
Linux GSO逻辑分析
Linux GSO逻辑分析
——lvyilong316
(注:kernel版本linux 2.6.32)
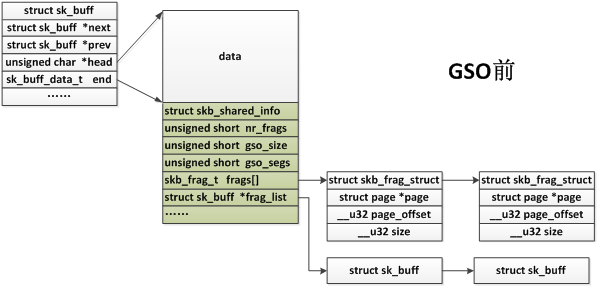
GSO用来扩展之前的TSO,目前已经并入upstream内核。TSO只能支持tcp协议,而GSO可以支持tcpv4, tcpv6, udp等协议。在GSO之前,skb_shinfo(skb)有两个成员ufo_size, tso_size,分别表示udp fragmentation offloading支持的分片长度,以及tcp segmentation offloading支持的分段长度,现在都用skb_shinfo(skb)->gso_size代替。
skb_shinfo(skb)->ufo_segs, skb_shinfo(skb)->tso_segs也被替换成了skb_shinfo(skb)->gso_segs,表示分片的个数。
gso用来delay 大包的分片,所以一直到dev_hard_start_xmit函数才会调用到。
l dev_hard_start_xmit
1 int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev, 2 3 struct netdev_queue *txq) 4 5 { 6 7 const struct net_device_ops *ops = dev->netdev_ops; 8 9 int rc; 10 11 12 13 if (likely(!skb->next)) { 14 15 if (!list_empty(&ptype_all)) 16 17 dev_queue_xmit_nit(skb, dev); 18 19 //判断网卡是否需要协议栈负责gso 20 21 if (netif_needs_gso(dev, skb)) { 22 23 //真正负责GSO操作的函数 24 25 if (unlikely(dev_gso_segment(skb))) 26 27 goto out_kfree_skb; 28 29 if (skb->next) 30 31 goto gso; 32 33 } 34 35 //…… 36 37 gso: 38 39 do { 40 41 //指向GSO分片后的一个skb 42 43 struct sk_buff *nskb = skb->next; 44 45 skb->next = nskb->next; 46 47 nskb->next = NULL; 48 49 if (dev->priv_flags & IFF_XMIT_DST_RELEASE) 50 51 skb_dst_drop(nskb); 52 53 //将通过GSO分片后的包逐个发出 54 55 rc = ops->ndo_start_xmit(nskb, dev); 56 57 if (unlikely(rc != NETDEV_TX_OK)) { 58 59 nskb->next = skb->next; 60 61 skb->next = nskb; 62 63 return rc; 64 65 } 66 67 txq_trans_update(txq); 68 69 if (unlikely(netif_tx_queue_stopped(txq) && skb->next)) 70 71 return NETDEV_TX_BUSY; 72 73 } while (skb->next); 74 75 76 77 skb->destructor = DEV_GSO_CB(skb)->destructor; 78 79 80 81 out_kfree_skb: 82 83 kfree_skb(skb); 84 85 return NETDEV_TX_OK; 86 87 }
那是不是所有skb在发送时都要经过GSO的逻辑呢?显然不是,只有通过netif_needs_gso判断才会进入GSO的逻辑,下面我们看下netif_needs_gso是如何判断的。
1 static inline int netif_needs_gso(struct net_device *dev, struct sk_buff *skb) 2 3 { 4 5 return skb_is_gso(skb) && 6 7 (!skb_gso_ok(skb, dev->features) || 8 9 unlikely(skb->ip_summed != CHECKSUM_PARTIAL)); 10 11 }
注意这里最后用了一个unlikely,因为如果通过前面的判断,说明网卡是支持GSO的,而一般网卡支持GSO也就会支持CHECKSUM_PARTIAL。进入GSO处理的第一个前提是skb_is_gso函数返回真,看下skb_is_gso的逻辑:
1 static inline int skb_is_gso(const struct sk_buff *skb) 2 3 { 4 5 return skb_shinfo(skb)->gso_size; 6 7 }
skb_is_gso的逻辑很简单,返回skb_shinfo(skb)->gso_size,所以进入GSO处理逻辑的必要条件之一是skb_shinfo(skb)->gso_size不为0,那么这个字段的含义是什么呢?gso_size表示生产GSO大包时的数据包长度,一般时mss的整数倍。下面看skb_gso_ok,如果这个函数返回False,就可以进入GSO处理逻辑。
1 static inline int skb_gso_ok(struct sk_buff *skb, int features) 2 3 { 4 5 return net_gso_ok(features, skb_shinfo(skb)->gso_type) && 6 7 (!skb_has_frags(skb) || (features & NETIF_F_FRAGLIST)); 8 9 }
skb_shinfo(skb)->gso_type包括SKB_GSO_TCPv4, SKB_GSO_UDPv4,同时NETIF_F_XXX的标志也增加了相应的bit,标识设备是否支持TSO, GSO, e.g.
