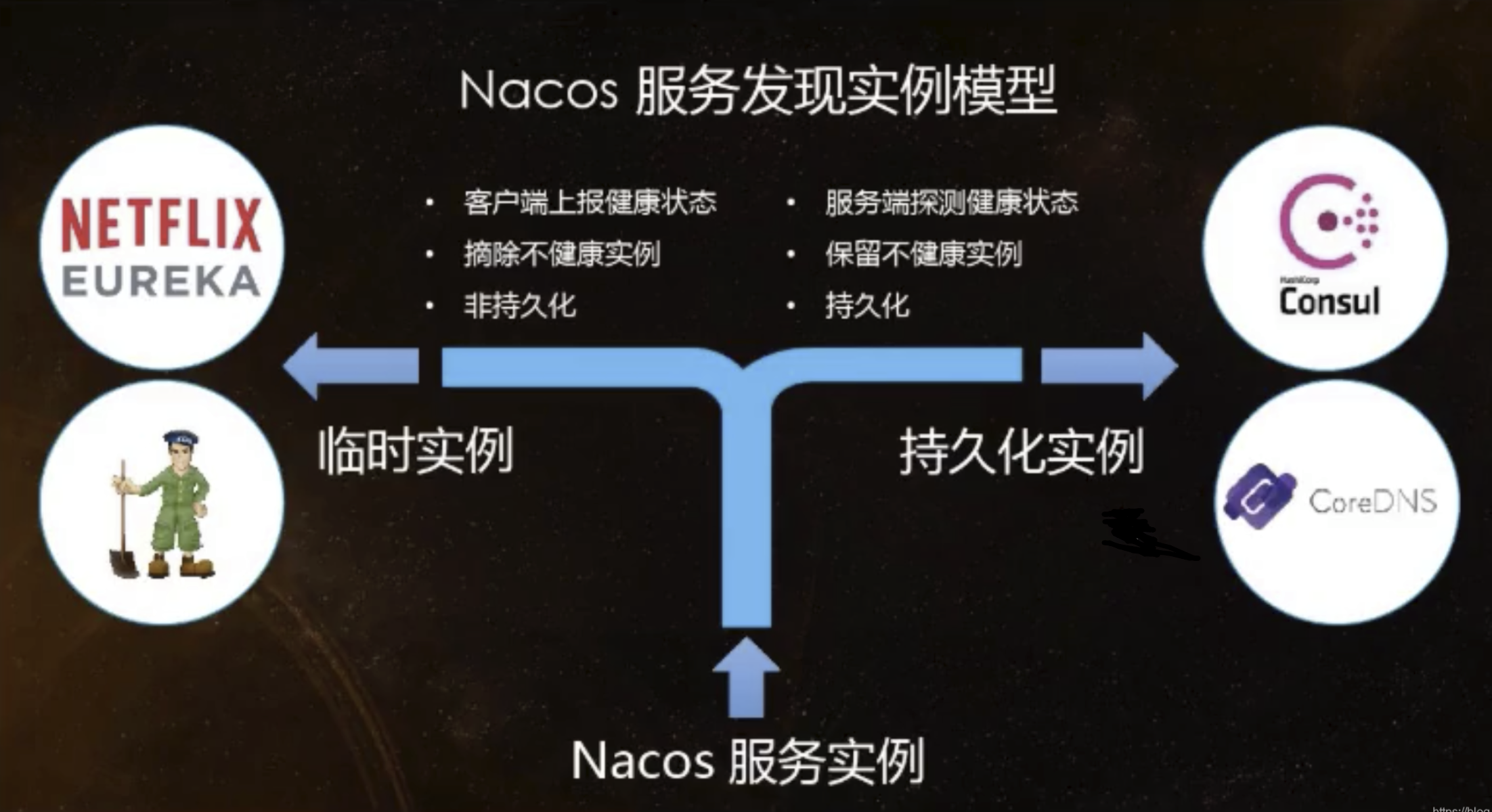
何时选用哪种模式?
一般来说,如果不需要存储服务级别的信息且服务实例是通过nacos-client注册,并能够保持心跳上报,那么就可以选择AP模式。当前主流的服务如Spring Cloud 和 Dubbo服务,都适用于AP模式,AP模式为了服务的可能性而减弱了一致性,因此AP模式下只支持注册临时实例。
如果需要在服务级别编辑或者存储配置信息,那么CP是必须的,K8S服务和DNS服务则适用于CP模式。CP模式下支持注册持久化实例,此时则是以Raft协议为集群运行模式,该模式下注册实例之前必须先注册服务,如果服务不存在,则会返回错误。
curl -X PUT '$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP'
#false为永久实例,true表示临时实例开启,注册为临时实例 spring.cloud.nacos.discovery.ephemeral=false
Nacos产生的背景
Nacos分布式注册与发现功能|分布式配置中心
产生背景rpc远程调用中,服务的url的治理
Rpc的远程调用框架 HttpClient、gprc、dubbo、rest、openfeign等。
传统的rpc远程调用中存在哪些问题
1、超时的问题
2、安全的问题
3、服务与服务之间URL地址管理
在我们微服务架构通讯,服务之间依赖关系非常大,如果通过传统的方式管理我们服务的url地址的情况下,一旦地址发生变化的情况下,还需要人工修改rpc远程调用地址。
每个服务的url管理地址发出复杂,所以这是我们采用服务url治理技术,可以实现对我们整个实现动态服务注册与发现、本地负载均衡、容错等。
服务治理基本的概念
服务治理概念:
在RPC远程调用过程中,服务与服务之间依赖关系非常大,服务Url地址管理非常复杂,所以这时候需要对我们服务的url实现治理,通过服务治理可以实现服务注册与发现、负载均衡、容错等。
rpc远程调用中,地址中 域名和端口号/调用的方法名称:
域名和端口号/调用的方法名称。
服务注册中心的概念
每次调用该服务如果地址直接写死的话,一旦接口发生变化的情况下,这时候需要重新发布版本才可以接口调用地址,所以需要一个注册中心统一管理我们的服务注册与发现。
注册中心:我们的服务注册到我们注册中心,key为服务名称、value为该服务调用地址,该类型为集合类型。Eureka、consul、zookeeper、nacos等。
服务注册:我们生产者项目启动的时候,会将当前服务自己的信息地址注册到注册中心。
服务发现: 消费者从我们的注册中心上获取生产者调用的地址(集合),在使用负载均衡的策略获取集群中某个地址实现本地rpc远程调用。
微服务调用接口常用名词
生产者:提供接口被其他服务调用
消费者:调用生产者接口实现消费
服务注册:将当前服务地址自动注册到 Nacos 服务端
服务发现:动态感知和刷新某个实例的服务列表
服务注册原理实现:
1、生产者启动的时候key=服务的名称 value=ip:端口号 注册到注册中心上。如:member 127.0.0.1:8080
2、注册存放服务地址列表类型:key唯一,列表是list集合。Map<Key,List(String)>
{
member:["127.0.0.1.8080","127.0.0.1.8081"]
}
3、消费者从注册中心上根据服务名称查询服务地址列表(集合)
member=["127.0.0.1.8080","127.0.0.1.8081"]
4、消费者获取到集群列表之后,采用负载均衡器选择一个地址实现rpc远程调用。
Nacos的基本的介绍
Nacos可以实现分布式服务注册与发现/分布式配置中心框架。
官网的介绍: https://nacos.io/zh-cn/docs/what-is-nacos.html
Nacos的环境的准备
Nacos可以在linux/windows/Mac版本上都可以安装
官方安装地址:https://nacos.io/zh-cn/docs/quick-start.html
Nacos整合SpringCloud
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>
<dependencies>
<!-- springboot 整合web组件-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- nacos注册组件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>0.2.2.RELEASE</version>
</dependency>
</dependencies>
提供者
spring: application: name: member-service cloud: nacos: discovery: server-addr: 127.0.0.1:8848 server: port: 8081
消费者
spring: application: name: order-service cloud: nacos: discovery: server-addr: 127.0.0.1:8848 server: port: 8090
package com.lvym.order.service; import com.lvym.order.loadbalance.LoadBalace; import jdk.internal.org.objectweb.asm.tree.LdcInsnNode; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.client.ServiceInstance; import org.springframework.cloud.client.discovery.DiscoveryClient; import org.springframework.cloud.client.loadbalancer.LoadBalancerClient; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; import java.io.IOException; import java.net.URI; import java.util.List; @RestController public class OrderService { @Autowired private DiscoveryClient discoveryClient; // @RequestMapping("/getOrderToMemberInfo") // public Object getOrderToMemberInfo(){ // List<ServiceInstance> instances = discoveryClient.getInstances("menber-service"); // System.out.println(">>>>>>>>>>>>>>>>>>"+instances); // List<String> services = discoveryClient.getServices(); // System.out.println(">>>>>>>>>>>services>>>>>>>"+services); // return instances.get(0); // } @Autowired private RestTemplate restTemplate; @Autowired private LoadBalace loadBalace; @RequestMapping("/getOrderToMemberInfo") public String getOrderToMemberInfo(){ //获取服务列表 List<ServiceInstance> instances = discoveryClient.getInstances("menber-service"); // ServiceInstance serviceInstance = instances.get(0); //自定义轮询 ServiceInstance singleAddres = loadBalace.getSingleAddres(instances); String result = restTemplate.getForObject(singleAddres.getUri()+"/getMemberInfo", String.class); return "订单调用会员,"+result; } /** * ribbon + @LoadBalanced * @return */ @RequestMapping("/getOrderToRibbonMemberInfo") public String getOrderToRibbonMemberInfo(){ String result = restTemplate.getForObject("http://menber-service/getMemberInfo", String.class); return "订单调用会员,"+result; } /*
需要手动注入
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
*/ @Autowired private LoadBalancerClient loadBalancerClient; /** * LoadBalancerClient - @LoadBalanced * @return */ @RequestMapping("/getOrderToLoadBalancerClientMemberInfo") public Object getOrderToLoadBalancerClientMemberInfo(){ URI uri = loadBalancerClient.choose("menber-service").getUri(); String result = restTemplate.getForObject(uri+"/getMemberInfo", String.class); return "订单调用会员,"+result; } }
package com.lvym.order.loadbalance; import org.springframework.cloud.client.ServiceInstance; import java.util.List; public interface LoadBalace { ServiceInstance getSingleAddres(List<ServiceInstance> serviceInstance); }
package com.lvym.order.loadbalance; import org.springframework.cloud.client.ServiceInstance; import org.springframework.stereotype.Component; import java.util.List; import java.util.concurrent.atomic.AtomicInteger; @Component public class RotationLoadBalance implements LoadBalace { private AtomicInteger atomicInteger=new AtomicInteger(0);//记录访问次数 @Override public ServiceInstance getSingleAddres(List<ServiceInstance> serviceInstance) { int index = atomicInteger.incrementAndGet() % serviceInstance.size(); return serviceInstance.get(index); } }
Nacos的集群部署
1.准备三台机器,并把nacos-server-1.3.1.tar.gz上传到机器
2.解压,配置config
application.properties
### Default web server port: server.port=8847
#Linux的默认需要配置数据库
spring.datasource.platform=mysql
### Count of DB: 在这个配置文件的MySQL数量,在这里也可配置其他机器的MySQL
db.num=1
### Connect URL of DB:
db.url.0=jdbc:mysql://192.168.146.110:12345/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user=root
db.password=123456
cluster.conf 这个IP不能写127.0.0.1,必须是Linux命令hostname -i能够识别的IP
192.168.146.110:8847 192.168.146.111:8848 192.168.146.112:8849
另外两台做出相应修改
3.启动
4.进入nacos管理界面
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
Nacos与Eureka区别
1、Eureka采用ap模式形式实现注册中心
2、Nacos默认采用ap模式。在1.0版本之后采用ap+cp模式混合实现注册中心。
Eureka与Nacos底层实现集群协议区别
1、去中心化对等。相互注册
2、Raft协议实现集群产生领导角色。
到底什么是分布式一致性协议的算法
分布式系统一致性算法 应用于系统软件实现集群保持每个节点数据的同步性
保持我们的集群中每个节点的数据的一致性的问题,专业的术语分布式一致性的算法。
场景:Redis集群、nacos集群、mongdb集群等
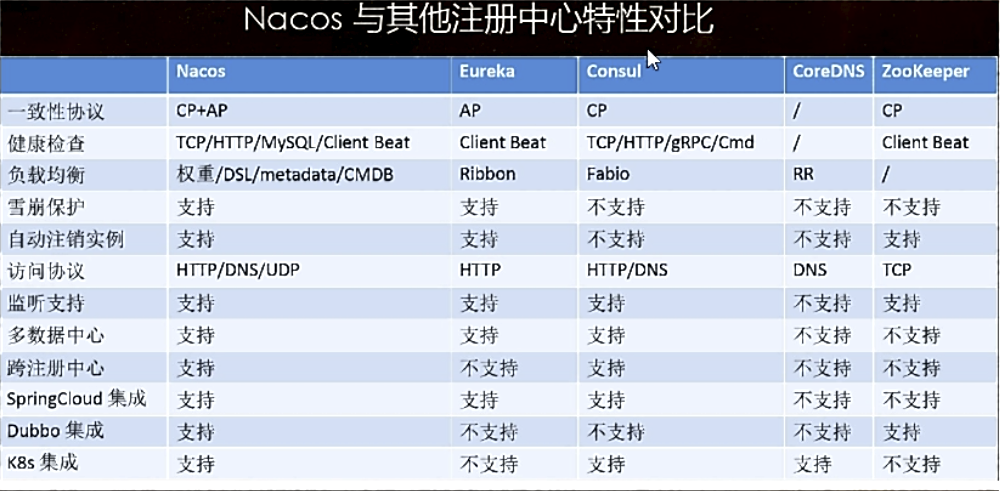
Nacos与Zookeeper区别
1、Zookeeper采用cp模式形式实现注册中心
2、Nacos默认采用ap模式。在1.0版本之后采用ap+cp模式混合实现注册中心。
Zookeeper与Nacos底层实现集群协议区别
1、Zab协议集群,中心化思想集群模式。
2、Raft协议实现集群产生领导角色。
Zab协议集群原理
我们在分布式系统,存在多个系统之间的集群保持数据一致性,采用CP一致性算法保持数据的一致性问题。
Zookeeper基于ZAP协议实现保持每个节点的数据同步的问题,中心化思想集群模式;
分为领导和跟随角色。
在程序中如何成为 某个节点能力比较强:
对每个节点配置一个myid或者serverid还有数值越大表示能力越强 或者随机时间。
整个集群中为了保持数据的一致性的问题,必须满足大多数情况>n/2+1 可运行的节点环境下才可以使用。
ZAP的协议实现原理事通过比较myid myid谁最大谁就是为可能是领导角色,只要满足过半的机制就可以成为领导角色,后来启动的节点不会参与选举的。
Zab协议如何保持数据的一致性问题?
所有写的请求统一交给我们的领导角色实现,领导角色写完数据之后,领导角色再将 数据同步给每个节点。
注意:数据之间同步采用2pc两个阶段提交协议。
第一阶段:携带zxid发送给每个Follower,询问是否同步数据,Follower回馈。
第二阶段:携带zxid发送给每个Follower,询问是否提交数据,Follower回馈。
选举过程:
先去比较zxid zxid谁最大谁就是为领导角色;
如果zxid相等的情况下,myid谁最大谁就为领导角色;
Raft协议选举的基本概念
在Raft协议算法中分为角色|名词:
1、状态:分为三种 跟随者、竞选者(候选人)、领导角色 。 三台机器似乎只有领导者和候选人
2、大多数:>=n/2+1
3、任期:每次选举一个新的领导角色 任期都会 +1
4、竞选者谁的票数最多,谁就是为领导角色
多个竞选者,产生的票数都一样,这到底谁是领导角色,服务器集群是偶数的情况下。总之票数相同就重新选举。
SpringCloud负载均衡器说明
在SpringCloud第一代中使用Ribbon、SpringCloud第二代中直接采用自研发loadbalancer即可,默认使用的Ribbon。
ribbon:
//需要手动注入
@Bean @LoadBalanced public RestTemplate restTemplate() { return new RestTemplate(); }
/** * ribbon + @LoadBalanced * @return */ @RequestMapping("/getOrderToRibbonMemberInfo") public String getOrderToRibbonMemberInfo(){ String result = restTemplate.getForObject("http://menber-service/getMemberInfo", String.class); return "订单调用会员,"+result; }
loadbalancer:
@Autowired private LoadBalancerClient loadBalancerClient; /** * LoadBalancerClient - @LoadBalanced * @return */ @RequestMapping("/getOrderToLoadBalancerClientMemberInfo") public Object getOrderToLoadBalancerClientMemberInfo(){ URI uri = loadBalancerClient.choose("menber-service").getUri(); String result = restTemplate.getForObject(uri+"/getMemberInfo", String.class); return "订单调用会员,"+result; }
本地负载均衡与Nginx 的区别
本地负载均衡
本地负载均衡器基本的概念:我们的消费者服务从我们的注册中心获取到集群地址列表,缓存到本地,然后本地采用负载均衡策略(轮训、随机、权重等),实现本地的rpc远程的。
本地负载均衡器有哪些呢:自己写、ribbon SpringleCloud第一代中loadbalancer SpringCloud自己研发。
如何选择ribbon还是loadbalancer
SpringCloud Rest或者Openfeign都是默认支持ribbon。
区别
Nginx是客户端所有的请求统一都交给我们的Nginx处理,让后在由Nginx实现负载均衡转发,属于服务器端负载均衡器。
本地负载均衡器是从注册中心获取到集群地址列表,本地实现负载均衡算法,既本地负载均衡器。
应用场景:
Nginx属于服务器负载均衡,应用于Tomcat/Jetty服务器等,而我们的本地负载均衡器,应用于在微服务架构中rpc框架中,rest、openfeign、dubbo。
OpenFeign客户端
OpenFeign是一个Web声明式的Http客户端调用工具,提供接口和注解形式调用。
SpringCloud第一代采用feign第二代采用openfeign
openfeign客户端作用:是一个Web声明式的Http客户端远程调用工具,底层是封装HttpClient技术。
Openfeign属于SPringleCloud自己研发,而feign是netflix代码写法几乎是没有任何变化。
注意feign客户端调用的事项:如果请求参数没有加上注解的话,默认采用post请求发送。
Openfeign默认是支持负载均衡,ribbon。
测试:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2.0.0.RELEASE</version>
</dependency>
调用方:继承被调用方的接口
@FeignClient("member-service")
public interface MemberServiceFeign extends MemberService{}
版本:
2.6.13
2021.0.5.0
2021.0.5
与之前的不同:
分布式配置中心
分布式配置中心产生的背景?
在项目中定义配置文件,最大的缺陷?
如果在生成环境正在运行的时候突然需要修改配置文件的话,必须重启我们的服务器。
分布式配置中心的框架有哪些:
携程的阿波罗、Nacos(属于轻量级)、SpringCloud Config(没有界面)、携程的阿波罗(属于比较重的分布式配置)/disConfig等。
轻量级:部署、架构设计原理都比较简单,学习成本也是比较低:
重量级:部署、架构设计、体量都是非常大,学习成本是比较高。
如何判断配置文件是否发生变化 采用版本|MD5(nacos)
分布式配置中心实现原理:
1、本地应用读取我们云端分布式配置中心文件(第一次建立长连接)
2、本地应用读取到配置文件之后,本地jvm和硬盘中都会缓存一份。
3、本地应用与分布式配置中心服务器端一致保持长连接。
4、当我们的配置文件发生变化(MD5|版本号)实现区分,将变化的结果通知给我们的本地应用实时的刷新我们的配置文件。
完全百分百实现动态化修改我们的配置文件。
注意:Nacos分布式配置中心和注册中心都部署在同一个应用,就是一个单体的应用。
分布式配置中心的作用
分布式配置中心可以实现不需要重启我们的服务器,动态的修改我们的配置文件内容,
常见的配置中心有携程的阿波罗、SpringCloud Config、Nacos轻量级的配置中心等。
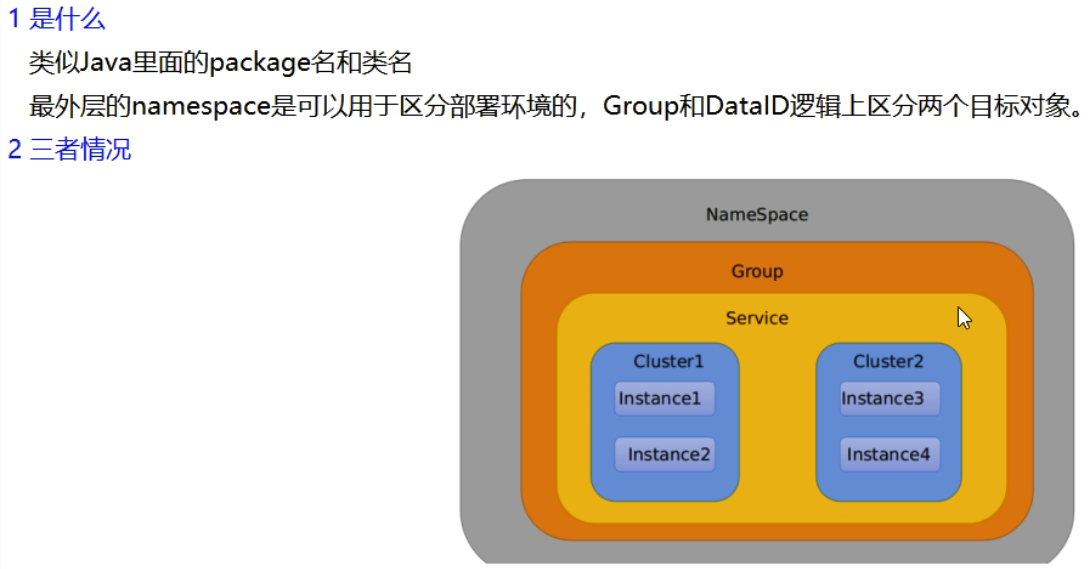