1 NETIF_F_TSO = SKB_GSO_TCPV4 << NETIF_F_GSO_SHIFT 2 3 NETIF_F_UFO = SKB_GSO_UDPV4 << NETIF_F_GSO_SHIFT 4 5 #define NETIF_F_GSO_SHIFT 16
通过以上三个函数分析,以下三个情况需要协议栈负责GSO。
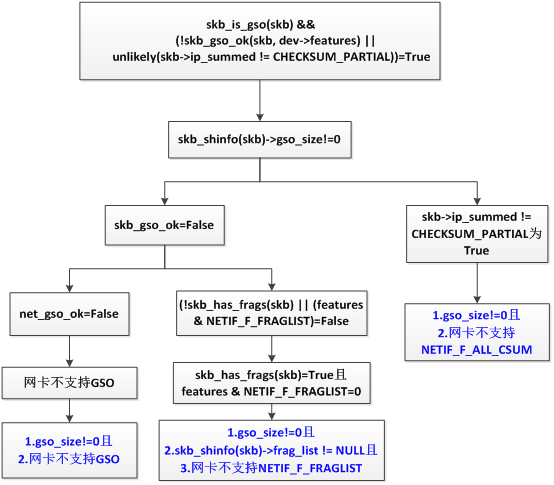
下面看GSO的协议栈处理逻辑,入口就是dev_gso_segment。
l dev_gso_segment
协议栈的GSO逻辑是在dev_gso_segment中进行的。这个函数主要完成对skb的分片,并将分片存放在原始skb的skb->next中,这也是GSO的主要工作。
1 static int dev_gso_segment(struct sk_buff *skb) 2 3 { 4 5 struct net_device *dev = skb->dev; 6 7 struct sk_buff *segs; 8 9 int features = dev->features & ~(illegal_highdma(dev, skb) ? 10 11 NETIF_F_SG : 0); 12 13 14 15 segs = skb_gso_segment(skb, features); 16 17 18 19 /* Verifying header integrity only. */ 20 21 if (!segs) 22 23 return 0; 24 25 26 27 if (IS_ERR(segs)) 28 29 return PTR_ERR(segs); 30 31 32 33 skb->next = segs; 34 35 DEV_GSO_CB(skb)->destructor = skb->destructor; 36 37 skb->destructor = dev_gso_skb_destructor; 38 39 40 41 return 0; 42 43 }
主要分片逻辑由skb_gso_segment来处理,这里我们主要看下析构过程,此时skb经过分片之后已经是一个skb list,通过skb->next串在一起,此时把初始的skb->destructor函数存到skb->cb中,然后把skb->destructor变更为dev_gso_skb_destructor。dev_gso_skb_destructor会把skb->next一个个通过kfree_skb释放掉,最后调用DEV_GSO_CB(skb)->destructor,即skb初始的析构函数做最后的清理。
l skb_gso_segment
这个函数将skb分片,并返回一个skb list。如果skb不需要分片则返回NULL。
1 struct sk_buff *skb_gso_segment(struct sk_buff *skb, int features) 2 3 { 4 5 struct sk_buff *segs = ERR_PTR(-EPROTONOSUPPORT); 6 7 struct packet_type *ptype; 8 9 __be16 type = skb->protocol; 10 11 int err; 12 13 14 15 skb_reset_mac_header(skb); 16 17 skb->mac_len = skb->network_header - skb->mac_header; 18 19 __skb_pull(skb, skb->mac_len); 20 21 //如果skb->ip_summed 不是 CHECKSUM_PARTIAL,那么报个warning,因为GSO类型的skb其ip_summed一般都是CHECKSUM_PARTIAL 22 23 if (unlikely(skb->ip_summed != CHECKSUM_PARTIAL)) { 24 25 struct net_device *dev = skb->dev; 26 27 struct ethtool_drvinfo info = {}; 28 29 WARN(……); 30 31 if (skb_header_cloned(skb) && 32 33 (err = pskb_expand_head(skb, 0, 0, GFP_ATOMIC))) 34 35 return ERR_PTR(err); 36 37 } 38 39 rcu_read_lock(); 40 41 list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) { 42 43 if (ptype->type == type && !ptype->dev && ptype->gso_segment) { 44 45 if (unlikely(skb->ip_summed != CHECKSUM_PARTIAL)) { 46 47 // 