指定spring.profile.active和配置文件的DataID来使不同环境下读取不同的配置
测试:
进入nacos配置
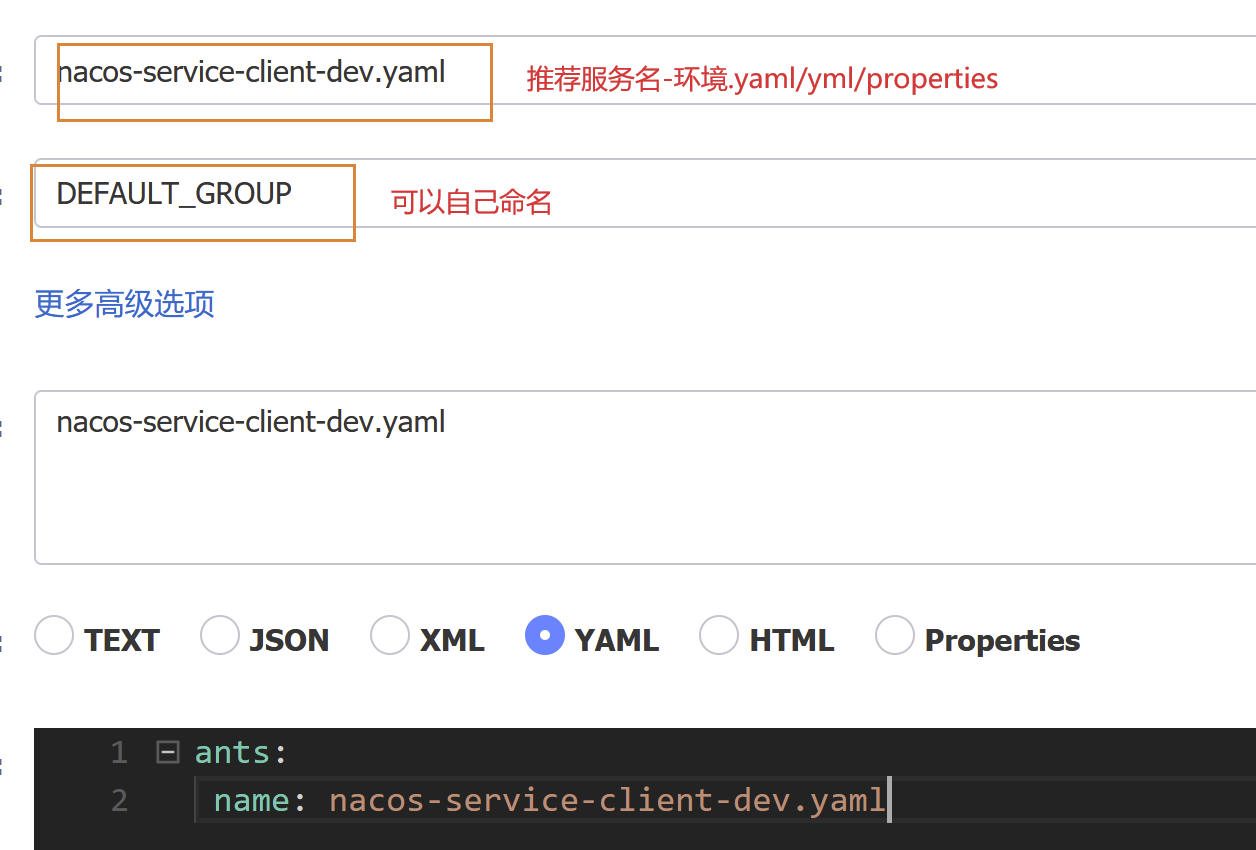
命名规则:https://github.com/alibaba/spring-cloud-alibaba/wiki/Nacos-config
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
<version>0.2.2.RELEASE</version>
</dependency>
新建bootstrap.yml
spring: application: name: nacos-service-client cloud: nacos: config: server-addr: 127.0.0.1:8848 group: DEFAULT_GROUP #namespace: ****
file-extension: yaml #要与配置中心文件后缀完全匹配 yml=yml yaml=yaml properties=properties
application.yml
spring: cloud: nacos: discovery: server-addr: 127.0.0.1:8848 profiles: active: dev #版本
测试:
package com.lvym.nacos.controller; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.context.config.annotation.RefreshScope; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController @RefreshScope //实时刷新,拉取配置 public class NacosController { @Value("${ants.name}") private String antsName; @GetMapping("/getInfo") public String getInfo(){ return antsName; } }
配置中心数据持久化,不会因为每次重启配置会消失,默认存储内存,
1.导入sql文件到数据库,文件在conf目录下nacos-mysql.sql
2.修改配置文件 application.properties
#*************** Config Module Related Configurations ***************# ### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://139.196.130.111:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user=lvym db.password=tbny1312
3.重新启动。
默认的情况下,分布式配置中心的数据存放到本地data目录下,但是这种情况如果nacos集群的话无法保证数据的同步性。
在0.7版本之前,在单机模式时nacos使用嵌入式数据库实现数据的存储,不方便观察数据存储的基本情况。0.7版本增加了支持mysql数据源能力,具体的操作步骤:
1.安装数据库,版本要求:5.6.5+ 版本在1.3.1之后可以使用MySQL8
2.初始化mysql数据库,数据库初始化文件:nacos-mysql.sql
3.修改conf/application.properties文件,增加支持mysql数据源配置(目前只支持mysql),添加mysql数据源的url、用户名和密码。
基于Nacos+Nginx集群部署方案
1.nacos集群跟上面一样,
2.配置 nginx.conf
#gzip on; upstream nacosCluster{ server 127.0.0.1:8847 server 127.0.0.1:8848;
server 127.0.0.1:8849; } server { listen 80; server_name localhost; location /nacos/ { proxy_pass http://nacosCluster; }
3.配置
spring: application: ###服务的名称 name: nacos-client cloud: nacos: discovery: ###nacos注册地址 server-addr: 127.0.0.1:8847,127.0.0.1:8848,127.0.0.1:8849 enabled: true config: ###配置中心连接地址 可选 server-addr: 127.0.0.1:8847,127.0.0.1:8848,127.0.0.1:8849 ###分组 group: DEFAULT_GROUP ###类型 file-extension: yaml
微服务网关
微服务网关是整个微服务API请求的入口,可以实现过滤Api接口。
作用:可以实现用户的验证登录、解决跨域、日志拦截、权限控制、限流、熔断、负载均衡、黑名单与白名单机制等。
微服务中的架构模式采用前后端分离,前端调用接口地址都能够被抓包分析到。
在微服务中,我们所有的企业入口必须先经过Api网关,经过Api网关转发到真实的服务器中。
如果此时需要添加验证会话信息:
传统的方式我们可以使用过滤器拦截用户会话信息,这个过程所有的服务器都必须写入该验证会话登录的代码。
过滤器与网关的区别
过滤器适合于单个服务实现过滤请求;
网关拦截整个的微服务实现过滤请求,能够解决整个微服务中冗余代码。
过滤器是局部拦截,网关实现全局拦截。
Zuul与Gateway有哪些区别
Zuul网关属于netfix公司开源的产品,属于第一代微服务网关。
Gateway属于SpringCloud自研发的网关框架,属于第二代微服务网关。
相比来说SpringCloudGateway性能比Zuul性能要好。
注意:Zuul网关底层基于Servlet实现的,阻塞式的Api, 不支持长连接。
SpringCloudGateway基于Spring5构建,能够实现响应式非阻塞式的Api,支持长连接,能够更好的整合Spring体系的产品,依赖SpringBoot-WebFux。
Spring Cloud Gateway 使用的Webflux中的reactor-netty响应式编程组件,底层使用了Netty通讯框架
测试:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
<version>2.0.0.RELEASE</version>
</dependency>
不能有,否则报错
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
yml
server:
port: 80
spring:
application:
name: gateway-service
cloud:
gateway:
discovery:
locator:
enabled: true #开启以服务id去注册中心上获取转发地址
routes:
- id: baidu
uri: http://www.baidu.com/ #转发http://www.baidu.com/
predicates:
- Path=/bd/** #匹配规则
# 127.0.0.1/bd 转发到http://www.baidu.com/
##路由id
- id: member
uri: lb://member-service
filters: #过滤
- StripPrefix=1
predicates:
- Path=/member/**
#- After=2020-03-08T10:59:34.102+08:00[Asia/Shanghai]
#- Cookie=username,zhangshuai #并且Cookie是username=zhangshuai才能访问
#- Header=X-Request-Id, \d+ #请求头中要有X-Request-Id属性并且值为整数的正则表达式
#- Host=**.lvym.com
#- Method=GET
#- Query=username, \d+ #要有参数名称并且是正整数才能路由
可以通过访问 http://localhost/member/接口 访问。。。。
Nginx与网关的区别
微服务网关能够做的事情,Nginx也可以实现。
相同点:都是可以实现对api接口的拦截,负载均衡、反向代理、请求过滤等,可以实现和网关一样的效果。
不同点:
Nginx采用C语言编写的
在微服务领域中,都是自己语言编写的,比如我们使用java构建微服务项目,Gateway就是java语言编写的。
Gateway属于Java语言编写的, 能够更好对微服务实现扩展功能,相比Nginx如果想实现扩展功能需要结合Nginx+Lua语言等。
Nginx实现负载均衡的原理:属于服务器端负载均衡器。
Gateway实现负载均衡原理:采用本地负载均衡器的形式。
GateWay高可用
使用Nginx或者lvs虚拟vip访问增加系统的高可用。
动态请求参数网关
动态网关:任何配置都实现不用重启网关服务器都可以及时刷新网关配置。
方案:
1.基于数据库形式实现,特别建议,阅读性高
2.基于配置中心实现,不建议使用,需要定义json格式配置,阅读性差
注意:配置中心实现维护性比较差,建议采用数据库形式设计。
基于数据库表形式的设计
网关已经提供了API接口
1、直接新增
2、直接修改
思路:
默认加载时候
1、当我们的网关服务启动的时候,从我们数据库查询网关的配置。
2、将数据库的内容读取到网关内存中
网关配置要更新的时候,需要同步调用
测试:
1.增加表
CREATE TABLE `gateway` ( `id` int(11) NOT NULL AUTO_INCREMENT, `route_id` varchar(11) DEFAULT NULL, `route_name` varchar(255) DEFAULT NULL, `route_pattern` varchar(255) DEFAULT NULL, `route_type` varchar(255) DEFAULT NULL, `route_url` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=latin1;
2.依赖
<!-- mysql 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- 阿里巴巴数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.14</version>
</dependency>
3.实体类
package com.lvym.gateway.entity; import lombok.Data; @Data public class GateWayEntity { private Long id; private String routeId; private String routeName; private String routePattern; private String routeType; private String routeUrl; }
4.yml
server: port: 80 spring: application: name: gateway-service cloud: gateway: discovery: locator: enabled: true #开启以服务id去注册中心上获取转发地址 routes: # - id: baidu # uri: http://www.baidu.com/ #转发http://www.baidu.com/ # predicates: # - Path=/bd/** #匹配规则 # # 127.0.0.1/bd 转发到http://www.baidu.com/ # ##路由id # - id: member # uri: lb://member-service # filters: #过滤 # - StripPrefix=1 # predicates: # - Path=/member/** nacos: discovery: server-addr: 127.0.0.1:8848 datasource: url: jdbc:mysql://139.196.130.111:3306/gateway?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC username: lvym password: tbny1312 driver-class-name: com.mysql.cj.jdbc.Driver
5.实现类
package com.lvym.gateway.service; import com.lvym.gateway.entity.GateWayEntity; import com.lvym.gateway.mapper.AntsGatewayMapper; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cloud.gateway.event.RefreshRoutesEvent; import org.springframework.cloud.gateway.filter.FilterDefinition; import org.springframework.cloud.gateway.handler.predicate.PredicateDefinition; import org.springframework.cloud.gateway.route.RouteDefinition; import org.springframework.cloud.gateway.route.RouteDefinitionWriter; import org.springframework.context.ApplicationEventPublisher; import org.springframework.context.ApplicationEventPublisherAware; import org.springframework.stereotype.Service; import org.springframework.web.util.UriComponentsBuilder; import reactor.core.publisher.Mono; import java.net.URI; import java.util.Arrays; import java.util.HashMap; import java.util.List; import java.util.Map; @Service public class GatewayService implements ApplicationEventPublisherAware { private ApplicationEventPublisher publisher; @Autowired private RouteDefinitionWriter routeDefinitionWriter; @Autowired private AntsGatewayMapper antsGatewayMapper; @Override public void setApplicationEventPublisher(ApplicationEventPublisher applicationEventPublisher) { this.publisher = applicationEventPublisher; } public String initAllRoute() { // 从数据库查询配置的网关配置 List<GateWayEntity> gateWayEntities = antsGatewayMapper.gateWayAll(); for (GateWayEntity gw : gateWayEntities) { loadRoute(gw); } return "SUCCESS"; } public String loadRoute(GateWayEntity gateWayEntity) { RouteDefinition definition = new RouteDefinition(); Map<String, String> predicateParams = new HashMap<>(8); PredicateDefinition predicate = new PredicateDefinition(); FilterDefinition filterDefinition = new FilterDefinition(); Map<String, String> filterParams = new HashMap<>(8); // 如果配置路由type为0的话 则从注册中心获取服务 URI uri = null; if (gateWayEntity.getRouteType().equals("0")) { uri = UriComponentsBuilder.fromUriString("lb://" + gateWayEntity.getRouteUrl() + "/").build().toUri(); } else { uri = UriComponentsBuilder.fromHttpUrl(gateWayEntity.getRouteUrl()).build().toUri(); } // 定义的路由唯一的id definition.setId(gateWayEntity.getRouteId()); predicate.setName("Path"); //路由转发地址 predicateParams.put("pattern", gateWayEntity.getRoutePattern()); predicate.setArgs(predicateParams); // 名称是固定的, 路径去前缀 filterDefinition.setName("StripPrefix"); filterParams.put("_genkey_0", "1"); filterDefinition.setArgs(filterParams); definition.setPredicates(Arrays.asList(predicate)); definition.setFilters(Arrays.asList(filterDefinition)); definition.setUri(uri); routeDefinitionWriter.save(Mono.just(definition)).subscribe(); this.publisher.publishEvent(new RefreshRoutesEvent(this)); return "SUCCESS"; } }
6.mapper
package com.lvym.gateway.mapper; import com.lvym.gateway.entity.GateWayEntity; import org.apache.ibatis.annotations.Param; import org.apache.ibatis.annotations.Select; import org.apache.ibatis.annotations.Update; import java.util.List; public interface AntsGatewayMapper { @Select("SELECT ID AS ID, route_id as routeid, route_name as routeName,route_pattern as routePattern\n" + ",route_type as routeType,route_url as routeUrl\n" + " FROM ants_gateway\n") List<GateWayEntity> gateWayAll(); @Update("update ants_gateway set route_url=#{routeUrl} where route_id=#{routeId};") Integer updateGateWay(@Param("routeId") String routeId, @Param("routeUrl") String routeUrl); }
7.controller
package com.lvym.gateway.controller; import com.lvym.gateway.service.GatewayService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class GatewayController { @Autowired private GatewayService gatewayService; /** * 同步网关配置 * * @return */ @RequestMapping("/synGatewayConfig") public String synGatewayConfig() { return gatewayService.initAllRoute(); } }
更多网关配置:https://cloud.spring.io/spring-cloud-gateway/reference/html/#gatewayfilter-factories
GateWay解决跨域的问题
@Component public class CrossOriginFilter implements GlobalFilter { @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { ServerHttpRequest request = exchange.getRequest(); ServerHttpResponse response = exchange.getResponse(); HttpHeaders headers = response.getHeaders(); headers.add(HttpHeaders.ACCESS_CONTROL_ALLOW_ORIGIN, "*"); headers.add(HttpHeaders.ACCESS_CONTROL_ALLOW_METHODS, "POST, GET, PUT, OPTIONS, DELETE, PATCH"); headers.add(HttpHeaders.ACCESS_CONTROL_ALLOW_CREDENTIALS, "true"); headers.add(HttpHeaders.ACCESS_CONTROL_ALLOW_HEADERS, "*"); headers.add(HttpHeaders.ACCESS_CONTROL_EXPOSE_HEADERS, "*"); return chain.filter(exchange); } }
网关GateWay源码分析
1.客户端向网关发送Http请求,会到达DispatcherHandler接受请求,匹配到 RoutePredicateHandlerMapping。
- 根据RoutePredicateHandlerMapping匹配到具体的路由策略。
- FilteringWebHandler获取的路由的GatewayFilter数组,创建 GatewayFilterChain 处理过滤请求
- 执行我们的代理业务逻辑访问。
常用配置类说明:
- GatewayClassPathWarningAutoConfiguration 检查是否有正确的配置webflux
- GatewayAutoConfiguration 核心配置类
- GatewayLoadBalancerClientAutoConfiguration 负载均衡策略处理
- GatewayRedisAutoConfiguration Redis+lua整合限流
spring.factoies
- GatewayClassPathWarningAutoConfiguration 作用检查是否配置我们webfux依赖。
- GatewayAutoConfiguration加载了我们Gateway需要的注入的类。
- GatewayLoadBalancerClientAutoConfiguration 网关需要使用的负载均衡 Lb//mayikt-member// 根据服务名称查找真实地址
- GatewayRedisAutoConfiguration 网关整合Redis整合Lua实现限流
- GatewayDiscoveryClientAutoConfiguration 服务注册与发现功能
解决跨域的问题
- HttpClient转发
- 使用过滤器允许接口可以跨域 响应头设置
- Jsonp 不支持我们的post 属于前端解决
- Nginx解决跨域的问题保持我们域名和端口号一致性
- Nginx也是通过配置文件解决跨域的问题
- 基于微服务网关解决跨域问题,需要保持域名和端口一致性
- 使用网关代码允许所有的服务可以跨域的问题
- 使用SpringBoot注解形式@CrossOrigin
SpringCloud Sentinel
Sentinel 介绍
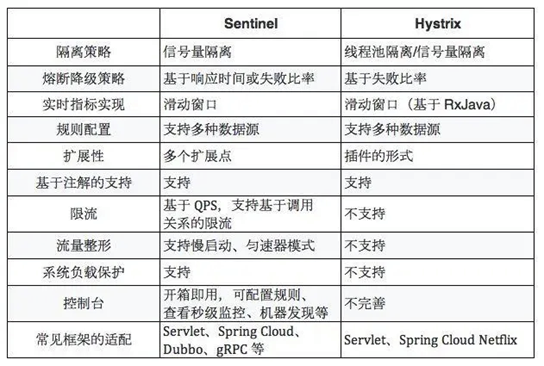
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。 Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 具有以下特征:
-
丰富的应用场景: Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、实时熔断下游不可用应用等。
-
完备的实时监控: Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
-
广泛的开源生态: Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
-
完善的 SPI 扩展点: Sentinel 提供简单易用、完善的 SPI 扩展点。您可以通过实现扩展点,快速的定制逻辑。例如定制规则管理、适配数据源等。
服务限流/熔断
服务限流目的是为了更好的保护我们的服务,在高并发的情况下,如果客户端请求的数量达到一定极限(后台可以配置阈值),请求的数量超出了设置的阈值,开启自我的保护,直接调用我们的服务降级的方法,不会执行业务逻辑操作,直接走本地blockHandler的方法,返回一个友好的提示。
服务降级
在高并发的情况下, 防止用户一直等待,采用限流/熔断方法,使用服务降级的方式返回一个友好的提示给客户端,不会执行业务逻辑请求,直接走本地的fallback的方法。返回一个友好的提示给到客户端。
提示语:当前排队人数过多,稍后重试~
熔断降级设计理念
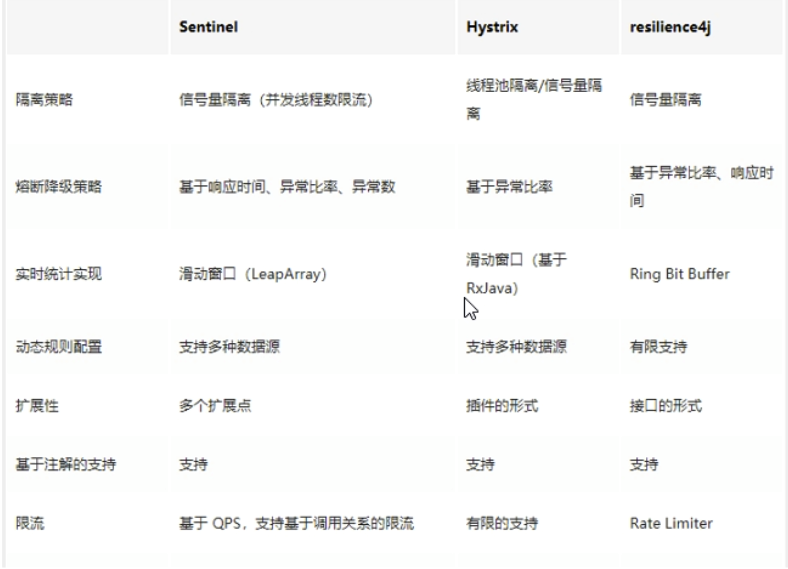
在限制的手段上,Sentinel 和 Hystrix 采取了完全不一样的方法。
Hystrix 通过 线程池隔离 的方式,来对依赖(在 Sentinel 的概念中对应 资源)进行了隔离。这样做的好处是资源和资源之间做到了最彻底的隔离。缺点是除了增加了线程切换的成本(过多的线程池导致线程数目过多),还需要预先给各个资源做线程池大小的分配。
Sentinel 对这个问题采取了两种手段:
- 通过并发线程数进行限制
和资源池隔离的方法不同,Sentinel 通过限制资源并发线程的数量,来减少不稳定资源对其它资源的影响。这样不但没有线程切换的损耗,也不需要您预先分配线程池的大小。当某个资源出现不稳定的情况下,例如响应时间变长,对资源的直接影响就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后,对该资源的新请求就会被拒绝。堆积的线程完成任务后才开始继续接收请求。
- 通过响应时间对资源进行降级
除了对并发线程数进行控制以外,Sentinel 还可以通过响应时间来快速降级不稳定的资源。当依赖的资源出现响应时间过长后,所有对该资源的访问都会被直接拒绝,直到过了指定的时间窗口之后才重新恢复。
fallback与blockHandler的区别
fallback是服务熔断或者业务逻辑出现异常执行的方法(1.6版本以上)
blockHandler 限流出现错误执行的方法
服务的雪崩效应
默认的情况下,Tomcat或者是Jetty服务器只有一个线程池去处理客户端的请求,
这样的话就是在高并发的情况下,如果客户端所有的请求都堆积到同一个服务接口上,
那么就会产生tomcat服务器所有的线程都在处理该接口,可能会导致其他的接口无法访问,短暂没有线程处理
Sentinel 与hytrix区别
哨兵以流量为切入点,从流量控制,熔断降级,系统负载保护等多个维度保护服务的稳定性。


Sentinel的断路器是没有半开状态的,半开的状态系统自动去检测是否请求有异常,没有异常就关闭断路器恢复使用,有异常则继续打开断路器不可用。
Sentinel采用的懒加载说明。

Sentinel 实现对Api动态限流
限流配置有两种方案:
1、手动使用代码配置 纯代码/注解的形式
2、Sentinel控制台形式配置+注解 推荐
默认情况下Sentinel不对数据持久化,需要自己独立持久化
测试:控制台+注解
1.下载sentinel-dashboard-1.7.1.jar 并运行 java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar 可做相应修改
2.依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-alibaba-sentinel</artifactId>
<version>0.2.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
3.yml
server: port: 8090 spring: application: name: order-service cloud: nacos: discovery: server-addr: 127.0.0.1:8848 sentinel: transport: dashboard: 127.0.0.1:8080 #界面访问接口 port: 8719 #默认 通讯接口 eager: true
4.实现类
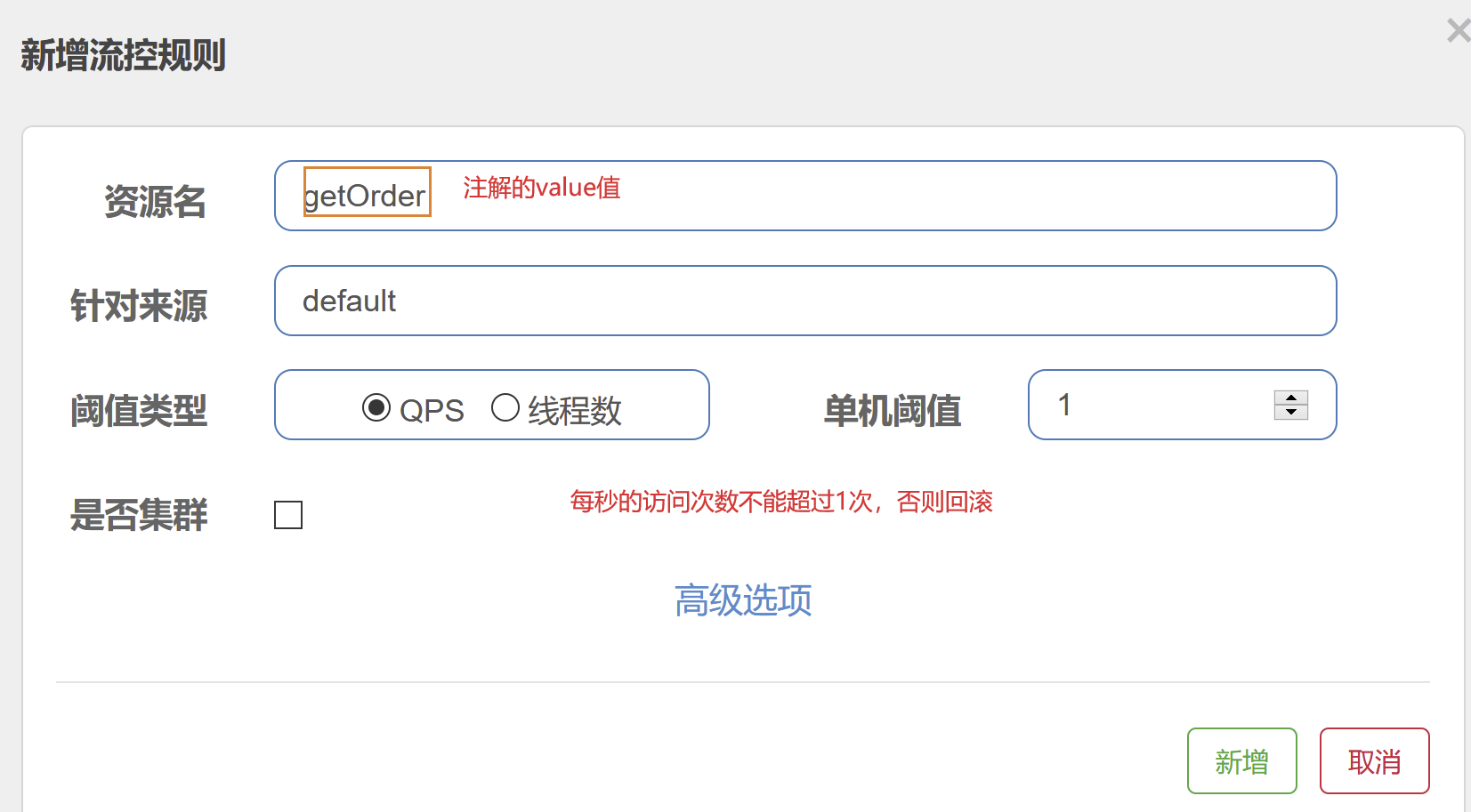
流控--QPS
private static final String GETORDER_KEY = "getOrder";
/** * 限流
* 不写注解 @SentinelResource 默认资源名是 /getOrderAnnotation 且有自己的回滚提示。 blockHandlerClass * @return */ @SentinelResource(value = GETORDER_KEY,blockHandler ="getOrderQpsException") @RequestMapping("/getOrderAnnotation") public String getOrderAnnotation() { return "getOrder接口"; } /** * 被限流后返回的提示 * * @param e * @return */ public String getOrderQpsException(BlockException e) { e.printStackTrace(); return "该接口已经被限流啦!"; }
注意:资源名可以精确到方法名,免写value值(=方法名)
启动项目,并登录sentinel管理界面

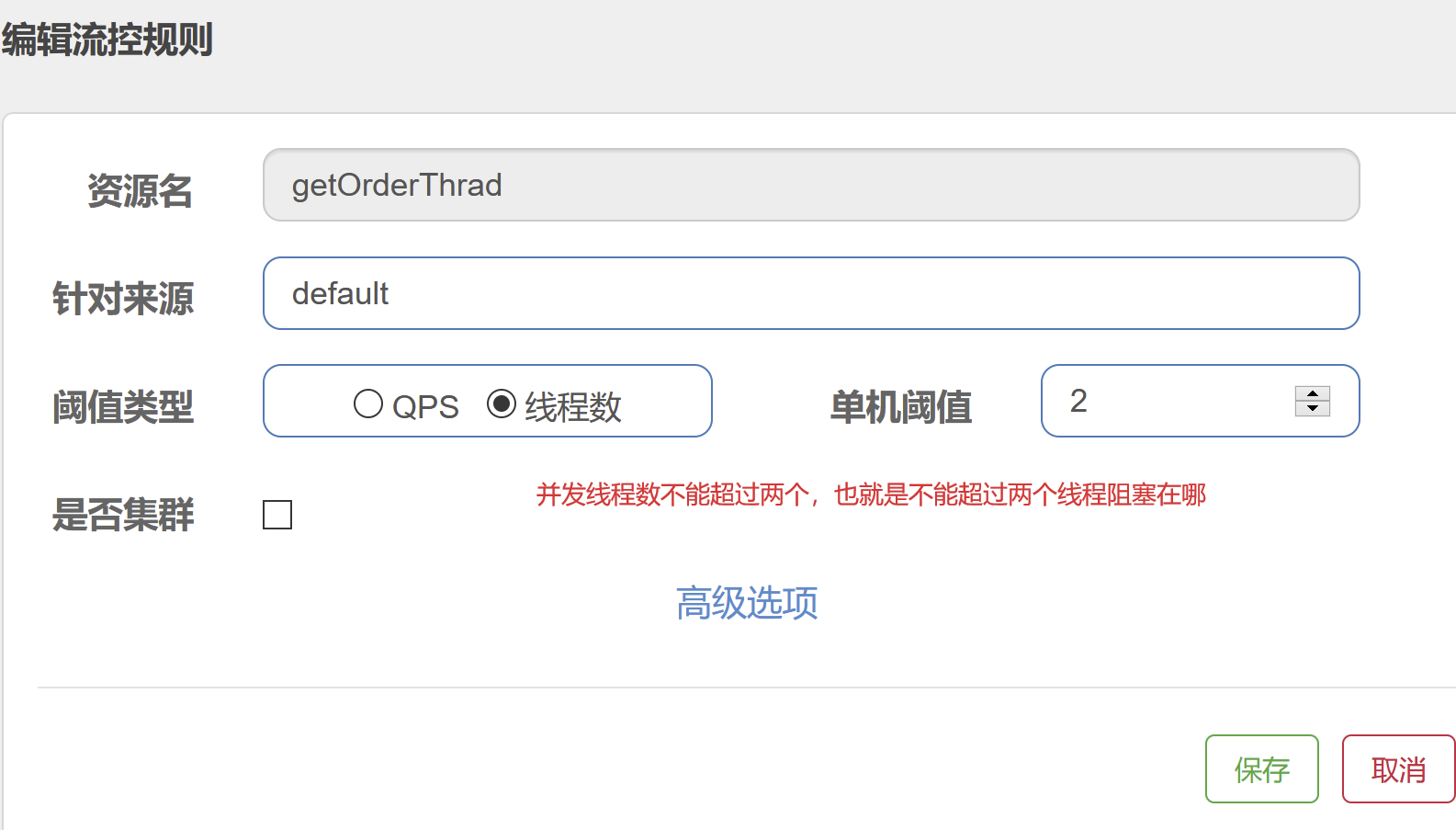
流控 --线程数
/** * 限流-- 并发数量处理限流 * @return */ @SentinelResource(value = "getOrderThrad",blockHandler ="getOrderQpsException") @RequestMapping("/getOrderThrad") public String getOrderThrad() { System.out.println(Thread.currentThread().getName()); try { Thread.sleep(1000); } catch (Exception e) { } return "getOrderThrad"; }
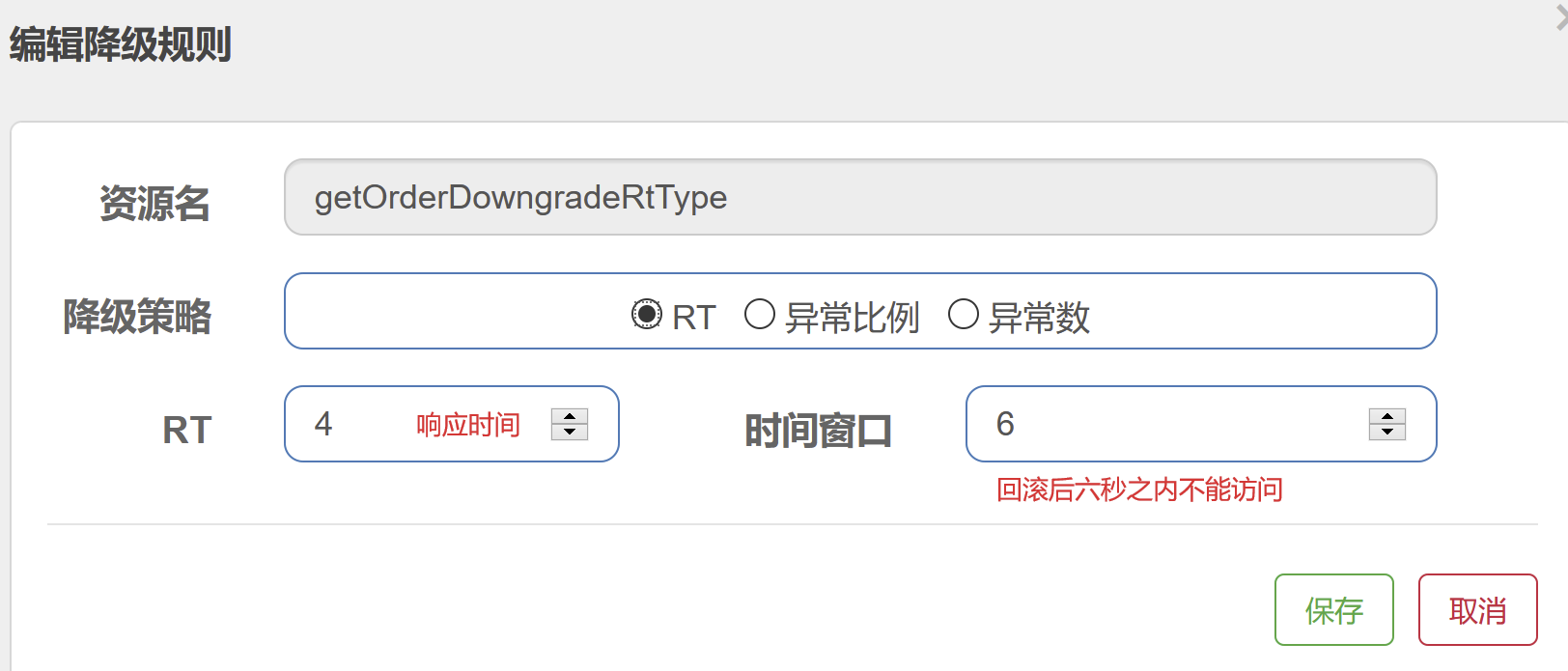
降级---RT
/** * 基于我们的平均响应时间实现降级 * fallbackClass * @return */ @SentinelResource(value = "getOrderDowngradeRtType", fallback = "getOrderDowngradeRtTypeFallback") @RequestMapping("/getOrderDowngradeRtType") public String getOrderDowngradeRtType() { try { Thread.sleep(300); } catch (Exception e) { System.out.println("降级不会走"); } System.out.println("次数"); return "正常执行我们业务逻辑"; } public String getOrderDowngradeRtTypeFallback() { return "执行我们本地的服务降级的方法"; }
平均响应时间 (DEGRADE_GRADE_RT):当 1s 内持续进入 N 个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置
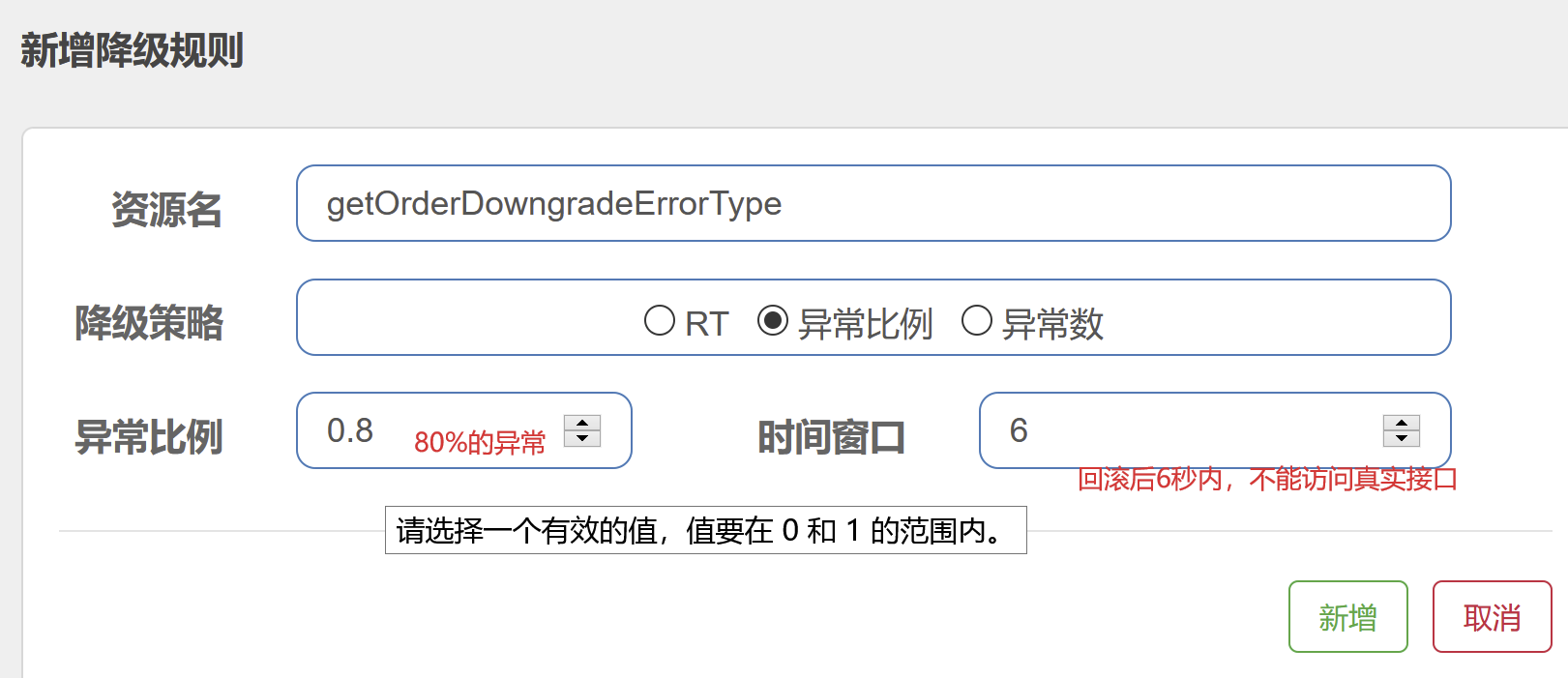
降级----异常比例
/** * 基于我们错误率/异常实现服务降级 * * @return */ @SentinelResource(value = "getOrderDowngradeErrorType", fallback = "getOrderDowngradeErrorTypeFallback") @RequestMapping("/getOrderDowngradeErrorType") public String getOrderDowngradeErrorType(int age) { int j = 1 / age; return "正常执行我们业务逻辑:j" + j; } public String getOrderDowngradeErrorTypeFallback(int age) { return "错误率/异常数太高,展示无法访问该接口"; }
异常比例 (DEGRADE_GRADE_EXCEPTION_RATIO):当资源的每秒请求量 >= N(可配置),并且每秒异常总数占通过量的比值超过阈值(DegradeRule 中的 count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
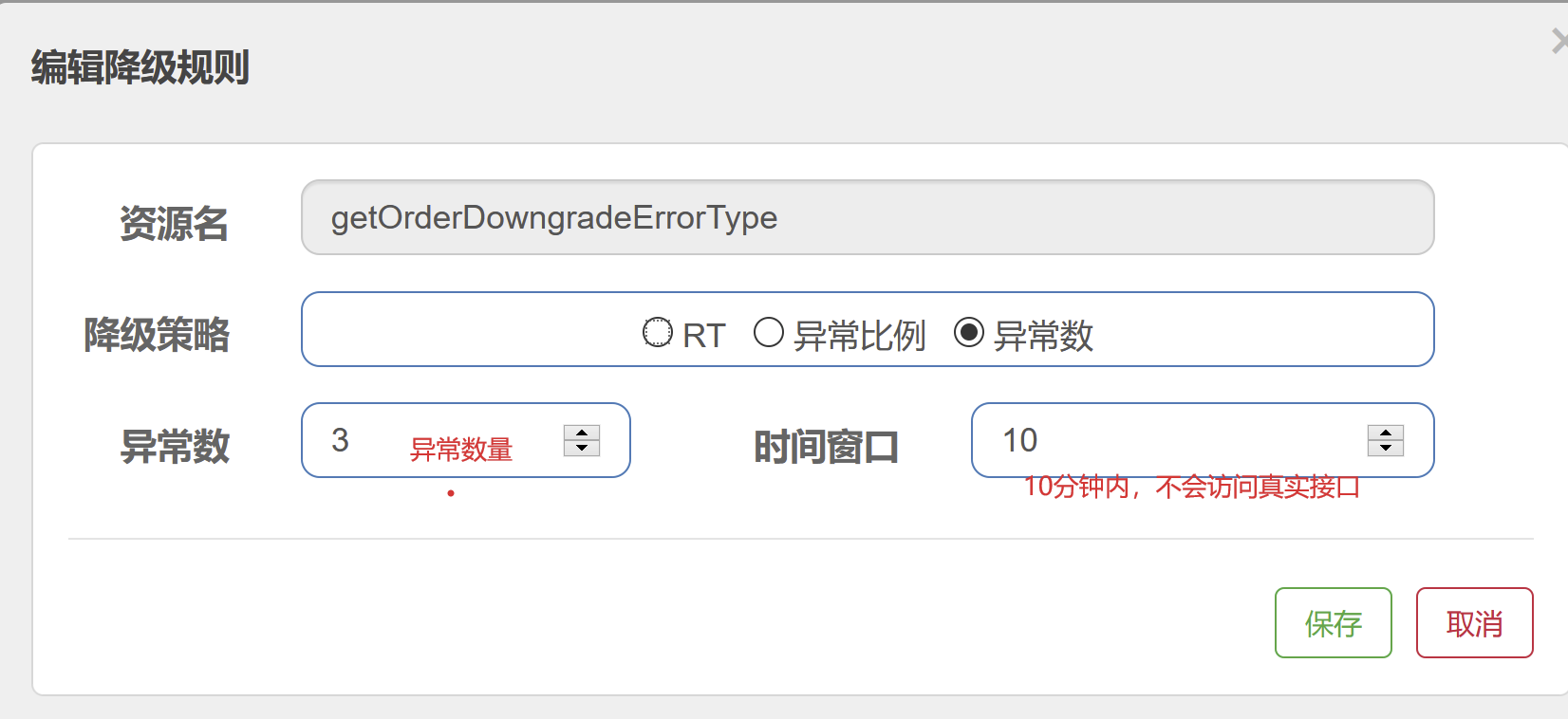
降级---异常数
/** * 基于我们错误率/异常实现服务降级 * * @return */ @SentinelResource(value = "getOrderDowngradeErrorType", fallback = "getOrderDowngradeErrorTypeFallback") @RequestMapping("/getOrderDowngradeErrorType") public String getOrderDowngradeErrorType(int age) { int j = 1 / age; return "正常执行我们业务逻辑:j" + j; } public String getOrderDowngradeErrorTypeFallback(int age) { return "错误率/异常数太高,展示无法访问该接口"; }
异常数 (DEGRADE_GRADE_EXCEPTION_COUNT):当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若 timeWindow 小于 60s,则结束熔断状态后仍可能再进入熔断状态。
热点规则
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
- 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
- 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限
![Sentinel Parameter Flow Control]()
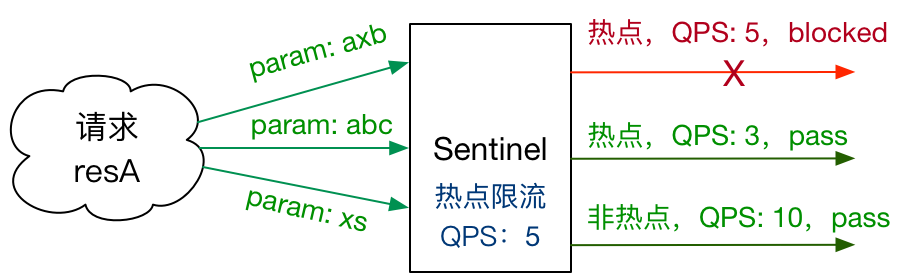
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。热点参数限流支持集群模式。
@SentinelResource(value = "seckill", fallback = "seckillFallback", blockHandler = "seckillBlockHandler") @RequestMapping("/seckill") public String seckill(Long userId, Long orderId) { return "秒杀成功"; } public String seckillFallback(Long userId, Long orderId) { return "不走这里"; } public String seckillBlockHandler(Long userId, Long orderId) { return "不走这里"; }
热点回滚:
package com.lvym.service.order.config; import com.alibaba.csp.sentinel.slots.block.flow.param.ParamFlowException; import org.springframework.web.bind.annotation.ExceptionHandler; import org.springframework.web.bind.annotation.ResponseBody; import org.springframework.web.bind.annotation.RestControllerAdvice; @RestControllerAdvice public class InterfaceExceptionHandler { @ResponseBody @ExceptionHandler(ParamFlowException.class) public String businessInterfaceException(ParamFlowException e) { return "您当前访问的频率过高,请稍后重试!"; } }