如果ip_summed != CHECKSUM_PARTIAL,则调用上层协议的gso_send_check 48 49 err = ptype->gso_send_check(skb); 50 51 segs = ERR_PTR(err); 52 53 if (err || skb_gso_ok(skb, features)) 54 55 break; 56 57 __skb_push(skb, (skb->data - 58 59 skb_network_header(skb))); 60 61 } 62 63 //把skb->data指向network header,调用上层协议的gso_segment完成分片 64 65 segs = ptype->gso_segment(skb, features); 66 67 break; 68 69 } 70 71 } 72 73 rcu_read_unlock(); 74 75 //把skb->data再次指向mac header 76 77 __skb_push(skb, skb->data - skb_mac_header(skb)); 78 79 80 81 return segs; 82 83 }
最终追调用上层协议的gso处理函数,对于IP协议,在注册IP的packet_type时,其gso处理函数被初始化为inet_gso_segment。下面我们看inet_gso_segment的处理流程。
l inet_gso_segment
./net/ipv4/af_inet.c
IP层GSO操作只是提供接口给链路层来访问传输层(TCP、UDP),因此IP层实现的接口只是根据分段数据报获取对应的传输层接口,并对完成GSO分段后的IP数据报重新计算校验和。
static struct sk_buff *inet_gso_segment(struct sk_buff *skb, int features) { struct sk_buff *segs = ERR_PTR(-EINVAL); struct iphdr *iph; const struct net_protocol *ops; int proto; int ihl; int id; unsigned int offset = 0; if (!(features & NETIF_F_V4_CSUM)) features &= ~NETIF_F_SG; //校验待软GSO分段的的skb,其gso_tpye是否存在其他非法值 if (unlikely(skb_shinfo(skb)->gso_type & ~(SKB_GSO_TCPV4 | SKB_GSO_UDP | SKB_GSO_DODGY | SKB_GSO_TCP_ECN | 0))) goto out; //分段数据至少大于IP首部长度 if (unlikely(!pskb_may_pull(skb, sizeof(*iph)))) goto out; //检验首部中的长度字段是否有效 iph = ip_hdr(skb); ihl = iph->ihl * 4; if (ihl < sizeof(*iph)) goto out; //再次通过首部中的长度字段检测skb长度是否有效 if (unlikely(!pskb_may_pull(skb, ihl))) goto out; //注意:这里已经将data偏移到了传送层头部了,去掉了IP头 __skb_pull(skb, ihl); skb_reset_transport_header(skb);//设置传输层头部位置 iph = ip_hdr(skb); id = ntohs(iph->id);//取出首部中的id字段 proto = iph->protocol & (MAX_INET_PROTOS - 1);//取出IP首部的协议值,用于定位与之对应的传输层接口(tcp还是udp) segs = ERR_PTR(-EPROTONOSUPPORT); rcu_read_lock(); ops = rcu_dereference(inet_protos[proto]);//根据协议字段取得上层的协议接口 if (likely(ops && ops->gso_segment)) segs = ops->gso_segment(skb, features);//调用上册协议的GSO处理函数 rcu_read_unlock(); if (!segs || IS_ERR(segs)) goto out; //开始处理分段后的skb skb = segs; do { iph = ip_hdr(skb); if (proto == IPPROTO_UDP) {//对于UDP进行的IP分片的头部处理逻辑 iph->id = htons(id);//所有UDP的IP分片id都相同 iph->frag_off = htons(offset >> 3);//ip头部偏移字段单位为8字节 if (skb->next != NULL) iph->frag_off |= htons(IP_MF);//设置分片标识 offset += (skb->len - skb->mac_len - iph->ihl * 4); } else iph->id = htons(id++);//对于TCP报,分片后IP头部中id加1 iph->tot_len = htons(skb->len - skb->mac_len); iph->check = 0; //计算校验和,只是IP头部的 iph->check = ip_fast_csum(skb_network_header(skb), iph->ihl); } while ((skb = skb->next)); out: return segs; }