Sentinel规则的持久化
默认的情况下Sentinel的规则是存放在内存中,如果Sentinel客户端重启后,Sentinel数据规则可能会丢失。
解决方案:
Sentinel持久化机制支持四种持久化的机制。
- 本地文件 ,拉模式
- 携程阿波罗 ,推模式
- Nacos ,推模式
- Zookeeper ,推模式
基于Nacos持久化我们的数据规则+动态修改
进入nacos界面配置
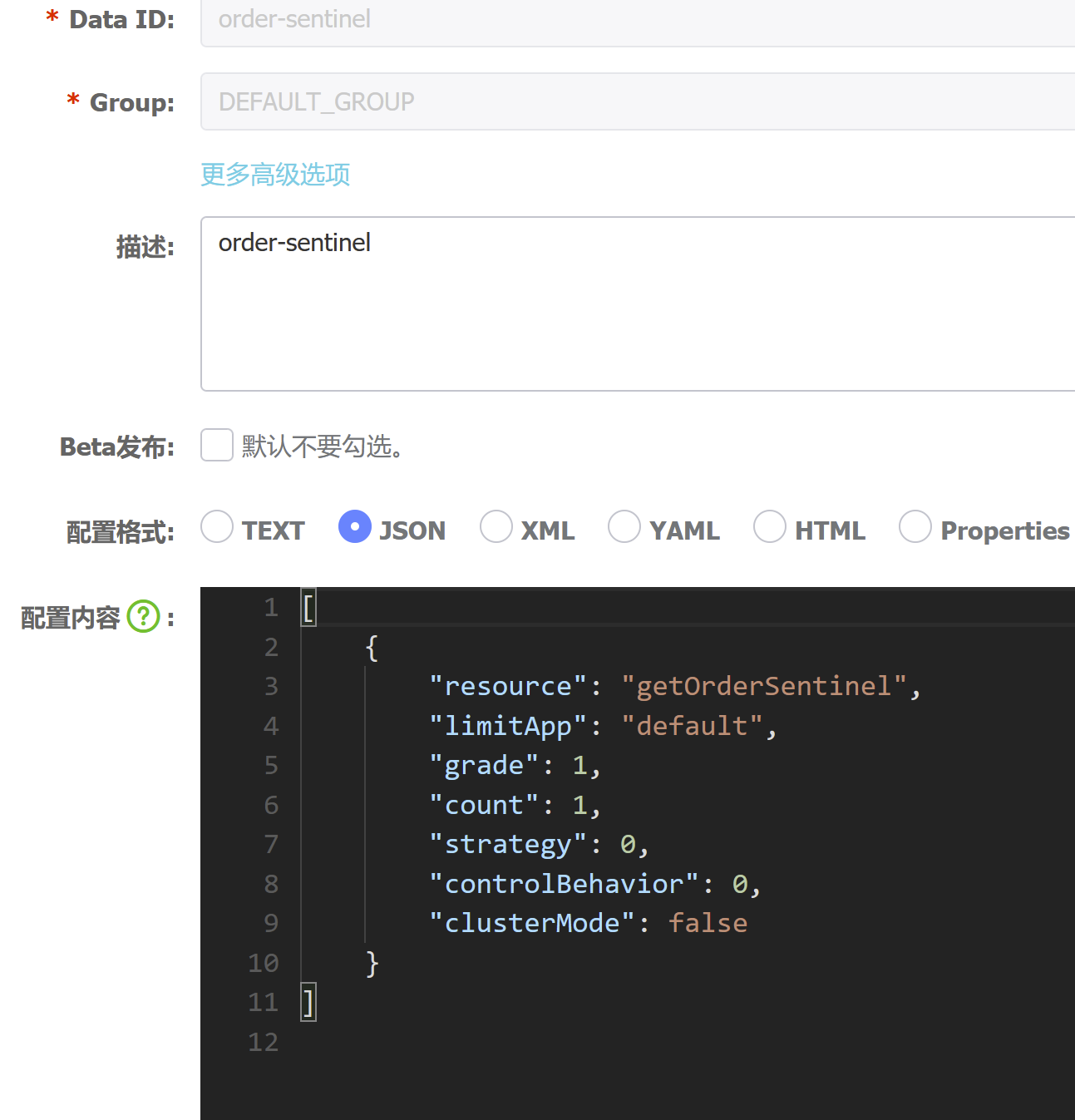
resource:资源名,即限流规则的作用对象
limitApp:流控针对的调用来源,若为 default 则不区分调用来源
grade:限流阈值类型(QPS 或并发线程数);0代表根据并发数量来限流,1代表根据QPS来进行流量控制
count:限流阈值
strategy:调用关系限流策略
controlBehavior:流量控制效果(直接拒绝、Warm Up、匀速排队)
clusterMode:是否为集群模式
[ { "resource": "getOrderSentinel", "limitApp": "default", "grade": 1, "count": 1, "strategy": 0, "controlBehavior": 0, "clusterMode": false } ]
实现类:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
<version>1.5.2</version>
</dependency>
yml
server: port: 8090 spring: application: name: order-service cloud: nacos: discovery: server-addr: 127.0.0.1:8848 sentinel: transport: dashboard: 127.0.0.1:8080 #界面访问接口 port: 8719 #默认 通讯接口 eager: true datasource: ds: nacos: ### nacos连接地址 server-addr: localhost:8848 ## nacos连接的分组 group-id: DEFAULT_GROUP ###路由存储规则 rule-type: flow ### 读取配置文件的 data-id data-id: order-sentinel ### 读取培训文件类型为json data-type: json
/** * 持久化 * @return */ @SentinelResource(value = "getOrderSentinel", blockHandler = "getOrderQpsException") @RequestMapping("/getOrderSentinel") public String getOrderSentinel() { return "getOrderSentinel持久化"; }
SpringCloudGateWay整合sentinel实现限流
https://github.com/alibaba/Sentinel/wiki/%E7%BD%91%E5%85%B3%E9%99%90%E6%B5%81
1.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
<version>2.0.0.RELEASE</version>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-spring-cloud-gateway-adapter</artifactId>
<version>1.6.0</version>
</dependency>
2.yml
server: port: 80 spring: application: name: gateway-service cloud: gateway: discovery: locator: enabled: true #开启以服务id去注册中心上获取转发地址 routes: - id: baidu uri: http://www.baidu.com/ #转发http://www.baidu.com/ predicates: - Path=/bd/** #匹配规则 #127.0.0.1/bd 转发到http://www.baidu.com/
3.GatewayConfiguration
package com.lvym.gateway.config; import com.alibaba.csp.sentinel.adapter.gateway.sc.SentinelGatewayFilter; import com.alibaba.csp.sentinel.adapter.gateway.sc.exception.SentinelGatewayBlockExceptionHandler; import org.springframework.beans.factory.ObjectProvider; import org.springframework.cloud.gateway.filter.GlobalFilter; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.Ordered; import org.springframework.core.annotation.Order; import org.springframework.http.codec.ServerCodecConfigurer; import org.springframework.web.reactive.result.view.ViewResolver; import java.util.Collections; import java.util.List; @Configuration public class GatewayConfiguration { private final List<ViewResolver> viewResolvers; private final ServerCodecConfigurer serverCodecConfigurer; public GatewayConfiguration(ObjectProvider<List<ViewResolver>> viewResolversProvider, ServerCodecConfigurer serverCodecConfigurer) { this.viewResolvers = viewResolversProvider.getIfAvailable(Collections::emptyList); this.serverCodecConfigurer = serverCodecConfigurer; } // @Bean // @Order(Ordered.HIGHEST_PRECEDENCE) // public SentinelGatewayBlockExceptionHandler sentinelGatewayBlockExceptionHandler() { // // Register the block exception handler for Spring Cloud Gateway. // return new SentinelGatewayBlockExceptionHandler(viewResolvers, serverCodecConfigurer); // } /** * 自定以回滚 * @return */ @Bean @Order(Ordered.HIGHEST_PRECEDENCE) public JsonSentinelGatewayBlockExceptionHandler jsonSentinelGatewayBlockExceptionHandler() { // 自定义 return new JsonSentinelGatewayBlockExceptionHandler(viewResolvers, serverCodecConfigurer); } @Bean @Order(Ordered.HIGHEST_PRECEDENCE) public GlobalFilter sentinelGatewayFilter() { return new SentinelGatewayFilter(); } }
自定义回滚:
package com.lvym.gateway.config; import org.springframework.core.io.buffer.DataBuffer; import org.springframework.http.codec.ServerCodecConfigurer; import org.springframework.http.server.reactive.ServerHttpResponse; import org.springframework.web.reactive.result.view.ViewResolver; import org.springframework.web.server.ServerWebExchange; import org.springframework.web.server.WebExceptionHandler; import reactor.core.publisher.Mono; import java.nio.charset.StandardCharsets; import java.util.List; public class JsonSentinelGatewayBlockExceptionHandler implements WebExceptionHandler { public JsonSentinelGatewayBlockExceptionHandler(List<ViewResolver> viewResolvers, ServerCodecConfigurer serverCodecConfigurer) { } @Override public Mono<Void> handle(ServerWebExchange exchange, Throwable ex) { ServerHttpResponse serverHttpResponse = exchange.getResponse(); serverHttpResponse.getHeaders().add("Content-Type", "application/json;charset=UTF-8"); byte[] datas = "{\"code\":403,\"msg\":\"API接口被限流\"}".getBytes(StandardCharsets.UTF_8); DataBuffer buffer = serverHttpResponse.bufferFactory().wrap(datas); return serverHttpResponse.writeWith(Mono.just(buffer)); } }
4.规则
package com.lvym.gateway.config; import com.alibaba.csp.sentinel.adapter.gateway.common.rule.GatewayFlowRule; import com.alibaba.csp.sentinel.adapter.gateway.common.rule.GatewayRuleManager; import lombok.extern.slf4j.Slf4j; import org.springframework.boot.ApplicationArguments; import org.springframework.boot.ApplicationRunner; import org.springframework.stereotype.Component; import java.util.HashSet; import java.util.Set; @Slf4j @Component public class SentinelApplicationRunner implements ApplicationRunner { @Override public void run(ApplicationArguments args){ initGatewayRules(); } /** * 配置限流规则 */ private void initGatewayRules() { Set<GatewayFlowRule> rules = new HashSet<>(); rules.add(new GatewayFlowRule("baidu") // 限流阈值 .setCount(1) // 统计时间窗口,单位是秒,默认是 1 秒 .setIntervalSec(1) ); GatewayRuleManager.loadRules(rules); } }
基于nacos网关动态sentinel,不知什么原因,一走网关,sentinel就会删除规则???????????????
Feign整合Sentinel
<!--sentinel客户端-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
在配置文件中开启Feign对Sentinel的支持
feign: sentinel: enabled: true
容错类中拿到具体的错误
@FeignClient(value = "service-product",
fallbackFactory = ProductServiceFallBackFactory.class)
fallback
import com.itheima.service.ProductService; import feign.hystrix.FallbackFactory; import lombok.extern.slf4j.Slf4j; import org.springframework.stereotype.Service; //这是容错类,他要求我们要是实现一个FallbackFactory<要为哪个接口产生容错类> @Slf4j @Service public class ProductServiceFallbackFactory implements FallbackFactory<ProductService> { //Throwable 这就是fegin在调用过程中产生异常 @Override public ProductService create(Throwable throwable) { return new ProductService() { @Override public Product findByPid(Integer pid) { log.error("{}",throwable); Product product = new Product(); product.setPid(-100); product.setPname("商品微服务调用出现异常了,已经进入到了容错方法中"); return product; } }; } }
SpringCloud 解决分布式事务
Base与CAP理论
这个定理的内容是指的是在一个分布式系统中、Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
一致性C:在分布式系统中,同一时刻所有的节点的数据都是相同的;
可用性A: 集群中部分节点出现了故障,集群的整体也能够给响应;
分区容错性P:分区容错性是指系统能够容忍节点之间的网络通信的故障,意味着发生了分区的情况,必须就当前操作在C和A之间做出选择;
BASE是Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent(最终一致性)三个短语的缩写。
目前主流分布式解决框架
- 单体项目多数据源 可以jta+ Atomikos
- 基于rabbitmq的形式解决 最终一致性的思想
- 基于rocketmq解决分布式事务 采用事务消息
- LCN采用lcn模式 假关闭连接 (目前已经被淘汰)
- Alibaba的Seata 未来可能是主流 背景非常强大
两阶段提交协议基本概念
两阶段提交协议可以理解为2pc,也就是分为参与者和协调者,协调者会通过两次阶段实现数据最终的一致性的。
2PC和3pc的区别就是解决参与者超时的问题和多加了一层询问,保证数据的传输可靠性。
Seata 是什么?
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
官方文档:http://seata.io/zh-cn/docs/overview/what-is-seata.html
Seata的实现原理
Seata有3个基本组成部分:
事务协调器(TC):维护全局事务和分支事务的状态,驱动全局提交或回滚。
事务管理器TM:定义全局事务的范围:开始全局事务,提交或回滚全局事务。
资源管理器(RM):管理分支事务正在处理的资源,与TC进行对话以注册分支事务并报告分支事务的状态,并驱动分支事务的提交或回滚。
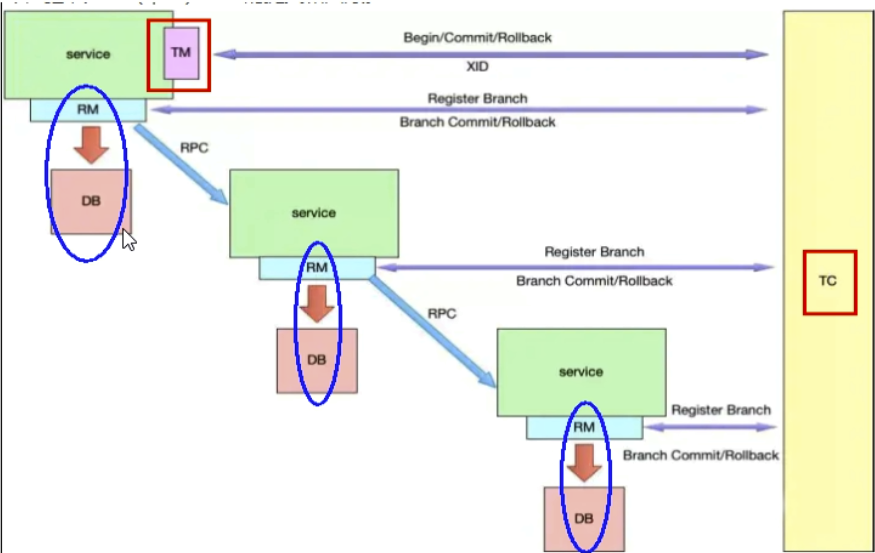
分布式事务的执行流程
TM开启分布式事务(TM向TC注册全局事务记录)
换业务场景,编排数据库,服务等事务内资源(RM向TC汇报资源准备状态)
TM结束分布式事务,事务一阶段结束(TM通知TC提交/回滚分布式事务)
TC汇总事务信息,决定分布式事务是提交还是回滚
TC通知所有RM提交/回滚资源,事务二阶段结束。
分布式事务产生的背景
- 如果是在传统项目中,使用同一个数据源,在数据用同用一个事务管理器的情况下,不存在分别事务事务问题,因为有事务的传播行为帮助我们实现。每个数据源都自己独立的事务事务管理,每个数据源中的事务管理都互不影响。
- 2. 如果是在单体项目中, 存在多个不同的数据源,每个事务源都有自己独立的事务管理器,每个事务管理器互不影响,也会存在分布式事务的问题。Jta+atominc 将每个独立的事务管理器统一交给我们的atominc全局事务管理。
- 3. 在分布式系统中采用rpc远程通讯也会存在分布式事务问题。
分布式rpc通讯中为什么会存在分布式事务?
消费者(调用方)调用完接口成功之后后,调用方突然抛出异常。。
Rpc通讯中产生的分布式事务的问题原因
1.调用方(订单服务)调用完rpc接口之后,突然程序抛出异常,调用方的事务回滚了,但是被调用方接口没有回滚。
订单服务回滚了,派单成功,在每个jvm中都有自己的本地事务,每个事务都互不影响。
2.被调用方(派单服务)的接口失败的话,调用方可以根据返回的结果,手动回滚调用方本地事务。
解决分布式事务的最大核心是什么?
最终一致性 在分布式系统中, 因为rpc通讯是需要时间的,短暂的数据一致这是允许的,但是最终数据一定要保持一致性;
Base理论和CAP理论
CAP总结:三者无法兼顾,在分布式系统当中可以容忍网络之间出现的通讯故障;
要么是CP或者AP
CP:当你网络出现故障之后,只能保证数据一致性,但是不能保证可用性; zk
AP:当你网络出现故障之后,不能保证数据一致性,但是能够保证可用性 eureka
在分布式系统中,可能存在强一致性的问题。
注意:在分布式系统中无法保证强一致性,因为数据短暂不一致这是运行的,但是最终数据一定要保证一致性的问题。
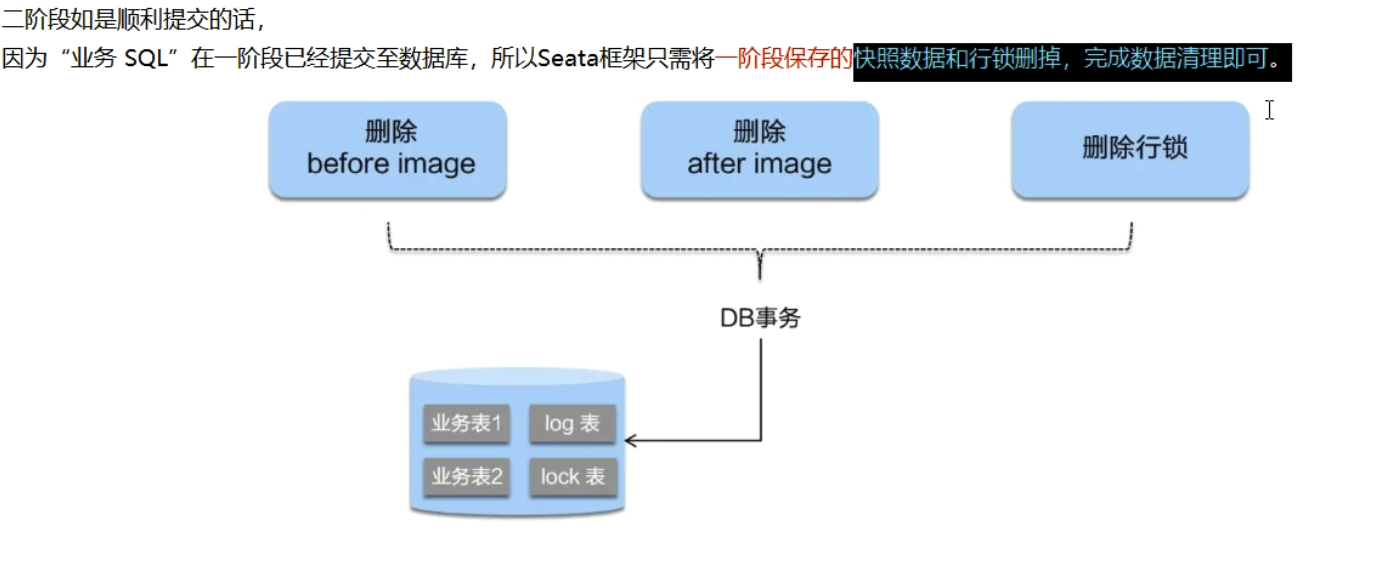
AT模式如何做到对业务的无侵入?




测试:》》》》》》》》》》
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<artifactId>seata-all</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>0.9.0</version>
</dependency>
yml
server: port: 2001 spring: application: name: seata-order-service cloud: alibaba: seata: tx-service-group: fsp_tx_group #自定义事务组名称需要与seata-server中的对应 nacos: discovery: server-addr: localhost:8848 datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.146.177:3306/seata_order username: root password: Lvym777@ feign: hystrix: enabled: true logging: level: io: seata: info mybatis: mapperLocations: classpath:mapper/*.xml
file.conf
transport { # tcp udt unix-domain-socket type = "TCP" #NIO NATIVE server = "NIO" #enable heartbeat heartbeat = true #thread factory for netty thread-factory { boss-thread-prefix = "NettyBoss" worker-thread-prefix = "NettyServerNIOWorker" server-executor-thread-prefix = "NettyServerBizHandler" share-boss-worker = false client-selector-thread-prefix = "NettyClientSelector" client-selector-thread-size = 1 client-worker-thread-prefix = "NettyClientWorkerThread" # netty boss thread size,will not be used for UDT boss-thread-size = 1 #auto default pin or 8 worker-thread-size = 8 } shutdown { # when destroy server, wait seconds wait = 3 } serialization = "seata" compressor = "none" } service { vgroup_mapping.fsp_tx_group = "default" #修改自定义事务组名称 default.grouplist = "127.0.0.1:8091" enableDegrade = false disable = false max.commit.retry.timeout = "-1" max.rollback.retry.timeout = "-1" disableGlobalTransaction = false } client { async.commit.buffer.limit = 10000 lock { retry.internal = 10 retry.times = 30 } report.retry.count = 5 tm.commit.retry.count = 1 tm.rollback.retry.count = 1 } ## transaction log store store { ## store mode: file、db mode = "db" ## file store file { dir = "sessionStore" # branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions max-branch-session-size = 16384 # globe session size , if exceeded throws exceptions max-global-session-size = 512 # file buffer size , if exceeded allocate new buffer file-write-buffer-cache-size = 16384 # when recover batch read size session.reload.read_size = 100 # async, sync flush-disk-mode = async } ## database store db { ## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc. datasource = "dbcp" ## mysql/oracle/h2/oceanbase etc. db-type = "mysql" driver-class-name = "com.mysql.jdbc.Driver" url = "jdbc:mysql://192.168.146.177:3306/seata" user = "root" password = "Lvym777@" min-conn = 1 max-conn = 3 global.table = "global_table" branch.table = "branch_table" lock-table = "lock_table" query-limit = 100 } } lock { ## the lock store mode: local、remote mode = "remote" local { ## store locks in user's database } remote { ## store locks in the seata's server } } recovery { #schedule committing retry period in milliseconds committing-retry-period = 1000 #schedule asyn committing retry period in milliseconds asyn-committing-retry-period = 1000 #schedule rollbacking retry period in milliseconds rollbacking-retry-period = 1000 #schedule timeout retry period in milliseconds timeout-retry-period = 1000 } transaction { undo.data.validation = true undo.log.serialization = "jackson" undo.log.save.days = 7 #schedule delete expired undo_log in milliseconds undo.log.delete.period = 86400000 undo.log.table = "undo_log" } ## metrics settings metrics { enabled = false registry-type = "compact" # multi exporters use comma divided exporter-list = "prometheus" exporter-prometheus-port = 9898 } support { ## spring spring { # auto proxy the DataSource bean datasource.autoproxy = false } }
registry.conf
registry { # file 、nacos 、eureka、redis、zk、consul、etcd3、sofa type = "nacos" nacos { serverAddr = "localhost:8848" namespace = "" cluster = "default" } eureka { serviceUrl = "http://localhost:8761/eureka" application = "default" weight = "1" } redis { serverAddr = "localhost:6379" db = "0" } zk { cluster = "default" serverAddr = "127.0.0.1:2181" session.timeout = 6000 connect.timeout = 2000 } consul { cluster = "default" serverAddr = "127.0.0.1:8500" } etcd3 { cluster = "default" serverAddr = "http://localhost:2379" } sofa { serverAddr = "127.0.0.1:9603" application = "default" region = "DEFAULT_ZONE" datacenter = "DefaultDataCenter" cluster = "default" group = "SEATA_GROUP" addressWaitTime = "3000" } file { name = "file.conf" } } config { # file、nacos 、apollo、zk、consul、etcd3 type = "file" nacos { serverAddr = "localhost" namespace = "" } consul { serverAddr = "127.0.0.1:8500" } apollo { app.id = "seata-server" apollo.meta = "http://192.168.1.204:8801" } zk { serverAddr = "127.0.0.1:2181" session.timeout = 6000 connect.timeout = 2000 } etcd3 { serverAddr = "http://localhost:2379" } file { name = "file.conf" } }
数据源:
package com.lvym.alibaba.config; import com.alibaba.druid.pool.DruidDataSource; import io.seata.rm.datasource.DataSourceProxy; import org.apache.ibatis.session.SqlSessionFactory; import org.mybatis.spring.SqlSessionFactoryBean; import org.mybatis.spring.transaction.SpringManagedTransactionFactory; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.io.support.PathMatchingResourcePatternResolver; import javax.sql.DataSource; @Configuration public class DataSourceProxyConfig { @Value("${mybatis.mapperLocations}") private String mapperLocations; @Bean @ConfigurationProperties(prefix = "spring.datasource") public DataSource druidDataSource(){ return new DruidDataSource(); } @Bean public DataSourceProxy dataSourceProxy(DataSource dataSource) { return new DataSourceProxy(dataSource); } @Bean public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception { SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean(); sqlSessionFactoryBean.setDataSource(dataSourceProxy); sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(mapperLocations)); sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory()); return sqlSessionFactoryBean.getObject(); } }
package com.lvym.alibaba.config; import org.mybatis.spring.annotation.MapperScan; import org.springframework.context.annotation.Configuration; @Configuration @MapperScan({"com.lvym.alibaba.dao"}) public class MyBatisConfig { }
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class) @EnableDiscoveryClient @EnableFeignClients public class AlibabaSeataOrder2001 { public static void main(String[] args) { SpringApplication.run(AlibabaSeataOrder2001.class,args); } }
@Override @GlobalTransactional //如果失败的话,可以在失败方加入本地事务注解 public void create(Order order) { log.info("创建订单"); orderDao.create(order); //扣减库存 log.info("----->订单微服务开始调用库存,做扣减Count"); storageService.decrease(order.getProductId(),order.getCount()); log.info("----->订单微服务开始调用库存,做扣减end"); //扣减账户 log.info("----->订单微服务开始调用账户,做扣减Money"); accountService.decrease(order.getUserId(),order.getMoney()); log.info("----->订单微服务开始调用账户,做扣减end"); //修改订单状态,从零到1代表已经完成 log.info("----->修改订单状态开始"); orderDao.update(order.getUserId(),0); log.info("----->修改订单状态结束"); log.info("----->下订单结束了"); }
SpringCloud Sleuth分布式请求链路追踪
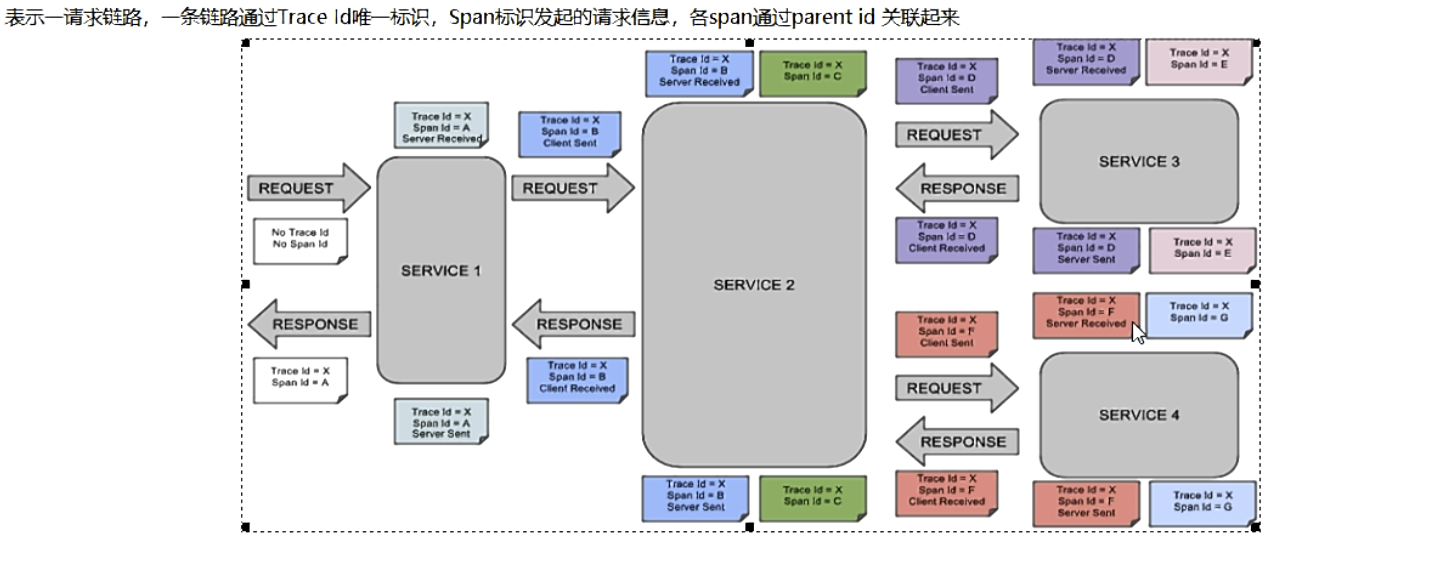
在大型系统的微服务化构建中,一个系统被拆分成了许多模块。这些模块负责不同的功能,组合成系统,最终可以提供丰富的功能。在这种架构中,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心,也就意味着这种架构形式也会存在一些问题:如何快速发现问题?如何判断故障影响范围?如何梳理服务依赖以及依赖的合理性?如何分析链路性能问题以及实时容量规划
分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
常见的链路追踪技术有下面这些:
cat由大众点评开源,基于Java开发的实时应用监控平台,包括实时应用监控,业务监控。集成方案是通过代码埋点的方式来实现监控,比如:拦截器,过滤器等。对代码的侵入性很大,集成成本较高。风险较大。
zipkin由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。该产品结合spring-cloud-sleuth使用较为简单,集成很方便,但是功能较简单。
Pinpoint是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能强大,接入端无代码侵入。
SkyWalking是本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
Sleuth SleuthSpringCloud 提供的分布式系统中链路追踪解决方案。
注意:SpringCloud alibaba技术栈中并没有提供自己的链路追踪技术的,我们可以采用Sleuth +Zinkin来做链路追踪解决方案
Sleuth介绍
SpringCloud Sleuth主要功能就是在分布式系统中提供追踪解决方案。它大量借用了GoogleDapper的设计,先来了解一下Sleuth中的术语和相关概念。
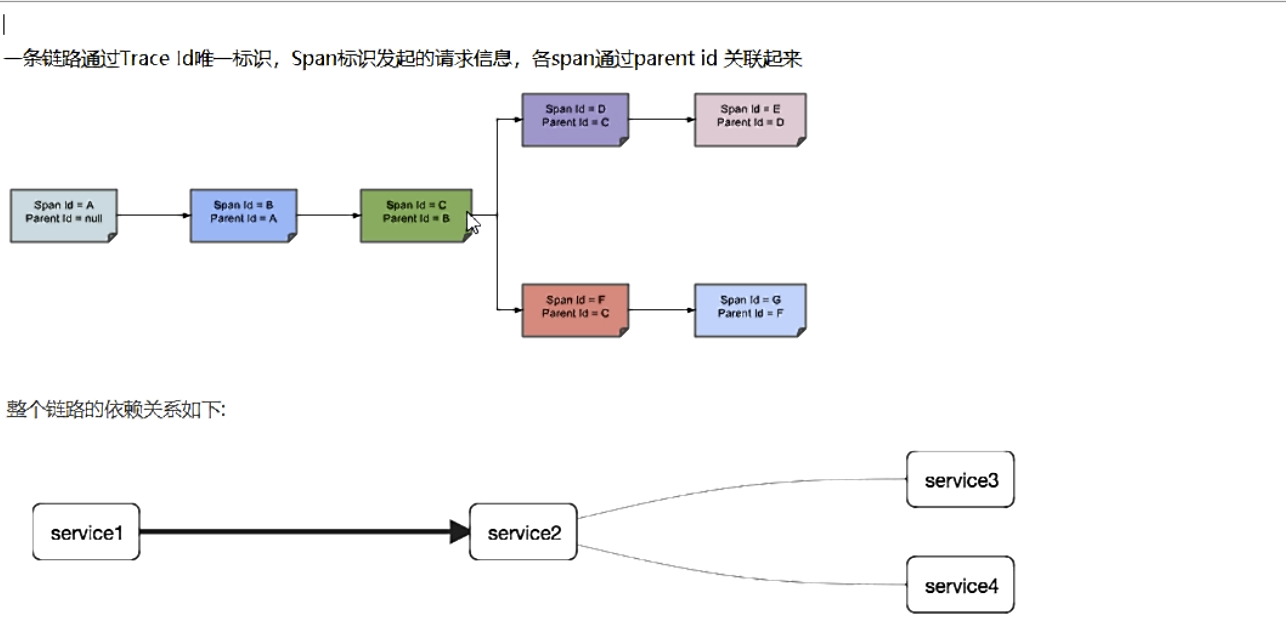
Trace 由一组Trace Id相同的Span串联形成一个树状结构。为了实现请求跟踪,当请求到达分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的标识(即TraceId),同时在分布式系统内部流转的时候,框架始终保持传递该唯一值,直到整个请求的返回。那么我们就可以使用该唯一标识将所有的请求串联起来,形成一条完整的请求链路。
Span 代表了一组基本的工作单元。为了统计各处理单元的延迟,当请求到达各个服务组件的时候,也通过一个唯一标识(SpanId)来标记它的开始、具体过程和结束。通过SpanId的开始和结束时间戳,就能统计该span的调用时间,除此之外,我们还可以获取如事件的名称。请求信息等元数据。
Annotation 用它记录一段时间内的事件,内部使用的重要注释:
cs(Client Send)客户端发出请求,开始一个请求的生命
sr(Server Received)服务端接受到请求开始进行处理, sr-cs = 网络延迟(服务调用的时间)
ss(Server Send)服务端处理完毕准备发送到客户端,ss - sr = 服务器上的请求处理时间
cr(Client Reveived)客户端接受到服务端的响应,请求结束。 cr - sr = 请求的总时间
测试:
<!--链路追踪Sleuth-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
加入依赖启动,之后控制台就会发生变化。
.. INFO [gateway-service,c3a459362b832a82,c3a459362b832a82,false] ..
.. INFO [gateway-service,c3a459362b832a82,c3a459362b832a82,false] ..
.. INFO [member-service,,,] ..
.. INFO [member-service,,,] ..
其中c3a459362b832a82是TraceId,c3a459362b832a82是SpanId,依次调用有一个全局的TraceId,将调用链路串起来。仔细分析每个微服务的日志,不难看出请求的具体过程。
查看日志文件并不是一个很好的方法,当微服务越来越多日志文件也会越来越多,通过Zipkin可以将日志聚合,并进行可视化展示和全文检索。
所以需要zipkin+spring-cloud-sleuth更方便查看。。。
ZipKin介绍
Zipkin 是 Twitter 的一个开源项目,它基于Google Dapper实现,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。
除了面向开发的 API 接口之外,它也提供了方便的UI组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等。
Zipkin 提供了可插拔数据存储方式:In-Memory、MySql、Cassandra 以及 Elasticsearch。
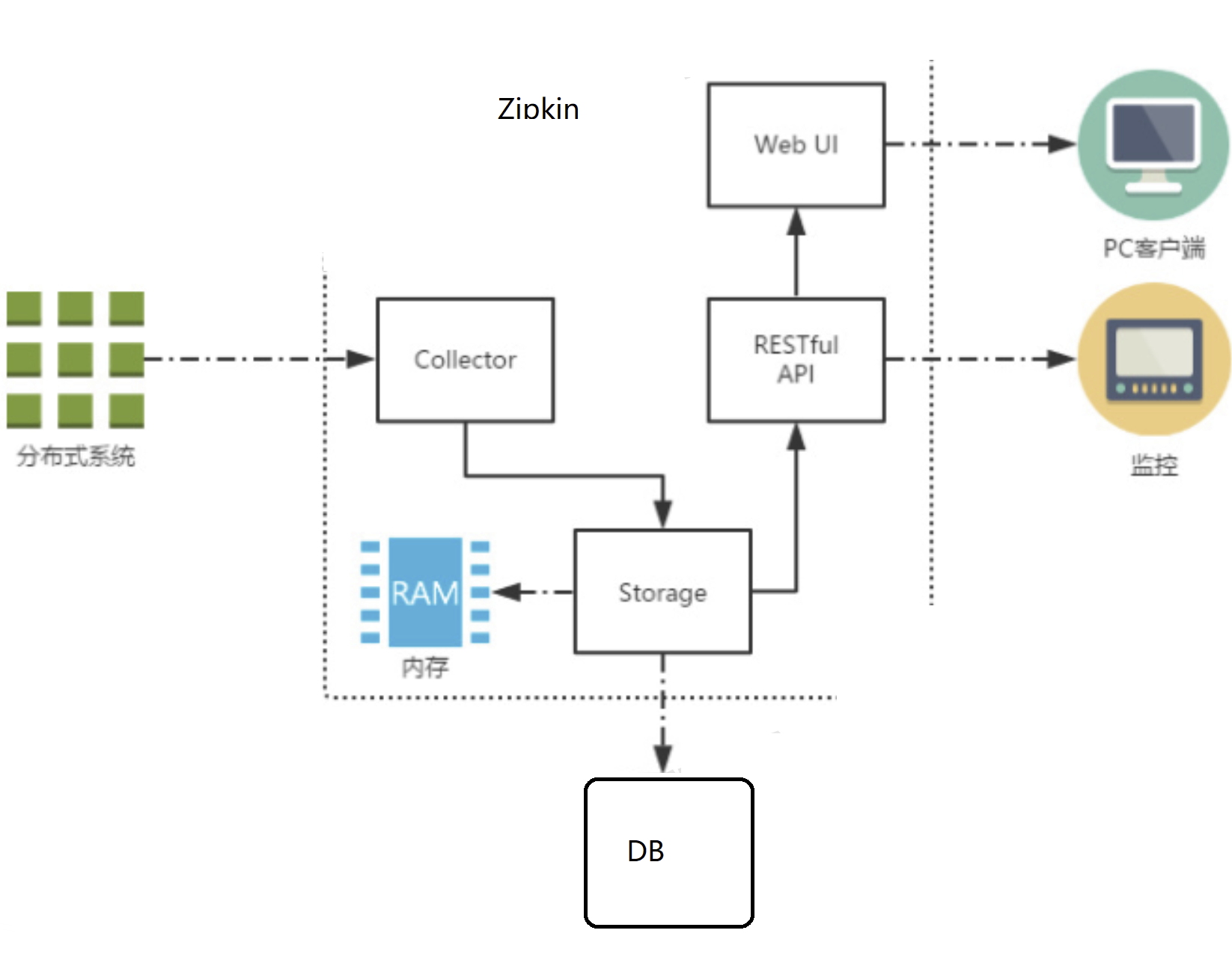
上图展示了 Zipkin 的基础架构,
它主要由 4 个核心组件构成:
Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。RESTful API:API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。
Web UI:UI 组件,基于API组件实现的上层应用。通过UI组件用户可以方便而有直观地查询和分析跟踪信息。
Zipkin分为两端,一个是 Zipkin服务端,一个是 Zipkin客户端,客户端也就是微服务的应用。客户端会配置服务端的 URL 地址,一旦发生服务间的调用的时候,会被配置在微服务里面的 Sleuth 的监听器监听,并生成相应的 Trace 和 Span 信息发送给服务端。
整合Zipkin+Sleuth
下载jar并运行 运行命令: java -jar zipkin-server-2.12.9-exec.jar
客户端:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
yml
spring: zipkin: base-url: http://127.0.0.1:9411/ #zipkin server的请求地址 discoveryClientEnabled: false #让n acos把它当成一个URL,而不要当做服务名 sleuth: sampler: probability: 1.0 #采样的百分比
正常访问
默认Zipkin访问地址:http://localhost:9411/
MySQL持久化:建库建表
CREATE TABLE IF NOT EXISTS zipkin_spans ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL, `id` BIGINT NOT NULL, `name` VARCHAR(255) NOT NULL, `remote_service_name` VARCHAR(255), `parent_id` BIGINT, `debug` BIT(1), `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query', PRIMARY KEY (`trace_id_high`, `trace_id`, `id`) ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds'; ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames'; ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames'; ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range'; CREATE TABLE IF NOT EXISTS zipkin_annotations ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds'; ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames'; ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values'; ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job'; CREATE TABLE IF NOT EXISTS zipkin_dependencies ( `day` DATE NOT NULL, `parent` VARCHAR(255) NOT NULL, `child` VARCHAR(255) NOT NULL, `call_count` BIGINT, `error_count` BIGINT, PRIMARY KEY (`day`, `parent`, `child`) ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
启动Zipkin服务指定MySQL
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root
SpringCloud Stream消息驱动 屏蔽底层消息中间件的差异,降低切换版本,统一消息的编程模型 
Message 生产者/消费者之间靠消息媒介传递信息内容
消息通道MessageChannel 消息必须走特定的通道
消息通道MessageChannel的子接口SubscribableChannel,由MessageHandler消息处理器订阅
stream为什么可以统一底层差异 
Binder 
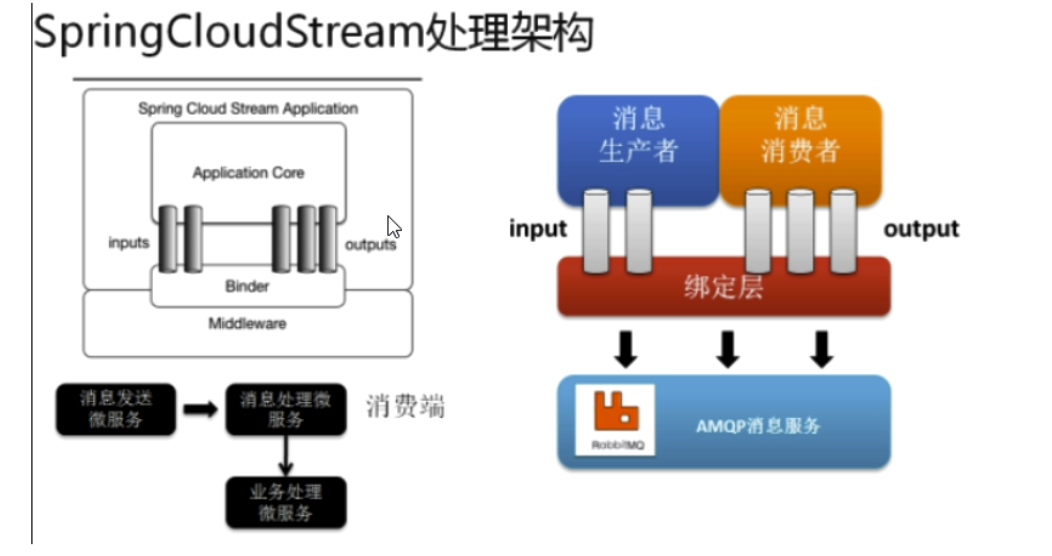