这里有个问题,UDP经过GSO分片后每个分片的IP头部id是一样的,这个符合IP分片的逻辑,但是为什么TCP的GSO分片,IP头部的id会依次加1呢?原因是: tcp建立三次握手的过程中产生合适的mss(具体的处理机制参见TCP/IP详解P257),这个mss肯定是<=网络层的最大路径MTU,然后tcp数据封装成ip数据包通过网络层发送,当服务器端传输层接收到tcp数据之后进行tcp重组。所以正常情况下tcp产生的ip数据包在传输过程中是不会发生分片的!由于GSO应该保证对外透明,所以其效果应该也和在TCP层直接分片的效果是一样的,所以这里对UDP的处理是IP分片逻辑,但对TCP的处理是构造新的skb逻辑。
l 小结:对于GSO
UDP:所有分片ip头部id都相同,设置IP_MF分片标志(除最后一片) (等同于IP分片)
TCP:分片后,每个分片IP头部中id加1, (等同于TCP分段)
下面分别看对于TCP和UDP调用不通的GSO处理函数。对于TCP其GSO处理函数为tcp_tso_segment。
l tcp_tso_segment
./net/ipv4/tcp.c
1 struct sk_buff *tcp_tso_segment(struct sk_buff *skb, int features) 2 3 { 4 5 struct sk_buff *segs = ERR_PTR(-EINVAL); 6 7 struct tcphdr *th; 8 9 unsigned thlen; 10 11 unsigned int seq; 12 13 __be32 delta; 14 15 unsigned int oldlen; 16 17 unsigned int mss; 18 19 //检测报文长度至少由tcp头部长度 20 21 if (!pskb_may_pull(skb, sizeof(*th))) 22 23 goto out; 24 25 26 27 th = tcp_hdr(skb); 28 29 thlen = th->doff * 4;//TCP头部的长度字段单位为4字节 30 31 if (thlen < sizeof(*th)) 32 33 goto out; 34 35 //再次通过首部中的长度字段检测skb长度是否有效 36 37 if (!pskb_may_pull(skb, thlen)) 38 39 goto out; 40 41 //把tcp header移到skb header里,把skb->len存到oldlen中,此时skb->len就只有ip payload的长度(包含TCP首部) 42 43 oldlen = (u16)~skb->len; 44 45 __skb_pull(skb, thlen); //data指向tcp payload 46 47 //这里可以看出gso_size的含义就是mss 48 49 mss = skb_shinfo(skb)->gso_size; 50 51 if (unlikely(skb->len <= mss))//如果skb长度小于mss就不需要GSO分片处理了 52 53 goto out; 54 55 if (skb_gso_ok(skb, features | NETIF_F_GSO_ROBUST)) { 56 57 /* Packet is from an untrusted source, reset gso_segs. */ 58 59 int type = skb_shinfo(skb)->gso_type; 60 61 //校验待软GSO分段的的skb,其gso_tpye是否存在其他非法值 62 63 if (unlikely(type & 64 65 ~(SKB_GSO_TCPV4 | 66 67 SKB_GSO_DODGY | 68 69 SKB_GSO_TCP_ECN | 70 71 SKB_GSO_TCPV6 | 72 73 0) || 74 75 !(type & (SKB_GSO_TCPV4 | SKB_GSO_TCPV6)))) 76 77 goto out; 78 79 //计算出skb按照mss的长度需要分多少片,赋值给gso_segs 80 81 skb_shinfo(skb)->gso_segs = DIV_ROUND_UP(skb->len, mss); 82 83 84 85 segs = NULL; 86 87 goto out; 88 89 } 90 91 //skb_segment是真正的分段实现,后面再分析 92 93 segs = skb_segment(skb, features); 94 95 if (IS_ERR(segs)) 96 97 goto out; 98 99 100 101 delta = htonl(oldlen + (thlen + mss)); 102 103 104 105 skb = segs; 106 107 th = tcp_hdr(skb); 108 109 seq = ntohl(th->seq); 110 111 //下面是设置每个分片的tcp头部信息 112 113 do { 114 115 th->fin = th->psh = 0; 116 117 //计算每个分片的校验和 118 119 th->check = ~csum_fold((__force __wsum)((__force u32)th->check + 120 121 (__force u32)delta)); 122 123 if (skb->ip_summed != CHECKSUM_PARTIAL) 124 125 th->check =csum_fold(csum_partial(skb_transport_header(skb), 126 127 thlen, skb->csum)); 128 129 //重新初始化每个分片的序列号 130 131 seq += mss; 132 133 skb = skb->next; 134 135 th = tcp_hdr(skb); 136 137 138 139 th->seq = htonl(seq); 140 141 th->cwr = 0; 142 143 } while (skb->next); 144 145 146 147 delta = htonl(oldlen + (skb->tail - skb->transport_header) + 148 149 skb->data_len); 150 151 th->check = ~csum_fold((__force __wsum)((__force u32)th->check + 152 153 (__force u32)delta)); 154 155 if (skb->ip_summed != CHECKSUM_PARTIAL) 156 157 th->check = csum_fold(csum_partial(skb_transport_header(skb), 158 159 thlen, skb->csum)); 160 161 162 163 out: 164 165 return segs; 166 167 }
从上面可以看出,每个TCP的GSO分片是包含了TCP头部信息的,这也符合TCP层的分段逻辑。另外注意这里传递给skb_segment做分段时是不带TCP首部的。对于UDP,其GSO处理函数为udp4_ufo_fragment。
l udp4_ufo_fragment
./net/ipv4/udp.c
1 struct sk_buff *udp4_ufo_fragment(struct sk_buff *skb, int features) 2 3 { 4 5 struct sk_buff *segs = ERR_PTR(-EINVAL); 6 7 unsigned int mss; 8 9 int offset; 10 11 __wsum csum; 12 13 14 15 mss = skb_shinfo(skb)->gso_size; 16 17 if (unlikely(skb->len <= mss)) 18 19 goto out; 20 21 22 23 if (skb_gso_ok(skb, features | NETIF_F_GSO_ROBUST)) { 24 25 /* Packet is from an untrusted source, reset gso_segs. */ 26 27 int type = skb_shinfo(skb)->gso_type; 28 29 30 31 if (unlikely(type & ~(SKB_GSO_UDP | SKB_GSO_DODGY) || 32 33 !(type & (SKB_GSO_UDP)))) 34 35 goto out; 36 37 38 39 skb_shinfo(skb)->gso_segs = DIV_ROUND_UP(skb->len, mss); 40 41 42 43 segs = NULL; 44 45 goto out; 46 47 } 48 49 50 51 /* Do software UFO. Complete and fill in the UDP checksum as HW cannot 52 53 * do checksum of UDP packets sent as multiple IP fragments. 