Stream中的消息通信方式遵循了发布-订阅模式
在RabbitMQ就是Exchange
在kafka中就是Topic
Spring Cloud Stream标准流程套路
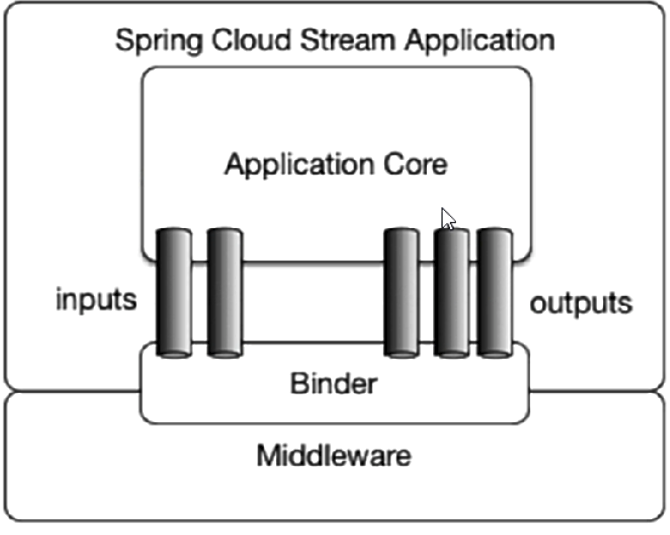
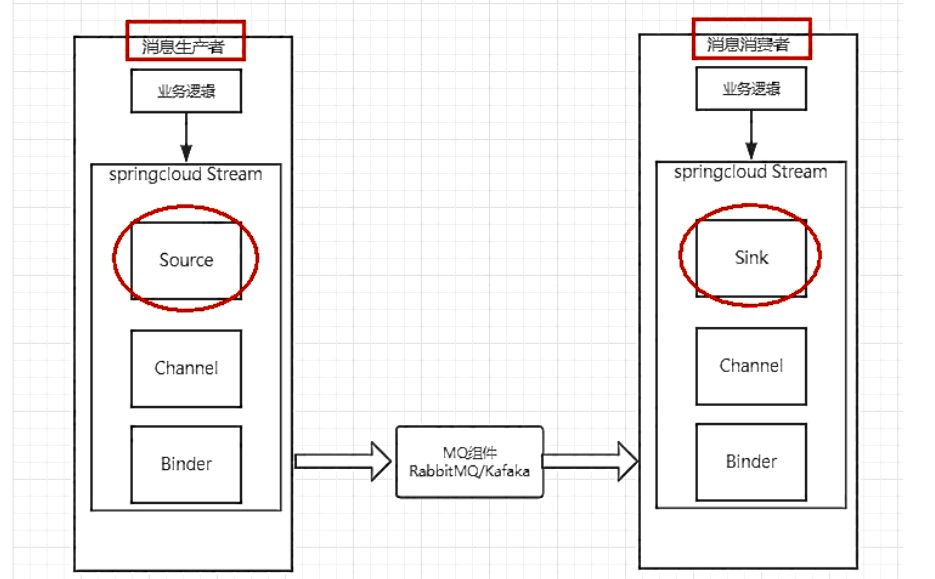

测试:》》》》》》》》》》》》》》》》》
生产者:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
yml
server: port: 8801 spring: application: name: stream-provider cloud: stream: binders: # 在此处配置要绑定的rabbitmq的服务信息; defaultRabbit: # 表示定义的名称,用于于binding整合 type: rabbit # 消息组件类型 environment: # 设置rabbitmq的相关的环境配置 spring: rabbitmq: host: localhost port: 5672 username: guest password: guest bindings: # 服务的整合处理 output: # 这个名字是一个通道的名称 destination: studyExchange # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: defaultRabbit # 设置要绑定的消息服务的具体设置 eureka: client: # 客户端进行Eureka注册的配置,也可用nacos service-url: defaultZone: http://localhost:7001/eureka instance: lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒) lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒) instance-id: send-8801 # 在信息列表时显示主机名称 prefer-ip-address: true # 访问的路径变为IP地址
package com.lvym.springcloud.service; public interface IRabbitmqService { String send(); }
package com.lvym.springcloud.service.impl; import cn.hutool.core.util.IdUtil; import com.lvym.springcloud.service.IRabbitmqService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cloud.stream.annotation.EnableBinding; import org.springframework.cloud.stream.messaging.Source; import org.springframework.integration.support.MessageBuilder; import org.springframework.messaging.MessageChannel; @EnableBinding(Source.class) public class RabbitmqServiceImpl implements IRabbitmqService { @Autowired private MessageChannel output; @Override public String send() { String uuid = IdUtil.simpleUUID(); output.send(MessageBuilder.withPayload(uuid).build()); System.out.println("*****uuid: "+uuid); return null; } }
package com.lvym.springcloud.controller; import com.lvym.springcloud.service.IRabbitmqService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class RabbitmqController { @Autowired private IRabbitmqService iRabbitmqService; @GetMapping(value = "/sendMessage") public String sendMessage(){ return iRabbitmqService.send(); } }
消费者:
yml
server: port: 8802 spring: application: name: stream-consumer cloud: stream: binders: # 在此处配置要绑定的rabbitmq的服务信息; defaultRabbit: # 表示定义的名称,用于于binding整合 type: rabbit # 消息组件类型 environment: # 设置rabbitmq的相关的环境配置 spring: rabbitmq: host: localhost port: 5672 username: guest password: guest bindings: # 服务的整合处理 input: # 这个名字是一个通道的名称 destination: studyExchange # 表示要使用的Exchange名称定义 content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain” binder: defaultRabbit # 设置要绑定的消息服务的具体设置 group: lvymA #微服务应用放置于同一个group中,就能够保证消息只会被其中一个应用消费一次。不同的组是可以消费的,同一个组内会发生竞争关系,只有其中一个可以消费。 与 Spring Cloud Stream 的opinionated 应用模型一致,消费者组订阅是持久的。也就是说, binder 实现确保组订阅是持久的,一旦一个组中创建了一个订阅,就算这个组里边的所有应用都挂掉了,这个组也会受到消息。 #匿名订阅生来就是不持久的。在一些 binder 实现中(例如:RabbitMQ),存在不持久的组订阅是有可能的。 #通常来说,当绑定一个应用到给定的 destination 时,最好是指定一个消费者组。在扩展 Spring Cloud Stream 应用的时候,你必须队每个输入绑定指定你一个消费者组。这将保护应用实例不会接收到重复信息(除非你的确想要这么做)。 eureka: client: # 客户端进行Eureka注册的配置 service-url: defaultZone: http://localhost:7001/eureka instance: lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒) lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒) instance-id: receive-8802 # 在信息列表时显示主机名称 prefer-ip-address: true # 访问的路径变为IP地址
package com.lvym.springcloud.controller; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.stream.annotation.EnableBinding; import org.springframework.cloud.stream.annotation.StreamListener; import org.springframework.cloud.stream.messaging.Sink; import org.springframework.messaging.Message; @EnableBinding(Sink.class) public class ReceiveMessageListenerController { @Value("${server.port}") private String serverPort; @StreamListener(Sink.INPUT) public void input(Message<String> message){ System.out.println("消费者1号,----->接受到的消息: "+message.getPayload()+"\t port: "+serverPort); } }
Rocketmq--消息驱动
MQ(Message Queue)是一种跨进程的通信机制,用于传递消息。通俗点说,就是一个先进先出的数据结构。

场景主要包含以下3个方面
-
应用解耦
系统的耦合性越高,容错性就越低。以电商应用为例,用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障或者因为升级等原因暂时不可用,都会造成下单操作异常,影响用户使用体验。
异步解耦是消息队列 MQ 的主要特点,主要目的是减少请求响应时间和解耦。主要的使用场景就是将比较耗时而且不需要即时(同步)返回结果的操作作为消息放入消息队列。同时,由于使用了消息队列MQ,只要保证消息格式不变,消息的发送方和接收方并不需要彼此联系,也不需要受对方的影响,即解耦合。
使用消息队列解耦合,系统的耦合性就会降低。比如物流系统发生故障,需要几分钟才能来修复,在这段时间内,物流系统要处理的数据被缓存到消息队列中,用户的下单操作正常完成。当物流系统回复后,补充处理存在消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故障。

-
流量削峰
应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮。有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大大提到系统的稳定性和用户体验。
一般情况,为了保证系统的稳定性,如果系统负载超过阈值,就会阻止用户请求,这会影响用户体验,而如果使用消息队列将请求缓存起来,等待系统处理完毕后通知用户下单完毕,这样总不能下单体验要好。
处于经济考量:
业务系统正常时段的QPS如果是1000,流量最高峰是10000,为了应对流量高峰配置高性能的服务器显然不划算,这时可以使用消息队列对峰值流量削峰
-
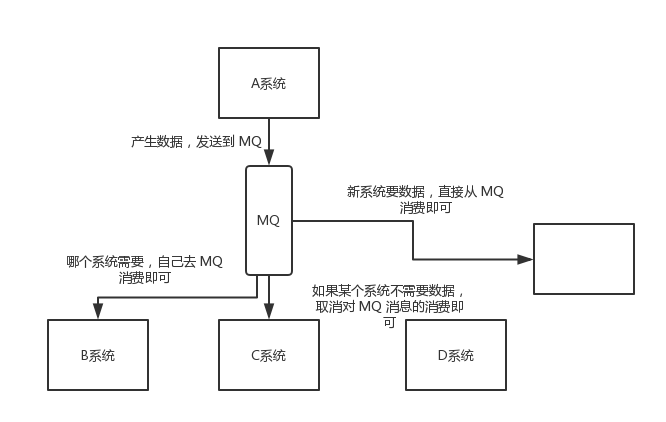
数据分发
通过消息队列可以让数据在多个系统更加之间进行流通。数据的产生方不需要关心谁来使用数据,只需要将数据发送到消息队列,数据使用方直接在消息队列中直接获取数据即可
MQ的优点和缺点
优点:解耦、削峰、数据分发
缺点包含以下几点:
-
系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。
如何保证MQ的高可用?
-
系统复杂度提高
MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。
如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性?
-
一致性问题
如何保证消息数据处理的一致性?
各种MQ产品的比较
常见的MQ产品包括Kafka、ActiveMQ、RabbitMQ、RocketMQ。
安装启动MQ
http://rocketmq.apache.org/release_notes/release-notes-4.4.0/
解压,进入bin
修改runbroker.sh和runserver.sh修改默认JVM大小,修改成适当大小。。。
# JVM Configuration #=========================================================================================== JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m"
# JVM Configuration #=========================================================================================== JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
1.启动NameServer
# 1.启动NameServer nohup sh bin/mqnamesrv & # 2.查看启动日志 tail -f ~/logs/rocketmqlogs/namesrv.log
2.启动Broker
# 1.启动Broker nohup sh bin/mqbroker -n localhost:9876 & # 2.查看启动日志 tail -f ~/logs/rocketmqlogs/broker.log
关闭
# 1.关闭NameServer sh bin/mqshutdown namesrv # 2.关闭Broker sh bin/mqshutdown broker
测试》》》》》》》》》》》》》
spring boot整合
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.0.3</version>
</dependency>
rocketmq: name-server: 192.168.146.200:9876;192.168.146.201:9876 producer: group: group
非spring boot整合
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.4.0</version>
</dependency>
发送消息
消息发送步骤:
1. 创建消息生产者, 指定生产者所属的组名
2. 指定Nameserver地址
3. 启动生产者
4. 创建消息对象,指定主题、标签和消息体
5. 发送消息
6. 关闭生产者
发送同步消息
这种可靠性同步地发送方式使用的比较广泛,比如:重要的消息通知,短信通知。
API 请看:https://github.com/apache/rocketmq/blob/master/docs/cn/RocketMQ_Example.md
spring boot
@Autowired private RocketMQTemplate rocketMQTemplate; @Test public void test(){ Order order = new Order(); order.setId(1); order.setName("helloWorld"); GenericMessage<String> message = new GenericMessage(order); //topic 信息 过期时间ms 延迟级别优先 rocketMQTemplate.syncSend("springboot-mq",message,1000,3); //还有其他的api rocketMQTemplate.syncSend("springboot-mq",1,1000); }
发送异步消息
异步消息通常用在对响应时间敏感的业务场景,即发送端不能容忍长时间地等待Broker的响应。
spring boot
Order order = new Order(); order.setId(1); order.setName("helloWorld"); GenericMessage<String> message = new GenericMessage(order); //topic 信息 过期时间 延迟级别优先ms rocketMQTemplate.asyncSend("springboot-mq", message, new SendCallback() { @Override public void onSuccess(SendResult sendResult) { log.info("接收异步返回结果的回调"+sendResult.getMsgId()); } @Override public void onException(Throwable e) { log.info("发生异常>>>>"+e); e.printStackTrace(); } }, 1000, 3); //不让程序那么快停止 System.in.read();
单向发送消息
Order order = new Order(); order.setId(1); order.setName("helloWorld"); GenericMessage<String> message = new GenericMessage(order); rocketMQTemplate.sendOneWay("springboot-mq", message); rocketMQTemplate.sendOneWay("springboot-mq", 123);
| 发送方式 | 发送 TPS | 发送结果反馈 | 可靠性 |
|---|---|---|---|
| 同步发送 | 快 | 有 | 不丢失 |
| 异步发送 | 快 | 有 | 不丢失 |
| 单向发送 | 最快 | 无 | 可能丢失 |
顺序消息 默认有四个queue
消息有序指的是可以按照消息的发送顺序来消费(FIFO)。RocketMQ可以严格的保证消息有序,可以分为分区有序或者全局有序。
下面用订单进行分区有序的示例。一个订单的顺序流程是:创建、付款、推送、完成。订单号相同的消息会被先后发送到同一个队列中,消费时,同一个OrderId获取到的肯定是同一个队列。
同步异步单向类似
Order order = new Order(); order.setId(1); order.setName("helloWorld"); GenericMessage<String> message = new GenericMessage(order); //topic 信息 标识(同一个标识分在queue) 过期时间 rocketMQTemplate.syncSendOrderly("springboot-mq", message,"shun",1000);
延时消息
现在RocketMq并不支持任意时间的延时,需要设置几个固定的延时等级,从1s到2h分别对应着等级1到18: "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
Order order = new Order(); order.setId(1); order.setName("helloWorld"); GenericMessage<String> message = new GenericMessage(order); //topic 信息 过期时间ms 延迟级别优先(从1开始) rocketMQTemplate.syncSend("springboot-mq",message,1000,3);
convertAndSendOrder order = new Order(); order.setId(1); order.setName("helloWorld"); GenericMessage<String> message = new GenericMessage(order); //同步消息 rocketMQTemplate.convertAndSend("springboot-mq", message); rocketMQTemplate.send("test-topic-1", MessageBuilder.withPayload("Hello, World! I'm from spring message").build());
批量消息
批量发送消息能显著提高传递小消息的性能。限制是这些批量消息应该有相同的topic,相同的waitStoreMsgOK,而且不能是延时消息。此外,这一批消息的总大小不应超过4MB。
就是将消息放入List中
Order order = new Order(); order.setId(1); order.setName("helloWorld"); GenericMessage<String> message = new GenericMessage(order); List<GenericMessage> messages = new ArrayList<>(); messages.add(message); messages.add(message); //批量消息 rocketMQTemplate.convertAndSend("springboot-mq", messages);
以上的消费者差不多:
接收消息
消息接收步骤:
1. 创建消息消费者, 指定消费者所属的组名
2. 指定Nameserver地址
3. 指定消费者订阅的主题和标签
4. 设置回调函数,编写处理消息的方法
5. 启动消息消费者
@RocketMQMessageListener(topic = "springboot-mq",consumerGroup = "group") @Component @Slf4j public class RocketmqListen implements RocketMQListener<MessageExt> { @Override public void onMessage(MessageExt message) { log.info("消费者>>>>>"+new String(message.getBody())); } }
过滤消息
在大多数情况下,TAG是一个简单而有用的设计,其可以来选择您想要的消息。例如:
依赖
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
生产:getProducer下生产,api有的这里也有,像设置延迟级别,额外的值等,但SQL过滤 (selectorType = SelectorType.SQL92,selectorExpression = "")
Message msg = new Message("TopicTest","tag",("Hello RocketMQ ").getBytes());
//延迟级别
// msg.setDelayTimeLevel(3);
// 设置一些属性
msg.putUserProperty("a",String.valueOf(2));
rocketMQTemplate.getProducer().send(msg);
消费:
依赖 2.1.0之前的有bug
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
rocketmq: name-server: 192.168.146.200:9876;192.168.146.201:9876 consumer: group: group1 rocketmqs: selectorExpression: tag
@RocketMQMessageListener(topic = "TopicTest",consumerGroup = "group",selectorExpression = "${rocketmqs.selectorExpression}") @Component @Slf4j //生产什么类型的数据就用什么类型的接收 public class RocketmqListen implements RocketMQListener<MessageExt> { @Override public void onMessage(MessageExt message) { log.info("消费者>>>>>"+new String(message.getBody())); } }
事务消息
RocketMQ提供了事务消息,通过事务消息就能达到分布式事务的最终一致
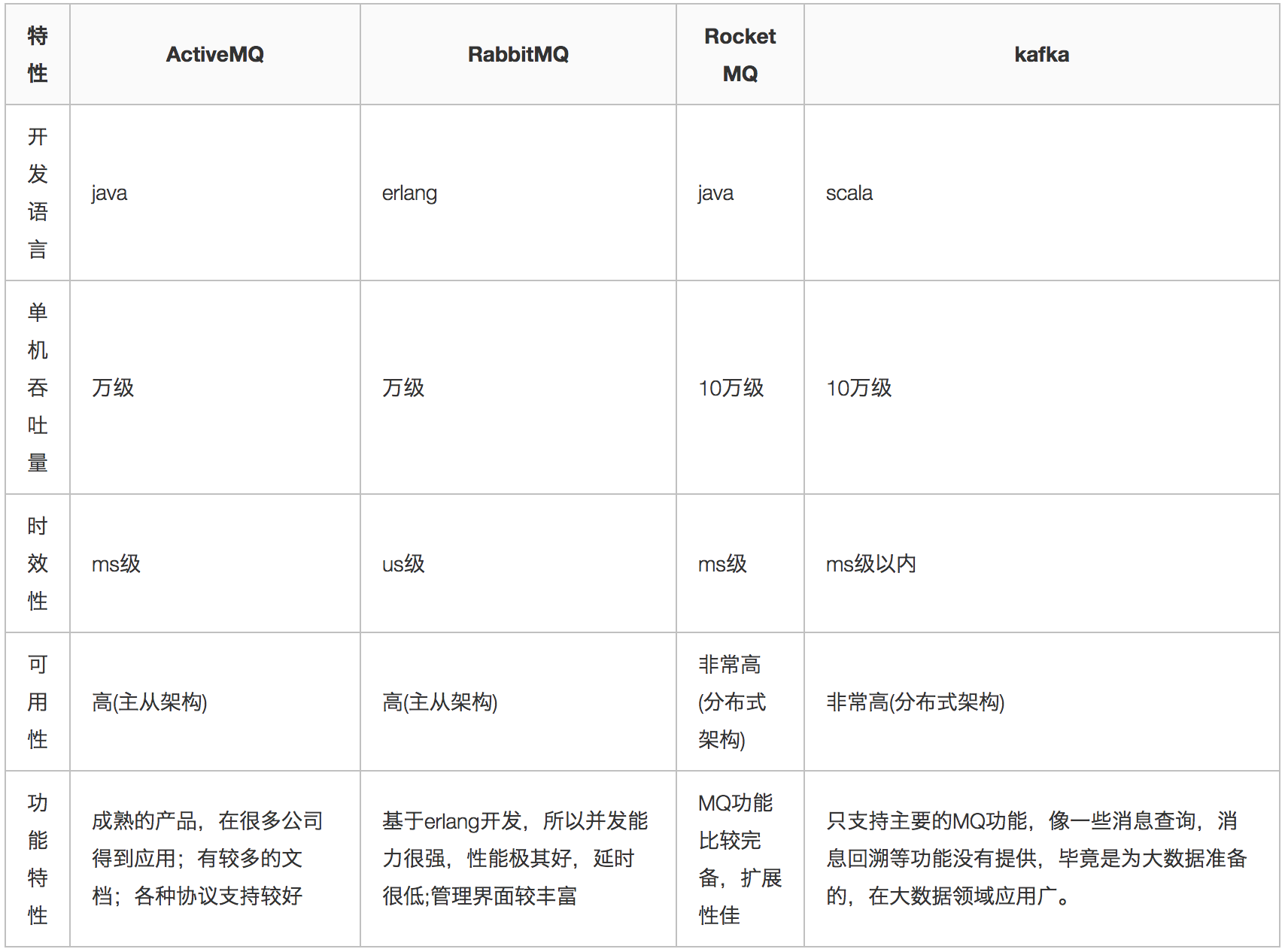
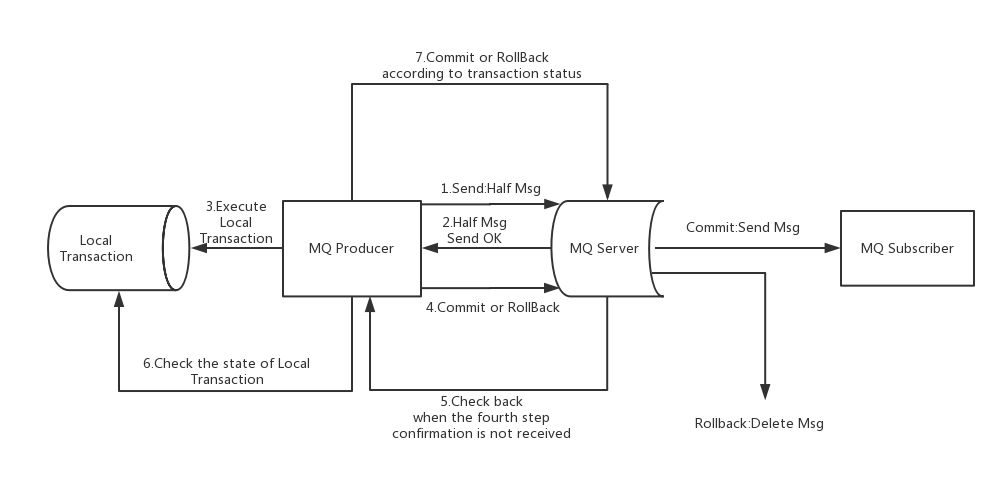
流程分析
上图说明了事务消息的大致方案,其中分为两个流程:正常事务消息的发送及提交、事务消息的补偿流程。
两个概念:
半事务消息:暂不能投递的消息,发送方已经成功地将消息发送到了RocketMQ服务端,但是服务端未收到生产者对该消息的二次确认,此时该消息被标记成“暂不能投递”状态,处于该种状态下的消息即半事务消息。
消息回查:由于网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,RocketMQ服务端通过扫描发现某条消息长期处于“半事务消息”时,需要主动向消息生产者询问该消息的最终状态(Commit 或是 Rollback),该询问过程即消息回查。
事务消息发送步骤:
1. 发送方将半事务消息发送至RocketMQ服务端。
2. RocketMQ服务端将消息持久化之后,向发送方返回Ack确认消息已经发送成功,此时消息为半事务消息。
3. 发送方开始执行本地事务逻辑。
4. 发送方根据本地事务执行结果向服务端提交二次确认(Commit 或是 Rollback),服务端收到Commit 状态则将半事务消息标记为可投递,订阅方最终将收到该消息;服务端收到 Rollback 状态则删除半事务消息,订阅方将不会接受该消息。事务消息回查步骤:
1. 在断网或者是应用重启的特殊情况下,上述步骤4提交的二次确认最终未到达服务端,经过固定时间后服务端将对该消息发起消息回查。
2. 发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
3. 发送方根据检查得到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤
4对半事务消息进行操作。
1)事务消息发送及提交
(1) 发送消息(half消息)。
(3) 根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行)。
(4) 根据本地事务状态执行Commit或者Rollback(Commit操作生成消息索引,消息对消费者可见)
2)事务补偿
(5) 对没有Commit/Rollback的事务消息(pending状态的消息),从服务端发起一次“回查”
(6) Producer收到回查消息,检查回查消息对应的本地事务的状态
(7) 根据本地事务状态,重新Commit或者Rollback
其中,补偿阶段用于解决消息Commit或者Rollback发生超时或者失败的情况。
3)事务消息状态
事务消息共有三种状态,提交状态、回滚状态、中间状态:
-
TransactionStatus.CommitTransaction: 提交事务,它允许消费者消费此消息。
-
TransactionStatus.RollbackTransaction: 回滚事务,它代表该消息将被删除,不允许被消费。
-
TransactionStatus.Unknown: 中间状态,它代表需要检查消息队列来确定状态。
4.6.1 发送事务消息
依赖还是以2.0.3,2.1.0有不同,但差别不大
Order order = new Order(); order.setId(1); order.setName("helloWorld"); GenericMessage<String> message = new GenericMessage(order); String txId = UUID.randomUUID().toString(); //1.发送半事务消息 发送唯一标识,防止幂等性,回查根据txId查 rocketMQTemplate.sendMessageInTransaction("tx_producer_group","tx_topic",MessageBuilder.withPayload(order).setHeader("txId", txId).build(),order);
import com.lvym.rocketmq.entity.TxLog; import org.apache.rocketmq.spring.annotation.RocketMQTransactionListener; import org.apache.rocketmq.spring.core.RocketMQLocalTransactionListener; import org.apache.rocketmq.spring.core.RocketMQLocalTransactionState; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.messaging.Message; import org.springframework.stereotype.Service; @Service @RocketMQTransactionListener(txProducerGroup = "tx_producer_group") public class OrderServiceImpl4Listener implements RocketMQLocalTransactionListener { @Autowired private OrderServiceImpl4 orderServiceImpl4; @Autowired private TxLogDao txLogDao; //执行本地事物 @Override public RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) { String txId = (String) msg.getHeaders().get("txId"); try { //3.本地事物 第二步不可见 Order order = (Order) arg; orderServiceImpl4.createOrder(txId,order); //4. return RocketMQLocalTransactionState.COMMIT; } catch (Exception e) {
//4. return RocketMQLocalTransactionState.ROLLBACK; } } //5.消息回查 @Override public RocketMQLocalTransactionState checkLocalTransaction(Message msg) { String txId = (String) msg.getHeaders().get("txId"); //6.
TxLog txLog = txLogDao.findById(txId).get(); if (txLog != null){ //本地事物(订单)成功了 7. return RocketMQLocalTransactionState.COMMIT; }else {
//7. return RocketMQLocalTransactionState.ROLLBACK; } } }
//3.本地事物 @Transactional public void createOrder(String txId, Order order) { //本地事物代码 //保存订单 orderDao.save(order); //记录日志到数据库,回查使用 TxLog txLog = new TxLog(); txLog.setTxId(txId); txLog.setDate(new Date()); //记录事物日志 txLogDao.save(txLog); }
使用限制
-
事务消息不支持延时消息和批量消息。
-
为了避免单个消息被检查太多次而导致半队列消息累积,我们默认将单个消息的检查次数限制为 15 次,但是用户可以通过 Broker 配置文件的
-
事务消息将在 Broker 配置文件中的参数 transactionMsgTimeout 这样的特定时间长度之后被检查。当发送事务消息时,用户还可以通过设置用户属性 CHECK_IMMUNITY_TIME_IN_SECONDS 来改变这个限制,该参数优先于
transactionMsgTimeout参数。 -
事务性消息可能不止一次被检查或消费。
-
提交给用户的目标主题消息可能会失败,目前这依日志的记录而定。它的高可用性通过 RocketMQ 本身的高可用性机制来保证,如果希望确保事务消息不丢失、并且事务完整性得到保证,建议使用同步的双重写入机制。
-
事务消息的生产者 ID 不能与其他类型消息的生产者 ID 共享。与其他类型的消息不同,事务消息允许反向查询、MQ服务器能通过它们的生产者 ID 查询到消费者。
消息存储
分布式队列因为有高可靠性的要求,所以数据要进行持久化存储。
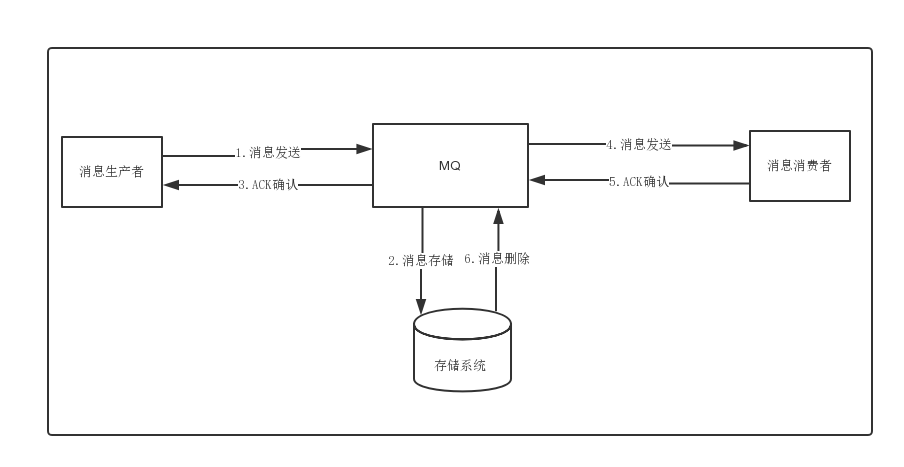
-
-
MQ收到消息,将消息进行持久化,在存储中新增一条记录
-
返回ACK给生产者
-
MQ push 消息给对应的消费者,然后等待消费者返回ACK
-
如果消息消费者在指定时间内成功返回ack,那么MQ认为消息消费成功,在存储中删除消息,即执行第6步;如果MQ在指定时间内没有收到ACK,则认为消息消费失败,会尝试重新push消息,重复执行4、5、6步骤
-
-
关系型数据库DB
Apache下开源的另外一款MQ—ActiveMQ(默认采用的KahaDB做消息存储)可选用JDBC的方式来做消息持久化,通过简单的xml配置信息即可实现JDBC消息存储。由于,普通关系型数据库(如Mysql)在单表数据量达到千万级别的情况下,其IO读写性能往往会出现瓶颈。在可靠性方面,该种方案非常依赖DB,如果一旦DB出现故障,则MQ的消息就无法落盘存储会导致线上故障。
-
文件系统
目前业界较为常用的几款产品(RocketMQ/Kafka/RabbitMQ)均采用的是消息刷盘至所部署虚拟机/物理机的文件系统来做持久化(刷盘一般可以分为异步刷盘和同步刷盘两种模式)。消息刷盘为消息存储提供了一种高效率、高可靠性和高性能的数据持久化方式。除非部署MQ机器本身或是本地磁盘挂了,否则一般是不会出现无法持久化的故障问题。
性能对比 :文件系统>关系型数据库DB
消息的存储和发送
1)消息存储
磁盘如果使用得当,磁盘的速度完全可以匹配上网络 的数据传输速度。目前的高性能磁盘,顺序写速度可以达到600MB/s, 超过了一般网卡的传输速度。但是磁盘随机写的速度只有大概100KB/s,和顺序写的性能相差6000倍!因为有如此巨大的速度差别,好的消息队列系统会比普通的消息队列系统速度快多个数量级。RocketMQ的消息用顺序写,保证了消息存储的速度。
Linux操作系统分为【用户态】和【内核态】,文件操作、网络操作需要涉及这两种形态的切换,免不了进行数据复制。
一台服务器 把本机磁盘文件的内容发送到客户端,一般分为两个步骤:
1)read;读取本地文件内容;
2)write;将读取的内容通过网络发送出去。
这两个看似简单的操作,实际进行了4 次数据复制,分别是:
-
从磁盘复制数据到内核态内存;
-
从内核态内存复 制到用户态内存;
-
然后从用户态 内存复制到网络驱动的内核态内存;
-
最后是从网络驱动的内核态内存复 制到网卡中进行传输。

RocketMQ充分利用了上述特性,也就是所谓的“零拷贝”技术,提高消息存盘和网络发送的速度。
这里需要注意的是,采用MappedByteBuffer这种内存映射的方式有几个限制,其中之一是一次只能映射1.5~2G 的文件至用户态的虚拟内存,这也是为何RocketMQ默认设置单个CommitLog日志数据文件为1G的原因了
消息存储结构

-
-
ConsumerQueue:存储消息在CommitLog的索引
-
刷盘机制
RocketMQ的消息是存储到磁盘上的,这样既能保证断电后恢复, 又可以让存储的消息量超出内存的限制。RocketMQ为了提高性能,会尽可能地保证磁盘的顺序写。消息在通过Producer写入RocketMQ的时 候,有两种写磁盘方式,分布式同步刷盘和异步刷盘。
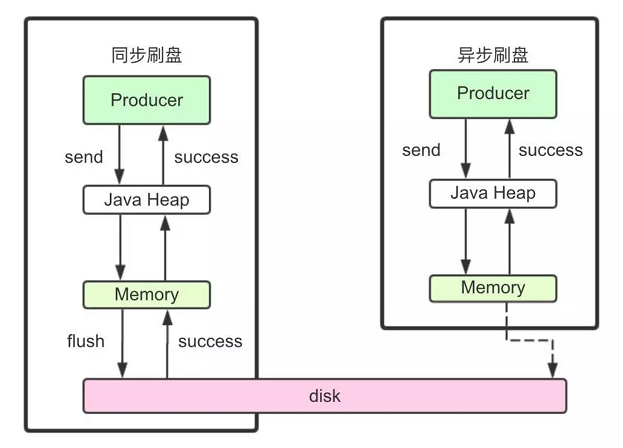
同步刷盘
2)异步刷盘
在返回写成功状态时,消息可能只是被写入了内存的PAGECACHE,写操作的返回快,吞吐量大;当内存里的消息量积累到一定程度时,统一触发写磁盘动作,快速写入。但可能会有丢失数据的风险
配置
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=SYNC_FLUSH
RocketMQ分布式集群是通过Master和Slave的配合达到高可用性的。
Master和Slave的区别:在Broker的配置文件中,参数 brokerId的值为0表明这个Broker是Master,大于0表明这个Broker是 Slave,同时brokerRole参数也会说明这个Broker是Master还是Slave。
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SLAVE
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SYNC_MASTER
Master角色的Broker支持读和写,Slave角色的Broker仅支持读,也就是 Producer只能和Master角色的Broker连接写入消息;Consumer可以连接 Master角色的Broker,也可以连接Slave角色的Broker来读取消息。
消息消费高可用
在Consumer的配置文件中,并不需要设置是从Master读还是从Slave 读,当Master不可用或者繁忙的时候,Consumer会被自动切换到从Slave 读。有了自动切换Consumer这种机制,当一个Master角色的机器出现故障后,Consumer仍然可以从Slave读取消息,不影响Consumer程序。这就达到了消费端的高可用性。
消息发送高可用

消息主从复制
如果一个Broker组有Master和Slave,消息需要从Master复制到Slave 上,有同步和异步两种复制方式。
1)同步复制
同步复制方式是等Master和Slave均写 成功后才反馈给客户端写成功状态;
在同步复制方式下,如果Master出故障, Slave上有全部的备份数据,容易恢复,但是同步复制会增大数据写入 延迟,降低系统吞吐量。
2)异步复制
异步复制方式是只要Master写成功 即可反馈给客户端写成功状态。
在异步复制方式下,系统拥有较低的延迟和较高的吞吐量,但是如果Master出了故障,有些数据因为没有被写 入Slave,有可能会丢失;
3)配置
同步复制和异步复制是通过Broker配置文件里的brokerRole参数进行设置的,这个参数可以被设置成ASYNC_MASTER、 SYNC_MASTER、SLAVE三个值中的一个。
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SYNC_MASTER
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SLAVE
实际应用中要结合业务场景,合理设置刷盘方式和主从复制方式, 尤其是SYNC_FLUSH方式,由于频繁地触发磁盘写动作,会明显降低 性能。通常情况下,应该把Master和Save配置成ASYNC_FLUSH的刷盘 方式,主从之间配置成SYNC_MASTER的复制方式,这样即使有一台 机器出故障,仍然能保证数据不丢,是个不错的选择。
RocketMQ集群搭建
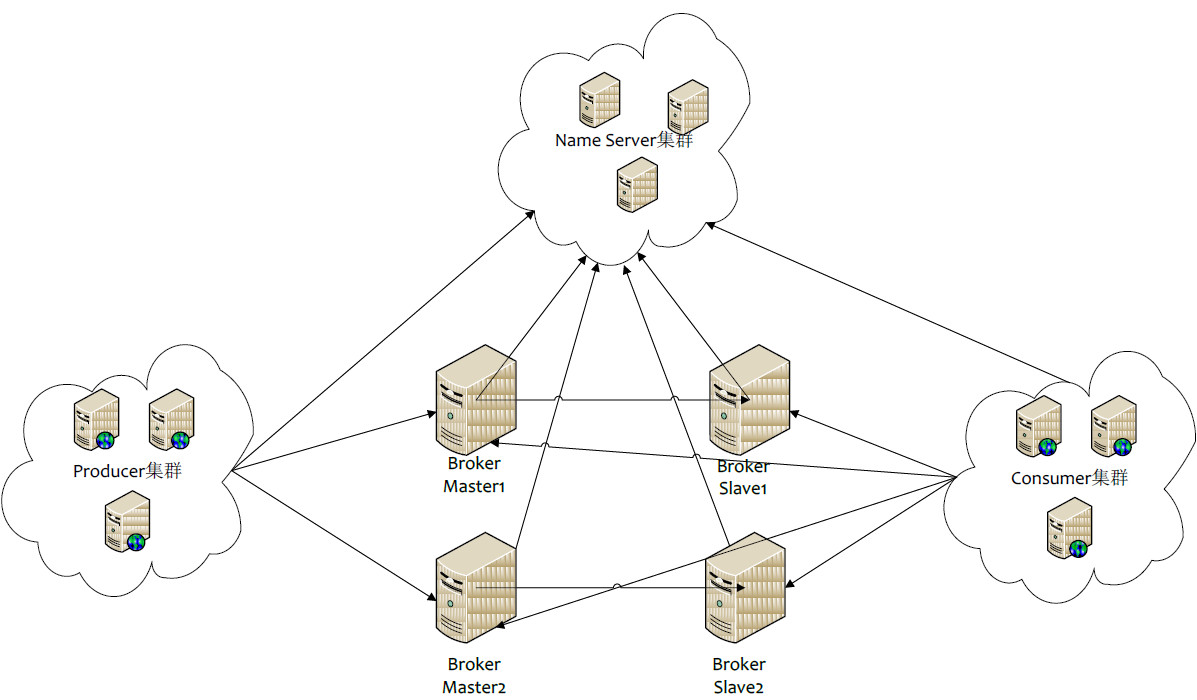
各角色介绍
-
Producer:消息的发送者;举例:发信者
-
Consumer:消息接收者;举例:收信者
-
Broker:暂存和传输消息;举例:邮局
-
NameServer:管理Broker;举例:各个邮局的管理机构
-
Topic:区分消息的种类;一个发送者可以发送消息给一个或者多个Topic;一个消息的接收者可以订阅一个或者多个Topic消息
-
Message Queue:相当于是Topic的分区;用于并行发送和接收消息
集群特点
-
NameServer是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
-
Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有NameServer。
-
Producer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
-
Consumer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
集群模式
1)单Master模式
这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用。不建议线上环境使用,可以用于本地测试。
2)多Master模式
一个集群无Slave,全是Master,例如2个Master或者3个Master,这种模式的优缺点如下:
-
优点:配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
-
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
3)多Master多Slave模式(异步)
每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级),这种模式的优缺点如下:
-
优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
-
缺点:Master宕机,磁盘损坏情况下会丢失少量消息。
4)多Master多Slave模式(同步)
每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式的优缺点如下:
-
优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
-
缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。
双主双从集群搭建---同步,两台机器,主1和从2在同一台机器(200),主2和从1在同一台机器(201)
环境:java8起步,关闭防火墙或开放端口 (RocketMQ默认使用3个端口:9876 、10911 、11011 )* `nameserver` 默认使用 9876 端口* `master` 默认使用 10911 端口* `slave` 默认使用11011 端口
1.修改hosts文件(可选)
# nameserver
192.168.146.200 rocketmq-nameserver1
192.168.146.201 rocketmq-nameserver2
# broker
192.168.146.200 rocketmq-master1
192.168.146.200 rocketmq-slave2
192.168.146.201 rocketmq-master2
192.168.146.201 rocketmq-slave1
配置完成后, 重启网卡 systemctl restart network
2. 环境变量配置(可选),方便在任何地方都能输入命令
vim /etc/profile
在profile文件的末尾加入如下命令
#set rocketmq
ROCKETMQ_HOME=/usr/local/rocketmq/rocketmq-all-4.4.0-bin-release
PATH=$PATH:$ROCKETMQ_HOME/bin
export ROCKETMQ_HOME PATH
使得配置立刻生效:source /etc/profile
3.创建消息存储路径
mkdir /usr/local/rocketmq/store
mkdir /usr/local/rocketmq/store/commitlog
mkdir /usr/local/rocketmq/store/consumequeue
mkdir /usr/local/rocketmq/store/index
mkdir /usr/local/rocketmq/store2
mkdir /usr/local/rocketmq/store2/commitlog
mkdir /usr/local/rocketmq/store2/consumequeue
mkdir /usr/local/rocketmq/store2/index
4.broker配置文件
Master1(200)
vim /usr/local/rocketmq/rocketmq-all-4.4.0-bin-release/conf/2m-2s-sync/broker-a.properties
| brokerIP1 | 网卡的 InetAddress | 当前 broker 监听的 IP |
| brokerIP2 | 跟 brokerIP1 一样 | 存在主从 broker 时,如果在 broker 主节点上配置了 brokerIP2 属性,broker 从节点会连接主节点配置的 brokerIP2 进行同步 |
#所属集群名字
brokerClusterName=rocketmq-cluster
#broker名字,注意此处不同的配置文件填写的不一样
brokerName=broker-a
#0 表示 Master,>0 表示 Slave
brokerId=0
#当前 broker 监听的 IP
brokerIP1=192.168.146.200
brokerIP2=192.168.146.201
#nameServer地址,分号分割
namesrvAddr=rocketmq-nameserver1:9876;rocketmq-nameserver2:9876
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#Broker 对外服务的监听端口
listenPort=10911
#删除文件时间点,默认凌晨 4点
deleteWhen=04
#文件保留时间,默认 48 小时
fileReservedTime=120
#commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=1073741824
#ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间
diskMaxUsedSpaceRatio=88
#存储路径
storePathRootDir=/usr/local/rocketmq/store
#commitLog 存储路径
storePathCommitLog=/usr/local/rocketmq/store/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/usr/local/rocketmq/store/consumequeue
#消息索引存储路径
storePathIndex=/usr/local/rocketmq/store/index
#checkpoint 文件存储路径
storeCheckpoint=/usr/local/rocketmq/store/checkpoint
#abort 文件存储路径
abortFile=/usr/local/rocketmq/store/abort
#限制的消息大小
maxMessageSize=65536
#flushCommitLogLeastPages=4
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SYNC_MASTER
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=SYNC_FLUSH
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
Slave2 broker-b-s.properties (200)
# limitations under the License.
#所属集群名字
brokerClusterName=rocketmq-cluster
#broker名字,注意此处不同的配置文件填写的不一样
brokerName=broker-b
#0 表示 Master,>0 表示 Slave
brokerId=1
#当前 broker 监听的 IP
brokerIP2=192.168.146.201
#nameServer地址,分号分割
namesrvAddr=rocketmq-nameserver1:9876;rocketmq-nameserver2:9876
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#Broker 对外服务的监听端口
listenPort=11011
#删除文件时间点,默认凌晨 4点
deleteWhen=04
#文件保留时间,默认 48 小时
fileReservedTime=120
#commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=1073741824
#ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间
diskMaxUsedSpaceRatio=88
#存储路径
storePathRootDir=/usr/local/rocketmq/store2
#commitLog 存储路径
storePathCommitLog=/usr/local/rocketmq/store2/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/usr/local/rocketmq/store2/consumequeue
#消息索引存储路径
storePathIndex=/usr/local/rocketmq/store2/index
#checkpoint 文件存储路径
storeCheckpoint=/usr/local/rocketmq/store2/checkpoint
#abort 文件存储路径
abortFile=/usr/local/rocketmq/store2/abort
#限制的消息大小
maxMessageSize=65536
#flushCommitLogLeastPages=4
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SLAVE
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=ASYNC_FLUSH
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
Master2(201)broker-b.properties
#所属集群名字
brokerClusterName=rocketmq-cluster
#broker名字,注意此处不同的配置文件填写的不一样
brokerName=broker-b
#0 表示 Master,>0 表示 Slave
brokerId=0
#当前 broker 监听的 IP
brokerIP1=192.168.146.201
brokerIP2=192.168.146.200
#nameServer地址,分号分割
namesrvAddr=rocketmq-nameserver1:9876;rocketmq-nameserver2:9876
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#Broker 对外服务的监听端口
listenPort=10911
#删除文件时间点,默认凌晨 4点
deleteWhen=04
#文件保留时间,默认 48 小时
fileReservedTime=120
#commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=1073741824
#ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间
diskMaxUsedSpaceRatio=88
#存储路径
storePathRootDir=/usr/local/rocketmq/store
#commitLog 存储路径
storePathCommitLog=/usr/local/rocketmq/store/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/usr/local/rocketmq/store/consumequeue
#消息索引存储路径
storePathIndex=/usr/local/rocketmq/store/index
#checkpoint 文件存储路径
storeCheckpoint=/usr/local/rocketmq/store/checkpoint
#abort 文件存储路径
abortFile=/usr/local/rocketmq/store/abort
#限制的消息大小
maxMessageSize=65536
#flushCommitLogLeastPages=4
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SYNC_MASTER
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=SYNC_FLUSH
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
Slave1(201)broker-a-s.properties
#所属集群名字
brokerClusterName=rocketmq-cluster
#broker名字,注意此处不同的配置文件填写的不一样
brokerName=broker-a
#0 表示 Master,>0 表示 Slave
brokerId=1
#当前 broker 监听的 IP
brokerIP1=192.168.146.200
#nameServer地址,分号分割
namesrvAddr=rocketmq-nameserver1:9876;rocketmq-nameserver2:9876
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
#Broker 对外服务的监听端口
listenPort=11011
#删除文件时间点,默认凌晨 4点
deleteWhen=04
#文件保留时间,默认 48 小时
fileReservedTime=120
#commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=1073741824
#ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间
diskMaxUsedSpaceRatio=88
#存储路径
storePathRootDir=/usr/local/rocketmq/store2
#commitLog 存储路径
storePathCommitLog=/usr/local/rocketmq/store2/commitlog
#消费队列存储路径存储路径
storePathConsumeQueue=/usr/local/rocketmq/store2/consumequeue
#消息索引存储路径
storePathIndex=/usr/local/rocketmq/store2/index
#checkpoint 文件存储路径
storeCheckpoint=/usr/local/rocketmq/store2/checkpoint
#abort 文件存储路径
abortFile=/usr/local/rocketmq/store2/abort
#限制的消息大小
maxMessageSize=65536
#flushCommitLogLeastPages=4
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE
brokerRole=SLAVE
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘
flushDiskType=ASYNC_FLUSH
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
5.修改启动脚本文件
runbroker.sh
vim /usr/local/rocketmq/rocketmq-all-4.4.0-bin-release/bin/runbroker.sh
需要根据内存大小进行适当的对JVM参数进行调整:
# JVM Configuration
#===========================================================================================
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m"
runserver.sh
vim /usr/local/rocketmq/rocketmq-all-4.4.0-bin-release/bin/runserver.sh
# JVM Configuration
#===========================================================================================
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
6.服务启动 启动过程中最好不要出错,
先启动NameServe集群
nohup sh mqnamesrv &
启动Broker集群
nohup sh mqbroker -c /usr/local/rocketmq/rocketmq-all-4.4.0-bin-release/conf/2m-2s-sync/broker-a.properties &
nohup sh mqbroker -c /usr/local/rocketmq/rocketmq-all-4.4.0-bin-release/conf/2m-2s-sync/broker-b-s.properties &
201
nohup sh mqbroker -c /usr/local/rocketmq/rocketmq-all-4.4.0-bin-release/conf/2m-2s-sync/broker-b.properties &
nohup sh mqbroker -c /usr/local/rocketmq/rocketmq-all-4.4.0-bin-release/conf/2m-2s-sync/broker-a-s.properties &
启动后通过JPS查看启动进程
[root@rocketmqM bin]# jps
2917 NamesrvStartup
2949 BrokerStartup
3046 BrokerStartup
3126 Jps
[root@rocketmq bin]# jps
2866 NamesrvStartup
3011 BrokerStartup
3348 Jps
2927 BrokerStartup
负载均衡
Producer负载均衡
Producer端,每个实例在发消息的时候,默认会轮询所有的message queue发送,以达到让消息平均落在不同的queue上。而由于queue可以散落在不同的broker,所以消息就发送到不同的broker下,如下图
Consumer负载均衡
1)集群模式
在集群消费模式下,每条消息只需要投递到订阅这个topic的Consumer Group下的一个实例即可。RocketMQ采用主动拉取的方式拉取并消费消息,在拉取的时候需要明确指定拉取哪一条message queue。
而每当实例的数量有变更,都会触发一次所有实例的负载均衡,这时候会按照queue的数量和实例的数量平均分配queue给每个实例。
默认的分配算法是AllocateMessageQueueAveragely