54 55 */ 56 57 //计算udp的checksum 58 59 offset = skb->csum_start - skb_headroom(skb); 60 61 csum = skb_checksum(skb, offset, skb->len - offset, 0); 62 63 offset += skb->csum_offset; 64 65 *(__sum16 *)(skb->data + offset) = csum_fold(csum); 66 67 skb->ip_summed = CHECKSUM_NONE; 68 69 //这里传递给skb_segment做分片时是没有将UDP首部去除的 70 71 segs = skb_segment(skb, features); 72 73 out: 74 75 return segs; 76 77 }
注意这里传递给skb_segment 做分片是带有udp首部的,分片将udp首部作为普通数据切分,这也意味着对于udp的GSO分片,只有第一片有UDP首部。udp的分段其实和ip的分片没什么区别,只是多一个计算checksum的步骤,下面看完成分片的关键函数skb_segment。
l skb_segment
/net/core/skbuff.c
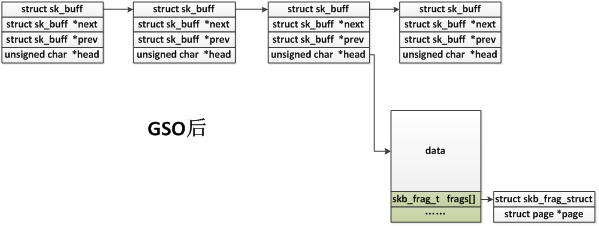
1 struct sk_buff *skb_segment(struct sk_buff *skb, int features) 2 3 { 4 5 struct sk_buff *segs = NULL; 6 7 struct sk_buff *tail = NULL; 8 9 struct sk_buff *fskb = skb_shinfo(skb)->frag_list; 10 11 unsigned int mss = skb_shinfo(skb)->gso_size; 12 13 unsigned int doffset = skb->data - skb_mac_header(skb);//mac头+ip头+tcp头 或mac头+ip头(对于UDP传入时没有将头部偏移过去) 14 15 unsigned int offset = doffset; 16 17 unsigned int headroom; 18 19 unsigned int len; 20 21 int sg = features & NETIF_F_SG; 22 23 int nfrags = skb_shinfo(skb)->nr_frags; 24 25 int err = -ENOMEM; 26 27 int i = 0; 28 29 int pos; 30 31 32 33 __skb_push(skb, doffset); 34 35 headroom = skb_headroom(skb); 36 37 pos = skb_headlen(skb);//pos初始化为线性区长度 38 39 40 41 do { 42 43 struct sk_buff *nskb; 44 45 skb_frag_t *frag; 46 47 int hsize; 48 49 int size; 50 51 // offset为分片已处理的长度,len为skb->len减去直到offset的部分。开始时,offset只是mac header + ip header + tcp header的长度,len即tcp payload的长度。随着segment增加, offset每次都增加mss长度。因此len的定义是每个segment的payload长度(最后一个segment的payload可能小于一个mss长度) 52 53 len = skb->len - offset; 54 55 if (len > mss)//len为本次要创建的新分片的长度 56 57 len = mss; 58 59 // hsize为线性区部分的payload减去offset后的大小,如果hsize小于0,那么说明payload在skb的frags或frag_list中。随着offset一直增长,必定会有hsize一直<0的情况开始出现,除非skb是一个完全linearize化的skb 60 61 hsize = skb_headlen(skb) - offset; 62 63 //这种情况说明线性区已经没有tcp payload的部分,需要pull数据过来 64 65 if (hsize < 0) 66 67 hsize = 0; 68 69 //如果不支持NETIF_F_SG或者hsize大于len,那么hsize就为len(本次新分片的长度),此时说明segment的payload还在skb 线性区中 70 71 if (hsize > len || !sg) 72 73 hsize = len; 74 75 76 77 if (!hsize && i >= nfrags) {// hsize为0,表示需要从frags数组或者frag_list链表中拷贝出数据,i >= nfrags说明frags数组中的数据也拷贝完了,下面需要从frag_list链表中拷贝数据了 78 79 BUG_ON(fskb->len != len); 80 81 82 83 pos += len; 84 85 //frag_list的数据不用真的拷贝,只需要拷贝其skb描述符,就可以复用其数据区 86 87 nskb = skb_clone(fskb, GFP_ATOMIC);//拷贝frag_list中的skb的描述符 88 89 fskb = fskb->next;//指向frag_list的下一个skb元素 90 91 92 93 if (unlikely(!nskb)) 94 95 goto err; 96 97 98 99 hsize = skb_end_pointer(nskb) - nskb->head; 100 101 //保证新的skb的headroom有mac header+ip header+tcp/udp+header的大小 102 103 if (skb_cow_head(nskb, doffset + headroom)) { 104 105 kfree_skb(nskb); 106 107 goto err; 108 109 } 110 111 //调整truesize,使其包含本次已分片的数据部分长度(hsize) 112 113 nskb->truesize += skb_end_pointer(nskb) - nskb->head - 114 115 hsize; 116 117 skb_release_head_state(nskb); 118 119 __skb_push(nskb, doffset); 120 121 } else {//数据从线性区或者frags数组中取得 122 123 //注意,每次要拷贝出的数据长度为len,其中hsize位于线性区 124 125 nskb = alloc_skb(hsize + doffset + headroom,GFP_ATOMIC); 126 127 128 129 if (unlikely(!nskb)) 130 131 goto err; 132 133 skb_reserve(nskb, headroom); 134 135 __skb_put(nskb, doffset); 136 137 } 138 139 140 141 if (segs) 142 143 tail->next = nskb; 144 145 else 146 147 segs = nskb; 148 149 tail = nskb; 150 151 //拷贝skb结构中的成员 152 153 __copy_skb_header(nskb, skb); 154 155 nskb->mac_len = skb->mac_len; 156 157 158 159 /* nskb and skb might have different headroom */ 160 161 if (nskb->ip_summed == CHECKSUM_PARTIAL) 162 163 nskb->csum_start += skb_headroom(nskb) - headroom; 164 165 166 167 skb_reset_mac_header(nskb); 168 169 skb_set_network_header(nskb, skb->mac_len); 170 171 nskb->transport_header = (nskb->network_header + 172 173 skb_network_header_len(skb)); 174 175 //把skb->data开始doffset长度的内容拷贝到nskb->data中 176 177 skb_copy_from_linear_data(skb, nskb->data, doffset); 178 179 // fskb被初始化为skb_shinfo(skb)->frag_list,现在如果不再相等,说明已经开始拷贝frag_list链表中的数据,不用继续后面的逻辑了(后面的逻辑是从线性区或者frags数组中拷贝的逻辑) 180 181 if (fskb != skb_shinfo(skb)->frag_list) 182 183 continue; 184 185 //如果不支持NETIF_F_SG,说明frags数组中没有数据,只考虑从线性区中拷贝数据 186 187 if (!sg) { 188 189 nskb->ip_summed = CHECKSUM_NONE; 190 191 //注意,每次要拷贝出的数据长度为len,其中hsize位于线性区 192 193 nskb->csum = skb_copy_and_csum_bits(skb, offset, 194 195 skb_put(nskb, len), len, 0); 196 197 continue; 198 199 } 200 201 202 203 frag = skb_shinfo(nskb)->frags; 204 205 //如果hsize不为0,那么拷贝hsize的内容到nskb的线性区中 206 207 skb_copy_from_linear_data_offset(skb, offset,skb_put(nskb, hsize), hsize); 208 209 //注意:每次要拷贝的数据长度是len,其中hsize是位于线性区中,但是随着线性区数据逐渐被处理,hsize可能不够len,这时剩下的(len-hsize)长度就要从frags数组中拷贝了 210 211 while (pos < offset + len && i < nfrags) { //从frags数组中拷贝数据 212 213 *frag = skb_shinfo(skb)->frags[i]; 214 215 get_page(frag->page); 216 217 size = frag->size; 218 219 //pos初始为线性区长度,后来表示已经被拷贝的长度 220 221 if (pos < offset) { 222 223 frag->page_offset += offset - pos; 224 225 frag->size -= offset - pos; 226 227 } 228 229 //frags数组中的数据并不是真的拷贝,而是nskb的frags数组直接指向相应的page 230 231 skb_shinfo(nskb)->nr_frags++; 232 233 234 235 if (pos + size <= offset + len) { 236 237 i++; 238 239 pos += size; 240 241 } else { 242 243 frag->size -= pos + size - (offset + len); 244 245 goto skip_fraglist; 246 247 } 248 249 frag++; 250 251 } 252 253 //如果把frags数组中的数据拷贝完还不够len长度,则需要从frag_list中拷贝了 254 255 if (pos < offset + len) { 256 257 struct sk_buff *fskb2 = fskb;//指向frag_list 258 259 260 261 BUG_ON(pos + fskb->len != offset + len); 262 263 264 265 pos += fskb->len; 266 267 fskb = fskb->next; 268 269 270 271 if (fskb2->next) { 272 273 fskb2 = skb_clone(fskb2, GFP_ATOMIC); 274 275 if (!fskb2) 276 277 goto err; 278 279 } else 280 281 skb_get(fskb2); 282 283 284 285 SKB_FRAG_ASSERT(nskb); 286 287 //这里也不是真的拷贝数据,而是nskb的frag_list直接链上老的frag_list中的元素 288 289 skb_shinfo(nskb)->frag_list = fskb2; 290 291 } 292 293 skip_fraglist: 294 295 nskb->data_len = len - hsize; 296 297 nskb->len += nskb->data_len; 298 299 nskb->truesize += nskb->data_len; 300 301 } while ((offset += len) < skb->len);//完成一个nskb之后,继续下一个seg,一直到offset >= skb->len 302 303 return segs; 304 305 306 307 err: 308 309 while ((skb = segs)) { 310 311 segs = skb->next; 312 313 kfree_skb(skb); 314 315 } 316 317 return ERR_PTR(err); 318 319 }
从上面的分片过程可以看出,分成的小skb并不一定都是线性话的,如果之前的skb存在frags数组或者frag_list,则分成的小skb也可能有指向非线性区域。并不用担心网卡不支持分散聚合IO,因为之前如果能产生这些非线性数据,就说明网卡一定是支持的。
最后回顾下整个协议栈的GSO处理逻辑,如下图:
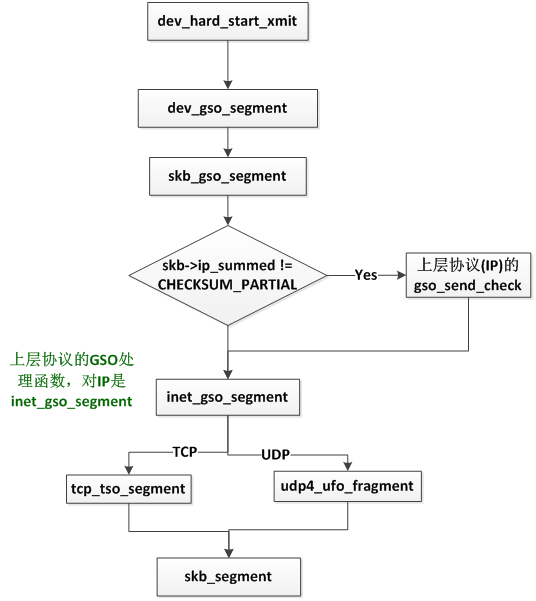
我们再看一下skb组织形式在GSO前后的变化:
GSO之后如下,注意GSO之后也是可能带有frags的。
posted on 2017-05-07 16:15 yilong316 阅读(8932) 评论(0) 编辑 收藏 举报