另外一种平均的算法是AllocateMessageQueueAveragelyByCircle,也是平均分摊每一条queue,只是以环状轮流分queue的形式,
需要注意的是,集群模式下,queue都是只允许分配只一个实例,这是由于如果多个实例同时消费一个queue的消息,由于拉取哪些消息是consumer主动控制的,那样会导致同一个消息在不同的实例下被消费多次,所以算法上都是一个queue只分给一个consumer实例,一个consumer实例可以允许同时分到不同的queue。
通过增加consumer实例去分摊queue的消费,可以起到水平扩展的消费能力的作用。而有实例下线的时候,会重新触发负载均衡,这时候原来分配到的queue将分配到其他实例上继续消费。
但是如果consumer实例的数量比message queue的总数量还多的话,多出来的consumer实例将无法分到queue,也就无法消费到消息,也就无法起到分摊负载的作用了。所以需要控制让queue的总数量大于等于consumer的数量。
广播模式
由于广播模式下要求一条消息需要投递到一个消费组下面所有的消费者实例,所以也就没有消息被分摊消费的说法。
在实现上,其中一个不同就是在consumer分配queue的时候,所有consumer都分到所有的queue。
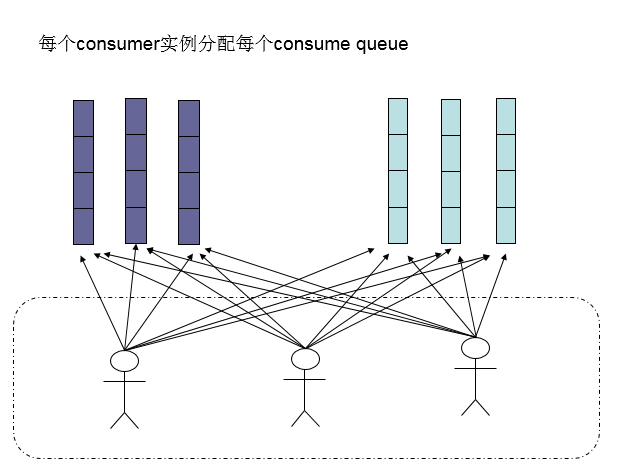
消息消费要注意的细节 @RocketMQMessageListener(consumerGroup = "shop",//消费者分组 topic = "order-topic",//要消费的主题 consumeMode = ConsumeMode.CONCURRENTLY, //消费模式:无序和有序 messageModel = Mess ageModel.CLUSTERING, //消息模式:广播和集群,默认是集群) public class SmsService implements RocketMQListener<Order> {} RocketMQ支持两种消息模式: 广播消费: 每个消费者实例都会收到消息,也就是一条消息可以被每个消费者实例处理; 集群消费: 一条消息只能被一个消费者实例消息
消息重试
1.4.1 顺序消息的重试
对于顺序消息,当消费者消费消息失败后,消息队列 RocketMQ 会自动不断进行消息重试(每次间隔时间为 1 秒),这时,应用会出现消息消费被阻塞的情况。因此,在使用顺序消息时,务必保证应用能够及时监控并处理消费失败的情况,避免阻塞现象的发生。
1.4.2 无序消息的重试
对于无序消息(普通、定时、延时、事务消息),当消费者消费消息失败时,您可以通过设置返回状态达到消息重试的结果。
无序消息的重试只针对集群消费方式生效;广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息。
1)重试次数
消息队列 RocketMQ 默认允许每条消息最多重试 16 次,每次重试的间隔时间如下
| 第几次重试 | 与上次重试的间隔时间 | 第几次重试 | 与上次重试的间隔时间 |
|---|---|---|---|
| 1 | 10 秒 | 9 | 7 分钟 |
| 2 | 30 秒 | 10 | 8 分钟 |
| 3 | 1 分钟 | 11 | 9 分钟 |
| 4 | 2 分钟 | 12 | 10 分钟 |
| 5 | 3 分钟 | 13 | 20 分钟 |
| 6 | 4 分钟 | 14 | 30 分钟 |
| 7 | 5 分钟 | 15 | 1 小时 |
| 8 | 6 分钟 | 16 | 2 小时 |
如果消息重试 16 次后仍然失败,消息将不再投递。如果严格按照上述重试时间间隔计算,某条消息在一直消费失败的前提下,将会在接下来的 4 小时 46 分钟之内进行 16 次重试,超过这个时间范围消息将不再重试投递。
注意: 一条消息无论重试多少次,这些重试消息的 Message ID 不会改变。
集群消费方式下,消息消费失败后期望消息重试,需要在消息监听器接口的实现中明确进行配置(三种方式任选一种):
-
-
返回 Null
-
抛出异常
//方式1:返回 Action.ReconsumeLater,消息将重试
return Action.ReconsumeLater;
//方式2:返回 null,消息将重试
return null;
//方式3:直接抛出异常, 消息将重试
throw new RuntimeException("88888");
消费失败后,不重试配置方式
集群消费方式下,消息失败后期望消息不重试,需要捕获消费逻辑中可能抛出的异常,最终返回 Action.CommitMessage,此后这条消息将不会再重试。
//捕获消费逻辑中的所有异常,并返回 Action.CommitMessage;
return Action.CommitMessage;
自定义消息最大重试次数
消息队列 RocketMQ 允许 Consumer 启动的时候设置最大重试次数,重试时间间隔将按照如下策略:
-
最大重试次数小于等于 16 次,则重试时间间隔同上表描述。
-
最大重试次数大于 16 次,超过 16 次的重试时间间隔均为每次 2 小时。
可以配置原生的API,spring boot好像只有自动重试,或者版本问题。。。。。
-
-
如果只对相同 Group ID 下两个 Consumer 实例中的其中一个设置了 MaxReconsumeTimes,那么该配置对两个 Consumer 实例均生效。
-
死信队列
在消息队列 RocketMQ 中,这种正常情况下无法被消费的消息称为死信消息(Dead-Letter Message),存储死信消息的特殊队列称为死信队列(Dead-Letter Queue)。
死信特性
死信消息具有以下特性
-
不会再被消费者正常消费。
-
有效期与正常消息相同,均为 3 天,3 天后会被自动删除。因此,请在死信消息产生后的 3 天内及时处理。
死信队列具有以下特性:
-
一个死信队列对应一个 Group ID, 而不是对应单个消费者实例。
-
如果一个 Group ID 未产生死信消息,消息队列 RocketMQ 不会为其创建相应的死信队列。
-
一个死信队列包含了对应 Group ID 产生的所有死信消息,不论该消息属于哪个 Topic。
一条消息进入死信队列,意味着某些因素导致消费者无法正常消费该消息,因此,通常需要您对其进行特殊处理。排查可疑因素并解决问题后,可以在消息队列 RocketMQ 控制台重新发送该消息,让消费者重新消费一次。
消费幂等
消息队列 RocketMQ 消费者在接收到消息以后,有必要根据业务上的唯一 Key 对消息做幂等处理的必要性。
消费幂等的必要性
在互联网应用中,尤其在网络不稳定的情况下,消息队列 RocketMQ 的消息有可能会出现重复,这个重复简单可以概括为以下情况:
-
发送时消息重复
当一条消息已被成功发送到服务端并完成持久化,此时出现了网络闪断或者客户端宕机,导致服务端对客户端应答失败。 如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
-
投递时消息重复
消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。 为了保证消息至少被消费一次,消息队列 RocketMQ 的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
-
负载均衡时消息重复(包括但不限于网络抖动、Broker 重启以及订阅方应用重启)
当消息队列 RocketMQ 的 Broker 或客户端重启、扩容或缩容时,会触发 Rebalance,此时消费者可能会收到重复消息。
处理方式
因为 Message ID 有可能出现冲突(重复)的情况,所以真正安全的幂等处理,不建议以 Message ID 作为处理依据。 最好的方式是以业务唯一标识作为幂等处理的关键依据,而业务的唯一标识可以通过消息 Key 进行设置:
Message message = new Message("springboot-mq","hello".getBytes()); message.setKeys("uuid1");唯一就好 rocketMQTemplate.getProducer().send(message);
消费:
String key = message.getKeys() // 根据业务唯一标识的 key 做幂等处理
消息轨迹
1. 消息轨迹数据关键属性
| Producer端 | Consumer端 | Broker端 |
|---|---|---|
| 生产实例信息 | 消费实例信息 | 消息的Topic |
| 发送消息时间 | 投递时间,投递轮次 | 消息存储位置 |
| 消息是否发送成功 | 消息是否消费成功 | 消息的Key值 |
| 发送耗时 | 消费耗时 | 消息的Tag值 |
2. 支持消息轨迹集群部署
2.1 Broker端配置文件
这里贴出Broker端开启消息轨迹特性的properties配置文件内容:
brokerClusterName=DefaultCluster
brokerName=broker-a
brokerId=0
deleteWhen=04
fileReservedTime=48
brokerRole=ASYNC_MASTER
flushDiskType=ASYNC_FLUSH
storePathRootDir=/data/rocketmq/rootdir-a-m
storePathCommitLog=/data/rocketmq/commitlog-a-m
autoCreateSubscriptionGroup=true
## if msg tracing is open,the flag will be true
traceTopicEnable=true
listenPort=10911
brokerIP1=XX.XX.XX.XX1
namesrvAddr=XX.XX.XX.XX:98762.2 普通模式
RocketMQ集群中每一个Broker节点均用于存储Client端收集并发送过来的消息轨迹数据。因此,对于RocketMQ集群中的Broker节点数量并无要求和限制。
2.3 物理IO隔离模式
对于消息轨迹数据量较大的场景,可以在RocketMQ集群中选择其中一个Broker节点专用于存储消息轨迹,使得用户普通的消息数据与消息轨迹数据的物理IO完全隔离,互不影响。在该模式下,RockeMQ集群中至少有两个Broker节点,其中一个Broker节点定义为存储消息轨迹数据的服务端。
2.4 启动开启消息轨迹的Broker
nohup sh mqbroker -c ../conf/2m-noslave/broker-a.properties &
3. 保存消息轨迹的Topic定义
RocketMQ的消息轨迹特性支持两种存储轨迹数据的方式:
3.1 系统级的TraceTopic
在默认情况下,消息轨迹数据是存储于系统级的TraceTopic中(其名称为:RMQ_SYS_TRACE_TOPIC)。该Topic在Broker节点启动时,会自动创建出来(如上所叙,需要在Broker端的配置文件中将traceTopicEnable的开关变量设置为true)。
3.2 用户自定义的TraceTopic
如果用户不准备将消息轨迹的数据存储于系统级的默认TraceTopic,也可以自己定义并创建用户级的Topic来保存轨迹(即为创建普通的Topic用于保存消息轨迹数据)。下面一节会介绍Client客户端的接口如何支持用户自定义的TraceTopic。
4. 支持消息轨迹的Client客户端实践
为了尽可能地减少用户业务系统使用RocketMQ消息轨迹特性的改造工作量,作者在设计时候采用对原来接口增加一个开关参数(enableMsgTrace)来实现消息轨迹是否开启;并新增一个自定义参(customizedTraceTopic)数来实现用户存储消息轨迹数据至自己创建的用户级Topic。
4.1 发送消息时开启消息轨迹
rocketmq: name-server: 192.168.146.200:9876;192.168.146.201:9876 producer: group: group retry-times-when-send-failed: 2 retry-next-server: true enable-msg-trace: true customized-trace-topic:
4.2 订阅消息时开启消息轨迹
与发送方差不多4.3 支持自定义存储消息轨迹Topic
在上面的发送和订阅消息时候分别将DefaultMQProducer和DefaultMQPushConsumer实例的初始化修改为如下即可支持自定义存储消息轨迹Topic。
rocketmq: name-server: 192.168.146.200:9876;192.168.146.201:9876 producer: group: group retry-times-when-send-failed: 2 retry-next-server: true enable-msg-trace: true customized-trace-topic: ttt
docker安装rocketmq
新建目录:在相应目录
mkdir /mydata/rocketmq/broker/{conf,logs,store} mkdir /mydata/rocketmq/namesrv/logs mkdir /mydata/rocketmq/rocketmq-console-ng/logs
拉取镜像:docker pull rocketmqinc/rocketmq:4.4.0
运行rmqnamesrv服务器:
docker run --name rmqnamesrv --restart=always -d -p 9876:9876 -v /mydata/rocketmq/namesrv/logs:/root/rocketmq/logs -v /mydata/rocketmq/namesrv/store:/root/rocketmq/store -e "MAX_POSSIBLE_HEAP=100000000" rocketmqinc/rocketmq:4.4.0 sh mqnamesrv
安装 broker 服务器:
在brocker/conf目录下创建 broker.conf 文件
brokerClusterName = DefaultCluster brokerName = broker-a brokerId = 0 deleteWhen = 04 fileReservedTime = 48 brokerRole = ASYNC_MASTER flushDiskType = ASYNC_FLUSH brokerIP1 = 192.168.146.200
启动服务器:
docker run --name rmqbroker --restart=always -d -p 10911:10911 -p 10909:10909 -v /mydata/rocketmq/broker/logs:/root/rocketmq/logs -v /mydata/rocketmq/broker/store:/root/rocketmq/store -v /mydata/rocketmq/broker/conf/broker.conf:/opt/rocketmq-4.4.0/conf/broker.conf --link rmqnamesrv:namesrv -e "NAMESRV_ADDR=namesrv:9876" -e "MAX_POSSIBLE_HEAP=200000000" rocketmqinc/rocketmq:4.4.0 sh mqbroker -c /opt/rocketmq-4.4.0/conf/broker.conf
安装 rocketmq 控制台
docker pull styletang/rocketmq-console-ng:1.0.0
启动控制台:
docker run -d --restart=always --name rocketmq-console-ng -v /mydata/rocketmq/rocketmq-console-ng/logs:/root/logs -e "JAVA_OPTS=-Drocketmq.namesrv.addr=192.168.146.200:9876 -Dcom.rocketmq.sendMessageWithVIPChannel=false" -p 6080:8080 -t styletang/rocketmq-console-ng:1.0.0
SMS--短信服务
短信服务(Short Message Service)是阿里云为用户提供的一种通信服务的能力。
产品优势:覆盖全面、高并发处理、消息堆积处理、开发管理简单、智能监控调度
产品功能:短信通知、短信验证码、推广短信、异步通知、数据统计
应用场景:短信验证码、系统信息推送、推广短信等

短信服务使用

》》》》》》》》》》》》》》》》》》》》》》》》》》》》》
<dependencyManagement>
<dependencies>
<!--spring boot 2.2.2-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.2.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud Hoxton.SR1-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud alibaba 2.1.0.RELEASE-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
spring: application: name: gateway-service cloud: gateway: discovery: locator: enabled: true #开启从注册中心动态创建路由的功能,利用微服务名进行路由 routes: - id: payment_routh #路由的ID,没有固定规则但要求唯一,建议配合服务名 #uri: http://localhost:8001 #匹配后提供服务的路由地址 uri: lb://lvym-payment-service #动态路由 predicates: - Path=/payment/get/** #断言,路径相匹配的进行路由 - id: payment_routh2 #uri: http://localhost:8001 uri: lb://lvym-payment-service #动态路由 predicates: - Path=/payment/lb/** #断言,路径相匹配的进行路由 - After=2020-04-13T17:09:09.715+08:00[Asia/Shanghai] # - Cookie=username,lvym
》》》》》》》》》》》》》》》
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
<version>2.0.0.RELEASE</version>
</dependency>
spring: zipkin: base-url: http://127.0.0.1:9411/ #zipkin server的请求地址 discoveryClientEnabled: false #让n acos把它当成一个URL,而不要当做服务名 sleuth: sampler: probability: 1.0 #采样的百分比 application: name: gateway-service cloud: gateway: discovery: locator: enabled: true #开启以服务id去注册中心上获取转发地址 routes: - id: baidu uri: http://www.baidu.com/ #转发http://www.baidu.com/ predicates: - Path=/bd/** #匹配规则 - id: member uri: lb://member-service #转发http://www.baidu.com/ filters: - StripPrefix=1 #不加会报错 predicates: - Path=/member/** #匹配规则 #127.0.0.1/bd 转发到http://www.baidu.com/
》》》》》》》》》》》》》》》》 有两种依赖,但似乎没什么不同
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>0.2.2.RELEASE</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
<version>2.1.0.RELEASE</version>
</dependency>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号